tp 01
One step at a time.
create table searchable_content (
rowid bigint primary key generated always as identity,
domain64 bigint not null,
path text not null,
tag text default 'p' not null,
content text not null,
fts tsvector generated always as (to_tsvector('english', content)) STORED
);
This is the simplest possible approach we can take: one content table, that can be filtered on the domain64 value.
Then, inserting ~5GB of content into the table:
with data as
(
select domain64, path, tag, content
from raw_content
)
insert into searchable_content (domain64, path, tag, content)
select * from data;
This provides a collection of content from many domains, including NASA. There's no optimization (other than pre-computing the tsvector), and no filtering.
Copying the data takes around 20m. 1.3M rows. The raw content of 5GB expanded to close to 10GB once the tsvector column came into the mix.
Working with a query that looks for moon landing against the NASA blogs...
@set query='(moon | moon:*) & (landing | land:*)'
@set d64_start=x'0100008700000100'::bigint
@set d64_end=x'0100008700000200'::bigint
explain (ANALYZE, COSTS, VERBOSE, BUFFERS, FORMAT JSON)
select
to_hex(domain64),
path,
ts_rank_cd(fts, query) AS rank,
ts_headline('english', sc.content, query, 'MaxFragments=3, MaxWords=7, MinWords=3') as Snippet
from searchable_content sc,
to_tsquery('english', :query) query
where
domain64 >= :d64_start
and
domain64 < :d64_end
and
fts @@ query
order by rank desc
limit 10
;
which runs as

create index if not exists domain64_idx on searchable_content (domain64);
create index if not exists tag_idx on searchable_content (tag);
create index if not exists idx_gin_paths on searchable_content
using gin (to_tsvector('english', path));
create index if not exists idx_gist_paths on searchable_content
using gist (to_tsvector('english', path));
create index if not exists idx_gin_bodies on searchable_content
using gin (to_tsvector('english', content));
create index if not exists idx_gist_bodies on searchable_content
using gist (to_tsvector('english', content));
-- This uses a new FTS vector column. Pre-compute for speed.
create index sc_fts_idx on searchable_content using gin (fts);
This takes ~45m.
The same query now looks like:
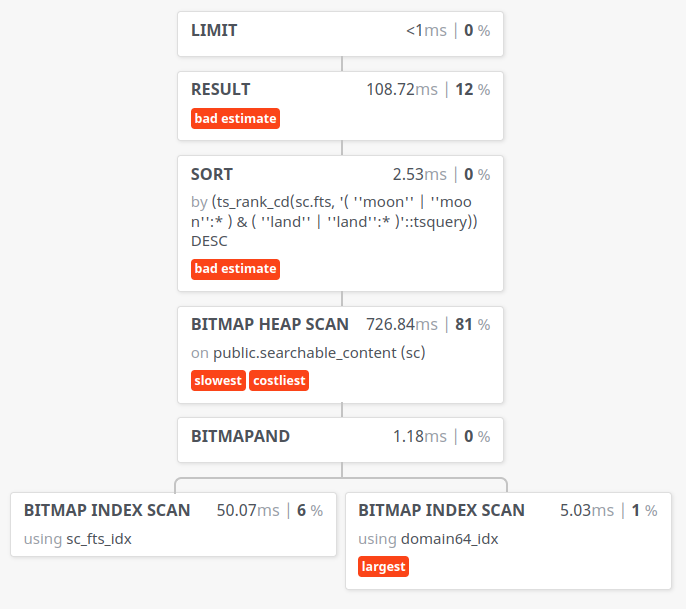
This looks to take us down closer to 1s.
Does it make sense to index both the domain64 and content?
create index if not exists many_idx on searchable_content using gin (domain64, fts);
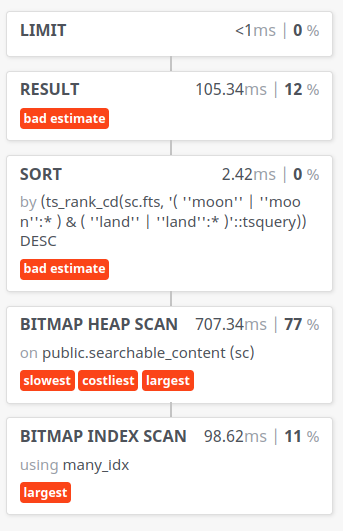
Not substantially.
