kubesql is a tool to use sql to query the resources of kubernetes.
The resources of kubernetes such as nodes, pods and so on are handled as tables.
For example, all pods are easily to list from apiserver. But the number of pods on each node is not easy to caculate.
presto:kubesql> select nodename, count(*) as pod_count from pods group by nodename;
nodename | pod_count
---------------+-----------
10.111.11.118 | 8
(1 row)
Query 20200513_094558_00006_7cycm, FINISHED, 1 node
Splits: 49 total, 49 done (100.00%)
0:00 [8 rows, 0B] [48 rows/s, 0B/s]
In case the kubeconfig file is located at /root/.kube/config. Just run and enjoy.
docker run -it -d --name kubesql -v /root/.kube/config:/home/presto/config xuxinkun/kubesql:latest
docker exec -it kubesql presto --server localhost:8080 --catalog kubesql --schema kubesql
TODO
kubesql makes use of presto to execute the sql.
There are three main modules in kubesql:
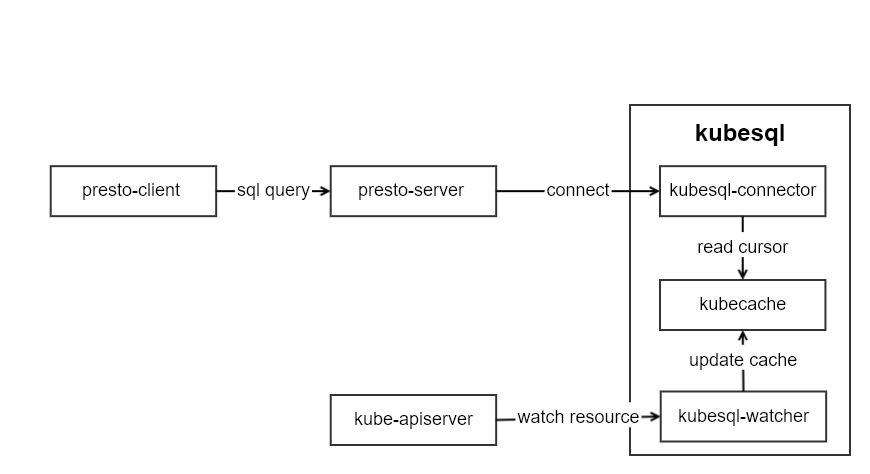
- kubesql-watcher: monitor k8s api pod and node changes. And convert the structured data of pod and node into relational data.
- kubecache: used to cache pod and node data.
- kubesql-connector: as presto connector, accept calls from presto, query column information and corresponding data through kubecache, and return to presto about column and data information.
Since all data is cached in memory, there is almost no disk requirement. But it also needs to provide larger memory according to the size of the cluster.
Taking pod data as an example, the main data in the pod is divided into three parts, metadata, spec, and status.
The more difficult parts of metadata are labels and annotations. I flatten the label map, each key is used as a column.
labels:
app: mysql
owner: xxx
labels word is used as the prefix, and put the keys of the labels as the column names. Thus two pieces of data are obtained:
labels.app: mysql
labels.owner: xxx
For pod A there is an app label but pod B does not have the label, then for pod B, the value of this column labels.app is null.
Annotations are handled similarly. Thus, annotations can be used to filter pods.
For spec, the biggest difficulty lies in the handling of containers. Because there may be several containers in a pod, I will directly use containers as a new table. At the same time, a uid column is added to the containers table to indicate which pod this row of data comes from.
The fields in the containers are also added to the containers table.
The more important information in containers is request and limit.
requests. is used as the prefix, and joined the resource name as a column name.
For example, requests.cpu, requests.memory, etc. Here, the CPU is processed as a double type and the unit is a core.
For example, 100m will be converted to 0.1.
The memory is bigint and the unit is B.
For status, conditions and containerStatus are more difficult to deal with. The conditions are a list, but the type of each condition is different.
