ORTEScalabilityTesting
To get a better handle on how scalable the ORTE is we plan on gathering some data. This document outlines a plan of what tests to do as well as providing a place to store the results. We first start describing the tests we want to run, the cluster we want to run the tests on, and the data we want to collect.
There are four tests we want to run. They are outlined in the table.
| Tests | Location | Description |
|---|---|---|
| /bin/true | measures native launching speed | |
| hostname | measures launching speed plus some trivial output | |
| orte_no_op | orte/test/system | add some basic ORTE coordination during launch |
| mpi_no_op | orte/test/mpi | add in the cost of OMPI coordination during launch |
Here is a list of configurations we should test.
Cluster Matrix:
| Nodes | Process/Node | Total np |
|---|---|---|
| 256 | 1 | 256 |
| 256 | 2 | 512 |
| 256 | 8 | 2048 |
| 256 | 16 | 4096 |
| 512 | 1 | 512 |
| 512 | 2 | 1024 |
| 1024 | 1 | 1024 |
| 1024 | 2 | 2048 |
| 2048 | 1 | 2048 |
| 2048 | 2 | 4096 |
| 3000 | 1 | 3000 |
| 3000 | 2 | 6000 |
| MPI Releases |
|---|
| OMPI 1.2.5 |
| OMPI Trunk |
| MVAPICH - Version to be determined |
Note that we have left MVAPICH2 off the table. We believe MVAPICH is the current competition when running at scale.
For the 256 node configurations, we want to test to see the effect of SM BTLs. Therefore, we will do these combinations.
| BTL Combinations for 256 Node Testing |
|---|
| --mca btl self,openib |
| --mca btl self,sm,openib |
| --mca btl self,tcp |
| --mca btl self,sm,tcp |
| --mca btl self,ud |
| --mca btl self,sm,ud |
For the larger cluster, we keep SM in for all testing.
| BTL Combinations for Larger Node Testing |
|---|
| --mca btl self,sm,openib |
| --mca btl self,sm,tcp |
| --mca btl self,sm,ud |
We can just use time for doing the measurements. Typically, we use the ''/usr/bin/time'' and are interested in the real value.
We may want to do a comparison between static and dynamic libraries.
Jeff Squyres says
Ralph was seeing a huge performance boost at scale on the LANL RoadRunner machine even in the 1.2.x series when using mpi_preconnect_oob=1. So for the ompi_noop tests, you might want to test with mpi_preconnect_oob for both 0 and 1, and then mpi_preconnect_all for 0 and 1 (which does an OOB preconnect followed by an MPI preconnect)
Ralph Castain says
You may well find that the OOB preconnect options actually hurt with 1.3 while helping 1.2.x
Do not use the ORTE internal timings as it is not very useful.
Below is a test matrix that cycles through both the tests and the size of the job. The MPI version, preconnect setting and BTLs are static. This matrix has 48 different test configurations. When we start varying the other parameters we can see that this table will get very large very quickly. Therefore, this table is a baseline for tests to run.