What about this query?
select
to_hex(domain64),
path,
ts_headline('english', sc.content, query, 'MaxFragments=3, MaxWords=7, MinWords=3') as Snippet
from searchable_content sc,
to_tsquery('english', :query) query
where
rowid in (680439, 695959, 29992, 79030, 17519, 275658, 226797, 1268343, 1299466, 399534)
;
This assumes an oracle that knows what rows we need for a given search.
This is around 120ms.
If I index t he rowids... no real difference.
The approach here would be to use SQLite's FTS5 for the search, get back row IDs, and then do a query against Postgres, where we would keep the content. The FTS in SQlite is very, very fast. (Initial tests suggest that FTS against the NASA blogs is around 8ms.) For just the NASA blogs, this is around (arguably) 30K rows, and 100MB of index. (We can probably filter a lot of things out of the NASA dataset, because a lot of the blog entries are actually duplicates under /category and /tag paths due to the CMS.)
This assumes an architecture where:
- The API call comes in.
- It is routed to a host that has the SQLite FTS index (but not content)
- The FTS query is made against the SQLite index, retrieving row ids.
- We use those row ids to look up the snippets in Postgres
A cache can be built on top of this that caches
domain64/rowid -> snippet
which, as an in-memory cache, is pretty efficient. We could also cache search terms -> listof row ids, but... that might be less valuable.
This approach would... be more complex (we have to build the SQLite indexes), but it would probably be 10x faster than Postgres in terms of the FTS search.
What if we eliminate roughly 50% of the content?
The NASA blogs have a lot of content that is duplicative.
select path
from raw_content
where
domain64 >= x'0100008700000100'::bigint
and
domain64 <= x'0100008700000200'::bigint
and
tag = 'body'
and
path not ilike '%/category/%'
and
path not ilike '%right%here%'
and
path not ilike '%/tag/%'
and
path not ilike '%/author/%'
and
path not ilike '%/page/%'
and
path not ilike '%wp-login%'
and
path not ilike '%wp-content%'
and
path !~ '/\d{4}/\d{2}$'
is an example of everything that can probably go. The original blog posts are all still present under a /YYYY/MM pattern, and the /category, /author, and /tag pages are all just the same content, but structured for browsing.
This also (as an example) eliminates all PDF content, because it gets rid of the wp-content paths. Should we index PDFs? Probably. But, we could also have PDF search be separate. But really, government is supposed to be publishing content to the WWW, not PDF.
This eliminates 28K rows.
Now... the query above takes... 800ms.
Not a lot of savings.
Getting rid of more rows... down to maybe 720ms.
https://stackoverflow.com/a/66269809
Quite often the slow search query is useless, which means optimizing it is a waste of time.
If there are 24037 records matching "cancer" then searching on this single term will never return relevant results to the user. Therefore it is pointless to sort by relevance. What could be more useful would be a bunch of heuristics, for example: if the user enters only one search term, display most recent articles about this term (fast) and maybe offer a list of keywords often related to this term. Then, switch to "ORDER BY rank" only when the user enters enough search keywords to produce a meaningful rank. This way you can implement a search that is not just faster, but also more useful.
Maybe you will say, "but if I type a single word into google I get relevant results!" and... yes, of course, but that's because google knows everything you do, it always has context, and if you don't enter extra search terms, it will do it for you.
This is important to consider.
If someone searches for "moon" or "space" on the NASA blog, they're going to get somewhat meaningless results; these are both in the top 10 of terms in the entire blog.
So, running different kinds of queries for different kinds of query statements might be reasonable. (Also, having ways to build more context, to limit the results.)
