Audio search
Audio search is the main part of Sushi processing.
Internally all search is performed on downsampled mono WAV streams, using unsigned 8-bit samples. Downsampled rate can be configured using the --sample-rate argument, 12kHz (12000) by default. In general increasing sampling rate leads to better searching but noticeably worse performance. You probably want to set it to 24000 if your script has a lot of short lines. Using downsample rate larger than the original sampling rate results in undefined behaviour.
The following types of events are ignored during the search:
- All comments
- Events that end after the source audio ends (
(start_time + duration/2) > audio_duration) - Events with zero duration (
start_time == end_time) - Events with start/end time identical to some other event (e.g. multiple layers of typesetting)
All these events get linked to some events nearby and inherit the shift from them.
Moreover, the search is not performed on the events themselves - instead Sushi creates so-called search groups. This is mostly required for typesetting and very short lines. Unlike regular events where the corresponding audio segment has some distinct features (someone is talking), typesetting events and short lines might be too small to get any reasonable result from the audio. Therefore Sushi tries to merge these events together. A group of merged events is called a search group.
As most other things in Sushi, events merging is configurable. Using the --max-ts-duration argument you can set the maximum duration of the line to be considered for merging, and using --max-ts-distance argument - the maximum distance between considered events. Two events are merged into a search group if and only if both of them have duration less than the --max-ts-duration, the distance between them is less than the --max-ts-distance and both of them fall in the same chapter group.
Not all search groups make it to the actual search. For every group Sushi checks if there's another group that is a superset of the current one. For example, if one group starts at 05:15 and ends at 05:30 and there's also a group with times 05:00-05:45, all events in the smaller group will be linked to the larger one and only the latter group will be used to calculate shifts.
The actual audio search for every event is performed in two different ways. First, Sushi checks if it can find a closely matched audio sample in a smaller window (currently 1.5 seconds in both directions, 3.0 seconds total). Closely matched means that the result shift is no more than 0.01 seconds different from the shift of the previously processed event. Usually small window works just fine and the result shift is "committed".
Do note that the window is placed around the last event shift point. For example, if the current event starts at 05:30 and the last event was shifted back by 10 seconds, the actual range for the smaller window will be 05:18.5-05:21.5. This makes a lot of sense because every x+1 event is more likely to be closer to the x than it is to the source event.
Now, if small window didn't work Sushi enters the so-called error recovery state. In this state it will start using the larger window controlled with the --window argument (10 seconds in both directions by default, 20 total) and will first calculate shift for the entire search group, then split it in two and calculate separate shift for both halves of the group. This excessive work is needed to see if the search group is actually broken (not found) - in case of missing audio segment results returned by audio search are basically random, meaning that both halves and the entire event will have different shift. If however all of them have almost identical shift value this means that the value is correct, even if it doesn't match the previous' group shift. If this is the case Sushi quits the error recovery state and commits all previous broken events using the found shift.
There is however one problem - what if missing audio segment is too long and Sushi diverges too much following the shift on incorrect events. To counter this and make things more confusing, Sushi will actually calculate shift twice for two different starting points: shift of the last event, however invalid it might be, and shift of the last committed search group.
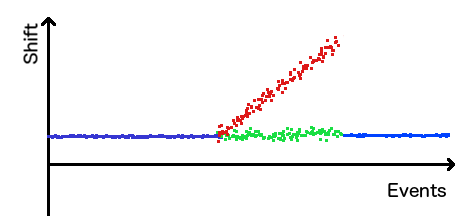
In the image above the first blue line shows groups' shifts where small window worked fine, the red line shows shifts calculated from the last group's shift and the green line - from the last committed (blue) group's shift. The last blue line shows that Sushi could find a correct event (with both of the halves matching) using the last committed group's shift. Without this mechanism in place the algorithm would just diverge forever following the red trend.
But that's not all! What if there matching audio segment for some broken event is actually there but the --window parameter is too small for Sushi to find it? Increasing the --window by default would make the script slower and might actually make the search less correct, so it's not an option. To counter that there's actually a third window controlled with the --max-window parameter (30 seconds by default). When Sushi detects more than --rewind-thresh (default 5) broken search groups in a row, it will rewind back to the first broken group and temporarily switch to using --max-window instead of the normal --window. After the first valid group is found Sushi will switch back to normal size to avoid potential problems with larger windows.
In short, Sushi tries very hard so you wouldn't have to.