1.3.3. The Multiline Generator
This is the first generator built on a completely reengineered architecture, which has been built from ground up to be modularized, standardized and scalable. It produces output by joining the individual efforts of very distinct classes of musical algorithms, each specialized in only one music trait (e.g., there are specific algorithms specialized in rhythm, harmony, etc).
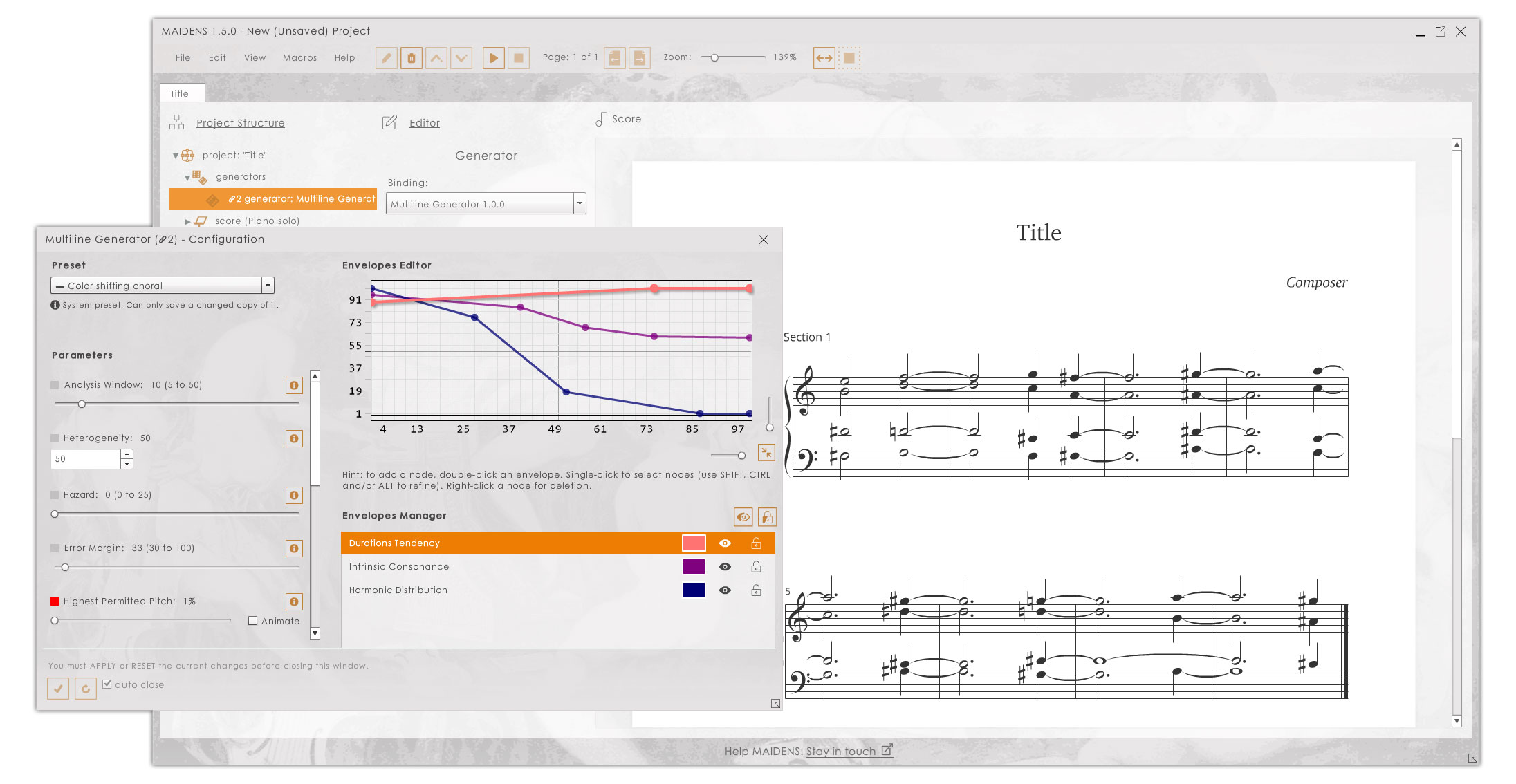
The module makes rhythmic, melodic and harmonic decisions based on the specifics of the area it is supposed to fill with musical content (i.e., what instruments are involved, what time signatures) and the explicit requirements it receives from the human creator controlling the software (i.e., what parameters are set to what values). Based on these decisions, the module is able to construct an interim musical body, which it holistically refines in a final step and then returns.