| Tests | MPI | NodexProcs (NP) | Preconnect | BTL | Time |
|---|---|---|---|---|---|
| /bin/true | OpenMPI 1.2.5 | 256x1 (256) | no | --mca btl self,sm,openib | |
| /bin/true | OpenMPI 1.2.5 | 256x2 (512) | no | --mca btl self,sm,openib | |
| /bin/true | OpenMPI 1.2.5 | 256x8 (2048) | no | --mca btl self,sm,openib | |
| /bin/true | OpenMPI 1.2.5 | 256x16 (4096) | no | --mca btl self,sm,openib | |
| /bin/true | OpenMPI 1.2.5 | 512x1 (512) | no | --mca btl self,sm,openib | |
| /bin/true | OpenMPI 1.2.5 | 512x2 (1024) | no | --mca btl self,sm,openib | |
| /bin/true | OpenMPI 1.2.5 | 1024x1 (1024) | no | --mca btl self,sm,openib | |
| /bin/true | OpenMPI 1.2.5 | 1024x2 (2048) | no | --mca btl self,sm,openib | |
| /bin/true | OpenMPI 1.2.5 | 2048x1 (2048) | no | --mca btl self,sm,openib | |
| /bin/true | OpenMPI 1.2.5 | 2048x2 (4096) | no | --mca btl self,sm,openib | |
| /bin/true | OpenMPI 1.2.5 | 3000x1 (3000) | no | --mca btl self,sm,openib | |
| /bin/true | OpenMPI 1.2.5 | 3000x2 (6000) | no | --mca btl self,sm,openib | |
| /bin/hostname | OpenMPI 1.2.5 | 256x1 (256) | no | --mca btl self,sm,openib | |
| /bin/hostname | OpenMPI 1.2.5 | 256x2 (512) | no | --mca btl self,sm,openib | |
| /bin/hostname | OpenMPI 1.2.5 | 256x8 (2048) | no | --mca btl self,sm,openib | |
| /bin/hostname | OpenMPI 1.2.5 | 256x16 (4096) | no | --mca btl self,sm,openib | |
| /bin/hostname | OpenMPI 1.2.5 | 512x1 (512) | no | --mca btl self,sm,openib | |
| /bin/hostname | OpenMPI 1.2.5 | 512x2 (1024) | no | --mca btl self,sm,openib | |
| /bin/hostname | OpenMPI 1.2.5 | 1024x1 (1024) | no | --mca btl self,sm,openib | |
| /bin/hostname | OpenMPI 1.2.5 | 1024x2 (2048) | no | --mca btl self,sm,openib | |
| /bin/hostname | OpenMPI 1.2.5 | 2048x1 (2048) | no | --mca btl self,sm,openib | |
| /bin/hostname | OpenMPI 1.2.5 | 2048x2 (4096) | no | --mca btl self,sm,openib | |
| /bin/hostname | OpenMPI 1.2.5 | 3000x1 (3000) | no | --mca btl self,sm,openib | |
| /bin/hostname | OpenMPI 1.2.5 | 3000x2 (6000) | no | --mca btl self,sm,openib | |
| orte_no_op | OpenMPI 1.2.5 | 256x1 (256) | no | --mca btl self,sm,openib | |
| orte_no_op | OpenMPI 1.2.5 | 256x2 (512) | no | --mca btl self,sm,openib | |
| orte_no_op | OpenMPI 1.2.5 | 256x8 (2048) | no | --mca btl self,sm,openib | |
| orte_no_op | OpenMPI 1.2.5 | 256x16 (4096) | no | --mca btl self,sm,openib | |
| orte_no_op | OpenMPI 1.2.5 | 512x1 (512) | no | --mca btl self,sm,openib | |
| orte_no_op | OpenMPI 1.2.5 | 512x2 (1024) | no | --mca btl self,sm,openib | |
| orte_no_op | OpenMPI 1.2.5 | 1024x1 (1024) | no | --mca btl self,sm,openib | |
| orte_no_op | OpenMPI 1.2.5 | 1024x2 (2048) | no | --mca btl self,sm,openib | |
| orte_no_op | OpenMPI 1.2.5 | 2048x1 (2048) | no | --mca btl self,sm,openib | |
| orte_no_op | OpenMPI 1.2.5 | 2048x2 (4096) | no | --mca btl self,sm,openib | |
| orte_no_op | OpenMPI 1.2.5 | 3000x1 (3000) | no | --mca btl self,sm,openib | |
| orte_no_op | OpenMPI 1.2.5 | 3000x2 (6000) | no | --mca btl self,sm,openib | |
| ompi_no_op | OpenMPI 1.2.5 | 256x1 (256) | no | --mca btl self,sm,openib | |
| ompi_no_op | OpenMPI 1.2.5 | 256x2 (512) | no | --mca btl self,sm,openib | |
| ompi_no_op | OpenMPI 1.2.5 | 256x8 (2048) | no | --mca btl self,sm,openib | |
| ompi_no_op | OpenMPI 1.2.5 | 256x16 (4096) | no | --mca btl self,sm,openib | |
| ompi_no_op | OpenMPI 1.2.5 | 512x1 (512) | no | --mca btl self,sm,openib | |
| ompi_no_op | OpenMPI 1.2.5 | 512x2 (1024) | no | --mca btl self,sm,openib | |
| ompi_no_op | OpenMPI 1.2.5 | 1024x1 (1024) | no | --mca btl self,sm,openib | |
| ompi_no_op | OpenMPI 1.2.5 | 1024x2 (2048) | no | --mca btl self,sm,openib | |
| ompi_no_op | OpenMPI 1.2.5 | 2048x1 (2048) | no | --mca btl self,sm,openib | |
| ompi_no_op | OpenMPI 1.2.5 | 2048x2 (4096) | no | --mca btl self,sm,openib | |
| ompi_no_op | OpenMPI 1.2.5 | 3000x1 (3000) | no | --mca btl self,sm,openib | |
| ompi_no_op | OpenMPI 1.2.5 | 3000x2 (6000) | no | --mca btl self,sm,openib |
This is a brief report on recent changes for better launch scalability, and where 1.3 currently stands in that regard. The comments will refer to the attached graphs fairly frequently, so you might want to have them available.
