Consecutive Kernels with Enqueue(and async) Mode: Single GPU Optimization
(v1.2.7+) If thousands of lightly loaded kernels are needed to be run consecutively without host-device synchronization, enqueue mode can be activated before computations begin and be deactivated after the end. Below example enqueues 3 different array operations with different number of workitems for 10k times and synchronizes with host only on the last line where enqueue mode is disabled. Performance difference versus normal execution is more than 30 times and there is felexibility to use different global range values per compute when compared to "kernel repeat" version where all kernels execute at same global range value.
Enqueue mode compute() is asynchronous to host codes so different CPU - GPU works can be overlapped(such as uploading old results to renderer GPU while new data is computed) but those host codes must be placed just before clearing enqueue mode.
ClNumberCruncher cr = new ClNumberCruncher((ClPlatforms.all().gpus()[0]),kernelString);
cr.enqueueMode = true;
// considering all data is already in GPU so no need to re-get any data
data0.read=false; data1.read=false; data2.read=false;
data0.write=false; data1.write=false; data2.write=false;
for (int i = 0; i < 10000; i++)
{
data0.compute(cr, 1, "vecAdd", 1024); // adds to commandQueue
data1.compute(cr, 1, "vecAdd", 512); // adds to commandQueue
data2.compute(cr, 1, "vecAdd", 256); // adds to commandQueue
}
cr.enqueueMode = false; // equivalent to clFinish(commandQueue)
cr.lastComputePerformanceReport(); // performance report to console
// without enqueueMode: 1200 miliseconds, with enqueueMode: 35 milisecondsThis works only for single GPU number crunchers and device to device pipeline stages. For device to device pipelines, each stage has its own enqueueMode field to enable faster multi-kernel execution per stage(disabled by default) so this must be used with single-device pipeline stages only. Performance gain is similar to number cruncher version and input data is read only once, instead of many times(one for each kernel). Then output is written only once, getting more performance with a simple change in behavior.
v1.2.10 adds async queue mode option to enqueue mode. This runs multiple groups of compute() operations in different queues to overlap their read/write/kernel parts to save time.
Setting async enable value to true selects next available command queue to start enqueuing to:
cruncher.enqueueModeAsyncEnable = true;
multiple groups can be separated by this re-setting to true value line. Clearing disables async mode and remaining compute jobs are enqueued on default queue (queue-0) and serialized with other non-async kernels/reads/writes.
Example code:
cruncher.enqueueMode = true;
// default queue (0)
dataArrayA.nextParam(dataArrayB, constant).compute(cruncher, 1, "vecAdd", 1024 * 1024);
// next concurrent queue(1)
cruncher.enqueueModeAsyncEnable = true;
dataArrayC.nextParam(dataArrayD, constant2).compute(cruncher, 1, "vecMul", 1024 * 1024);
cruncher.enqueueModeAsyncEnable = false;
// default queue(0)
dataArrayE.nextParam(dataArrayF, constant3).compute(cruncher, 1, "vecDiv", 1024 * 1024);
// next concurrent queue(2)
cruncher.enqueueModeAsyncEnable = true;
dataArrayG.nextParam(dataArrayH, constant4).compute(cruncher, 1, "vecAddInt", 1024 * 1024);
dataArrayG.nextParam(dataArrayH, constant4).compute(cruncher, 1, "vecAddInt", 1024 * 1024);
dataArrayG.nextParam(dataArrayH, constant4).compute(cruncher, 1, "vecAddInt", 1024 * 1024);
dataArrayG.nextParam(dataArrayH, constant4).compute(cruncher, 1, "vecAddInt", 1024 * 1024);
cruncher.enqueueModeAsyncEnable = false;
// some C# codes to run asynchronously here since enqueue mode is asynchronous
// updateRenderer()
// calculate user interface
// just before enqueueMode = false assignment
cruncher.enqueueMode = false;timeline graph of this example:
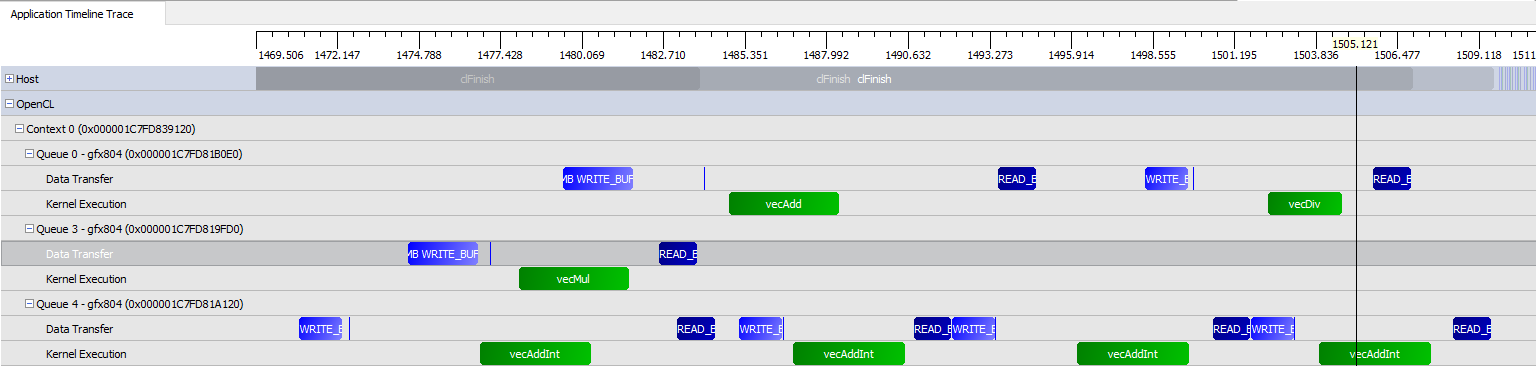
rules:
- a kernel name shouldn't be used in multiple concurrent queues, it means undefined behavior to write same place concurrently
- an array shouldn't be used as an output on multiple concurrent queues, it means undefined behavior again
- nextParam() clones properties of arrays so multiple nextParam instances can be used to define different behaviors in different compute() operations. Changing array properties after nextParam() doesn't change the ClParameterGroup instance.
- CPU host codes can run asynchronously to compute another data if this data is not used in compute().