Entwickler:innen Doku
Dieses Dokument soll Entwickler:innen als Einstieg in die Weiterentwicklung des MDM dienen. Es gibt dafür einen Überblick über die folgenden Punkte:
- Was macht das MDM eigentlich?
- Welche Komponenten sind weiterzuentwickeln?
- Welche Komponenten sind für den Betrieb relevant?
In diesem Dokument werden weitere Dokumente verlinkt, die einen höheren Detaillierungsgrad haben und daher auch gelesen werden sollten.
Das MDM (MetaDataManagement) verwaltet und veröffentlicht die Metadaten zu den Forschungsdaten (Scientific-Use-Files (SUFs) und Campus-Use-Files (CUFs), sowie Skripte), die das FDZ (Forschungsdatenzentrum) Studierenden und Forschenden zur Verfügung stellt. Es unterscheidet dabei im wesentlichen die folgenden Benutzerrollen:
- Public User (Studierende und Forschende, die Zugang zu Forschungsdaten des FDZs beantragen wollen)
- Data Provider (Forschende, die ihre Forschungsdaten im FDZ abgeben und der wissenschaftlichen Community zur Sekundärnutzung bereitstellen wollen)
- Publisher (FDZ-Mitarbeiter*innen, die die Forschungsdaten kuratieren und für die Öffentlichkeit freigeben)
- Admin (FDZ-Mitarbeier*innen, die die Benutzer- und Rollenverwaltung machen)
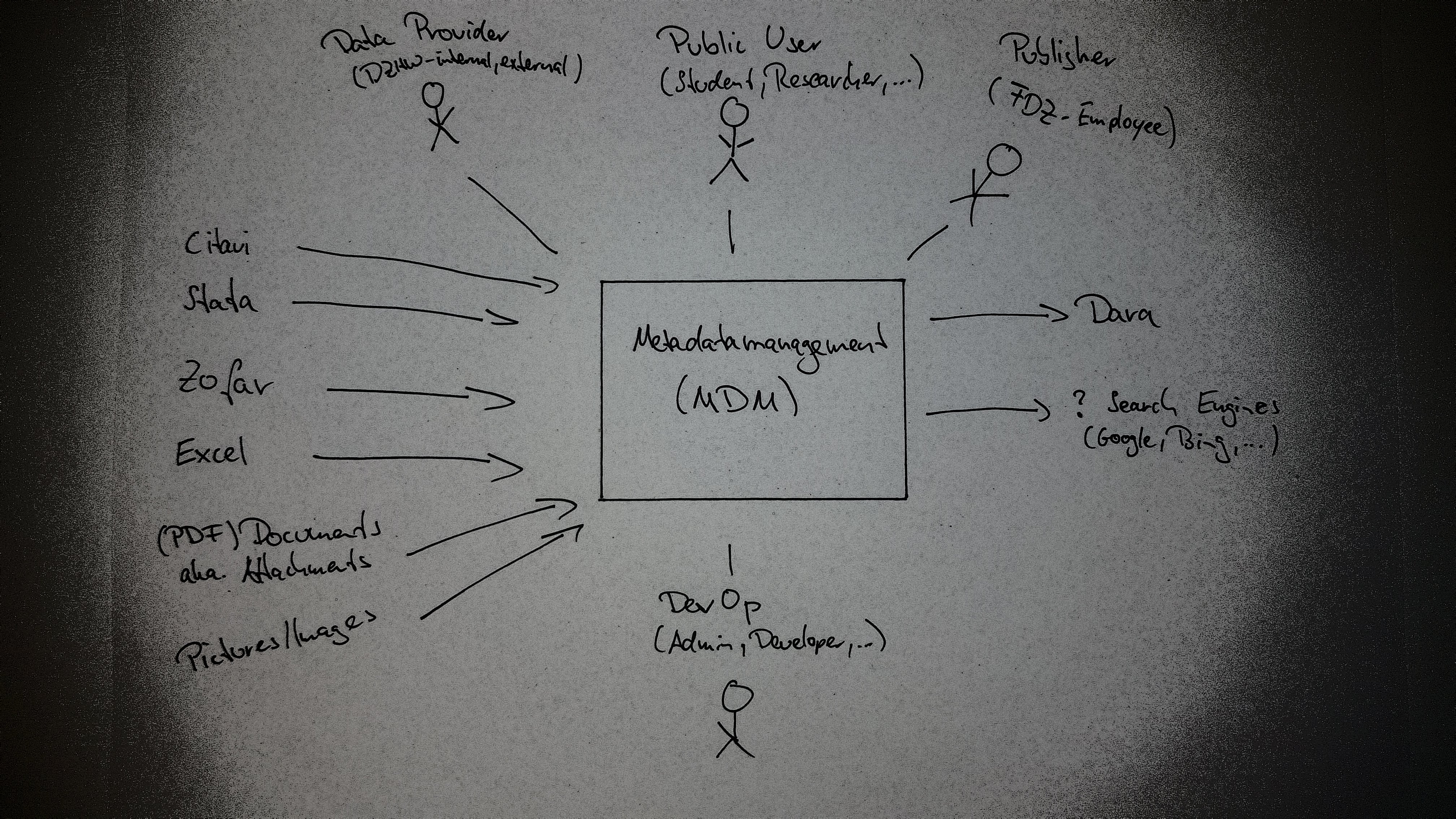
Public User können veröffentlichte Forschungsdaten (Datenpakete und Analysepakete) im MDM suchen und in ihren Warenkorb legen. Der Beantragungsprozess findet dann im DLP (Dienstleistungsportal) statt, welches sich den Warenkorb über die Order-API des MDM holt.
Data Provider und Publisher müssen sich im MDM anmelden. Sie arbeiten gemeinsam in einem Datenaufbereitungsprojekt daran, die Metadaten zu den Forschungsdaten zu erfassen, um sie zu veröffentlichen.
Das folgende Diagramm gibt einen Überblick über die Domänenobjekte und ihre Relationen.
