Scrivener is a program for all kinds of writers, handling the structural organisation and constructive process of writing like nothing else. You write and mange your text, ideas, figures and reference materials all in one place without having to worry about the final "look". The final "look" is handled by a process called compiling, where you choose the output format and select the contents with great flexibility. Although Scrivener uses rich text internally, it has excellent integration with plain text markdown. Compiling your Scrivener projects via markdown offers numerous advantages over rich text: it creates more structured, beautiful and flexible documents without lots of fussing in a Word processor or layout software. For example:
- Binder headings are automatically converted into semantic heading levels.
- Figures and figure captions get proper styling.
- Semantically styled block quotes, code blocks (with full syntax highlighting), and many inline styles.
- Mathematical equations are properly parsed to many output formats.
- You can generate multiple outputs (EPub3, HTML, PDF, LaTeX, DOCX, ODT) simultaneously from a single compile; and trigger further tools to automate many workflows.
- You can use a Microsoft Word/LibreOffice source file to provide all page setup and customised styles without any fussing in a word processor afterwards.
- For academics, using Pandoc as the markdown processor enables generation of a full Bibliography.
- For technical writers, you can add semantic custom block and span structures (warning or info boxes for example).
- For LaTeX users, there is a lot of flexibility using rich templates and meta-data.
This save you lots of time, especially if you compile regularly during collaborative editing.
Because of Pandoc's great flexibility, there are many possible settings to configure. To simplify this, you can run Pandoc using "template" tools like Pandocomatic. For each document output, the template specifies all the options in Scrivener front-matter and/or a seperate configuration file. Pandocomatic templates allow you to run pre– and post–processors for more complex workflows (i.e. you could automate moving a HTML file to a web server after Scrivener compile). To use the Pandocomatic templates with Scrivener, you specify their name in the front–matter or metadata, and all the settings are automated when Pandoc is run.
Scrivener already comes with Multimarkdown, but I really do think that Pandoc provides additional benefits and installation is simple. I also use Pandocomatic as a way to flexibly manage Pandoc settings (although this is optional if you are happy to specify the options yourself).
- Install the latest
pandocandpandocomatic. - Configure one or more templates; you can base them on mine shared below.
- In Scrivener, use a front-matter document containing the required settings and compile via the MultiMarkdown format (this option generates Pandoc output too). I offer a compile format for you to use.
- Scrivener's compile post-processing triggers
pandocomatic, automagically creating the final output(s) for you.
As a teaser for the full workflow, you can download a sample Scrivener project which bundles all the required files into the Binder (instructions included there to set up, you will still need to install pandoc and pandocomatic first).
Apart from Scrivener (V3.x is highly recommended for this workflow), you should install Pandoc and Pandocomatic. This requires a minimal amount of typing into the macOS terminal. You can install pandoc directly, but IMO it is better to use Homebrew to install pandoc, as it can help keep everything up to date (pandoc receives regular automatic updates via homebrew). So first, follow the instructions to install Homebrew (info for the security conscious), and then install pandoc using the brew command in the terminal:
brew install pandoc pandoc-citeproc pandoc-crossrefIf you already installed pandoc manually, but want to use brew, then you can use brew link --overwrite ... instead of brew install .... You can run the command brew upgrade every so often to ensure these tools are kept up-to-date.
NEWSFLASH: Recently pandocomatic broke compatibility with the ancient version of Ruby in macOS, and so you need to install a newer version of Ruby first, see Installing Ruby for more details!
You use Ruby's gem command to install pandocomatic:
gem install pandocomatic To keep both Pandoc and Pandocomatic up-to-date, you can run the update commands like so every week or so:
brew upgrade; gem update paru pandocomaticThe most important folder for this workflow is the Pandoc data directory: since Pandoc V2.7 it is $HOME/.local/share/pandoc ($HOME is your user directory, for example /Users/johndoe/; previous to V2.7 the folder was found at $HOME/.pandoc). Though not required, it is recommended to organise all your templates, filters and other files within this folder (pandocomatic uses the Pandoc data directory by default). To create your $HOME/.local/share/pandoc folder:
> mkdir -p ~/.local/share/pandocAll folders starting with a . are a hidden by default, but you can open them in Finder in two ways: 1) using the shortcut ⌘+SHIFT+G and typing the path, in this case ~/.local/share/pandoc; or 2) using the Terminal and typing:
> open ~/.local/share/pandocYou can explore my working Pandoc folder here. It is comprised of a series of subfolders of files Pandoc and pandocomatic use during converison. You can install my Pandoc folder by downloading it and unzipping its contents into your $HOME/.local/share/pandoc, or if you know how to use git you can just clone (or fork) it from Github.
