Examples | Atlantis Word Processor (Blog)
Ali Rizvi-Santiago of Cisco Talos recently tied second place in the IDA plugin contest with a plugin named “IDA-minsc”. IDA is a multi-processor disassembler and debugger created by the company Hex-Rays and this year there were a total of 4 winners with 9 submissions total. Every year, the company invites researchers to submit plugins that improve their products, and Talos determined that IDA-minsc would improve users’ experience enough that it deserved consideration for this year’s awards.
This plugin aims to make it easier for people to reverse and annotate binaries. We believe that this plugin expedites the annotation process and allows the user to work more efficiently. This is done by introducing a few concepts that change the way most users develop Python, which allows the user to treat the parts that they are reversing as more of a dataset that can be used to query and annotate as they see fit. This, combined with the plugin’s various components that automatically determine a function’s parameters based on the user’s current selection, allows the user to very quickly write code that can be used to mark and annotate the different parts of the database.
The plugin itself is hosted here with detailed documentation here. Below, we will demonstrate the capabilities of this plugin by reversing Atlantis Word Processor, a document creator coded in Borland Delphi. This blog will outline how to quickly tag any objects that are constructed for querying, how to identify tokens belonging to the RTF parser and their attributes, and then how to deal with closures that reference variables defined in other functions.. All the capabilities described below can be found within the document linked to above, or by calling Python’s help() function on the namespace or the module directly.
IDAPython is essentially a wrapper around the IDA SDK, which results in separate modules directly corresponding to the way in which the different components of IDA were implemented. The modules used in IDA 6.95 were too complex for a user to familiarize themselves with. IDAPython quickly fixed this by implementing a number of higher-level functions. However, the new modules were too generically named and required previous knowledge of the IDC scripting language. When writing this new plugin, we found that we could group the various components and functions used into separate modules, making it easier to recall and immediately reference them. There are various other modules available in this plugin, but the main feature is the two “contexts” that IDA-minsc started with. Inside each of these modules are class definitions with static methods that are used as “namespaces” to group functions together that act on similar data or with similar semantics.
When first opening the "awp.exe" file in Atlantis Word Processor, IDA will begin to process it. Once IDA has finished its processing, the plugin will kick in and begin to build its tag cache. The tag cache is utilized specifically for tagging and querying tags. During this process, the plugin will iterate through all of the comments available in the database, while updating an internal cache and showing its progress. Once this is complete, the user may begin the reversing process.

Progress bar shown during build of database
All Delphi applications will typically include a class called "TObject". This class can be inherited by a number of classes and we can utilize this to find "System.New", which is generally used as a constructor. To start out, we'll use IDA-minsc to list all symbol names that reference "TObject". This is the same as using IDA's "Names" window (Shift+F4), but uses IDA-minsc's matching component to specify different keywords for filtering IDA's different windows.
Python>db.names.list(like='*TObject')
[ 0] 0x4010b0 _cls_System_TObject
[ 382] 0x4058e4 GetCurrentObject
[ 408] 0x4059b4 SelectObject
[11340] 0x67d658 __imp_SelectObject
[11366] 0x67d6c0 __imp_GetCurrentObject
If we double-click the address or symbol for "_cls_System_TObject", IDA will then navigate to the the specified address. This will then look like Figure 1 below, which represents our "TObject". If we cross-reference this (Ctrl+X) we can see that this string is referenced by an address right next to it at 0x401070. This represents the actual class definition in Delphi. This address is what is referenced by classes that inherit "TObject".
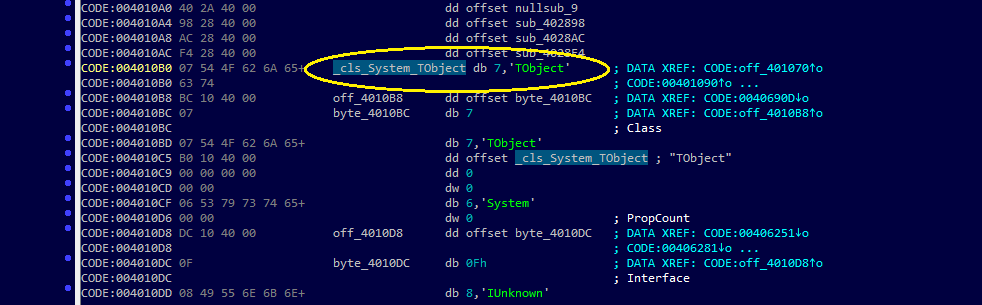
Figure 1
Once we have this address, we can again grab its references to see all the classes that inherit "TObject" — it appears that there's about 122 of them. If we pick one at random, we'll see what looks like some kind of structure. This structure begins with a self-reference, and includes a number of functions that can be called. In Delphi, this self-reference is used to distinguish between default functions that are used to control the object's scope and functions. If we follow this reference, then the functions above it are related to the standard library, whereas the ones that follow are custom implemented methods.

Figure 2
Since the three functions in Figure 2 are related to the standard library, we can see they perform a few tasks if we look over them one-by-one. The third function at address 0x406dec seems to call "CloseHandle", so this is likely a destructor. The first function at address 0x406De4 is typically the constructor. If we select this function and list the references that use it (X), we can see it has 473 references. We're going to use these references to find each class and label them. Before we do that, however, let's take a look in detail at this structure:
CODE:00406DAE 8B C0 align 10h
CODE:00406DB0 F0 6D 40 00 off_406DB0 dd offset off_406DF0 ; [1]
CODE:00406DB0
CODE:00406DB4 00 00 00 00 00 00+ dd 7 dup(0)
CODE:00406DD0 F8 6D 40 00 dd offset str.TThread ; [3] "TThread"
CODE:00406DD4 28 00 00 00 dd 28h ; [5]
CODE:00406DD8 70 10 40 00 dd offset off_401070
CODE:00406DDC 38 2A 40 00 dd offset sub_402A38
CODE:00406DE0 40 2A 40 00 dd offset nullsub_9
CODE:00406DE4 98 28 40 00 dd offset sub_402898 ; Constructor
CODE:00406DE8 AC 28 40 00 dd offset sub_4028AC ; Finalizer
CODE:00406DEC E8 A9 40 00 dd offset sub_40A9E8 ; Destructor
CODE:00406DF0 38 AA 40 00 off_406DF0 dd offset loc_40AA38 ; [2]
CODE:00406DF4 C4 25 40 00 dd offset nullsub_11
CODE:00406DF8 07 54 54 68 72 65+ str.TThread db 7,'TThread' ; [4]
CODE:00406E00 04 6E 40 00 off_406E00 dd offset byte_406E04
As mentioned before, this structure contains a self-reference at [1]. This reference is labelled by IDA since it is used by functions within the database. This reference is used specifically to get to [2] in order to locate the "Constructor", "Finalizer", and "Destructor” of the class. Also, near the beginning at [3], is a pointer to a string. This string represents the class name and its contents that are located at [4]. The format of this string is the same as in Pascal, which begins with a single-byte length, followed by the number of bytes representing the string. Finally, at [5] there is the length of the class. This represents the size that is needed to be allocated in order to store its members. To start out, let's quickly define a function that will set a pascal-style string at the IDAPython command line.