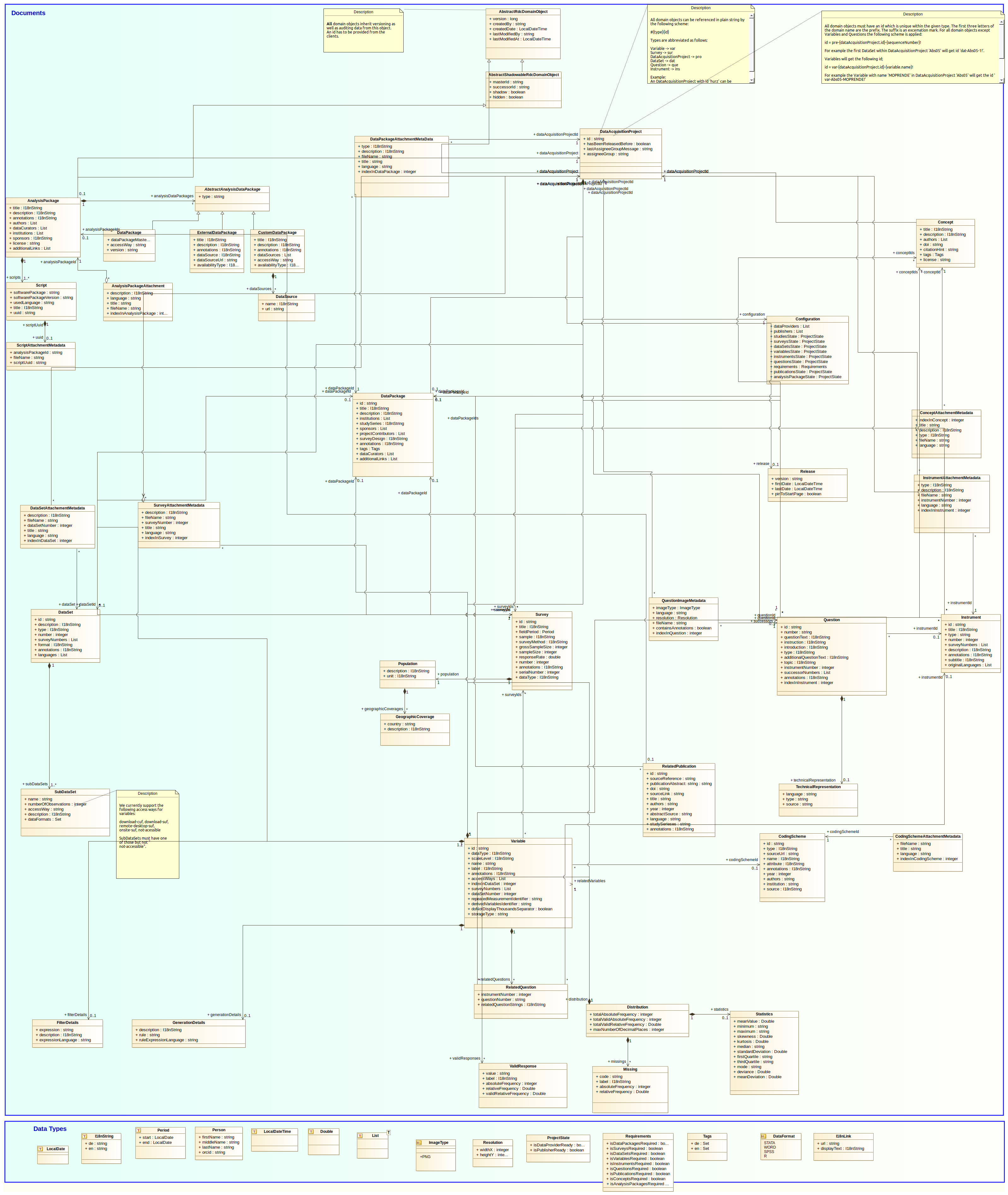
Eine aus dem Code generierte JavaDoc kann hier gefunden werden. Nachfolgend werden die Domänenobjekte erläutert.
Datenaufbereitungsprojekte oder kurz Projekte werden durch angemeldete Publisher in der Seitenleiste des Clients angelegt und im Projektcockpit bearbeitet.
Projekte - und damit die in dem Projekt angelegten Metadaten - können entweder der Gruppe der Publisher oder der Gruppe der Data Provider zur Bearbeitung zugewiesen sein. Das Zuweisen zur jeweils anderen Projektgruppe ist im Projektcockpit möglich. Ein Projekt dient entweder der Veröffentlichung eines Datenpakets und seiner Metadaten, oder der Veröffentlichung eines Analysepakets und seiner Metadaten. Mit der Veröffentlichung einer Version größer oder gleich 1.0.0 werden die Metadaten auch über da|ra veröffentlicht und dabei wird eine DOI (Digital Object Identifier) zu dem entsprechenden Datenpaket oder Analysepaket registriert. Details dazu finden sich hier: https://github.com/dzhw/metadatamanagement/wiki/Metadata-and-DOI-registration-at-dara
Bei der Veröffentlichung einer Projektversion entstehen "Schattenkopien" der aktuellen Mastermetadaten. Das bedeutet, dass jedes Objekt des Projektes (Datenpaket, Erhebungen, Instrumente, Fragen, Datensätze, Variablen Analysepaket, ... und Attachments) kopiert wird. Damit wird der Zustand des Projektes zu diesem Zeitpunkt festgehalten. Schattenkopien kennen die optionale ID ihrer Nachfolgerversion (successorId) und die ID ihres Masters (masterId). Masterobjekte erkennt man daran, dass id und masterId übereinstimmen. Die Schattenkopien haben eine id der Form {masterId}-{version}. Schattenkopien mit Version größer oder gleich 1.0.0 können nicht gelöscht werden, da bei da|ra eine öffentlich zugängliche Landing Page (die öffentliche Datenpaket- bzw. Analysepaketdetailseite) registriert wurde. Sobald eine Nachfolgeversion existiert, können Projektversionen jedoch im Projektcockpit versteckt werden. Damit sind sie nicht mehr über den Warenkorb beantragbar.
Projekte können gelöscht werden, solange noch keine Version veröffentlicht wurde. Auf den Stages local, dev und test können Projekte auch nach Veröffentlichung gelöscht werden. Beim Löschen eines Projektes werden alle in dem Projekt enthaltenen Metadaten und Attachments gelöscht.