Note: the Multiline Generator enables the operator to set both fixed and evolving parameters, by means of an Envelopes Editor.
The Multiline Generator was built from ground up and uses an entirely new architecture, which is more robust, scalable and maintainable, and which centers around the idea that any piece of well written music constitutes the congruence of a number of parametric forces that acted gracefully upon the primary material that is musical sound. Therefore, the Multiline Generator operates a number of Music Traits (such as rhythm, melody, harmony, etc.), each of them running several intrinsic or contextual Analyzers.
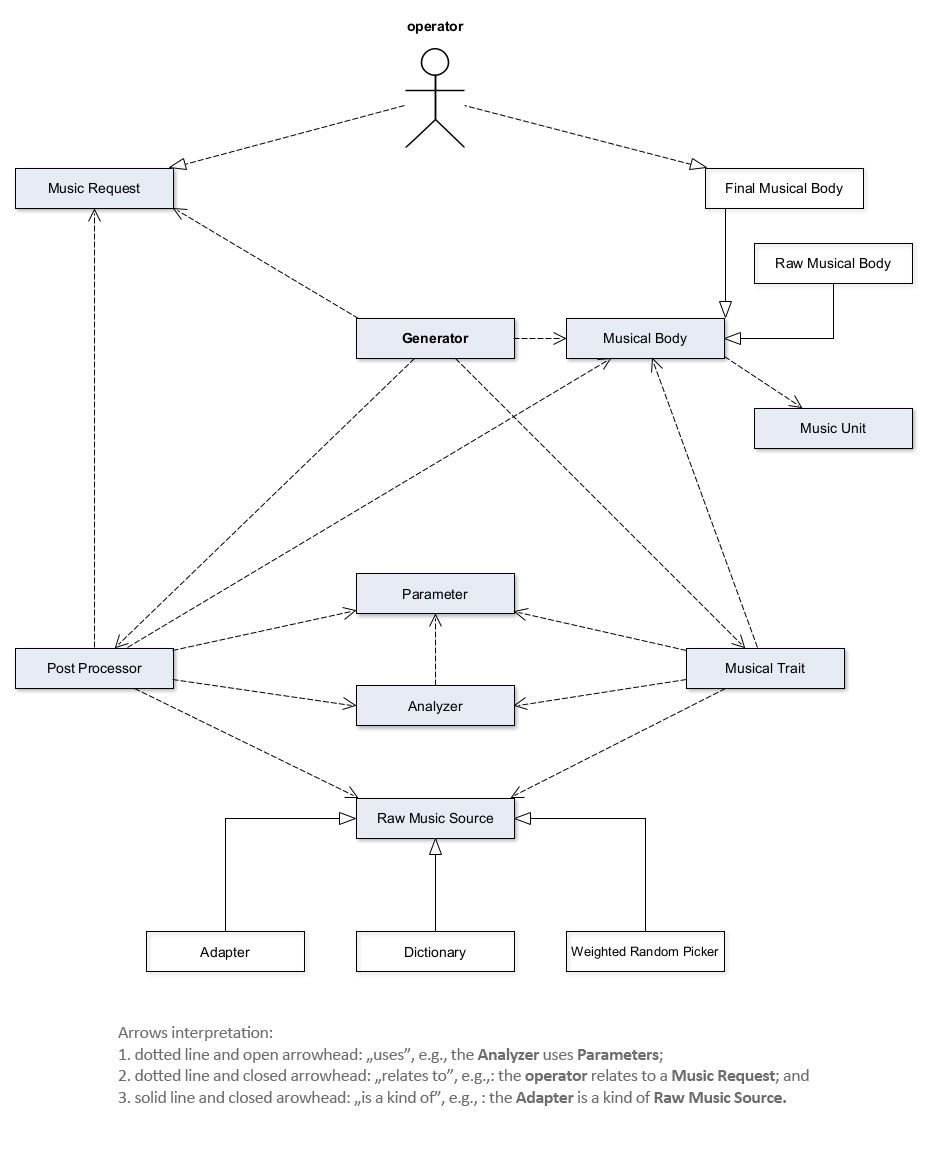
These evaluate and select from thousands of raw musical structures, which, in turn are provided by one or more Musical Sources — essentially, stochastic devices, but not exclusively. User-controlled Parameters act both upon the Analyzers and the Sources, in order to make sure that only the most fit of the structures make it to the resulting music. This is an open architecture: the more Parameters and Analyzers are added to the system, the better the assessment process will be, and the more qualitative the resulting music.