So type is used as the prefix to generate column names for conditon. such as:
conditions:
- lastProbeTime: null
lastTransitionTime: 2020-04-22T09:03:10Z
status: "True"
type: Ready
- lastProbeTime: null
lastTransitionTime: 2020-04-22T09:03:10Z
status: "True"
type: ContainersReady
Then in the pod table, these columns can be found:
| Column | Type | Extra | Comment |
|---|---|---|---|
| containersready.lastprobetime | timestamp | ||
| containersready.lasttransitiontime | timestamp | ||
| containersready.message | varchar | ||
| containersready.reason | varchar | ||
| containersready.status | varchar | ||
| ready.lastprobetime | timestamp | ||
| ready.lasttransitiontime | timestamp | ||
| ready.message | varchar | ||
| ready.reason | varchar | ||
| ready.status | varchar |
In this way, pods can be filtered for type ready and status True with condition "ready.status" = "True".
Since containerStatus corresponds one-to-one with containers, ContainerStatus are merged with the containers table, and correspond one-to-one with the container name.
Show tables.
descibe {table name} is also supported.
[root@localhost kubesql]# docker exec -it kubesql presto --server localhost:8080 --catalog kubesql --schema kubesql
presto:kubesql> show tables;
Table
------------
containers
nodes
pods
(3 rows)
Query the CPU resources of each pod (requests and limits).
presto:kubesql> select pods.namespace,pods.name,sum("requests.cpu") as "requests.cpu" ,sum("limits.cpu") as "limits.cpu" from pods,containers where pods.uid = containers.uid group by pods.namespace,pods.name
namespace | name | requests.cpu | limits.cpu
-------------------+--------------------------------------+--------------+------------
rrrrqq-test-01 | rrrrqq-test-01-202005151652391759 | 0.8 | 8.0
lll-nopassword-18 | lll-nopassword-18-202005211645264618 | 0.1 | 1.0
Query the remaining CPUs on each node.
presto:kubesql> select nodes.name, nodes."allocatable.cpu" - podnodecpu."requests.cpu" from nodes, (select pods.nodename,sum("requests.cpu") as "requests.cpu" from pods,containers where pods.uid = containers.uid group by pods.nodename) as podnodecpu where nodes.name = podnodecpu.nodename;
name | _col1
-------------+--------------------
10.11.12.29 | 50.918000000000006
10.11.12.30 | 58.788
10.11.12.32 | 57.303000000000004
10.11.12.34 | 33.33799999999999
10.11.12.33 | 43.022999999999996
Query all pods created after 2020-05-12.
presto:kube> select name, namespace,creationTimestamp from pods where creationTimestamp > date('2020-05-12') order by creationTimestamp desc;
name | namespace | creationTimestamp
------------------------------------------------------+-------------------------+-------------------------
kube-api-webhook-controller-manager-7fd78ddd75-sf5j6 | kube-api-webhook-system | 2020-05-13 07:56:27.000
Query based on labels are also supported. Pods with the appid label of springboot, and have not been scheduled successfully.
The label appid exists in the pods table with the column name labels.appid. Use this column as a where condition to query pods.
presto:kubesql> select namespace,name,phase from pods where phase = 'Pending' and "labels.appid" = 'springboot';
namespace | name | phase
--------------------+--------------+---------
springboot-test-xx | v6ynsy3f73jn | Pending
springboot-test-xx | mu4zktenmttp | Pending
springboot-test-xx | n0yvpxxyvk4u | Pending
springboot-test-xx | dd2mh6ovkjll | Pending
springboot-test-xx | hd7b0ffuqrjo | Pending
presto:kubesql> select count(*) from pods where phase = 'Pending' and "labels.appid" = 'springboot';
_col0
-------
5
At present, there are only pods and nodes resources. Compared with the various resources of k8s, it is only a small part. But adding table for each resource requires adding a considerable amount of code. I'm also thinking about how to use openapi's swagger description to automatically generate code.
The deployment is now using docker to deploy, and the deployment method of kubernetes will be added soon, which will be more convenient.
At the same time, I am thinking that in the future, each worker in Presto will be responsible for a cluster cache. Such a presto cluster can query all k8s cluster information. This feature also needs to be redesigned and considered.