Der Code für das Projektmanagement befindet sich in den folgenden fachlichen Slices:
- Backend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/java/eu/dzhw/fdz/metadatamanagement/projectmanagement
- Frontend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/webapp/scripts/dataacquisitionprojectmanagement
1.2 Datenpakete
Datenpakete, auch SUFs (Scientific-Use-Files) genannt, beschreiben die Daten, die das FDZ der wissenschaftlichen Community neben Analysepaketen zur Verfügung stellt. Public User können veröffentlichte Datenpakete über den Warenkorb im MDM beantragen.
Ein Projekt enthält maximal ein Datenpaket und seine untergeordneten Domänenobjekte (Erhebungen, Datensätze, Variablen, Instrumente und Frage). Datenpakete werden mit Javers versioniert. Sie können Attachments (z.B. den Daten- und Methodenbericht) haben, welche in GridFS gespeichert werden und deren Metadaten ebenfalls mit Javers versioniert werden. Die Datenpaketübersicht ist eines dieser Attachments, welches im Gegensatz zu den anderen automatisiert mit dem dzhw/report-task erzeugt werden kann. Manche Felder von Datenpaketen (z.B. description) können Markdown zur Formatierung beinhalten.
Die Erfassung der Datenpakete und ihrer Attachments geschieht über das Projektcockpit in einer Eingabemaske. Bei Veröffentlichung des Projektes entstehen, wie unter 1.1 beschrieben, Schattenkopien. Zusätzlich wird bei Versionen größer oder gleich 1.0.0 eine DOI zu dem Datenpakt registriert (siehe auch 1.1).
Der Code für das Datenpaketmanagement befindet sich in den folgenden fachlichen Slices:
- Backend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/java/eu/dzhw/fdz/metadatamanagement/datapackagemanagement
- Frontend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/webapp/scripts/datapackagemanagement
1.2.1 Erhebungen
Erhebungen beschreiben einen Zeitraum in dem die Daten des Datenpakets beispielsweise mit einer Onlinebefragung erhoben wurden.
Zu einem Datenpaket können mehrere Erhebungen gehören. Erhebungen werden mit Javers versioniert. Sie können Attachments haben, welche in GridFS gespeichert werden und deren Metadaten ebenfalls mit Javers versioniert werden. Zusätzlich können sie Bilder haben, welche die Rücklaufrate im Erhebungszeitraum darstellen und ebenfalls in GridFS gespeichert werden. Manche Felder von Erhebungen (z.B. description) können Markdown zur Formatierung beinhalten.
Die Erfassung der Erhebungen und ihrer Attachments geschieht über das Projektcockpit in einer Eingabemaske. Bei Veröffentlichung des Projektes entstehen, wie unter 1.1 beschrieben, Schattenkopien.
Der Code für das Erhebungsmanagement befindet sich in den folgenden fachlichen Slices:
- Backend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/java/eu/dzhw/fdz/metadatamanagement/surveymanagement
- Frontend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/webapp/scripts/surveymanagement
1.2.2 Instrumente
Instrumente, oder auch Erhebungsinstrumente, beschreiben das Werkzeug, mit dem die Daten des Datenpakets erhoben wurden. Ein Beispiel hierfür ist ein (Papier)-Fragebogen.
Ein Instrument kann in mehreren Erhebungen verwendet worden sein und mehrere Instrumente können in einer Erhebung verwendet worden sein. Instrumente werden mit Javers versioniert. Sie können Attachments haben, welche in GridFS gespeichert werden und deren Metadaten ebenfalls mit Javers versioniert werden. Manche Felder von Instrumenten können Markdown zur Formatierung beinhalten.
Die Erfassung der Instrumente und ihrer Attachments geschieht über das Projektcockpit in einer Eingabemaske. Bei Veröffentlichung des Projektes entstehen, wie unter 1.1 beschrieben, Schattenkopien.
Der Code für das Erhebungsmanagement befindet sich in den folgenden fachlichen Slices:
- Backend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/java/eu/dzhw/fdz/metadatamanagement/instrumentmanagement
- Frontend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/webapp/scripts/instrumentmanagement
1.2.3 Fragen
Fragen können Teil eines Instrumentes (z.B. Online- oder Papierfragebogen) sein.
Ein Instrument kann mehrere Fragen enthalten. Eine Frage gehört immer zu genau einem Instrument. Fragen können mehrere Bilder haben, auf welchen die Frage im Orginalfragebogen zu sehen ist. Diese Bilder werden in GridFS gespeichert.
Die Erfassung der Fragen und ihrer Bilder geschieht über Upload der Fragemetadaten im Projektcockpit. Die Erstellung der hochladbaren Fragemetadaten passiert mit dem R-Paket dzhw/questionMetadataPreparation. Der genaue Prozess ist hier beschrieben:
https://github.com/dzhw/FDZ_Allgemein/wiki/Fragen-(Questions)
Bei Veröffentlichung des Projektes entstehen, wie unter 1.1 beschrieben, Schattenkopien der Fragen und ihrer Bilder.
Der Code für das Fragenmanagement im MDM befindet sich in den folgenden fachlichen Slices:
- Backend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/java/eu/dzhw/fdz/metadatamanagement/questionmanagement
- Frontend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/webapp/scripts/questionmanagement
1.2.4 Datensätze
Datensätze beschreiben die analysierbaren Dateien (z.B. Stata-Files), die mit einem Datenpaket der Datennutzer:in zur Verfügung gestellt werden.
Ein Datensatz kann Daten aus mehreren Erhebungen enthalten und aus einer Erhebung können mehrere Datensätze resultieren. Datensätze werden mit Javers versioniert. Sie können Attachments haben, welche in GridFS gespeichert werden und deren Metadaten ebenfalls mit Javers versioniert werden. Der Datensatzreport (aka Codebook oder Variablenreport) ist eines dieser Attachments, welches automatisiert mit dem dzhw/report-task erzeugt werden kann. Manche Felder von Datensätzen können Markdown zur Formatierung beinhalten.
Die Erfassung der Datensätze und ihrer Attachments geschieht über das Projektcockpit in einer Eingabemaske (siehe auch hier). Bei Veröffentlichung des Projektes entstehen, wie unter 1.1 beschrieben, Schattenkopien.