pandocomatic uses a configuration file usually stored at the root of the Pandoc data directory: $HOME/.local/share/pandoc/pandocomatic.yaml. A simplified sample pandocomatic.yaml is viewable here; this won't work without customisation, but it gives you an idea of how pandocomatic-templates work (full documentation here). The basic idea is you create several pandocomatic-templates, and each pandocomatic-templates collects together a bunch of settings and configurations to produce a particular output. So I have docx pandocomatic-templates which is a basic Word conversion, but also a docx-refs which runs the bibliographic tools to generates a bibliography automatically for a docx file output.
For the rest of the files in the Pandoc data directory: all custom Pandoc templates reside in $HOME/.local/share/pandoc/templates, and Pandoc filters in $HOME/.local/share/pandoc/filters. For bibliographies, I symbolically link my Bibliography.bib into in $HOME/.local/share/pandoc and store my Journal style files in $HOME/.local/share/pandoc/csl. pandocomatic enables the use of pre– and post–processor scripts and these are stored in their own subfolders.
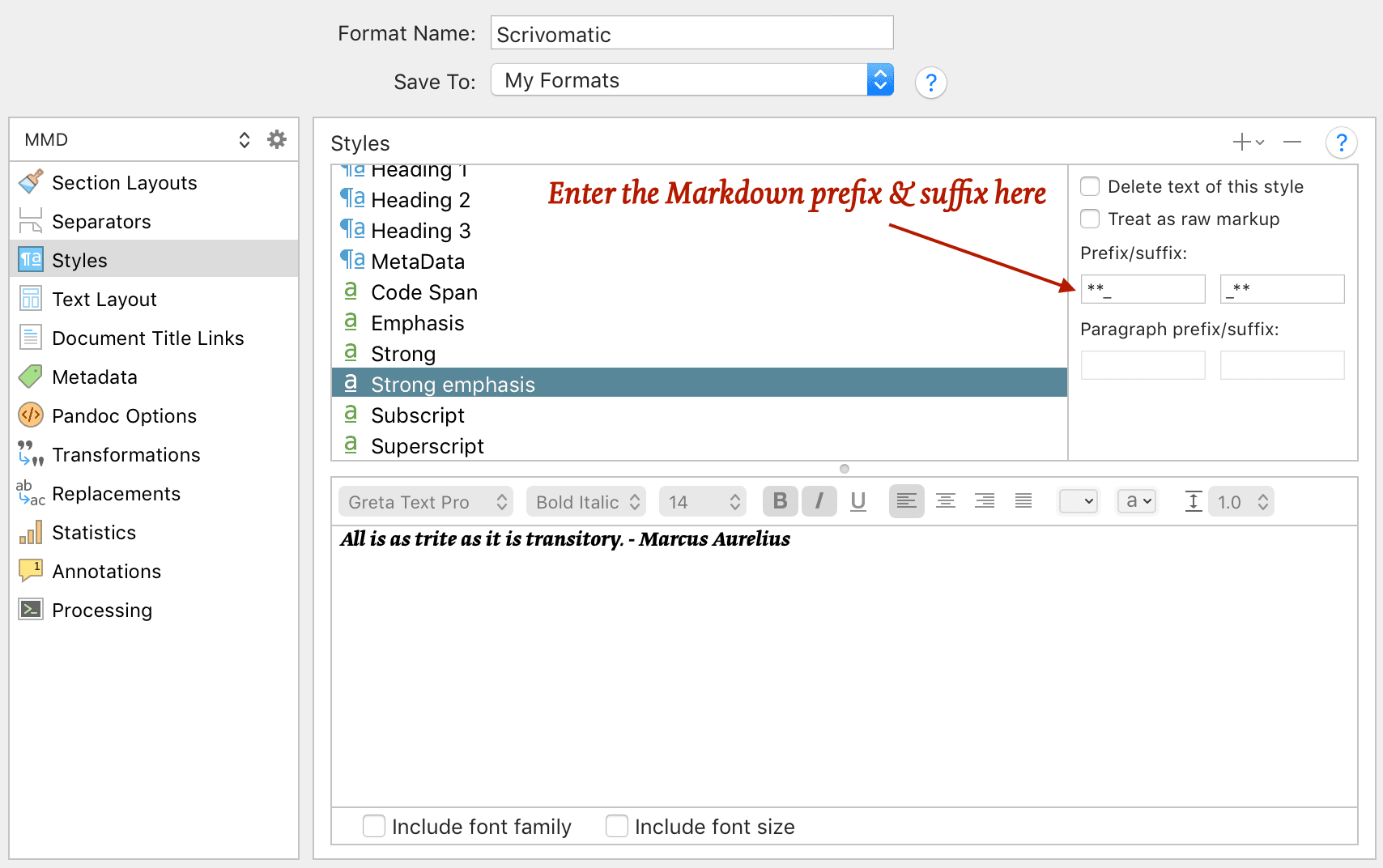
With Scrivener 3's new styles system (§15.5 user manual), there is a huge change to how you can write with markdown. You can use named paragraph styles (like "blockquote"), and named inline styles (like "emphasis" or "superscript") as you would writing in rich text (i.e. there is no need to add markdown syntax in the editor!) With the new compile system (§23—user manual), Scrivener can add a prefix/suffix to create the required plain-text markdown. So for example, create an inline style called strong, and in compile set the prefix to ** and suffix to ** and Scrivener automates conversion from the style to markdown! You can then rebind ⌘I and ⌘B to trigger the emphasis and strong styles directly. In Scrivener 2, you can still use formatting presets, but these will always be stripped out during the compile, so you need to write the markdown directly in the editor. I used to use formatting presets to visualise markdown structure in Scrivener 2 (block quotes, code blocks, lists, tables, figure captions). But in Scrivener 3, I now use Scrivener styles to visualise structure and generate the Pandoc markup itself:

You can download my customised Scrivener 3 compile preset here. Install it to get a flavour of how one can convert styles to markdown, and it now has the scrivomatic script built-in (needs Scrivener V3.03).
Because markdown is sensitive to whitespace, you should aim to use whitespace consistently: For a new paragraph and between any blocks of content I always use spacespacereturnreturn. It is automatic for me, but showing invisible characters in the Scrivener editor makes potential formatting issues when compiling simple to fix. Enable it using View ▶︎ Text Editing ▶︎ Show Invisibles, and change their colour in Preferences ▶︎ Appearance ▶︎ Textual Marks ▶︎ Invisible Characters.
Try not to not use markdown # headings within text documents themselves but create documents at the correct level hierarchy in the Binder. Scrivener is great at compiling the levels of the Binder structure into the correct heading levels for you, and you benefit from being able to use the outlining and organisation tools within Scrivener.
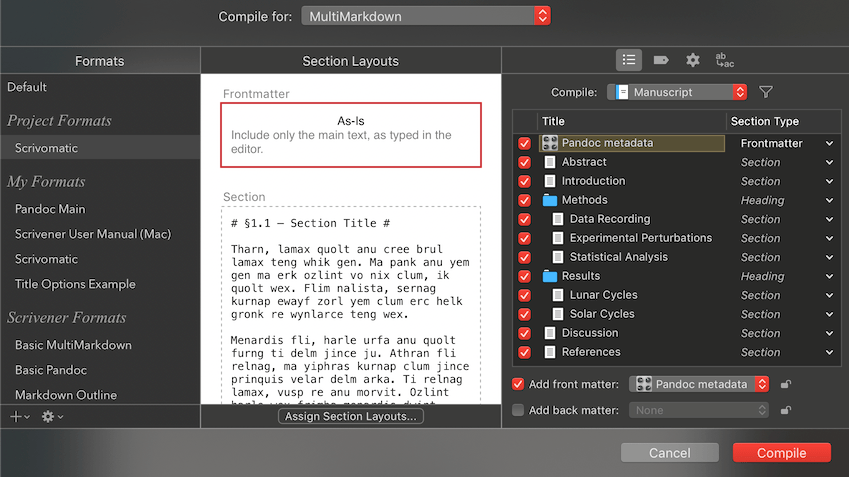
Scrivener can transform images that are embedded with a line of text (§21.4.1 user manual) into markup that generates proper semantic <figure> and <figcaption> elements. I now prefer to link images (Fig. 21.2—user manual) from the binder rather than by using the standard Pandoc markup: {.my_style}; in both cases (embedded or linked-from-binder) Scrivener will correctly export the image file into the compile folder. Scrivener 3 has a nice new feature where you can binder-link figures (Insert ▸ Image Linked to Document), they are not embedded but still visible in the document, to add a caption to these you can use a caption style or [] brackets around the caption (described at the end of §21.4.1—user manual).