Preliminary scaling tests on our RRZ machine (96 nodes, 8ppn, TM, with IB) revealed that our modex operation was still scaling poorly. Several of us subsequently developed a mitigation plan that consists of several parts. The first part was implemented and committed as r17988/r17992.
Prior to this change, and indeed in all prior OMPI releases, modex messages flowed from each proc in the job to a central location for collection. In prior releases, this was the GPR - in 1.3, this is the rank=0 application process. The number of messages being sent inbound therefore scaled with the number of processes. The collected data was subsequently "xcast'd" to all application processes in the job.
Under the revisions of r17988/r17992, the modex message from each process is sent to its local daemon. The local daemon collects a message from each process until all processes in that job have sent one - at that point, the local daemon sends the collected message to the rank=0 application process for that job. Thus, the number of messages being sent inbound to the rank=0 process scales with the number of nodes. As before, the collected data is then xcast to all application processes in the job.
The attached graph entitled "RRZ Scaling: 1.3rev vs 1.3" (file Revised-trunk-clean.png) shows a comparison of these two methods across 96 nodes at various ppn. As expected, the level of improvement in performance and scaling law increases with increasing ppn, and the revised method outperforms the prior method at all ppn levels above 1.
Fitting this data and trending it out to the size of a full launch on the RoadRunner computer (8000 procs on 1000 nodes) reveals the significance of the change. Under the old method, such a launch would have consumed about 65 minutes to complete an application consisting of MPI_Init/MPI_Finalize. Using the revised method now in 1.3, this has been reduced to roughly 7 minutes - an order of magnitude improvement.
A less cluttered view of 1.3's scaling is shown in the graph entitled "1.3 Scaling on RRZ" (file RRZ-1.3-by-proc.png). This is further captured in the graphs entitled "1.3 Scaling by Node" (file RRZ-1.3-by-node.png) - in these curves, I have indicated where the crossover takes place to the binomial xcast algorithm.
The graphs show better-than-linear behavior for non-MPI/ORTE jobs at levels where the binomial xcast comes into operation. As we include the orte_init effects, the behavior becomes more nearly linear.