Der Code für das Datensatzmanagement befindet sich in den folgenden fachlichen Slices:
- Backend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/java/eu/dzhw/fdz/metadatamanagement/datasetmanagement
- Frontend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/webapp/scripts/datasetmanagement
1.2.5 Variablen
Variablen beschreiben die Spalten in tabellarischen Datensätzen.
Ein Datensatz kann mehrere Variablen beinhalten. Eine Variable gehört dabei zu genau einem Datensatz und wurde in mehreren Erhebungen mit potentiell mehreren Fragen gemessen.
Die Erfassung der Variablen geschieht über Upload der Variablenmetadaten im Projektcockpit. Die Erstellung der hochladbaren Variablenmetadaten passiert mit dem R-Paket dzhw/variableMetadataPreparation. Der genaue Prozess ist hier beschrieben:
https://github.com/dzhw/FDZ_Allgemein/wiki/Variablen-(Variables)
Der Code für das Variablenmanagement im MDM befindet sich in den folgenden fachlichen Slices:
- Backend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/java/eu/dzhw/fdz/metadatamanagement/variablemanagement
- Frontend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/webapp/scripts/variablemanagement
1.3 Konzepte
Konzepte beschreiben etwas, dass nicht direkt gemessen werden kann, wozu es aber ein Modell gibt, mit dem es gemessen werden kann. Beispielsweise ist das Konzept "Persönlichkeit" mit dem Big Five -Modell messbar.
Ein Konzept kann mit mehreren Fragen oder Instrumenten gemessen worden sein. Eine Frage kann mehrere Konzepte messen. Ein Instrument kann ebenfalls mehrere Konzepte messen. Konzepte werden mit Javers versioniert. Sie können Attachments haben, welche in GridFS gespeichert werden und deren Metadaten ebenfalls mit Javers versioniert werden. Manche Felder von Konzepten können Markdown zur Formatierung beinhalten.
Die Erfassung der Konzepte und ihrer Attachments geschieht über das Projektcockpit in einer Eingabemaske (siehe auch hier). Da Konzepte projektübergreifend sind, gibt es von ihnen keine Schattenkopien. Sie werden in Fragen oder Instrumenten eines Projektes referenziert und damit sichtbar sobald ein solches Projekt veröffentlicht wird.
Der Code für das Konzeptmanagement befindet sich in den folgenden fachlichen Slices:
- Backend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/java/eu/dzhw/fdz/metadatamanagement/conceptmanagement
- Frontend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/webapp/scripts/conceptmanagement
1.4 Publikationen
Publikationen beschreiben Artikel oder andere Veröffentlichungen zu unseren Daten- oder Analysepaketen.
Eine Publikation muss zu mindestens einem Datenpaket oder einem Analysepaket gehören. Aus einem Datenpaket können mehrere Publikationen resultieren. Aus einem Analysepaket kann maximal eine Publikation resultieren. Manche Felder von Publikationen können Markdown zur Formatierung beinhalten.
Die Erfassung der Publikationen geschieht in Citavi. Der daraus resultierende Excelexport kann über die GUI hochgeladen werden. Der Prozess ist hier beschrieben: https://github.com/dzhw/fdz_related_publications/wiki
https://github.com/dzhw/metadatamanagement/wiki/Metadata-Import#related-publication-import
Da Publikationen projektübergreifend sind, gibt es von ihnen keine Schattenkopien. Sie referenzieren in Datenpakete oder Analysepakete von Projekten und werden damit sichtbar sobald ein solches Projekt veröffentlicht wird.
Der Code für das Publikationsmanagement befindet sich in den folgenden fachlichen Slices:
- Backend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/java/eu/dzhw/fdz/metadatamanagement/relatedpublicationmanagement
- Frontend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/webapp/scripts/relatedpublicationmanagement
1.5 Analysepakete
Analysepakete, auch Skripte genannt, werden neben Datenpaketen der wissenschaftlichen Community vom FDZ zur Verfügung stellt. Public User können veröffentlichte Analysepakete über den Warenkorb im MDM beantragen.
Ein Projekt enthält maximal ein Analysepaket. Analysepakete werden mit Javers versioniert. Sie können Attachments haben, welche in GridFS gespeichert werden und deren Metadaten ebenfalls mit Javers versioniert werden. Ein Analysepaket kann mehrere Skripte enthalten, zu welchen ebenfalls jeweils ein Attachment gehören kann. Manche Felder von Analysepaketen (z.B. description) können Markdown zur Formatierung beinhalten.
Die Erfassung der Analysepakete und ihrer Attachments geschieht über das Projektcockpit in einer Eingabemaske. Bei Veröffentlichung des Projektes entstehen, wie unter 1.1 beschrieben, Schattenkopien. Zusätzlich wird bei Versionen größer oder gleich 1.0.0 eine DOI zu dem Analysepaket registriert (siehe auch 1.1).
Der Code für das Analysepaketmanagement befindet sich in den folgenden fachlichen Slices:
- Backend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/java/eu/dzhw/fdz/metadatamanagement/analysispackagemanagement
- Frontend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/webapp/scripts/analysispackagemanagement
Public User können sich im MDM einen Warenkorb bestehend aus Datenpaketen und/oder Analysepaketen zusammenstellen. Dieser Warenkorb wird beim ersten Klick auf "Kostenlos beantragen" als Order gespeichert. Die User werden anschließend mit der Order-ID an das DLP (Dienstleistungsportal) weitergeleitet. Das DLP holt sich dann über die REST-API die entsprechende Order vom MDM, so dass der Beantragungsprozess im DLP starten kann.
Der Code für das Ordermanagement befindet sich in den folgenden fachlichen Slices:
- Backend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/java/eu/dzhw/fdz/metadatamanagement/ordermanagement
- Frontend: https://github.com/dzhw/metadatamanagement/tree/development/src/main/webapp/scripts/ordermanagement

In diesem Abschnitt werden alle Komponenten beschrieben, die für das MDM entwickelt wurden und die somit für die Weiterentwicklung relevant sind. Das folgende Bild gibt eine grobe Übersicht.
