A small DSPy clone built on Instructor
- Pydantic Models: Robust data validation and serialization using Pydantic.
- Optimizers: Includes an Optuna-based few-shot optimizer for hyperparameter tuning.
- Vision Models: Easy to tune few-shot prompts, even with image examples.
- Chat Model Templates: Uses prompt prefilling to and custom templates to make the most of modern LLM APIs.
- Asynchronous Processing: Utilizes
asynciofor efficient concurrent task handling.
git clone [email protected]:thomasnormal/fewshot.git
cd fewshot
pip install -e .
python examples/simple.pyThe framework supports various AI tasks. Here's a basic example for question answering:
import instructor
import openai
from datasets import load_dataset
from pydantic import Field, BaseModel
from tqdm.asyncio import tqdm
from fewshot import Predictor
from fewshot.optimizers import OptunaFewShot
# DSPy inspired Pydantic classes for inputs.
class Question(BaseModel):
"""Answer questions with short factoid answers."""
question: str
class Answer(BaseModel):
reasoning: str = Field(description="reasoning for the answer")
answer: str = Field(description="often between 1 and 5 words")
async def main():
dataset = load_dataset("hotpot_qa", "fullwiki")
trainset = [(Question(question=x["question"]), x["answer"]) for x in dataset["train"]]
client = instructor.from_openai(openai.AsyncOpenAI()) # Use any Instructor supported LLM
pred = Predictor(client, "gpt-4o-mini", output_type=Answer, optimizer=OptunaFewShot(3))
async for t, (input, expected), answer in pred.as_completed(trainset):
score = int(answer.answer == expected)
t.backwards(score=score) # Update the model, just like PyTorch
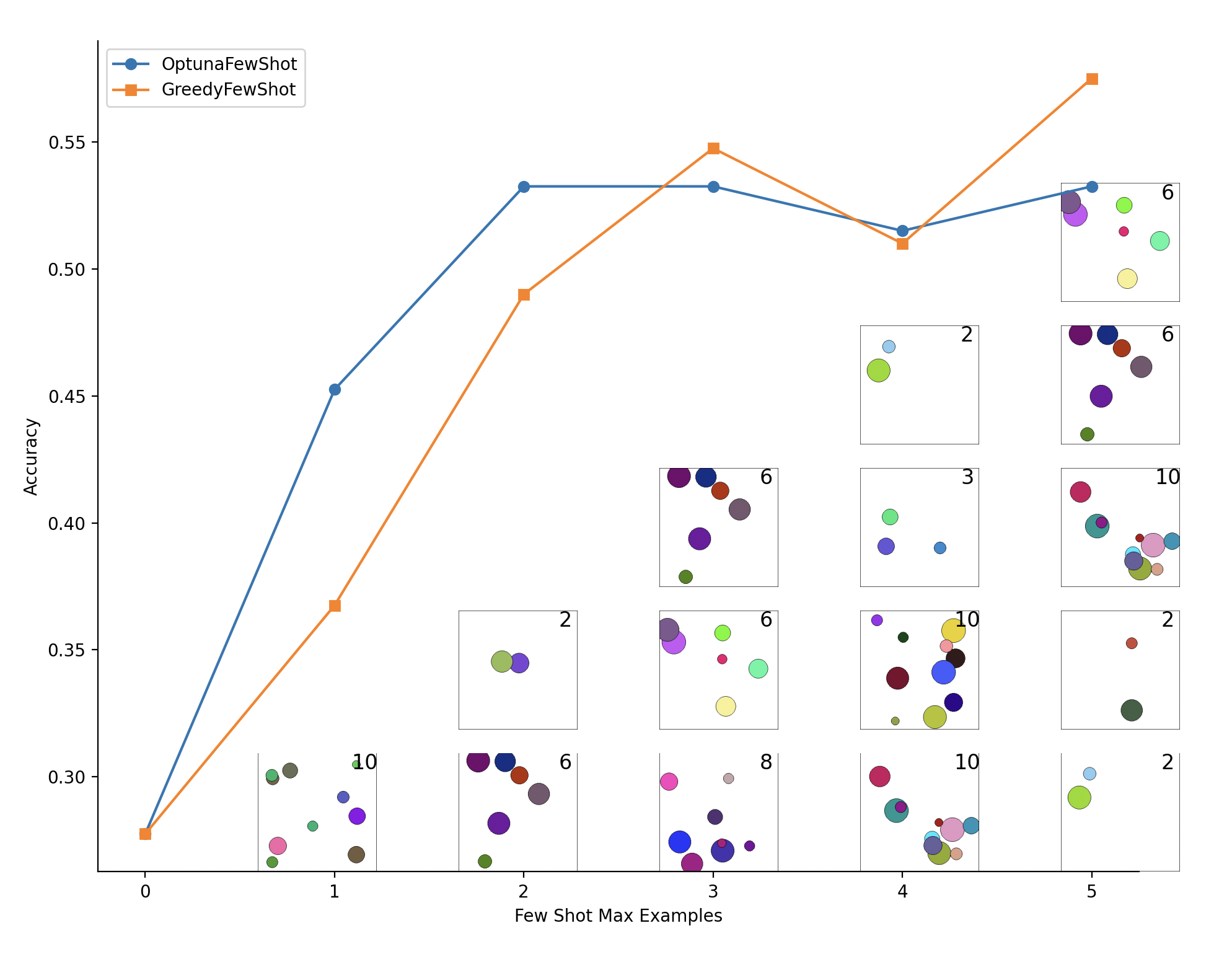
pred.inspect_history() # Inspect the messages sent to the LLMCode: examples/circles.py
import fewshot.experimental.tinytextgrad as tg
lm = tg.LMConfig("gpt-4o-mini")
await lm.call([{"role": "user", "content": "Who is a good robot?"}])
# A good robot is one that performs...
prompt = tg.Variable("How many r's are in `word`?")
word = tg.Variable("strawberry", requires_grad=False)
answer = await tg.complete(lm, prompt=prompt, word=word)
answer.value
# There are 2 r's in 'strawberry'.
expected = tg.Variable("3", requires_grad=False)
loss = await tg.equality_loss(lm, answer, expected)
loss.value
# No, 'answer' is not equal to 'expected' because the count of 'r's in 'strawberry' is 3, not 2.
await loss.backward(lm)
prompt.feedback
# ["Consider phrasing your question to be more explicit about the expected outcome. For example, you might ask, 'Can you count the occurrences of the letter r in the given word?'. This subtly encourages a more careful counting method."]
optimizer = tg.Optimizer([prompt])
await optimizer.step(lm)
prompt.value
# Can you count how many times the letter 'r' appears in the word 'word'?
answer = await tg.complete(lm, prompt=prompt, word=word)
answer.value
# 3See full notebook: https://colab.research.google.com/drive/12AYqI9Ofln6j7qf1s8_GYSjsgEra9orP?usp=sharing#scrollTo=2KmJveu5ROq5