To do this, we will use the database.set.integer namespace to make the first byte a uint8_t for the length. For the rest of the string, we’ll use database.set.string with the length to turn the address into a string of the specified length.
Python>def set_pascal_string(ea):
Python> ch = db.set.integer.uint8_t(ea)
Python> return db.set.string(ea + 1, ch)
After this is done, we can then use database.get.string to read it back if we want. Despite the database.set namespace returning the values that have been created, we can do the inverse of the code specified above with the following. To avoid having to type in database.get.integer, we can just use the shorter alias database.get.i.
Python>def get_pascal_string(ea):
Python> ch = db.get.i.uint8_t(ea)
Python> return db.get.string(ea + 1, length=ch)
Now we can type in the following to read a string at that address:
Python>print get_pascal_string(0x406df8)
TThread
Now that we can both fetch and apply strings which will give us the name, we can use this name to label the class. To do this, we're going to use all of the references of the constructor and use each reference to calculate the different fields for all the classes. Afterward, we will use tags to mark all of the different objects so we can query them later, if necessary. To begin, first we'll double-click on the "Constructor" at address 0x406de4. This should take us to the function "sub_402898". Since we have an idea what this function is, let's just name this with the following:
Python>func.name('System.New')
sub_402898
If you notice, we did not provide an address. We assume the current function since an address was not provided. This is the "multicased" functions component of IDA-minsc. If we run help() against function.name, we can see what other variations there are:
Python>help(function.name)
Help on function name in module function:
name(*arguments, **keywords)
name() -> Return the name of the current function.
name(string=basestring, *suffix) -> Set the name of the current function to ``string``.
name(none=NoneType) -> Remove the custom-name from the current function.
name(func) -> Return the name of the function ``func``.
name(func, none=NoneType) -> Remove the custom-name from the function ``func``.
name(func, string=basestring, *suffix) -> Set the name of the function ``func`` to ``string``.
Now that we have named the function, we're going to iterate through all of its references and grab its different fields. As a reference to the fields that we described above, we have the following layout:
CODE:00406DAE 8B C0 align 10h
CODE:00406DB0 F0 6D 40 00 off_406DB0 dd offset off_406DF0 ; [6] Top of class or Info (Reference - 16*4)
CODE:00406DB0
CODE:00406DB4 00 00 00 00 00 00+ dd 7 dup(0)
CODE:00406DD0 F8 6D 40 00 dd offset str.TThread ; [7] Class name (Reference - 8*4)
CODE:00406DD4 28 00 00 00 dd 28h ; [8] Class size (Reference - 7*4)
CODE:00406DD8 70 10 40 00 dd offset off_401070 ; [9] Parent class (Reference - 6*4)
CODE:00406DDC 38 2A 40 00 dd offset sub_402A38
CODE:00406DE0 40 2A 40 00 dd offset nullsub_9
CODE:00406DE4 98 28 40 00 dd offset sub_402898 ; [10] Constructor (Reference - 3*4)
CODE:00406DE8 AC 28 40 00 dd offset sub_4028AC ; [11] Finalizer (Reference - 2*4)
CODE:00406DEC E8 A9 40 00 dd offset sub_40A9E8 ; [12] Destructor (Reference - 1*4)
CODE:00406DF0 38 AA 40 00 off_406DF0 dd offset loc_40AA38 ; [13] * Reference
CODE:00406DF4 C4 25 40 00 dd offset nullsub_11
CODE:00406DF8 07 54 54 68 72 65+ str.TThread db 7,'TThread'
CODE:00406E00 04 6E 40 00 off_406E00 dd offset byte_406E04
With this layout, we can extract the different components of all of the classes that reference our constructor and tag them in order to query later. Since earlier we double-clicked on the constructor and then named it, we should currently be in the "System.New" function. To grab all of the references, we can use function.up(). We will then iterate through all of its references, add 0xc (3 * 4 == 12) to get to the reference at [13], and then use it to locate the rest of the fields. For the class name [7] we will use both our set_pascal_string and get_pascal_string functions, and for the standard scoping constructs [10], [11], and [12] we will descend into them and tag them with their "type". This results in the following code. The following code could be done much shorter, but is expanded for readability.