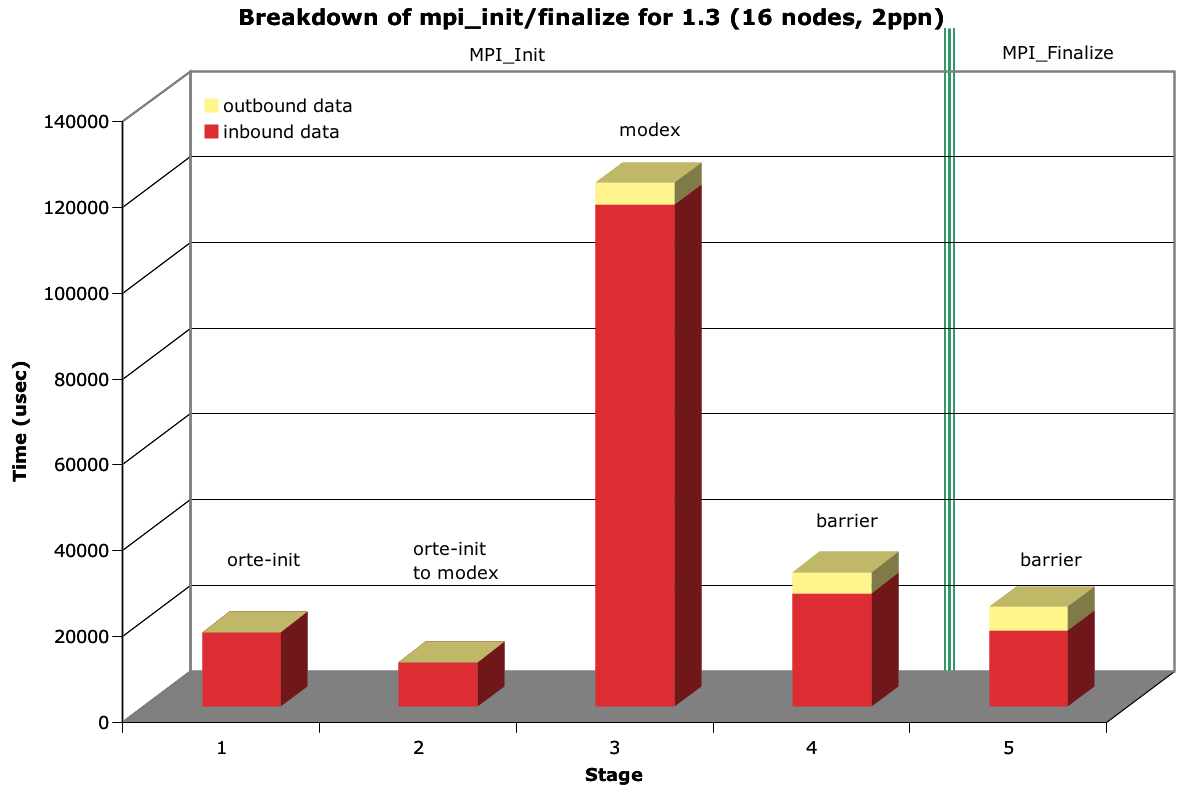
However, the launch behavior of MPI jobs remains worse-than-linear. Further analysis was done into the time consumed by specific elements in the MPI_Init procedure. The results are shown in the graphs entitled "Breakdown of mpi_init/finalize for 1.3" for 16 nodes, both 2ppn and 8ppn (see files RRZ-mpi-infin-2ppn.png and RRZ-1.3-minfin-8ppn.png). As the graphs show, the collection of inbound data on the modex remains the largest consumer of time during mpi_init, even using the revised method now in the trunk. This is due to a combination of message size and the (still) non-collective messaging scheme to collect that info.
Work continues to reduce the modex time through a series of steps that should be occurring over the next few weeks.
Per Pak (reference attached file PDF file):
The comparisons are done between trunk r17976 and v1.2.4. I've made approximately 10-15 runs for each data point, so the number ended up in a data point is actually an average of those 10-15 runs already.
To avoid any confusion when reading it, here's the slot-node conversion for those 16ppn runs:
| #procs | #nodes |
|---|---|
| 256 | 16 |
| 512 | 32 |
| 1024 | 64 |
| 2048 | 128 |
| 4096 | 256 |
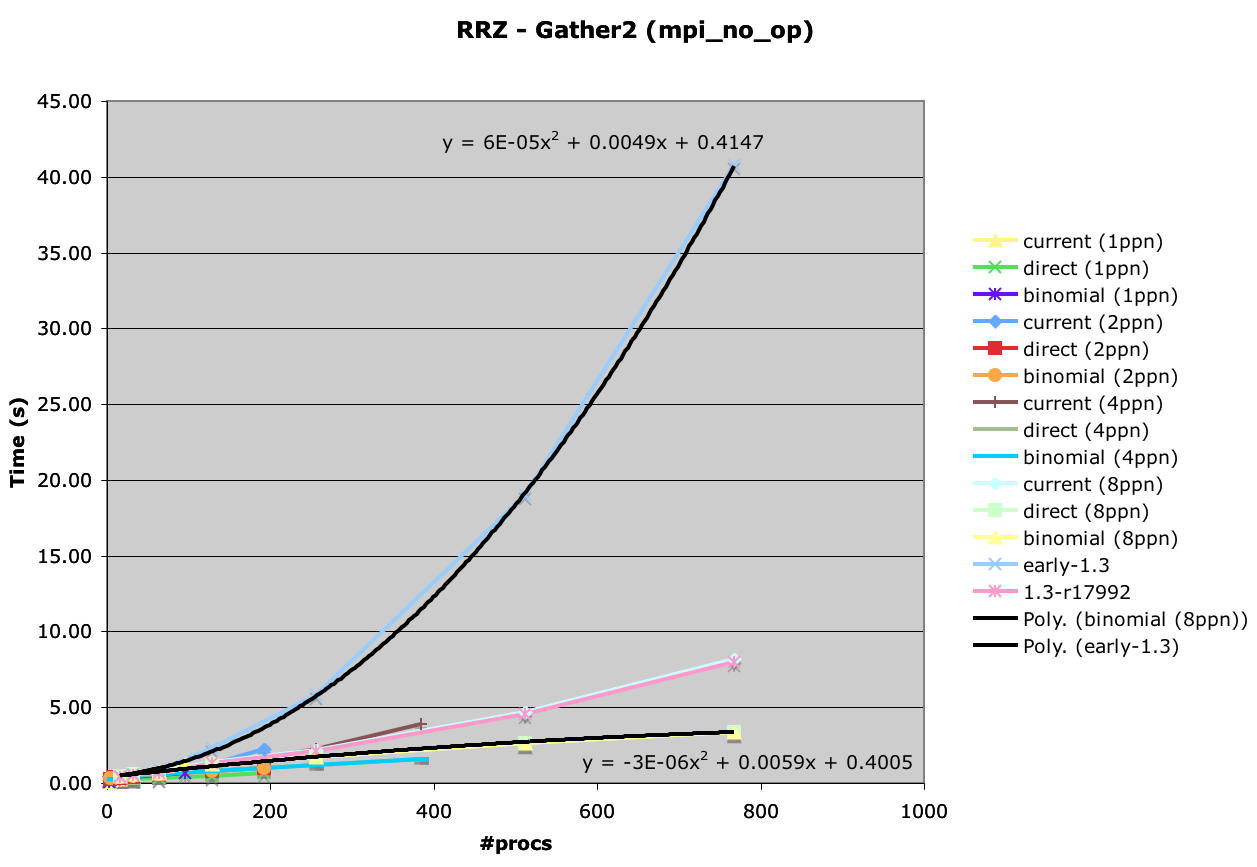
I have completed tests run on LANL's RRZ cluster using a branch that utilizes a binomial-tree based collective at the daemon level to execute the allgather (modex) and barrier operations. The attached graphs (RRZ-gather2-byproc.png and RRZ-gather2-bynode.png) show the results. I have included the line from 1.3 prior to the r17992 change in launch mechanism for comparison so you can see how far we have come.
As you can see, OMPI now exhibits a negative coefficient on the non-linear element of the curve. It appears that launch time may be turning asymptotic, but is definitely better-than-linear.
Some cleanup of the branch code is required prior to insertion into the trunk.
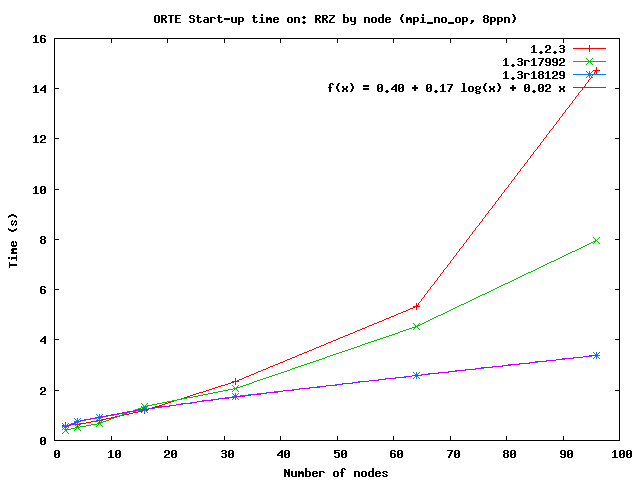
I ran the latest trunk (r18129) against the 1.2.3 and r17992 versions to see how much we have progressed. The attached graphs (RRZ-123-17992-18129-bynode.png and RRZ-123-17992-18129-byproc.png) illustrate the results.