Scrivener will automatically convert footnotes into Markdown format for you. But there is one caveat in that you are not allowed to style footnotes, and so if you want to use emphasis / strong or other character styles, you will have to use the Pandoc formatting directly.
Use comments and annotations freely. Scrivener 3 now allows you to transform comments to complex markup (§24.19.7—user manual) where the comment text <$cmt> AND the comment selection <$lnk> are both correctly exported). This can be set in compile ▶︎ annotations… — I use: <span class="comment" title="<$cmt>"><$lnk></span>. For export to DOCX, you can use <span class="comment-start" id="<$n>" author="<$author>" date="<$date>"><$cmt></span><$lnk><span class="comment-end" id="<$n>"></span>, which should transform into proper Word comments with using Pandoc 2+.
I prefer Scrivener links to cross-reference documents / export figures, and Scrivener's placeholder tags to cross-reference figures and equations. But for new users Pandoc does have several cross-referencing filters (pandoc-crossref and pandoc-fignos for example) and you can also use these.
In Scrivener, I remove all compile–metadata specified in compile user interface so it does not interfere with my custom metadata document. I create a document called front–matter with a configuration block right at the top (read more detailed documentation here). You can use Scrivener placeholder tags in this document (Help ▸ List of All Placeholders…). One small warning: Scrivener's autocorrect will "smarten" quotation marks and dashes, which will cause problems for Pandoc so please straigten quotes and ensure the 3 hyphens are not converted into an em dash — also indentation in the metadata block must be spaces and not tabs. In the example below, two templates are specified, and pandocomatic will run Pandoc twice to generate both a HTML & DOCX file from the same single Scrivener compile:
---
title: "<$projecttitle>"
author:
- Joanna Doe
- John Doe
keywords:
- test
- pandoc
pandocomatic_:
use-template:
- paper-with-refs-docx
- paper-with-refs-html
---
This front–matter should be the first document in the compile list and compiled as–is.
The Pandocomatic configuration template could look something like the example below for the DOCX template specified above (generating a bibliography using the APA style (with linked citations) and a table of contents):
paper-with-refs-docx:
pandoc:
from: markdown
to: docx
standalone: true
filter: pandoc-citeproc
bibliography: ./core.bib # ./ means same directory as markdown file
citation-style: csl/apa.csl
reference-docx: templates/custom.docx
toc: true
metadata:
notes-after-punctuation: false
link-citations: trueIn Scrivener, you select Multimarkdown as the compile document output and select a compile format that configures a post-processing tool to run pandocomatic automatically.
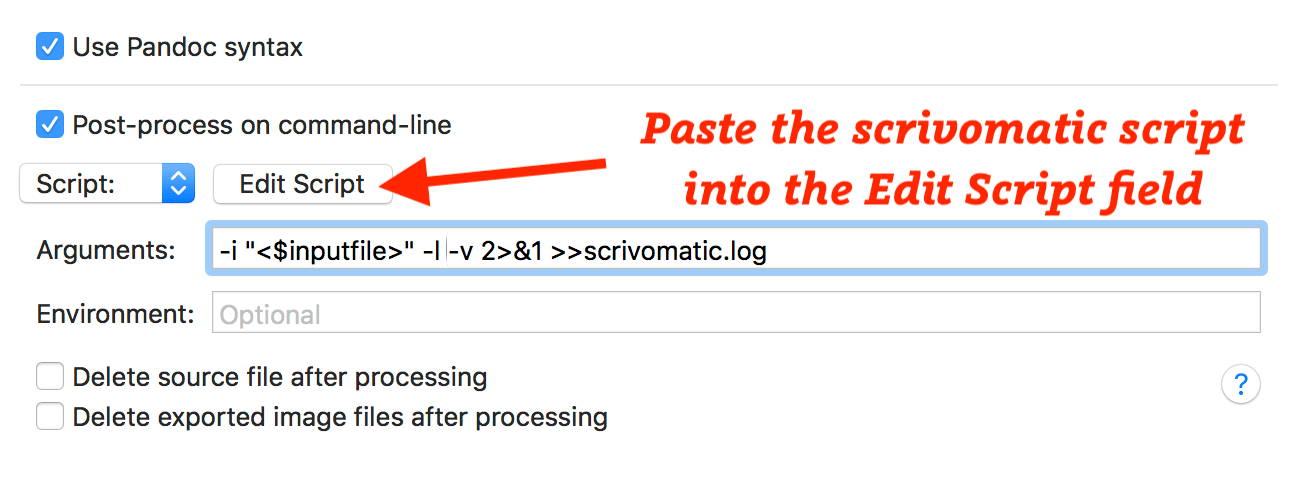
You can run pandocomatic directly from Scrivener's post-processing panel, but you may need to ensure the Environment path is set up so Scrivener can find all the files and the other tools properly. Scrivomatic is a small wrapper script (yes, welcome to the rabbit hole 🙃!) that handles this for you…
It adds the paths for tools installed via homebrew, MacTeX and Cabal; and if you've used rbenv, rvm or conda to install pandocomatic/panzer, it adds these paths too. It can also generate a detailed log file of the conversion (so you can check for missing references or other problems etc.). The easiest way to install it is to copy the raw code from here: scrivomatic, then you want to install it by pasting it into the Post-processing Edit Script edit field (leave Shell blank). You then configure the Arguments field (adding different flags to control scrivomatic, e.g. -l opens scrivomatic.log in Console automatically):