Python>for ea in func.up():
Python> ref = ea + 3*4 # [13] calculate address to reference
Python>
Python> # read our fields
Python> lookup = {}
Python> lookup['info'] = ref - 16*4 # [6]
Python> lookup['name'] = ref - 8*4 # [7]
Python> lookup['size'] = ref - 7*4 # [8]
Python> lookup['parent'] = ref - 6*4 # [9]
Python> lookup['constructor'] = ref - 3*4 # [10]
Python> lookup['finalizer'] = ref - 2*4 # [11]
Python> lookup['destructor'] = ref - 1*4 # [12]
Python> lookup['object'] = ref # [13]
Python>
Python> # dereference any fields that need it
Python> name_ea = db.get.i.uint32_t(lookup['name'])
Python> parent_ea = db.get.i.uint32_t(lookup['parent'])
Python> size = db.get.i.uint32_t(lookup['size'])
Python>
Python> # set our name (just in case IDA has it defined as something else)
Python> set_pascal_string(name_ea)
Python>
Python> # decode our name
Python> name = get_pascal_string(name_ea)
Python>
Python> # name our addresses
Python> db.name(lookup['info'], 'gv', "Info({:s})".format(name))
Python> db.name(lookup['object'], 'gv', "Object({:s})".format(name))
Python>
Python> # tag our methods
Python> m_constructor = db.get.i.uint32_t(lookup['constructor'])
Python> func.tag(m_constructor, 'function-type', 'constructor')
Python> m_finalizer = db.get.i.uint32_t(lookup['finalizer'])
Python> func.tag(m_finalizer, 'function-type', 'finalizer')
Python> m_destructor = db.get.i.uint32_t(lookup['destructor'])
Python> func.tag(m_destructor, 'function-type', 'destructor')
Python>
Python> # tag our class structure
Python> db.tag(lookup['info'], 'object.name', name)
Python> db.tag(lookup['info'], 'object.methods', lookup['object'])
Python> db.tag(lookup['info'], 'object.size', size)
Python> if parent_ea:
Python> db.tag(lookup['info'], 'object.parent', parent_ea)
Python> continue
This will result in all of the Delphi objects in the database being tagged. Tags will utilize the comments in the database so while a user is reversing they can immediately see what the tags associated with a given address may look like. After executing the previous code at the IDAPython command line, the “TThread” object will have the appearance shown in Figure 3.

Figure 3
After executing this large block of code, every object in the database should be tagged. This will then allow us to query the database using database.select() in order to find a class of a particular size. Please review the help() for database.select for more information. An example of doing using this to find an object size of 0x38 can be:
Python>for ea, tags in db.select(Or=('object.name', 'object.size')):
Python> if tags['object.size'] == 0x38:
Python> print hex(ea), tags
Python> continue
Atlantis Word Processor contains an RTF parser. This file format is well-known, so it’s easy to identify the tokens that it supports and hopefully find the function responsible for parsing each token's parameters. To do this, we will first search for the "objemb" string, which is hopefully defined within an array. To start out, we could use IDA's text search (Alt+T) but let’s instead use functionality provided by IDA-minsc via the database.search namespace combined with the go() function to immediately navigate to it.
Python>go(db.search.by_text('objemb'))
This takes us directly to the first instance of the "objemb" string. If we cross-reference this (Ctrl+X), it turns out that there's only one reference that uses it. This takes us to the following list of string references in Figure 4.
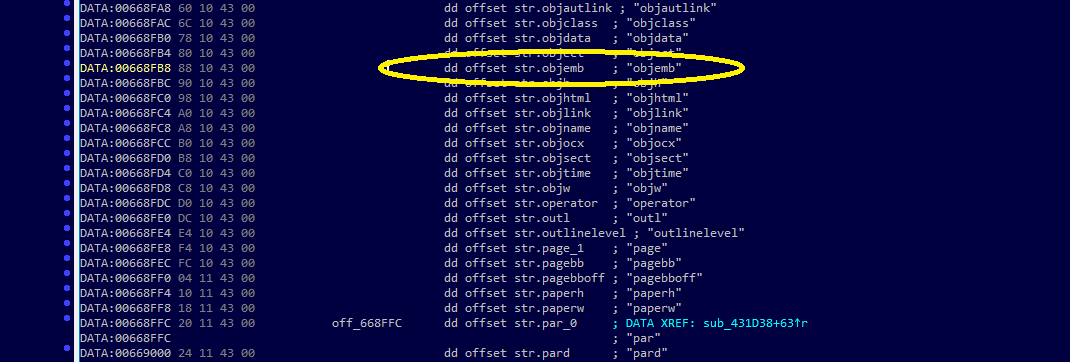
Figure 4
Since this doesn't have a reference, let's quickly navigate to the previous defined label that IDA has made. This label will exist due to IDA having disassembled code that references that particular address. To do this, we can use functionality within the database.address namespace. These are the nextlabel() and prevlabel() functions. We can use them by typing the following at the IDAPython command line. To avoid typing in the whole database.address namespace, we can again use its alias as database.a.
Python>go(db.a.prevlabel())
This data appears to be an array, but IDA has not made it one. We can hit '*' to bring up IDA's "Convert to array" dialog, but instead, we can use IDA-minsc. We will use database.address.nextlabel() and database.here() (aliased as h()) to calculate the number of elements of the array, and then assign it into the database using databaset.set.array(). The database.set.array function takes a "pythonic" type as one of its parameters. This is described within the documentation for IDA-minsc and allows us to describe a type in IDA without needing to understand the correct flags, or typeid. In this case we can use (int, 4) to specify a four-byte integer (dword), but since this is a 32-bit database, we can just use the default integer size by using int.
Python>size = (db.a.nextlabel() - h())
Python>db.set.array(int, size / 4)
Let's also name the array at the current address as well by using database.name():
Python>db.name('gv', "rtfTokenArray({:d})".format(db.t.array.length()))
However, it looks like some of this array's elements weren't marked by IDA as actual strings as in Figure 5:

Figure 5
We can quickly fix this by iterating through all the addresses in this array, undefining the address, and then re-defining it as a string in the same way one would do it manually. This can be done with the following at the IDAPython command line:
Python>for ea in db.get.array():
Python> db.set.undefined(ea)
Python> db.set.string(ea)
Now we have this array fixed. If we navigate back to the top, we'll notice that this array is contiguous with a number of arrays. Let's fix up the one above this array first and save our current position in a variable position, and then use database.address.prevlabel() to get there. Once there, we can do the same as we did for the first array.
Python>position = h()
Python>
Python>go(db.a.prevlabel())
Python>
Python>db.set.array(int, (db.a.nextlabel() - h()) / 4)
Python>db.name('gv', "rtfTokenArray({:d})".format(db.t.array.length()))
Python>for ea in db.get.array():
Python> db.set.undefined(ea)
Python> db.set.string(ea)
Now we can return to our previously saved position and repeat the process for the next two arrays:
Python>go(position)
Python>
Python>go(db.a.nextlabel())
Python>
Python>db.set.array(int, (db.a.nextlabel() - h()) / 4)
Python>db.name('gv', "rtfTokenArray({:d})".format(db.t.array.length()))
Python>for ea in db.get.array():
Python> db.set.undefined(ea)
Python> db.set.string(ea)
Python>
Python>go(db.a.nextlabel())
Python>
Python>db.set.array(int, (db.a.nextlabel() - h()) / 4)
Python>db.name('gv', "rtfTokenArray({:d})".format(db.t.array.length()))
Python>for ea in db.get.array():
Python> db.set.undefined(ea)
Python> db.set.string(ea)
Now that it's done, we can list all of the arrays that we've made using the database.names namespace. Let's list all of the symbols that begin with “gv_rtfToken”. From this list, let's look at the first array we defined ("gv_rtfTokenArray(213)") and double-click on its address.