Besides the new architecture, the new Generator introduces the concept of dynamic parameters (they change their value in time, making, e.g., a consonant passage “morph” into a dissonant one) and provides an advanced, dedicated UI to control them.
How many of the previously generated structures to observe when deciding what structure to add next. Note that Analyzers and Musical Sources take this value as a hint rather than a firm limit.
How much diversity to incur in the raw generated material. The more diversity, the more chances to find suitable choices in there. Value is a factor of the "Analysis window" parameter. This option directly controls the size of the pool of raw musical structures to be evaluated, and thus has the potential of slowing down the process, especially when chosen Error Margin is small.
A way to balance deterministics and chance. The smaller the value, the higher the odds that the generated music will sound more "orderly". Value is a factor of the full range of the generated structures. Practically, a value of 0 will ensure that only the most fit structure found will be promoted to the resulting music. Raising this value will increase the ods for other, "less than ideal" structures to also be considered.
Controls a preliminary validation device, which only accepts those structures whose calculated fitness score is within certain margin to the expected value. The smaller the value, the more CPU time is invested to closely match every parameter value.
Nota bene: when the pool of raw musical structures is exhausted without finding a match, the
Error Marginis automatically lowered, internally, and a new search begins. Eventually, the margin would be low enough to allow for at least one match to be found. Therefore, for all practical purposes, theError Marginparameter only controls the computation effort invested (which always means more CPU time, but only statistically translates to better results).
Turn on to engage the Melodic Profile Balance parameter; switch off to bypass it.
Applies a melodic model to the top-most voice of the structures being generated, where direction and magnitude of melodic motion self-balance themselves (e.g., upward motion is compensated by downward motion). The greater the value, the closer the generated melodies will abide by the model; smaller values encourage unbalanced lines that defy/contradict the model.
The highest pitch to consider including. Expressed as a percent, 1% means the upper limit of the average middle range of all involved instruments, while 100% means the highest pitch playable by any of the involved instruments.
Note: unlike legacy implementations, the Multiline Generator "knows" to correctly distribute available pitches based on playing instruments' range.
The lowest pitch to consider including. Expressed as a percent, 1% means the lowest pitch playable by any of the involved instruments, while 100% means the lower limit of the average middle range of all involved instruments.
The dominant durations to use when generating structures. Expressed as a percent, smaller values generally favor shorter durations, while greater values favor longer durations.
The value you provide to this parameter actually controls a sliding readout that picks up and serializes data from an internal dataset. This dataset describes evolution envelopes for each of the available musical durations. Halves, quarters and eights have rise – peak – fall profiles; sixteenths only have a fall, while wholes only have a rise.

The peaks of these internal envelopes are equally offset from one another. Proceeding from left to right through the graph, one would obtain a rather steady and linear change in the population of musical durations returned.