You can also download the script to your Downloads folder, move it to a directory on your path, and make sure it can be executed like so:
mkdir -p $HOME/bin
mv $HOME/Downloads/scrivomatic $HOME/bin
chmod 755 $HOME/bin/scrivomaticYou can then run scrivomatic from terminal with the following command line options:
Usage: scrivomatic [additional options] FILE
-i, --input FILE Input file
-o, --output [file] Output file. Optional for pandocomatic.
-t, --to [format] Pandoc Format. Optional for pandocomatic.
-y, --yaml [file] Specify which YAML file for pandocomatic.
-c, --command [command] Tool to use: [pandocomatic] | panzer
-p, --path [dirpath] Additional Path to Search for Commands.
-b, --build For LaTeX output, run latexmk
-B, --buildclean For LaTeX output, run latexmk and cleanup
-d, --dry-run Dry run.
-z, --data-dir [file] Pandoc data dir.
-v, --[no-]verbose Verbose output.
-l, --[no-]log View log in Console.app.
-h, --help Prints this help!
I also include an Alfred workflow so you can run scrivomatic directly from markdown files selected by Alfred:
There are two recent features added to Pandoc, Fenced Divs and Custom Styles (see also bracketed spans), that when combined, enable any arbitrary custom Scrivener paragraph or character styles to be converted into Word styles or CSS classes. So for example, we can create an "Allegory" paragraph style in Scrivener, and in the Compiler style we use the fenced div syntax prefix=\n::: {custom-style="Allegory"} :::\n & suffix=\n:::\n (\n means enter a return, done using option+return in the edit box) which would generate a fenced div like so in the compiled Pandoc file:
::: {custom-style="Allegory"} :::
All animals are equal but a few are more equal than others
:::Pandoc will then attach a word style named "Allegory" to that paragraph in the output DOCX. You can either edit the style in Word, or edit your reference.docx to include this custom style, so it already styled when you open the DOCX.
Bookends is an excellent reference manager for macOS which can be configured to output temporary citations for Scrivener in a format fully compatible with Pandoc. To set this up I'd first follow the excellent tutorial here:
To export your references as a file Pandoc can read (usually a BibTeX file) you can do tht manually from the Bookends GUI. However, you can do this automatically every day or so using this applescript, you can specify an output folder and comma-separated list of groups via command-line input. This script can also be run directly from Bookends Tools for Alfred. I would recommend setting the option to save a JSON instead of BibTeX as Pandoc parses the JSON ~3X faster when processing documents, and with a big reference database that can save quite a lot of time!
I prefer to use the minimal LaTeX installer found here: BasicTeX Installer — and for Pandoc's templates to work I've determined the following additional packages are needed (installed easily with tlmgr):
sudo tlmgr install lm-math lualatex-math luatexja abstract \
latexmk csquotes pagecolor relsize ucharcat mdframed needspace sectsty \
titling titlesec preprint layouts glossaries tabulary soul xargs todonotes \
mfirstuc xfor wallpaper datatool substr ctablestack ifetex adjustbox collectbox