Python>db.names.list('gv_rtfToken*')
[11612] 0x668ba8 gv_rtfTokenArray(64)
[11613] 0x668ca8 gv_rtfTokenArray(213)
[11614] 0x668ffc gv_rtfTokenArray(46)
[11615] 0x6690b4 gv_rtfTokenArray(135)
Now we should be at the definition of "gv_rtfTokenArray(213)". If we cross-reference this (Ctrl+X) we can see that there's only one code reference to it at the address 0x431DD7 ([14]).
CODE:00431DD7 000 A1 A8 8C 66 00 mov eax, ds:gv_rtfTokenArray(213) ; [14]
CODE:00431DDC 000 A3 EC 85 67 00 mov ds:dword_6785EC, eax ; [15]
CODE:00431DE1 000 C7 05 F0 85 67 00+ mov ds:dword_6785F0, 4
CODE:00431DEB 000 C7 05 F4 85 67 00+ mov ds:dword_6785F4, 4
CODE:00431DF5
CODE:00431DF5 locret_431DF5:
CODE:00431DF5 000 C3 retn
CODE:00431DF5 sub_431D38 endp
This instruction reads the token array address and then writes it to another global at [15]. Since this is just a pointer to our array, let's name this address, as well. Rather than using IDA's "Rename address" dialog, or double-clicking on "dword_6785EC" and then using database.name with the current address, we'll actually extract the address directly from the instruction's operand. This can be done via the instruction.op function. If we select the address 0x431ddc, our global token array will reside in the first operand of the current instruction. We can extract its operand as a named tuple at the IDAPython command line with the following.
Python>ins.op(0)
OffsetBaseIndexScale(offset=6784492L, base=None, index=None, scale=1)
Since we didn't provide an address as the first parameter to instruction.op, it will assume that we're referring to the current instruction. The "offset" field of the named tuple contains the address to our dword. So, we can use the following to name this pointer with the same address selected. Due to this address already having a name of "dword_6785EC", the database.name function will return the original name.
Python>ea = ins.op(0).offset
Python>db.name(ea, 'gp','rtfTokenArray(213)')
dword_6785EC
This same function does the same assignment to a global pointer for all of the arrays that we have previously defined. We can repeat this process to name all of them, and then cross-reference them to locate the RTF tokenizer. For now, let's prepare before we get to that point. Our preparations will simply involve going back to our arrays of tokens and extracting the strings from them. We already have these named, so we can list them with the following:
Python>db.names.list('gv_rtfToken*')
[11612] 0x668ba8 gv_rtfTokenArray(64)
[11613] 0x668ca8 gv_rtfTokenArray(213)
[11614] 0x668ffc gv_rtfTokenArray(46)
[11615] 0x6690b4 gv_rtfTokenArray(135)
However, we're going to want to iterate through this list. The database.names namespace includes an iterate() function for specifically this purpose. We can use this combined with database.get.array() to store the arrays as a single list. At the IDAPython command line, we'll execute the following:
Python>tokens = []
Python>for ea, name in db.names.iterate('gv_rtftoken*'):
Python> rtfTokenArray = db.get.array(ea)
Python> tokens.extend(rtfTokenArray)
Python>
Python>len(tokens)
458
We have a single list of 458 addresses that point to the actual RTF tokens. We'll convert this to a list of strings using a quick list comprehension to map the addresses to a string. Now we can convert a token identifier to its actual token string.
Python>tokens = [db.get.string(ea) for ea in tokens]
At this point, we should still be within "sub_431D38". Although we can probably cross-reference (Ctrl+X) some of the pointers to our token arrays that are assigned here and eventually get to a function that processes our tokens and their arguments, there might be a way to make this easier. We can tag all of the switches for each function in the database. While we're at it, let's count the number of cases of each switch so we can quickly query the functions that have the most cases. We can use function.switches() to enumerate all of the switches within a function. This allows us to iterate through all of the switches defined within a function and return an instance of IDA-minsc's switch_t that we can use to calculate the total number of non-default cases. To do this, let's first define a function that will tag the number of switches and the total count of cases for a function.
Python>def tag_switches(ea):
Python> count, total = 0, 0
Python> for sw in func.switches(ea):
Python> count += 1
Python> total += len(sw.cases)
Python> if count > 0:
Python> func.tag(ea, 'switch.count', count)
Python> func.tag(ea, 'switch.cases', total)
Python> return
Now that we have defined a function that can tag a function in the IDA database with the tags "switch.count" for the number of switches and "switch.cases" for the total number of cases, we can apply this to each function within the database so we can query this later. Let's iterate through all the functions using database.functions() via the following:
Python>for ea in db.functions():
Python> tag_switches(ea)
This might take a while, so, it'd be helpful if we can see the current progress. There's a tool provided by IDA-minsc within the "tools" module that pretty much implements this same logic that we can use. This is tools.map, and takes a callable as its parameter. To use this, we can type in the following at the Python prompt, if we prefer:
Python>_ = tools.map(tag_switches)
Now that we have each function with any switches tagged, we can query the entire database in order to sort them. Although we can use the "key" keyword of Python's sorted function, we'll just organize our query results so that the first entry is the total number of switches belonging to each function. Afterward, we'll sort them using sorted, and then look at the last element which should have the most combined switch cases.
Python>results = []
Python>for ea, tags in db.select('switch.cases'):
Python> results.append( (tags['switch.cases'], ea) )
Python>
Python>results = sorted(results)
Python>len(results)
162
Now that we have a sorted list of all of the functions that have the most switch cases, we can look at the last element to see what we found. Let's extract the address from the last result, and then navigate to it (Figure 6).