For instance, a readout at 50% would return a rhythmic population made of (values were rounded):
| Musical duration | Raw Value | Normalized Value | Chance of Being Used |
|---|---|---|---|
| sixteenths | 15 |
0.07 |
7% |
| eights | 30 |
0.16 |
16% |
| quarters | 100 |
0.54 |
54% |
| halves | 30 |
0.16 |
16% |
| wholes | 15 |
0.07 |
7% |
A value of 25% would produce a slightly modified, but still (essentially) harmonic distribution, only rooted on eights this time:
| Musical duration | Raw Value | Normalized Value | Chance of Being Used |
|---|---|---|---|
| sixteenths | 47 |
0.22 |
22% |
| eights | 100 |
0.48 |
48% |
| quarters | 36 |
0.18 |
18% |
| halves | 15 |
0.08 |
8% |
| wholes | 7 |
0.04 |
4% |
At 75% the readout would produce the same values, but mirrored (the dominant duration would be halves instead of eights). The two extreme positions (0% and 100%) are edge cases that only favor sixtieths or wholes respectively. In-between positions cause interpolation, e.g., at 40% returned population would be made of:
| Musical duration | Raw Value | Normalized Value | Chance of Being Used |
|---|---|---|---|
| sixteenths | 28 |
0.16 |
16% |
| eights | 58 |
0.33 |
33% |
| quarters | 58 |
0.33 |
33% |
| halves | 24 |
0.14 |
14% |
| wholes | 13 |
0.08 |
8% |
As the above table shows, it is perfectly possible to set the Durations Tendency parameter to a value that does not result in a single dominant duration.
Nota bene: individual values depicted in the tables above are fed to a weighted random picker device, which means that the actual durations used in the generated score might not seem to reflect your setting at times. This is why setting the
Durations Tendencyparameter to0%or100%is unlikely to produce only sixtieths or wholes (as noted above).Currently, the
Durations Tendencyparameter is unable to produce less harmonic distribution of musical durations.
How many "voices" to use (i.e., rhythmically autonomous pitches). Expressed as a percent, 1% means, by convention, 1 "voice", whereas 100% means the full polyphony that all involved instruments are able, together, to sustain. When this parameter is not at its 100% value, MAIDENS randomly chooses the actual "voices" to employ, but their number will reflect your setting at any given time.
Context-independent, harmonic consonance of each structure. Only relevant when there are several "voices" involved. Expressed as a percent, 1% favors harsh dissonances, whereas 100% favors more consonant chords (ideally triads). The implementation essentially follows Paul Hindemith's observations in the first volume of his text book Unterweisung im Tonsatz (The Craft of Musical Composition) and approximates any given chord's harmonic "value" by analysing the individual harmonic intervals it is made of. True to Hindemith's approach, consonant chords are considered to be more "valuable" than dissonant ones, which is why the 100% setting essentially produces consonant rather than dissonant harmonies.
Note: due to other parameters also playing a role in determining how "fit" a structure is, the influence of the Intrinsic Consonance setting is only statistically observable.
This option is very CPU-intensive. It adds a pre-filter to the harmonic structures being generated, ensuring that each of them is at least as consonant as the current value set by the Intrinsic Consonance parameter.
Motion profile of individual voices in two subsequent structures. Expressed as a percent, 100% favors more motion in the external "voices" and less in internal ones, while 1% imposes no such restrictions.
Note: individual "voices" motion from chord to chord is also influenced by other factors, such as the
Voice Restlessnessparameter, which is why the effect of theChord Progressionis rather subtle and rather difficult to observe. However, chords generally tend to progress more fluid when this setting is given a higher value.
Tendency of each individual note of a structure to progress to a different pitch in the structure immediately following it, rather than holding the same pitch. Higher values favor homophony, while lower values favor polyphony. The values in the extremes yield textures of long, held notes (1%) or isomorphous chorals (100%).
Distribution of individual notes inside of a given structure. Higher values favor pyramidal shapes, i.e., notes tend to crowd in the upper part of the structure and dilute toward the bass; lower values favor the opposite (reversed pyramids). Around the middle setting notes tend to distribute evenly. Introducing this setting was based on the observation that harmonic structures in which the pitches layout mimic those of the natural partials tend to have better resonance and increased stability. Giving this setting a higher value tends to make harmonies sound more convincing without touching their actual consonance.
The Multiline Generator can be used to generate isolated lines, polyphonies, isomorphic (homophonic) chorals, and anything in between. It is seen completely replacing the legacy Generators (Atonal Line and Atonal Harmony) in the near future.