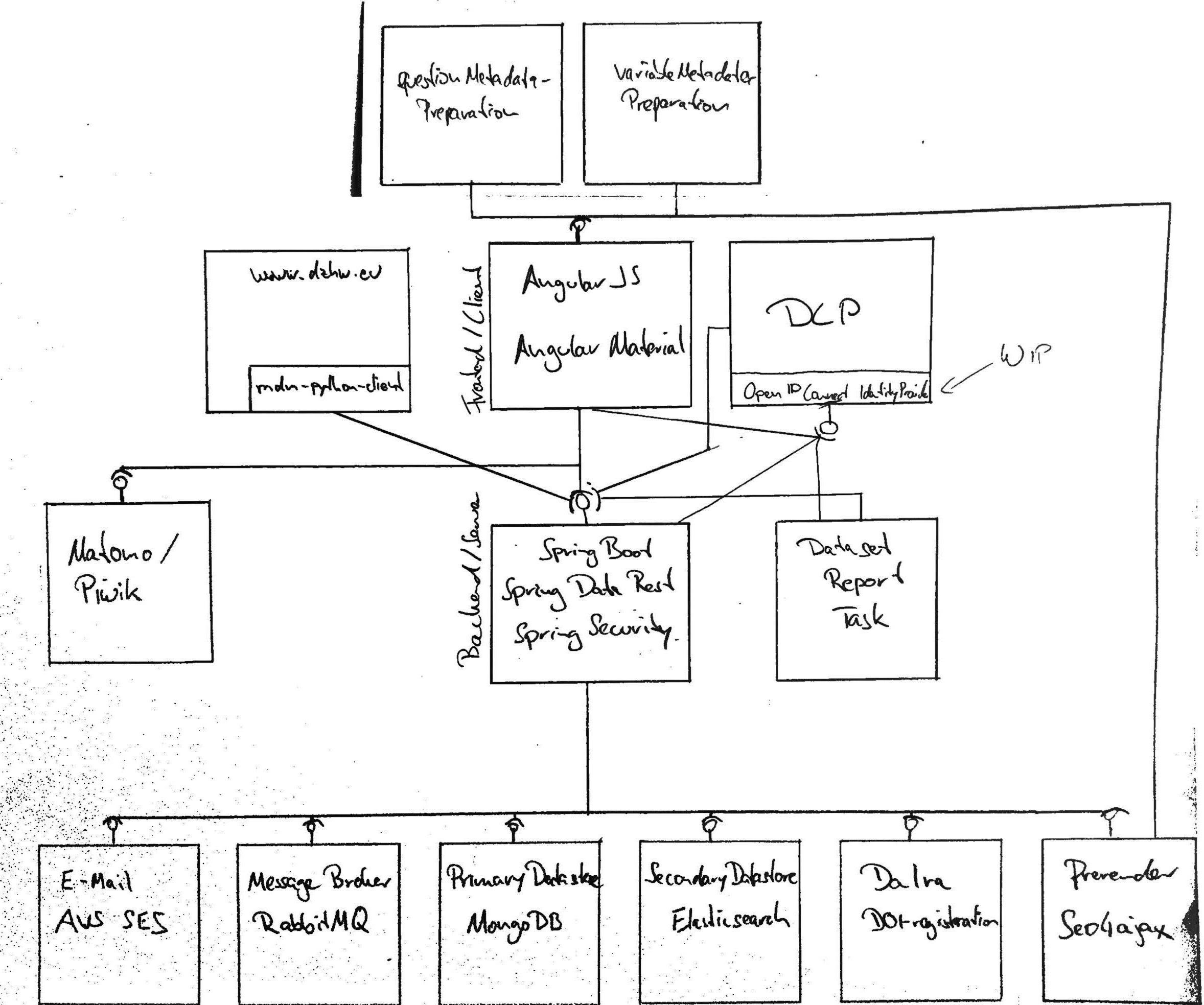
Die folgenden Repos enthalten den Code der eigenentwickelten Komponenten.
Das Repo dzhw/metadatamanagement ist das Hauptrepo des MDM und enthält sowohl das Frontend als auch das Backend des MDMs:
- Frontend (AngularJS, AngularJS Material): https://github.com/dzhw/metadatamanagement/tree/development/src/main/webapp
- Backend (Spring Boot, Spring MVC, Spring Security, Spring Data Mongo): https://github.com/dzhw/metadatamanagement/tree/development/src/main/java/eu/dzhw/fdz/metadatamanagement
In den Issues findet sowohl das Management der Scrum Backlog Items, als auch das Tracking der Bugs aller hier genannten Repos statt.
Die README beschreibt, welche Abhängigkeiten sich sowohl Frontend- als auch Backendentwickler auf ihrem Rechner installieren müssen, um das MDM weiterzuentwickeln.
GitHub Actions werden verwendet, um das Paket kontinuierlich zu testen und zu deployen. Jede Nacht werden End-to-End-Tests ausgeführt, die das Devsystem mit Hilfe des Robotframeworks und Saucelabs aus Benutzersicht testen. Der Code für die E2E-Tests ist hier zu finden: https://github.com/dzhw/metadatamanagement/tree/development/src/test/robotframework
Bei jedem Push von Commits werden durch GitHub Actions JUnit-Tests (Backend) und Jasmine-Tests (Frontend) ausgeführt. Diese sind hier zu finden:
- Backend: https://github.com/dzhw/metadatamanagement/tree/development/src/test/java
- Frontend: https://github.com/dzhw/metadatamanagement/tree/development/src/test/javascript
Abnahmetests durch FDZ-Mitarbeiter:innen finden auf dem Testsystem statt.
Grundsätzlich soll der Commit Flow von neuen Features wie folgt sein:
feature-branch -> development -> test -> release -> master
Kleinere Änderungen, von denen klar ist, dass sie bis zum Sprintende fertig werden, können auch direkt im development-Branch entwickelt werden. Der Branch master ist geschützt, das heißt, dass nur über Pull Requests Commits in diesen Branch eingespielt werden können.