Python>results[-1]
(294, 5797552)
Python>_, ea = results[-1]
Python>go(ea)
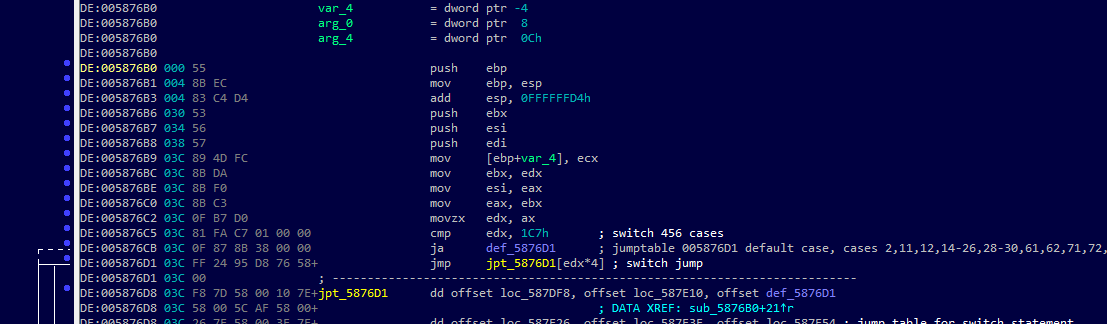
Figure 6
It looks like we got lucky and found something that looks like a parser, or really a tokenizer that has a switch with a bunch of cases. Let's double-check our switch count via a call to function.tag().
Python>print func.tag('switch.count')
1
It appears that there's only one switch. Let's grab our switch so we can see what cases it has. To do this, click on the address of its main branch at 0x5876d1. Now that it's selected, we don't need to pass an address to database.get.switch() and can instead let it use the current address. We'll store this into the "sw" variable.
Python>sw = db.get.switch()
Python>sw
<type 'switch_t{456}' at 0x5876c5> default:*0x58af5c branch[456]:*0x5876d8 register:edx
Let's see how many cases and default cases are within this switch. We'll calculate the number of default cases by taking its total length, and subtracting the length of its valid cases.
Python>print 'number of cases:', len(sw)
number of cases: 456
Python>print 'number of default cases:', len(sw) - len(sw.cases)
number of default cases: 162
To make it easier for us to identify the token associated with a particular case, we can simply tag each case with the token we stored in our "tokens" list. The list of available cases is in the "cases" property of our "sw" variable. We can simply call its ".case()" method in order to get the handler for a particular case. We will use these attributes to tag each case handler with a "token" tag containing the token from our "tokens" list that we assigned above.
Python>for case in sw.cases:
Python> handler = sw.case(case)
Python> db.tag(handler, 'token', tokens[case])
One issue with this, however, is that more than one token can be handled by each case. This requires grabbing the cases that are handled by each handler. To do this, we can use the "handler" method of our "sw" variable that we assigned. We'll use "function.select" to select all of the handlers that we tagged, then grab the cases for each handler, and then re-tag the handler with the tokens that it's responsible for. Although function.select() takes a function address as its parameter, since we want to query the current function, its address is not needed.
Python>for ea, tags in func.select('token'):
Python> toks = []
Python> for case in sw.handler(ea):
Python> toks.append( tokens[case] )
Python> db.tag(ea, 'token', toks)
This results in the list of tokens handled by each case being tagged with the name "token". If we ever need to locate the handlers again or the tokens that are handled by each case, we can simply use function.select again to grab them. In Figure 7, the handler for cases 66, 68, 69, 183, and 427 has a number of tokens associated with it.
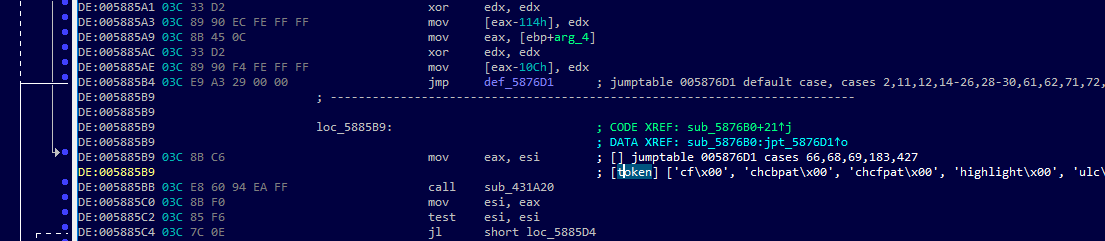
Figure 7
The next thing we're going to do is iterate through each of the addresses that we've tagged with "token" in order to find the first call instruction. We'll also look for an unconditional branch since we'll assume that if an unconditional branch is found, then the handler is done and branching outside of the switch. To identify an unconditional branch or call instruction, we will use the "instruction" module. Inside this module are the functions instruction.is_jmp and instruction.is_call. To find the "next" instructions that match one of these, we will use a variation of database.address.next that takes a predicate. Now although this might not produce 100 percent accurate results, we are going to go through this manually later. Therefore, accuracy isn't too important in this situation. So, let's query our handlers with function.select and then tag the handler's address with the target of its first call instruction using the tag name "rtf-parameter".
Python>for ea, tags in func.select('token'):
Python> next_call = db.a.next(ea, lambda ea: ins.is_jmp(ea) or ins.is_call(ea))
Python> if ins.is_call(next_call):
Python> db.tag(ea, 'rtf-parameter', ins.op(next_call, 0))
Python> elif ins.is_jmp(next_call):
Python> print "found an unconditional branch with the target: {:x}".format(ins.op(next_call, 0))
Python> continue
A number of unconditional branches were listed that don't really matter to us. So let's query what results were tagged as the first call instruction.
Python>found = set()
Python>for ea, tags in func.select('rtf-parameter'):
Python> found.add(tags['rtf-parameter'])
Python>
Python>found
set([4397600, 6556480, 4226632, 5797484, 5797008, 4226316, 4226640, 4397688, 5797216, 4226452, 5796288, 5797400, 5767988, 6487132])
Unfortunately, these numbers aren't useful, so let's map them to names so we can click on them.
Python>map(func.name, found)
['sub_431A20', 'sub_640B40', 'sub_407E48', 'sub_58766C', 'sub_587490', 'sub_407D0C', 'sub_407E50', 'sub_431A78', 'sub_587560', 'sub_407D94', 'sub_5871C0', 'sub_587618', 'sub_580334', 'sub_62FC5C']
After manually going through each one and very quickly looking for things that stand out, a quick summary of their results could be:
- sub_431A20 — looks like it does something with numbers and a hyphen, probably a range?
