Monitoring
This document outlines the process we use to collect metrics from our clusters on Google Cloud Engine and how to restart the relevant pods in the event they break in some way.
Note: the monitoring setup is a one time event that should only be done again in the event of failure or breakage
Everything on our cluster is monitored via Prometheus, and more specifically the kube-prometheus setup used for kubernetes clusters.
Here is the official workflow for Prometheus: 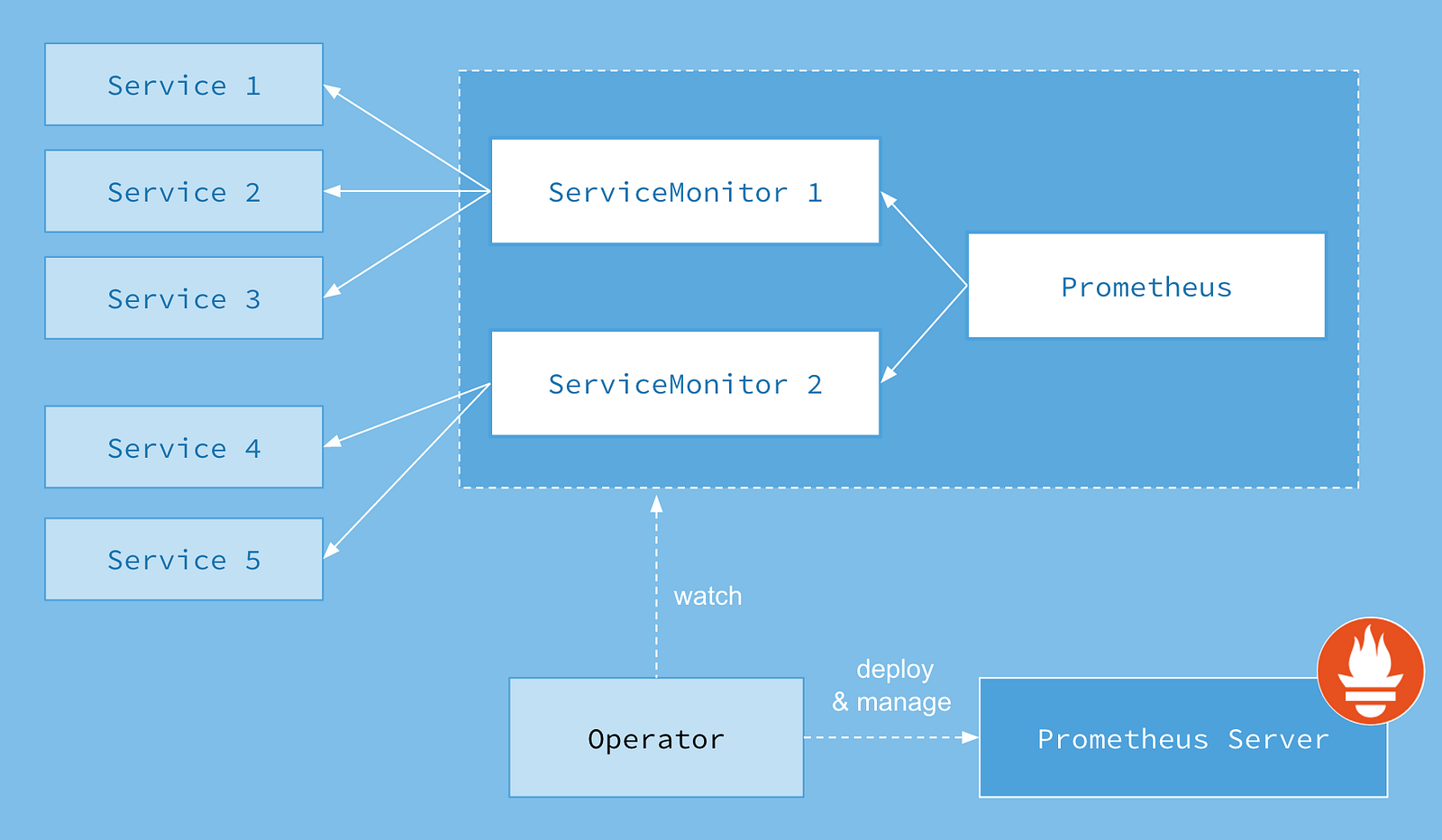
In the above picture there are a number of different components. In short, Prometheus uses service monitors to scrape metrics from all services on the cluster and holds them for a set amount of time. The operator is built on a framework used to package and deploy applications to kubernetes clusters, more information on operators can be found here, but it's not required to understand how Prometheus interacts with the cluster.