Die Commits auf den Branches development, test und master werden durch GitHub Actions automatisch zur Amazon Container Registry (ECR) mit entsprechenden Tags (z.B. master=latest-prod) gepusht. Damit stehen sie dem entsprechenden Fargate Cluster (siehe 3.1) zur Verfügung. Da die aktiven Tasks des Clusters beendet werden und mit dem jeweils aktuellsten Containerimage neu gestartet werden, sind die Änderungen auf dem entsprechenden Stage nach kurzer Downtime live.
Dokumentation für Benutzer:innen, die nicht beim FDZ arbeiten, wird durch readthedocs zur Verfügung gestellt. Die Quellen sind hier zu finden: https://github.com/dzhw/metadatamanagement/tree/development/docs Zusätzlich gibt es noch Benutzerdokumentation für FDZ-Mitarbeiter:innen, welche hier zu finden ist: https://github.com/dzhw/FDZ_Allgemein/wiki/Strukturierte-Metadaten
Snyk und dependabot stellen zwar Pull Requests für Updates zu den verwendeten Bibliotheken, dennoch sollten regelmäßig die Maven und Node Dependencies auf Updates überprüft werden:
mvn versions:display-dependency-updates
mvn versions:display-property-updates
npm outdated
Für Spring Boot Updates bietet es sich an Spring Boot auf Twitter zu folgen:
https://twitter.com/springboot. Updates sollten erst auf dem development-System eingespielt werden und die nächtlichen E2E-Tests sollten abgewartet werden bevor Updates produktiv gehen.
Das Repo dzhw/metadatamanagement-modelio enthält das Domänenmodell (als UML-Klassendiagramm). Dieses wurde mit Modelio 3.4.1 erstellt, welches nur unter Java 1.8 läuft.
2.1.2 dzhw/fdz-paginator
Das Repo dzhw/fdz-paginator enthält einen mit AngularJS und AngularJS Material geschriebenen Paginator, welcher vom MDM verwendet wird, um Suchergebnisse seitenweise darzustellen.
Github Actions werden verwendet, um das Paket kontinuierlich zu testen. Beim Release einer neuen Version (Tag mit prefix "v" wird gepusht) wird das AngularJS Modul automatisch von GitHub Actions bei NPM veröffentlicht.
2.2 dzhw/report-task
Das Repo dzhw/report-task (früher dzhw/dataset-report-task) enthält den Code für den containerisierten Spring Cloud Task der Datensatzreports und Datenpaketübersichten erzeugt. Angemeldete MDM User können Taskinstanzen auf der Datenpaketdetailseite bzw. auf der Datensatzdetailseite durch Klick auf den PDF-Button starten. Das MDM startet dann über die AWS Fargate API eine Taskinstanz. Der Task befüllt anschließend über die MDM-API ein Latex-Template und erzeugt daraus ein PDF, was dann über die MDM-API hochgeladen wird. Bei Beendigung des Tasks versendet das MDM eine E-Mail an den MDM User, der den Task gestartet hat.
Die README beschreibt, welche Abhängigkeiten sich Entwickler auf ihrem Rechner installieren müssen, um den Task weiterzuentwickeln.
Die Commits auf den Branches development, test und master werden durch GitHub Actions automatisch zur Amazon Container Registry (ECR) mit entsprechenden Tags (z.B. master=latest-prod) gepusht. Damit stehen sie den entsprechenden MDM Stages zur Verfügung.
Grundsätzlich soll der Commit Flow von neuen Features wie folgt sein:
feature-branch -> development -> test -> release -> master
Kleinere Änderungen, von denen klar ist, dass sie bis zum Sprintende fertig werden, können auch direkt im development-Branch entwickelt werden. Der Branch master ist geschützt, das heißt, dass nur über Pull Requests Commits in diesen Branch eingespielt werden können.
Das Repo dzhw/variableMetadataPreparation enthält den Code für ein R-Paket, welches im geschützten Bereich genutzt wird, um aus Stata-Datensätzen Variablen-Metadaten zu extrahieren, die dann über den MDM-Client im Projektcockpit hochgeladen werden können.
Die README beschreibt, welche Abhängigkeiten sich Entwickler auf ihrem Rechner installieren müssen, um das R-Paket weiterzuentwickeln. Zusätzlich wird hier beschrieben, wie das Deployment in den geschützten Bereich funktioniert.
Github Actions werden verwendet, um das Paket kontinuierlich zu testen und um ein Build Artifact zusammenzustellen, welches in den geschützten Bereich kopiert werden kann. Wenn es neuere Versionen von den in der DESCRIPTION festgelegten R-Paketen gibt, schlägt der Build aktuell fehl. Dann müssen die aktuellen Versionen in die DESCRIPTION eingetragen werden.
Der Prozess aus Benutzersicht ist hier dokumentiert: https://github.com/dzhw/FDZ_Allgemein/wiki/Variablen-(Variables)
Das Repo dzhw/questionMetadataPreparation enthält den Code für ein R-Paket, welches genutzt wird, um Frage-Metadaten zu erzeugen, die dann über den MDM-Client im Projektcockpit hochgeladen werden können.
Die README beschreibt, welche Abhängigkeiten sich Entwickler auf ihrem Rechner installieren müssen, um das R-Paket weiterzuentwickeln. Zusätzlich wird hier beschrieben, wie das Deployment auf die Rechner der FDZ-Mitarbeiter:innen funktioniert.
Github Actions werden verwendet, um das Paket kontinuierlich zu testen. Wenn es neuere Versionen von den in der DESCRIPTION festgelegten R-Paketen gibt, schlägt der Build aktuell fehl. Dann müssen die aktuellen Versionen in die DESCRIPTION eingetragen werden.
Der Prozess aus Benutzersicht ist hier dokumentiert: https://github.com/dzhw/FDZ_Allgemein/wiki/Fragen-(Questions)
Das Repo dzhw/mdm-python-client enthält den Code für ein Python-Paket, welches von der DZHW-Website (CMS Zope) genutzt, um veröffentlichte Datenpakete anzuzeigen. Der Client nutzt die MDM-API um sich die entsprechenden Metadaten zu holen.
Github Actions werden verwendet, um das Paket kontinuierlich zu testen.
Die README beschreibt, wie der Client zu installieren und zu verwenden ist. Die Readme ist auch bei readthedocs zu finden.