- sub_640B40 — no idea what this is
- sub_407E48 — fetches some property from an object and doesn't call anything
- sub_58766C — looks too complex for me to care about
- sub_587490 — looks too complex for me to care about
- sub_407D0C — fetches some property from an array using an index
- sub_407E50 — fetches some property from an array using an index
- sub_431A78 — calls two functions, first one does something with spaces second one is the first in this list which does stuff with numbers and a hyphen
- sub_587560 — looks complex, but calls some string-related stuff
- sub_407D94 — calls a function that does some allocation, probably allocating for a list
- sub_5871C0 — references a few characters that look rtf specific like a "{", backslash "" and a single quote
- sub_587618 — calls a couple functions that are currently in this list
- sub_580334 — calls a couple functions that are currently in this list
- sub_62FC5C — looks like it resizes some object of some kind
Going back through this list of notes, it appears that sub_431A20, sub_431A78, sub_5871C0, and sub_587618 seem to be parsing-related. Let's take this list of functions and convert them back into addresses. This way we can store them in a set and see which cases belonging to our switch are using them. So first, we'll convert the function names back into addresses using function.address().
Python>res = map(func.address, ['sub_431A20', 'sub_431A78', 'sub_5871c0', 'sub_587618'])
Python>match = set(res)
Now that we have a set to match with, let's collect all of the cases along with the "rtf-parameter" that it calls. We'll also output the cases that it handles in case we want to visit them individually.
Python>cases = []
Python>for ea, tags in func.select('rtf-parameter'):
Python> if tags['rtf-parameter'] in match:
Python> print hex(ea), sw.handler(ea)
Python> for i in sw.handler(ea):
Python> cases.append((i, func.name(tags['rtf-parameter'])))
Python> continue
Python> continue
Python>
Python>len(cases)
116
Let's take a few random samples out of this list and see what tokens these point to and identify the first function call that was made to handle each token. From taking a few random samples, it looks like a large number of them call the function "sub_431A20". We determined that this function seems to process a number which can include a hyphen. When executing the following at the IDAPython command line we can see that cases 246, 100, and 183 call this function and represent the following tokens.
Python>cases[246]
(246, 'sub_431A20')
Python>cases[100]
(100, 'sub_431A20')
Python>cases[183]
(183, 'sub_431A20')
Python>
Python>tokens[246], tokens[100], tokens[183]
('margt', 'colsx', 'highlight')
If we refer to the documentation for the RTF file format, it seems that these tokens ('\margt', '\colsx', and '\highlight') take a number as its parameter. We can safely assume that "sub_431A20" is responsible for processing a numerical parameter that follows an RTF token. Let's tag this now so we can look at another function and try to determine what parameter type it might take.
Python>func.tag(0x431a20, 'synopsis', 'parses a numerical parameter belonging to an rtf token')
Let's just dump what's left in our "cases" list that we made above so we can quickly see what what functions we haven't figured out yet. Let's also include the token name so that we can quickly reference the file format specification to determine what type of parameter it might take.
Python>for i, name in cases:
Python> if name != 'sub_431A20':
Python> print i, tokens[i], name
Python> continue
27 b sub_587618
63 caps sub_587618
105 contextualspace sub_431A78
114 deleted sub_431A78
123 embo sub_587618
186 hyphauto sub_431A78
187 hyphcaps sub_431A78
190 hyphpar sub_431A78
191 i sub_587618
193 impr sub_587618
232 listsimple sub_431A78
270 outl sub_587618
346 scaps sub_587618
363 shad sub_587618
373 strike sub_587618
423 u sub_5871C0
426 ul sub_431A78
Looking at the documentation for the "\b", "\caps", and "\i" tags tells us that these tags can take an optional "0" as a parameter to turn them off. So we can assume that "sub_587618" is a function used to process a parameter that is used to toggle these tokens. Let us tag this function as well.
Python>func.tag(0x587618, 'synopsis', 'parses an rtf parameter that can be toggled with "0"')
The other tokens that stand out in the list that we emitted is the "\hyphauto", "\hyphcaps", and "\hyphpar" tokens. These tokens take a single numerical parameter that is either a "1" or a "0" to toggle it. This is also a toggle, but this parameter is required. Let's tag this with our newfound knowledge
Python>func.tag(0x431a78, 'synopsis','parses an rtf parameter that can be toggled with "0" or "1"')
Now that we've identified the semantics of a number of these functions, we've quickly identified what tokens are supported by Atlantis and can use this information to generate a grammar that can be used to fuzz this particular target.
In Delphi 2009, a new feature known as "Anonymous Methods" was introduced. This feature introduces support for closures in the Delphi programming language. Closures will capture the local variables of the block that encompasses it. This allows for the code within a closure to actually be able to modify variables belonging to a completely different function.
In the assembly generated by Delphi, this will look like Figure 8 and will involve passing the frame pointer in the %ebp register as the argument to a function. This is so the function can dereference the pointer and use it to calculate the address of the local variable of the frame that is being referenced.

Figure 8
This can be hectic for the reverser as in some cases the local variables typically initialized in a completely different function. To track this with a debugger, a reverse-engineer might try to determine the scope of the variable and then use a hardware breakpoint to identify the first function that writes to it. If a reverser is doing this statically, however, this can very quickly become a difficult problem to overcome on a large scale.
Usage of these local variables might look like the following code. At [16], the frame is extracted from an argument and stored into the %eax register. This is repeated a number of times at [17], and [18] to walk up the stack dereferencing the frame pointer of each caller. Finally at [19], the local variable of the frame that was determined is then fetched. In Atlantis, this type of construct is very common and can be difficult for one to manage.
