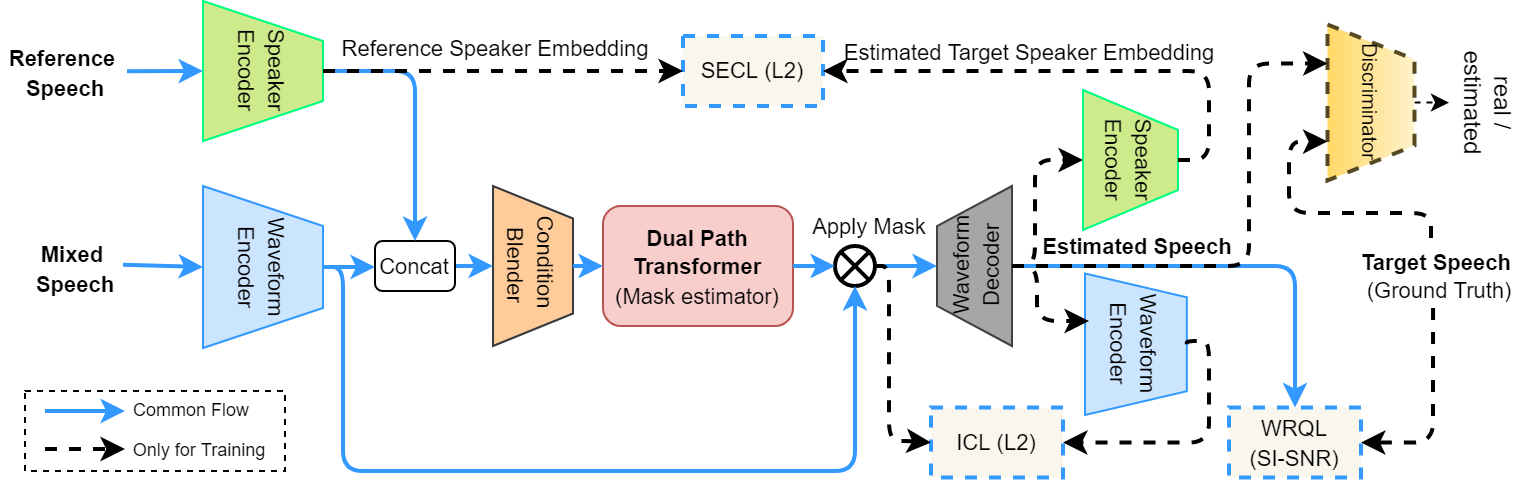
Recently, attention-based transformers have become a defacto standard in many deep learning applications including natural language processing, computer vision, signal processing, etc.. In this paper, we propose a transformer-based end-to-end model to extract a target speaker’s speech from a monaural multi-speaker mixed audio signal. Unlike existing speaker extraction methods, we introduce two additional objectives to impose speaker embedding consistency and waveform encoder invertibility and jointly train both speaker encoder and speech separator to better capture the speaker conditional embedding. Furthermore, we leverage a multiscale discriminator to refine the perceptual quality of the extracted speech. Our experiments show that the use of a dual path transformer in the separator backbone along with proposed training paradigm improves the CNN baseline by 3.12 dB points. Finally, we compare our approach with recent state-of-the-arts and show that our model outperforms existing methods by 4.1 dB points on an average without creating additional data dependency
- Project Page: https://tatban.github.io/spec-res/
- Paper: https://arxiv.org/abs/2409.01352
We assume the dataset is same as VoiceFilter paper. Data paths must be updated in the corresponding .csv files in data folder
- train spectron full model:
python train_spectron_msd.py - train spectron without adversarial refinement:
python train.py - train spectron with pretrained transformer (without adv. refinement):
python train_with_pretrained_DPT.py
- change the
OUT_DIRandweights_pathas per the training choice as above - run:
python test.py
| Model | SDRi (dB) | SI-SNRi (dB) |
|---|---|---|
| VoiceFilter | 7.8 | - |
| AtssNet | 9.3 | - |
| X-TasNet | 13.8 | 12.7 |
| Spectron without MSD (ours) | 13.9 | 12.8 |
| Spectron (ours) | 14.4 | 13.3 |
If you use this piece of code, please cite:
@misc{bandyopadhyay2024spectrontargetspeakerextraction,
title={Spectron: Target Speaker Extraction using Conditional Transformer with Adversarial Refinement},
author={Tathagata Bandyopadhyay},
year={2024},
eprint={2409.01352},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2409.01352},
}