In diesem Abschnitt werden alle Komponenten beschrieben, die für den Betrieb des MDM relevant sind. Das folgende Bild gibt einen groben Überblick über die Komponenten, die für den Betrieb bei AWS relevant sind.

Zu beachten ist:
- Aktuell wird ein OpenID Connect Identity Provider mit dem DLP realisiert. Dieser ist in der Übersicht nicht vorhanden.
- Der
dataset-report-taskheißt mittlerweilereport-task - Die folgenden Komponenten sind hier nicht abgebildet: Seo4Ajax, Google Search Console, Matomo, Uptimerobot
Eine Erläuterung der Systemarchitektur und wie es zu dieser gekommen ist, befindet sich hier.
Alle AWS Ressourcen des MDMs befinden sich in dem Account 347729458675 (dzhw-mdm-on-aws-pxxx7). Anmeldung in der AWS Console geschieht im Account 940499203403 (dzhw-user-management-pxxx1), weil hier das Identity und Accessmanagement gemacht wird. Anschließend muss man in die Rolle Admin (arn:aws:iam::347729458675:role/Admin) im MDM Account wechseln. Für die AWS CLI legt man sich am besten ein Profil mdm an, mit dem man in dem MDM Account arbeiten kann. Dieses wird auch von Terraform verwendet (~/.aws/config):
[default]
region = eu-central-1
output = json
[profile mdm]
region = eu-central-1
role_arn = arn:aws:iam::347729458675:role/Admin
source_profile = default
Das MDM besteht hauptsächlich aus drei Fargate (ECS) Clustern (jeweils einer für dev, test und prod) und einem Application Load Balancer, der das SSL-Offloading macht und je nach Domäne (dev.metadata.fdz.dzhw.eu, test.metadata.fdz.dzhw.eu, metadata.fdz.dzhw.eu und www.metadata.fdz.dzhw.eu) Anfragen an den Service metadatamanagement in dem jeweiligen Fargate Cluster weiterleitet. Der Service metadatamanagement besteht aus drei Taskinstanzen (sollte eine abstürzen, wird automatisch eine weitere gestartet), auf die die Anfragen Round-Robin verteilt werden. In der Taskdefinition (z.B. metadatamanagement-dev-web) wird festgelegt mit welchen Umgebungsvariablen und welchen Parametern (z.B. CPU, Memory) das Containerimage aus der AWS ECR instanziiert wird. Die Umgebungsvariablen enthalten dabei die Verbindungsdaten zu den benötigten externen Diensten (AWS SES, Scalegrid, elastic, CloudAMQP, da|ra).
Zusätzlich gibt es noch einen Service metadatamanagement-worker, der eine weitere Instanz des selben Containers enthält, der aber keine Webanfragen bekommt, sondern Hintergrundaufgaben erledigt. Dazu erhält dieser Container eine Taskdefinition (z.B. metadatamanagement-dev-worker) in der die Umgebungsvariable cf_instance_index=0 gesetzt wird. Die Webcontainer haben die Umgebungsvariable cf_instance_index=1.
Zusätzlich zu den genannten Containerinstanzen können zur Laufzeit noch Instanzen des Containerimages dzhw/report-task erzeugt werden. Diese Instanzen sind kurzlebig, erhalten keine HTTP-Anfragen und werden auch über eine Taskdefinition (z.B. report-task-dev) konfiguriert.
Die Firma tecracer ist unser AWS Reseller und schickt monatlich eine Rechnung über alle vom DZHW verwendeten Ressourcen. Diese Rechnung muss nach Aufforderung von der Buchhaltung aufgesplittet werden, damit die einzelnen Posten sachlich richtig gezeichnet werden können. Hier ein Beispiel:
- Rechnung
- Aufsplittung
- Kontakt zu tecracer über [email protected]
Alle AWS Ressourcen werden mit Terraform verwaltet. Das entsprechende Terraform Root Modul ist hier zu finden: https://github.com/dzhw/metadatamanagement/tree/development/terraform
Für den lokalen Start von Terraform mit terraform init muss ein Access Key als lokale Umgebungsvariable hinterlegt werden. Access Keys können für den Nutzer terraform über die IAM Konsole erstellt werden. Der terraform Nutzer verfügt über alle notwendigen Berechtigungen.
export AWS_ACCESS_KEY_ID="your access key id"
export AWS_SECRET_ACCESS_KEY="your access key"
Um terraform plan bzw. terraform apply ausführen zu können, muss in das lokale Verzeichnis noch folgende Datei kopiert werden, die die Zugangsdaten zu den externen Diensten, sowie andere sensible Daten enthält:
s3://metadatamanagement-private/sensitive_variables.tf
Das anschließende Ausführen von terraform plan führt die auszuführenden Änderungen in einer Übersicht auf. Mit terraform apply wird entweder der zuvor angelegte Plan ausgeführt oder ein neuer Plan erstellt und dieser ausgeführt. Die Ausführung muss bestätigt werden. Die Ausführung aktualisiert den terraform state und legt eine neue Version der sensitive_variables.tf im Bucket ab.
Der terraform state liegt hier:
s3://metadatamanagement-private/terraform.tfstate
Anschließend ist eine Aktualisierung der entsprechenden Aufgaben und ein Neustart der betreffenden Container erforderlich. Beides ist über den Amazon Elastic Container Service möglich.
MongoDB ist unser primärer Datenstore, d.h. die Domänenobjekte und sonstige Daten werden hier persistiert. Es gibt jeweils eine Collection für die oben erwähnten Domänenobjekte. Zusätzlich gibt es noch Collections von Javers (prefix jv) für die Objektversionierung, sowie Collections für das User-/Identitymanagement und für Hintergrundaufgaben (Queues und Tasks). GridFS wird ebenfalls genutzt zur Speicherung sogenannter "Attachments" an den Domänenobjekten. Indices werden von der Anwendung (dzhw/metadatamanagement) gesetzt.