CODE:0058BED8 018 8B 55 FC mov edx, [ebp+var_4]
CODE:0058BEDB 018 8B 45 08 mov eax, [ebp+arg_0] ; [16]
CODE:0058BEDE 018 8B 40 08 mov eax, [eax+8] ; [17]
CODE:0058BEE1 018 8B 40 08 mov eax, [eax+8] ; [18]
CODE:0058BEE4 018 8B 40 E8 mov eax, [eax-18h] ; [19]
CODE:0058BEE7 018 8B 88 64 05 00 00 mov ecx, [eax+564h]
CODE:0058BEED 018 8B 45 08 mov eax, [ebp+arg_0]
CODE:0058BEF0 018 8B 40 08 mov eax, [eax+8]
CODE:0058BEF3 018 8B 40 08 mov eax, [eax+8]
CODE:0058BEF6 018 8B 40 E8 mov eax, [eax-18h]
CODE:0058BEF9 018 E8 12 39 07 00 call sub_5FF810
CODE:0058BEFE 018 84 C0 test al, al
CODE:0058BF00 018 75 0C jnz short loc_58BF0E
However, with IDA-minsc we can tag the functions that store their caller's frame in an argument, and the address of the function that each frame belongs to. This way we can then identify the frame member that an instruction (similar to [19]) references. To do this, we will use two tag names. These will be, "frame-avar" for storing the name of the argument that contains the caller's frame, and "frame-lvars" for storing the address of the function that the referenced frame belongs to.
If we refer to Figure 8, at address 0x590a32, the function "sub_590728" is passing its frame as an argument to the call instruction at 0x590a33. If we descend into this function call by double-clicking on it, IDA will navigate us to the very top of the function named "sub_58BE98". This function has only one caller, and if we view its references (Ctrl+X) it will list the address that we just navigated from. Knowing this, we can tag this function with the address of its caller.
Python>callers = func.up()
Python>caller = callers[0]
Python>func.tag('frame-lvars', caller)
To make it easier to identify the argument, let's name the argument as "ap_frame_0" using the "Stack Variable Rename" dialog. This can be done by selecting "arg_0" and then hitting the "n" character. After renaming the variable to "arg_0". We will again use tagging to store the argument name as "frame-avar". This way if we wish to identify the argument that contains the frame we can extract it using the "frame-avar" tag.
Python>func.tag('frame-avar', 'ap_frame_0')
After doing this, the function will look like the following code. We can now iterate through any references to the "ap_frame_0" argument variable, and then tag them with the value found in the "frame-lvars" tag.
CODE:0058BE98 ; [frame-avar] ap_frame_0
CODE:0058BE98 ; [frame-lvars] 0x590a33
CODE:0058BE98 ; Attributes: bp-based frame
CODE:0058BE98
CODE:0058BE98 sub_58BE98 proc near
CODE:0058BE98
CODE:0058BE98 var_4 = dword ptr -4
CODE:0058BE98 ap_frame_0 = dword ptr 8
CODE:0058BE98
To do this, we will use the function.frame() function to grab the frame as a structure. Once this is done, we can then fetch the member that represents the “ap_frame_0” variable. This structure member can then be used to enumerate all the references to it within the current function.
Python>f = func.frame()
Python>f.members
<type 'structure' name='$ F58BE98' size=+0x10>
[0] -4:+0x4 'var_4' (<type 'int'>, 4)
[1] 0:+0x4 ' s' [(<type 'int'>, 1), 4]
[2] 4:+0x4 ' r' [(<type 'int'>, 1), 4]
[3] 8:+0x4 'ap_frame_0' (<type 'int'>, 4)
To then get the member, we can either use its index, or its name. In this case, we will reference it by name. Once the member is fetched, we can then proceed to call its refs() method to iterate through all the references to the member within the function.
Python>m = f.by('ap_frame_0')
Python>len(m.refs())
8
Python>for r in m.refs():
Python> print r
Python>
AddressOpnumReftype(address=5815998L, opnum=1, reftype=ref_t(r))
AddressOpnumReftype(address=5816027L, opnum=1, reftype=ref_t(r))
AddressOpnumReftype(address=5816045L, opnum=1, reftype=ref_t(r))
AddressOpnumReftype(address=5816066L, opnum=1, reftype=ref_t(r))
AddressOpnumReftype(address=5816087L, opnum=1, reftype=ref_t(r))
AddressOpnumReftype(address=5816112L, opnum=1, reftype=ref_t(r))
AddressOpnumReftype(address=5816134L, opnum=1, reftype=ref_t(r))
AddressOpnumReftype(address=5816175L, opnum=1, reftype=ref_t(r))
The references that are returned are a named tuple containing the address, its operand number, and whether the reference is reading or writing to the variable. To show the instructions that we're dealing with, we will simply unpack the address out of the tuple and use it with the database.disassemble function.
Python>for ea, _, _ in m.refs():
Python> print db.disasm(ea)
Python>
58bebe: mov eax, [ebp+ap_frame_0]
58bedb: mov eax, [ebp+ap_frame_0]
58beed: mov eax, [ebp+ap_frame_0]
58bf02: mov eax, [ebp+ap_frame_0]
58bf17: mov eax, [ebp+ap_frame_0]
58bf30: mov eax, [ebp+ap_frame_0]
58bf46: mov eax, [ebp+ap_frame_0]
58bf6f: mov eax, [ebp+ap_frame_0]
Now that we can be sure that these instructions all reference the argument containing the frame of its caller, let us temporarily tag them with the name "frame-operand" and the operand’s index.
Python>for ea, idx, _ in m.refs():
Python> db.tag(ea, 'frame-operand', idx)
Python>
Next, we will want to do is to identify the next instruction for each of these references that uses the register the frame variable is being assigned to. To identify the register belonging to the first operand, we can use instruction.op. To locate the next instruction that the register is being read from, we can use the database.address.nextreg function. Before we actually tag our results, however, let us first do a select of the "frame-operand" tag, and use the combination of instruction.op and database.address.nextreg to see what our results might look like.
Python>for ea, tags in func.select('frame-operand'):
Python> reg = ins.op(ea, 0)
Python> next_ref = db.a.nextreg(ea, reg, read=True)
Python> print hex(ea), '->', db.disasm(next_ref)
Python>
58bebe -> 58bec1: push eax
58bedb -> 58bede: mov eax, [eax+8]
58beed -> 58bef0: mov eax, [eax+8]
58bf02 -> 58bf05: mov eax, [eax+8]
58bf17 -> 58bf1a: mov eax, [eax+8]
58bf30 -> 58bf33: mov eax, [eax+8]
58bf46 -> 58bf49: mov eax, [eax+8]
58bf6f -> 58bf72: mov eax, [eax+8]
It appears that at the address 0x58bebe, the next usage of the %eax register is at 0x58bec1 via a "push" instruction. This is likely being used to pass the caller's frame to a function call. For now since we were only interested in the frame variables being used in the current function, we will remove the tag from this address.
