Job system architecture overview
Below is an overview of the architecture of the job system. You'll find information on the components that make up the system. As well as information on where to start looking when you encounter bugs and areas for improvement.
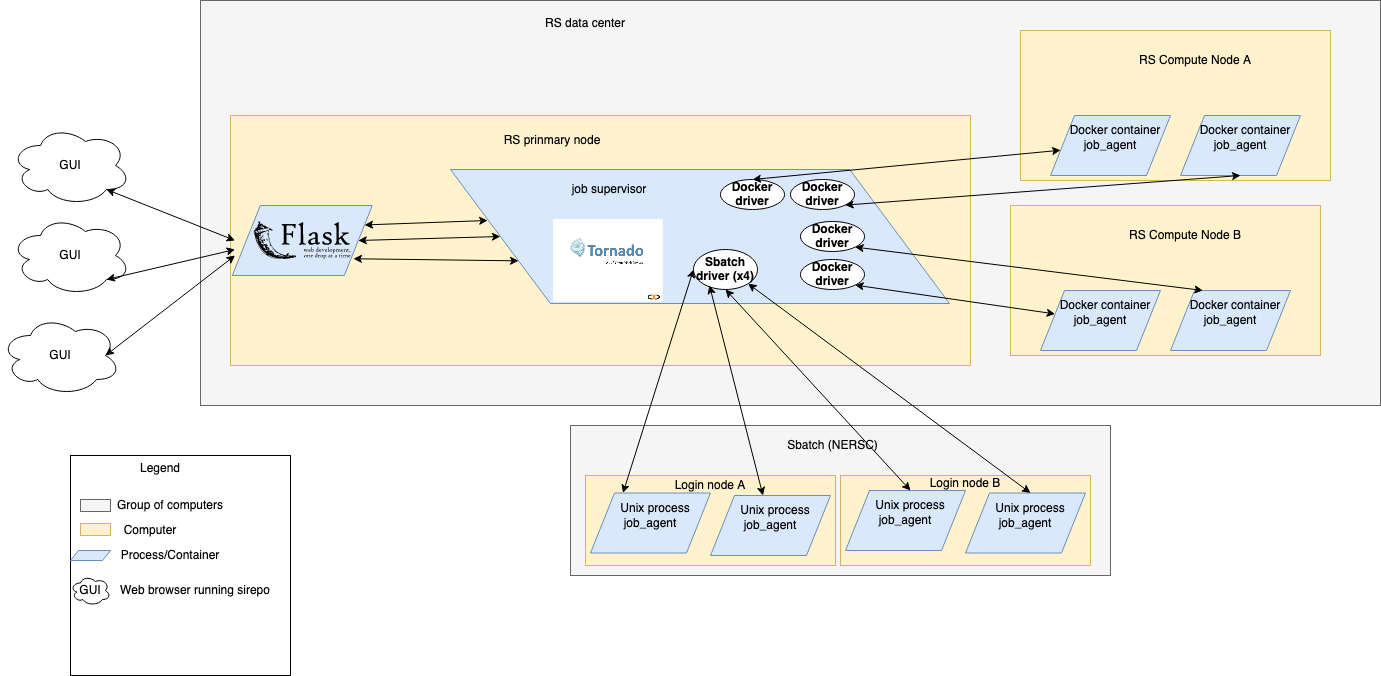
The flask server is the entry point from the GUI into the backend.
Some requests are responded to without ever leaving flask (the api's in server.py). These api's are ones that don't interact with the sirepo database (srdb) at all (ex. api_homePage) or those that interact with the srdb but don't involve running a simulation (ex. api_deleteSimulation).
Other requests are sent on to the job system (the api's in job_api.py). These api's involve running simulations (ex. api_runStatus) or requests that need to make it to remote agents (ex. api_sbatchLogin).
The bulk of the work of the Flask server with regards to the job system is permissions and translating incoming requests into requests the job system can interpret. Each incoming http request results in one outgoing http request to the job supervisor.
The job supervisor is the "brains" of the job system. It brokers messages between all other components, it starts agents, and implements a great deal of the business logic. If you are interested in modifying how jobs are executed or wondering why a job is not executing properly this is a good place to start.
The job supervisor runs as a separate unix process on the same server as the Flask server
This is the entrypoint for developers to start the supervisor and for incoming requests to the supervisor. The supervisor is run on top of a Tornado web server. Tornado is an async python webserver framework.
This is the bulk of business logic of the job supervisor. When someone says "job supervisor" this is likely the bit of code in they have in their mind. It maps apis one to one with those defined in job_api.py and handles the business logic related to each one.
Things to take note of in job_supervisor.py:
- Each incoming request is routed to a ComputeJob
instance. These
instances are identified by their computeJid.
- Each ComputeJob instance is recorded in the supervisor-job database
- Many requests (though not all) result in an op. These ops are what flow downstream of this system and ultimately are sent to agents.
- Each op has a driver instance. Drivers are what talk to agents (drivers and agents are explained in detail below).
- Once an incoming request is deemed valid (ex through checks like this). It is worked through a series of steps trying to gain resources until it is ultimately sent to an agent. Resources are things like an active websocket connection with an agent, compute resource to run a simulation, etc. The loop is necessary because whenever we wait on a resource being available we raise Awaited , start the loop over, and make sure that the state assumptions we made above are still valid (ex. does the websocket still exist?). This is the nature of non-preemptable concurrent programming, any state above an await cannot be guaranteed to be the same below an await so it must be checked again. For more info on this read this document.
Job drivers are the last component of the supervisor. I use the word "last" because the final piece of code that a request goes through in the supervisor is the driver code. Drivers handle the life-cycle of agents as well as communicating with agents. There are different types of drivers which communicate with their respective type of agents.
Each driver implementation is a subclass of the DriverBase class.
The local driver type starts agents that run as a unix process on the same machine as the supervisor. This class of drivers are usually used for local development.
The docker driver type starts agents that run inside of a docker container. This class of drivers can be used for local development and they are what we run in production.
The sbatch driver type starts agents that know how to execute jobs using Slurm. It does this by shh'ing into a machine that is running Slurm and executing Slurm commands to start the job. You can run sbatch while developing (assuming you have slurm installed) and we run it in production to talk with NERSC.
Agents are the "workers" of the job system. They take commands from the sueprvisor, run them, and report back the results.
Local and Docker agents are the same except for where they are running (ex inside of a docker container).
Sbatch agents are slightly different because they must execute commands talking to Slurm (ex prepare_simulation.
Agent's communicate with the supervisor using websockets.
Once an agent is started they should remain alive with an active websocket connection for the life of the system.
Agent's execute job cmds. Job cmds directly interact with the codes and can be run in py2 or py3.
License: http://www.apache.org/licenses/LICENSE-2.0.html
Copyright ©️ 2015–2020 RadiaSoft LLC. All Rights Reserved.
