{kind=link}
{kind=link}
This is an example of how to use Spark Streaming to Sessionize web log data by ip address.
This will mean that we are sessionizing in NRT and landing the results on HDFS.
A log with that we are going to be sending stats of the sessionization to HBase so that we can query it with Impala to get a NRT picture of stats like.
- Number of events
- Number of active sessions
- Average session time
- Number of new sessions
- Number of dead sessions
This will give us graphs like the following
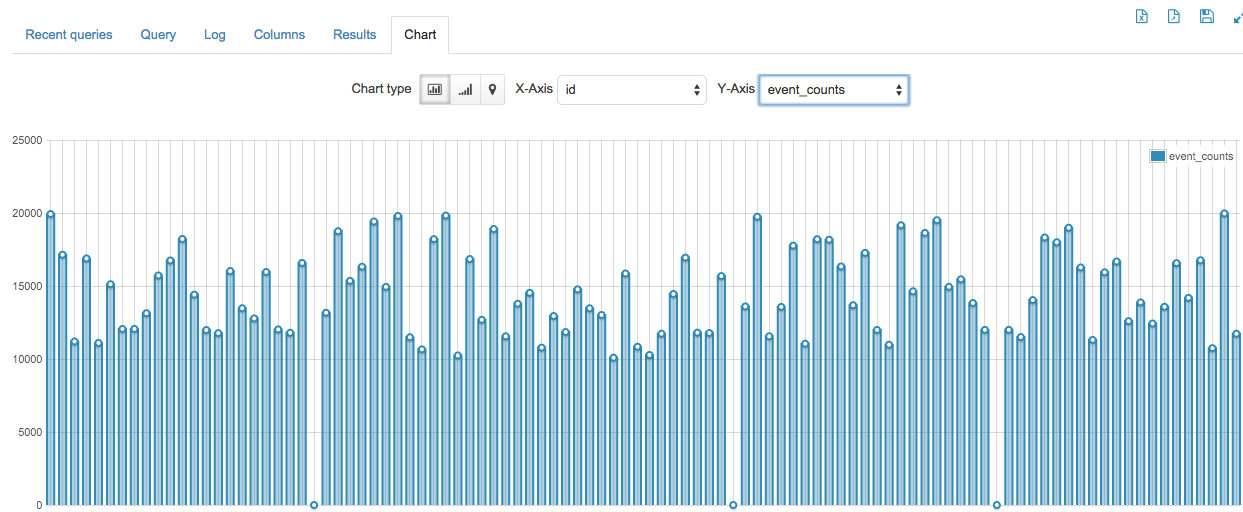
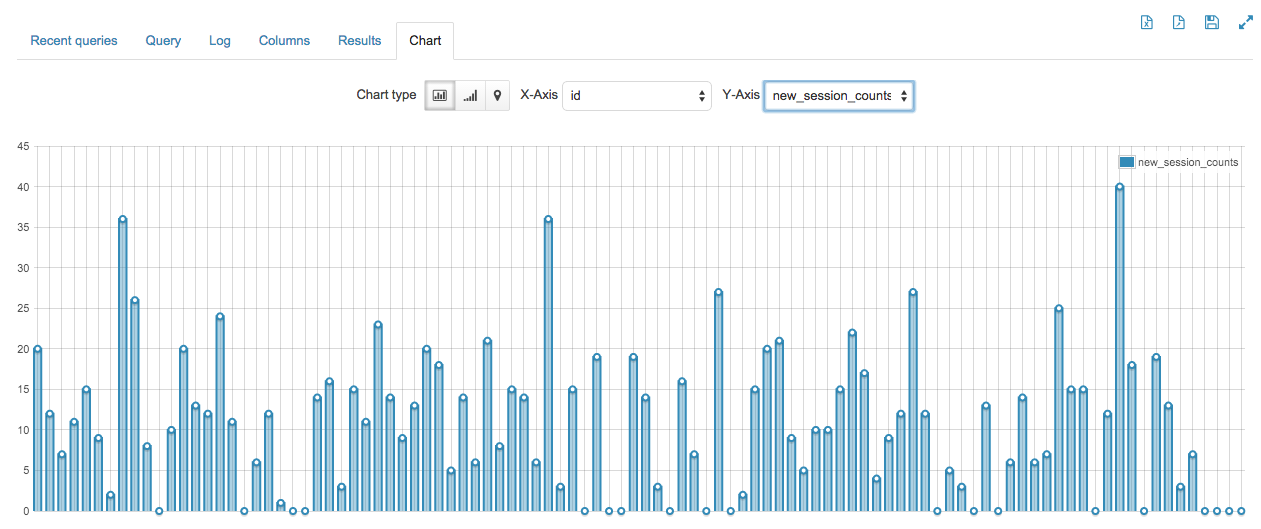
1: Set up HBase table. Just go to the HBase shell and use the following command
create 'stats', 's'
2: Create the following table in Hive using the createHiveTable.hql file
hive -f createHiveTable.hql
3: Create the following directories:
- /user/root/ss/checkpoint
- /user/root/ss/input
- /user/root/ss/results
- /user/root/ss/tmp
4: Start a generator. I only have two generators now: HDFS file and socket, with the HDFS file being tested more.
But this code can be made to support any Spark Streaming Receiver. Here is how I started my generator:
hadoop jar SparkStreamingSessionization.jar com.cloudera.sa.example.sparkstreaming.sessionization.SessionDataFileHDFSWriter /user/root/ss/tmp /user/root/ss/input 120 10000 9990
5: Then start the Spark Streaming process in Yarn with the following cmd
spark-submit --jars /opt/cloudera/parcels/CDH/lib/zookeeper/zookeeper-3.4.5-cdh5.1.0.jar,/opt/cloudera/parcels/CDH/lib/hbase/lib/guava-12.0.1.jar,/opt/cloudera/parcels/CDH/lib/hbase/lib/protobuf-java-2.5.0.jar,/opt/cloudera/parcels/CDH/lib/hbase/hbase-protocol.jar,/opt/cloudera/parcels/CDH/lib/hbase/hbase-client.jar,/opt/cloudera/parcels/CDH/lib/hbase/hbase-common.jar,/opt/cloudera/parcels/CDH/lib/hbase/hbase-hadoop2-compat.jar,/opt/cloudera/parcels/CDH/lib/hbase/hbase-hadoop-compat.jar,/opt/cloudera/parcels/CDH/lib/hbase/hbase-server.jar,/opt/cloudera/parcels/CDH/lib/hbase/lib/htrace-core.jar --class com.cloudera.sa.example.sparkstreaming.sessionization.SessionizeData --master yarn --deploy-mode client --executor-memory 512M --num-executors 4 --driver-java-options -Dspark.executor.extraClassPath=/opt/cloudera/parcels/CDH/lib/hbase/lib/* SparkStreamingSessionization.jar newFile hdfs://10.20.194.242/user/root/ss/results stats s hdfs://10.20.194.242/user/root/ss/checkpoint hdfs://10.20.194.242/user/root/ss/input
6: Then I go to hue and I use the following Impala query: invalidate metadata;
select * from hbasetable limit 30;
7: Then I used the graphing functinality in hue to so the graph that I included in this project