Python>db.tag(0x58bebe, 'frame-operand', None)
1
After removing the tag at this address, there should exist only assignment instructions that read from the frame. Previously, we have stored the address of the caller in the function tag "frame-lvars". As a result of this, we can now use this to tag each of the assignment instructions that follows the reference to the "ap_frame_0" variable with the "frame" tag.
Python>for ea, tags in func.select('frame-operand'):
Python> reg = ins.op(ea, 0)
Python> next_ref = db.a.nextreg(ea, reg, read=True)
Python> lvars = func.tag('frame-lvars')
Python> db.tag(next_ref, 'frame', lvars)
Python>
Now that we have created a new tag, "frame", which points to an instruction that uses the frame, we do not need the "frame-operand" tag anymore. We can now remove this "frame-operand" tag by executing the following code at the IDAPython command prompt.
Python>for ea, _ in func.select('frame-operand'):
Python> db.tag(ea, 'frame-operand', None)
Python>
Let's review our results again, by querying the function for any instructions that are tagged with "frame". We will again use database.disassemble and this time include any comments that were specified by using the "comment" keyword as one of its parameters.
Python>for ea, tags in func.select('frame'):
Python> print db.disasm(ea, comment=True)
Python>
58bede: mov eax, [eax+8]; [frame] 0x590a33
58bef0: mov eax, [eax+8]; [frame] 0x590a33
58bf05: mov eax, [eax+8]; [frame] 0x590a33
58bf1a: mov eax, [eax+8]; [frame] 0x590a33
58bf33: mov eax, [eax+8]; [frame] 0x590a33
58bf49: mov eax, [eax+8]; [frame] 0x590a33
58bf72: mov eax, [eax+8]; [frame] 0x590a33
After tagging each of these instructions with "frame", we can now see which frame the offset is actually referring to. With this, as we are reversing we are able to double-click and immediately view the frame that owns that particular variable. However, we can do a little bit better than this. If we double click on the address of one of the instructions we emitted we can then use the instruction.op function to extract the operand that references the frame variable. Let's navigate to one of these instructions and then try that.
Python>ins.op(1)
OffsetBaseIndexScale(offset=8L, base=<internal.interface.register.eax(0,dt_dword) 'eax' 0:+32>, index=None, scale=1)
Immediately by emitting the first operand of the current instruction via instruction.op, a named tuple is returned which contains the offset referring to the frame variable we wish to view. If we use this offset with function.frame to identify the frame's member, we can then get its name. Let's fetch the member name with this method, and then tag the instruction with it as the "frame-member".
Python>for ea, tags in func.select('frame'):
Python> frame = func.frame(tags['frame'])
Python> offset = ins.op(ea, 1).offset
Python> member = frame.by(offset)
Python> db.tag(ea, 'frame-member', member.name)
Python>
We can now see that every instruction in the current function that was marked with "frame", includes the "frame-member" tag containing the frame variable's name. If we have any instructions tagged with the tag "frame", the prior described code will look into the frame owned by the function identified with the value of "frame" and then tag it with a reference to its name. This way if more than one instruction contains the correct frame in a tag, the prior code will store the name of the variable that is being referenced. We can do the same for the instruction at 0x58bf36 if we determine the caller of the function at 0x590a33. With this, we can then tag 0x58bf36 with the tag name "frame" and the function's address.
CODE:0058BF33 018 8B 40 08 mov eax, [eax+8] ; [frame] 0x590a33
CODE:0058BF33 ; [frame-member] arg_0
CODE:0058BF36 018 8B 40 08 mov eax, [eax+8]
CODE:0058BF39 018 8B 80 54 F9 FF FF mov eax, [eax-6ACh]
CODE:0058BF3F 018 8B D3 mov edx, ebx
Instead of using tags to reference this, however, we can actually do even better. IDA-minsc actually allows us to apply the frame structure itself to an operand via the instruction.op_structure function. To perform this action, we will do the same selection for the "frame" tag and instead of fetching the offset to determine the name of the frame member we will just use instruction.op_structure with the frame structure itself..
Python>for ea, tags in func.select('frame'):
Python> frame = func.frame(tags['frame'])
Python> ins.op_struct(ea, 1, frame)
Python>
This will then result in each tagged instruction having its second operand referencing the frame member that it points to. For the "frame" tag at 0x58bf49, this will look like the following.
CODE:0058BF36 018 8B 40 08 mov eax, [eax+8]
CODE:0058BF39 018 8B 80 54 F9 FF FF mov eax, [eax-6ACh]
CODE:0058BF3F 018 8B D3 mov edx, ebx
CODE:0058BF41 018 E8 EA BE E7 FF call sub_407E30
CODE:0058BF46 018 8B 45 08 mov eax, [ebp+ap_frame_0]
CODE:0058BF49 018 8B 40 08 mov eax, [eax+($ F590728.arg_0-0Ch)] ; [frame] 0x590a33
There are a number of features within IDA-minsc that allow users to programmatically interact with the various parts of a binary that IDA exposes to a reverse-engineer. Among the features we mentioned above, this plugin also contains various tools provided in the "structure" module, and can use function.frame() to query the variables belonging to the stack frame of a particular function. We recommend the user run Python's help() keyword against these modules to see exactly what is available or to visit the documentation here.
Although a lot of this could've been done with a debugger and some clever breakpointing as with most reverse-engineering tasks, we believe there is a significant benefit to the user being able to script the annotation of the code that they are disassembling. By having a consistent, non-verbose API where most of each function’s parameters can be determined automatically, this plugin reduces the time the user needs to invest in developing a solution that automates the work of a reverser. A reverse engineer can use this to approach a larger-scale project with a more complex target without having to worry about a massive time commitment.
Again, please visit the repository located at GitHub to download the plugin and try it out. If you enjoy the plugin, please “star” it and refer to the CONTRIBUTING.md file within the repository for any reported issues or contributions.

|
|