这是一个使用scrapy框架的爬虫。
其中包括了爬取地方发改委、国家发改委网站的spiders,涉及到写出文件、存入数据库等,以及网页地址不变的、包含js动态网页、包含验证等等,其中国家发改委网站有很多坑,以后慢慢讲一讲。 还包括了使用scrapy-splash对动态网页的爬取,跑的是网上的例子,爬取京东网站。 (爬取动态网页还有一种方法,是selenium)
这个过程使用了一个比较方便的chrome插件,toggle JavaScript,屏蔽js。(为什么要屏蔽js?当不用类似scra-splash这些能解析js的包时,scrapy获取的response 只是右键查看网页源代码的,不包含解析js后的,因此在选择xpath的时候,可能会有问题)
- firstspider.py 是使用scrapy的第一个例子,爬取一个页面上的标题。
- douban_spider.py 也是参考简书的帖子,爬取豆瓣top250的电影,并存到csv中。
- pro.py 是新疆发改委网站下的页面,爬取其中的公开项目及具体内容,需要自动翻页,并且获取每一页的所有子链接,并且跳入子链接进行具体内容的爬取。
- jsSpider 是国家发改委的页面(好多坑。。。建议亲自跑一遍),需求跟上一个一样,但是首先,发改委网站是加载js的以及网页地址是不变的,以及post,而且是.aspx,它本身有一个反爬虫机制。
- SplashSpider.py是运用scrapy-splash进行京东网站的js爬取,很简单,跟着做了一遍,可参考
这里网上资源很多,这里就不重复了,我当时主要是看了这位大神的,可以参考下。
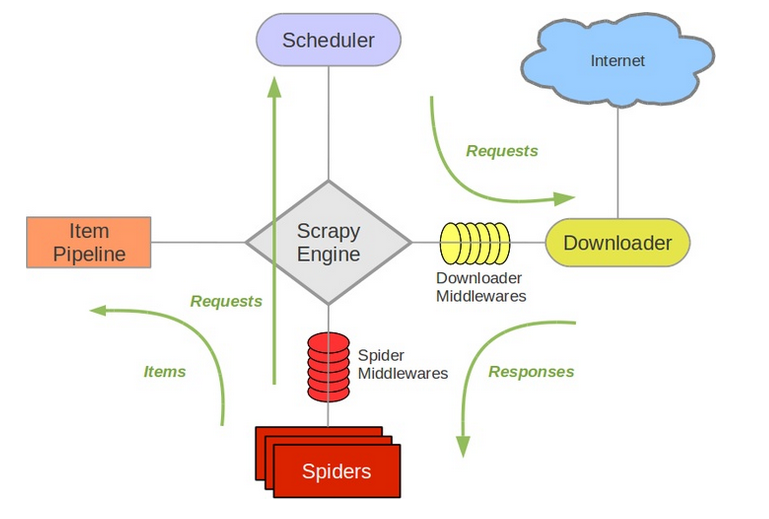
注意spiders文件夹下的spider可以有多个,对应多个爬虫,因此要运行哪个在begin.py中修改命令scrapy crawl %爬虫名字 即可,注意这里的爬虫名字是你class第一行的name=“”
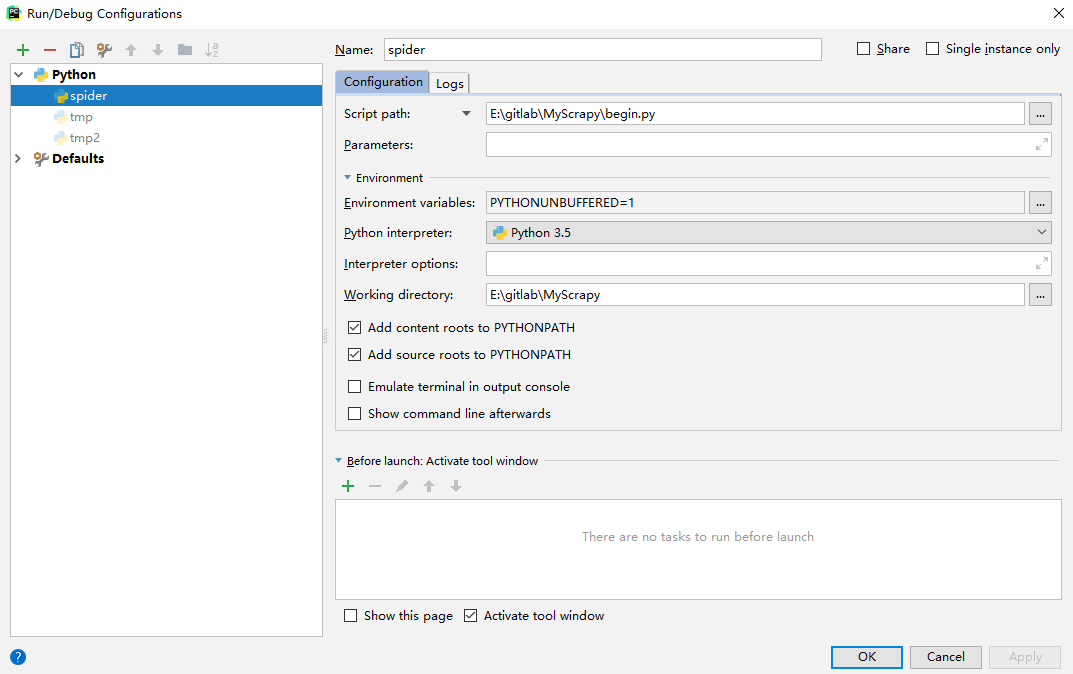
然后点击RUN-EDIT CONFIGRATIONS,加号选python文件,然后设置一下名字和目录,就可以看到运行按钮了~~~如下图
- xpath
-
xpath提取多个标签下的text; 例如:现在想获得以下html中的文字:
<div id="test3">我左青龙,<span id="tiger">右白虎,<ul>上朱雀,<li>下玄武。</li></ul>老牛在当中,</span>龙头在胸口。<div>
解决方法:使用xpath的string(.)
data = selector.xpath('//div[@id="test3"]')
info = data.xpath('string(.)').extract()[0]现在就可以获得所有的text了
-
选择xpath的时候,tbody是不存在的(是浏览器自己加的)。
-
在选xpath的时候,需要屏蔽js。
-
登录
cookiejar -
动态页面面
selenium
splash
-
验证码
-
(1)人工识别:
将图片保存下来,通过python脚本获取该图片,保存在本地,在python命令行中采用input()方式,人工识别后输入该验证码
-
(2)图片验证码
Selenium + pillow + tesseract(或baidu_api)
图像处理库 OCR识别API -
(3)滑动验证码:
可以对两张图片(完整和缺口)进行对比,获得偏移量,然后用selenium进行模拟移动。注意,这种方法的前提是两张图片
-
(4)现在还有用canvas的js前端生成验证图片的,怎么搞?
- 反爬虫
- 翻页
- (1)如果可以获取总页数,for循环或者当前页与总页数比较,访问下一页的链接即可;也就是我们点击页面上“下一页”的效果;
- (2)直接在网址后带页数参数访问;
- (3)post传递参数;
- (4)总页数不知道,下一页是靠js的,就需要获取页面选中元素,那如何判断是否到最后一页了呢?看下一页无法点击时便可。检测disabled标签,但是首页也会出现这个,因此需要处理一下
-
得到的结果很少?延时试试
可能就是解析的速度没跟上???因此,又各种百度试验之后,在settings.py中加入DOWNLOAD_DELAY=1
-
其他问题
参见个人笔记