Also, I need to think about the limits that PG imposes:
https://www.postgresql.org/docs/9.3/textsearch-limitations.html
- The length of each lexeme must be less than 2K bytes
- The length of a tsvector (lexemes + positions) must be less than 1 megabyte
- The number of lexemes must be less than 264
- Position values in tsvector must be greater than 0 and no more than 16,383
- No more than 256 positions per lexeme
- The number of nodes (lexemes + operators) in a tsquery must be less than 32,768
This suggests some cleanup of the text inserted is a very good idea. Perhaps pulling the most common terms? (Or, using the most common terms as a pre-built kind of facet?)
Hm. If the top 100 terms... they could be their own kind of index. A column called top100, and insert all of the terms that are in that category there. Then, FTS that first? Or... something. But, the point being, there must be a way to pull high-frequency terms out, or otherwise simplify the body text of these log posts?
https://stackoverflow.com/a/20637947
Suggests that using a common term will lead to sequential scans. Which... is what I'm seeing.
GIN indexes are not lossy for standard queries, but their performance depends logarithmically on the number of unique words. (However, GIN indexes store only the words (lexemes) of tsvector values, and not their weight labels. Thus a table row recheck is needed when using a query that involves weights.)
Partitioning of big collections and the proper use of GiST and GIN indexes allows the implementation of very fast searches with online update. Partitioning can be done at the database level using table inheritance, or by distributing documents over servers and collecting search results using the dblink module. The latter is possible because ranking functions use only local information.
Also: https://dba.stackexchange.com/a/56232
also, precomputing the common words: https://dba.stackexchange.com/a/149701
Hah. OK. So, unique terms and partitioning.
Let's try partitioning.
If we're going down the FTS route in Postgres, it is looking like we need to slim the corpus.
Searching all of NASA yields search times that are around 3-5 seconds. This is not acceptable for RT/FTS (real-time, full-text search).
... Postgres does most of this...
But, still, there must be a way to optimize this.
- The GIN index isn't enough straight out of the box. We end up with a lot of long documents. Can those be trimmed? Cleaned?
There are a lot of things that get mangled with URLs and paths. Those could be cleaned up/removed.
Anything over 12 characters might be a candidate for removal. (Or, pick a length N.)
It is unlikely that we have abbreviations... acroynms, maybe, but probably not things like "LOL"
plain language suggests we should have contractions. so, expanding those (or, removing them outright) for search prep might be a good idea.
getting rid of diacritics so we reduce down to ASCII might be a good step?
normalized_text = unicodedata.normalize('NFKD', text).encode('ASCII', 'ignore').decode('utf-8')
collapse all whitespace.
norm = ' '.join(text.split(' '))
def remove_url(text):
return re.sub(r"(https|http)?:\S*", "", text)
what happens if we throw out long tsvectors?
- https://medium.com/@gourav.didwania/step-1-a-comprehensive-guide-to-text-cleaning-36ae5077f15
- https://b-greve.gitbook.io/beginners-guide-to-clean-data/text-mining-problems/special-characters
- https://www.analyticsvidhya.com/blog/2022/01/text-cleaning-methods-in-nlp/
- multilingual/thorough: https://peterullrich.com/complete-guide-to-full-text-search-with-postgres-and-ecto
- postgres explain visualizer: https://github.com/AlexTatiyants/pev
- a good overview of postgres fts: https://remimercier.com/postgresql-full-text-search-for-beginners/
- one approach to misspellings: https://stackoverflow.com/questions/59843904/postgres-full-text-search-and-spelling-mistakes-aka-fuzzy-full-text-search
- optimizing fts: https://www.lateral.io/resources-blog/full-text-search-in-milliseconds-with-postgresql
- fts performance considerations: https://medium.com/database-dive/probing-text-data-using-postgresql-full-text-search-5c3dcee5854a
- Using Elastic as a throwaway behind the Postgres FTS: https://news.ycombinator.com/item?id=36699016
- https://xata.io/blog/postgres-full-text-search-postgres-vs-elasticsearch
- keywords/tf-idf in Postgres: https://www.alibabacloud.com/blog/keyword-analysis-with-postgresql-cosine-and-linear-correlation-algorithms-for-text-analysis_595793
- (^^^ has a lot of good articles to mine)