This gives us all we need to collect data and store it, but not a good way of making use of any of that data. That is handled via various Data vizualisation tools.
There are a number of ways to view the data Prometheus collects, the ones we make use of are: the Prometheus web UI, and Grafana. The Prometheus web UI is a simple tool that allows you to create queries on various metrics, view results in simple graphs, and view things like data targets (which is where all your data comes from), rules, and alerts (alerts will be explained later).
Grafana is a tool that allows to create dashboards and organise our data, and gives a much wider range of options when it comes to creating graphs and charts. It uses the same query language as the Prometheus web UI for collecting data, making it much simpler to switch between the web UI and Grafana.
In the monitoring folder in cluster-setup in the deploy app-engine repo. This folder contains all the configuration required to get Prometheus and Grafana onto our clusters, but they will need to be exposed manually.
- To do this, first find thet file named
prometheus-prometheus.yamland change the following line:
externalUrl: "https://{CLUSTER}-aimmo.codeforlife.education/prometheus"by replacing the word {CLUSTER} with either dev/staging/default depending on which cluster you are applying the manifests to.
- Next we need to repeat this step for the
alertmanager-alertmanager.yamlfile, again finding the the line:
externalUrl: "https://{CLUSTER}-aimmo.codeforlife.education/alertmanager"and replacing {CLUSTER} with either dev/staging/default depending on which cluster you're workking with.
- Now we need to look for files named:
monitoring-ingress.yaml&grafana-ingress.yaml. In both files there will be a line that looks like this:
- host: "https://{CLUSTER}-aimmo.codeforlife.education"Again you need to replace {CLUSTER} with either dev/staging/default depending on which cluster you're working on.
- After that, look for the
grafana-ini-configmap.yamlfile, this contains the main config file used to setup Grafana. inside the[server]header, look for the lines:
domain = {CLUSTER}-aimmo.codeforlife.education
...
root_url = https://{CLUSTER}-aimmo.codeforlife.education/grafana/and once again replace {CLUSTER} with either dev/staging/default.
- Next, you need to go onto the Kubernetes Engine section of our Google cloud console dashboard, then go into services and look for the
aimmo-ingressfor the cluster you're working on. It should be near to, or at the top of the list of services.
Click on the ingress to open up its details, then click "EDIT". You should see something like this:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx
kubernetes.io/ingress.global-static-ip-name: dev-aimmo-ingress
...Now add this line into the annotations section:
nginx.org/mergeable-ingress-type: masterThis is needed because we make use of multiple ingress files but you are only allowed a single ingress per host. For more information see the following example here.
- Finally, should be able to apply these manifests to the cluster you're working with.
To do this, run kubectl create -f monitoring/ || true, if prometheus does not exist on that cluster at all. If the manifests have already been applied before, use: kubectl apply -f monitoring/ || true and this will update the existing manifests and reset all the relevant components. You can use kubectl delete -f monitoring/ || true if you need to remove our monitoring for whatever reason (at present this will also destroy all data). You need to be in the same directory as the monitoring folder to run these commands.
Note: kubectl needs to be configured to work with the GCloud cluster for this method to work
Below are some issues you may encounter when setting up Prometheus and Grafana on any of the clusters.
If when you go to https://CLUSTER_URL/grafana all you see is a mostly blank page containing some text, this means the ingress isn't configured quite right so it's not exposing all the styles. Below are some examples for working configs for the grafana-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: grafana-ingress
namespace: monitoring
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /$1
nginx.org/mergeable-ingress-type: minion
spec:
rules:
- host: staging-aimmo.codeforlife.education
http:
paths:
- backend:
serviceName: grafana
servicePort: 3000
path: /grafana/?(.*)apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: grafana-ingress
namespace: monitoring
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /
nginx.org/mergeable-ingress-type: minion
spec:
rules:
- host: staging-aimmo.codeforlife.education
http:
paths:
- backend:
serviceName: grafana
servicePort: 3000
path: /grafana