Scalegrid betreibt für uns je Stage (dev, test, prod) eine Instanz bei AWS Frankfurt. Für den Zugang mit einem MongoDB-Client werden SSL-Zertifikate benötigt. Diese sind hier zu finden:
s3://metadatamanagement-private/ca_cert_mongodb_Dev.txt
s3://metadatamanagement-private/ca_cert_mongodb_Test.txt
s3://metadatamanagement-private/ca_cert_mongodb_Prod.txt
Scalegrid macht tägliche DB-Backups und hält diese 14 Tage vor. Sie können über die Web-UI restored werden.
Zugangsdaten zu den einzelnen Instanzen sind unter s3://metadatamanagement-private/sensitive_variables.tf zu finden.
Elasticsearch ist unser sekundärer Datenstore, d.h. alle Daten liegen weitestgehend normalisiert im primären Datenstore (MongoDB) und werden zusätzlich für die Volltextsuche denormalisiert in Elasticsearch gespeichert.
Elastic.co betreibt für uns je Stage (dev, test, prod) eine Instanz bei AWS Frankfurt. Die Indices werden von der Anwendung (dzhw/metadatamanagement/src/main/resources/elasticsearch) verwaltet und automatisch beim Deployment neu erstellt, wenn sich der Zeitstempel in der indices_verson.json geändert hat. Unter "Verfügbarkeit externer Dienste" -> "Reindizieren" kann dieser Prozess auch manuell angestoßen werden.
Zugangsdaten zu den einzelnen Instanzen sind unter s3://metadatamanagement-private/sensitive_variables.tf zu finden.
CloudAMQP betreibt für uns je Stage (dev, test, prod) eine kostenlose RabbitMQ Instanz bei AWS Frankfurt. Der kostenlose Plan umfasst lediglich 20 Connections.
Dieser Message Broker wird verwendet, um allen per Websocket verbundenen Clients Nachrichten zu schicken (in der GUI: Benutzer:innenverwaltung -> oranger Papierflieger). Bisher wurde diese Funktionalität lediglich verwendet, um die aktiven User direkt vor dem Deployment einer neuen Version über die bevorstehende Downtime zu informieren.
Zugangsdaten zu den einzelnen Instanzen sind unter s3://metadatamanagement-private/sensitive_variables.tf zu finden.
da|ra ist der Dienst bei dem das MDM eine DOI (Digital Object Identifier) für veröffentlichte Datenpaket- und Analysepaketversionen zusammen mit einigen Metadaten registriert. Details dazu finden sich hier: https://github.com/dzhw/metadatamanagement/wiki/Metadata-and-DOI-registration-at-dara
Lokale Entwicklersysteme und das Dev- und Testsystem nutzen folgende da|ra Instanz: https://labs.da-ra.de/dara/mydara/index?lang=en
Das Produktivsystem nutzt folgende Instanz: https://www.da-ra.de/dara/mydara/index?lang=en
Zugangsdaten sind unter s3://metadatamanagement-private/sensitive_variables.tf zu finden.
Wir nutzen seo4ajax, um Bots und Crawlern eine reine (gerenderte) HTML-Version unserer AngularJS-Seiten auszuliefern. Dynamisch gesetzte Meta-Tags für z.B. Schema.org, Open Graph und Twitter werden dadurch für die Bots und Crawler verfügbar gemacht. Seo4ajax hat seinen eigenen Crawler, der regelmäßig die öffentlichen Seiten des MDMs rendert und für andere Bots und Crawler cacht. Dabei wird auch eine sitemap erstellt.
Der Filter der die Weiterleitung von Botanfragen an seo4ajax macht, ist hier zu finden: Seo4AjaxFilter.java
Da wir nur einen Plan für 100.000 Seiten (aktuell 62.000 genutzt) haben, werden die Variablendetailseiten nicht gerendert. Es werden auch nur die Seiten des Produktivsystems gerendert.
Die Rechnung muss jeden Monat an die Buchhaltung und an Daniel Buck weitergeleitet werden.
Die Google Search Console gibt Auskunft darüber, welche Seiten vom Google Crawler indiziert wurden und über welche Suchparameter potentielle Datennutzer:innen zum MDM gekommen sind.
Der Google Crawler bekommt dabei eine von seo4ajax gerenderte Version unserer Seiten ausgeliefert.
Wir tracken aktuell das Benutzerverhalten mit Matomo. Eine Übersicht darüber, was wir tracken, ist hier zu finden: https://github.com/dzhw/metadatamanagement/wiki/Web-Analytics
Die Matomoinstanz wird von Ruth Coordes zusammen mit dem IT-Support betrieben und ist hier zu finden (nur aus dem DZHW-Netz verfügbar): https://webstat-admin.dzhw.eu/piwik/
Im Code (dzhw/metadatamanagement) findet man die Stellen, die für das Tracken verantwortlich sind, wenn man nach _paq bzw. analytics sucht.
Wir nutzen aktuell den Slack-Channel mdm-devops um Events von Github (Actions, Issues, Releases) zu empfangen und um Alarme von AWS Cloudwatch und Uptimerobot zu empfangen.
Der Slack-Channel mdm-review wird genutzt, um das Scrum Event "Sprint Review" durchzuführen.
Uptimerobot ist ein Dienst, der periodisch HTTP-Anfragen an unsere Spring Boot Health Endpoints schickt und bei Fehlern eine Nachricht an den Slack-Channel mdm-devops sendet. Es sind aktuell die folgenden Endpoints konfiguriert:
| Name | Endpoint |
|---|---|
| Dara Health | https://metadata.fdz.dzhw.eu/management/health/dara |
| Elasticsearch Health | https://metadata.fdz.dzhw.eu/management/health/elasticsearch |
| Index HTML | https://metadata.fdz.dzhw.eu |
| Info (no SSL) | http://metadata.fdz.dzhw.eu/management/info |
| Mail Health | https://metadata.fdz.dzhw.eu/management/health/mail |
| Mongo Health | https://metadata.fdz.dzhw.eu/management/health/mongo |
| Seo4Ajax Health | https://metadata.fdz.dzhw.eu/management/health/seo4Ajax |
Aktuell nutzen wir Docker Hub nicht mehr, sondern nutzen Amazon ECR (Elastic Container Registry) zum deployen unserer container images (dzhw/metadatamanagement und dzhw/report-task). Es gibt allerdings noch die Organisation DZHW bei Docker Hub:
https://hub.docker.com/orgs/dzhw