With some help from David Daniel on gnuplot, we also fit these plots to a variety of functions. The best fit to the r18129 data came with a log/linear combination (see RRZ-history-bynode-png and RRZ-history-byproc.png).
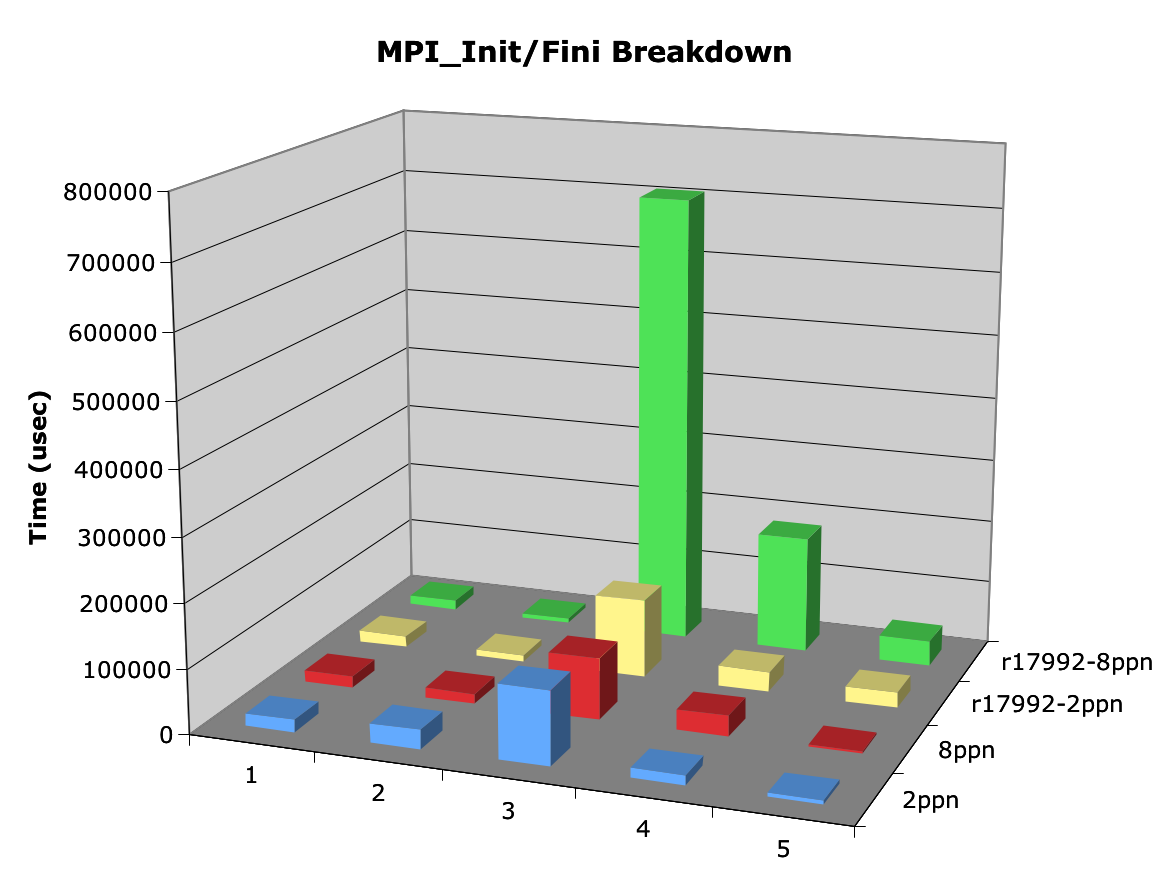
I also ran some timing data to see how things have changed internally to MPI_Init/Finalize. The new method of daemon-based collectives isn't amenable to the same inbound/outbound communication breakdown, so I instead compared total time to complete each phase (see graph RRZ-brkdn-17992-18129.png). As you can see, the modex has decreased significantly - but is still the largest consumer of time.
There are a few improvements still in the pipeline, including a reduction in the modex message size (remember, all this data is for IB interconnect). After that, I would expect the next major improvement to come in the 1.4 release (enter the trunk this summer).