- 使用自己本机的虚拟机安装,虚拟机配置:4核4G。
- MySQL:192.168.254.128:3306
- Redis:192.168.254.128:6379

- 这里我们进行服务部署时,采用手动打包的方式,还没有使用 jenkins 来进行打包部署,后面再进行微服务改造时再使用 jenkins 进行打包部署。
- 项目打包的时候: 必须引入以下的插件,否则打包将会出现依赖包无法打包到项目中。
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
- 后端服务部署命令:
# start.sh
nohup java -jar seckill-web.jar --spring.config.addition-location=application.yml > seckill-web.log 2>&1 &- 注意:
--spring.config.addition-location=application.yml加载外挂配置文件,为了方便服务的部署(本地开发,测试都是使用外网IP进行测试),服务部署必须使用内网IP地址,为了不再重新打包部署,使用外挂的配置文件。 - 外挂配置文件:MySQL 和 Redis 的 IP 都修改为 127.0.0.1

- 查看日志:启动成功
tail -f seckill-web.log
- 测试访问下 swagger 文档地址:http://192.168.254.128:9000/doc.html,首先登陆获取token,然后测一下
获取商品详情信息的接口:

- 接口是OK的!

- 压力测试:及时发现系统问题,系统瓶颈(预期系统达到的吞吐能力),及时对系统进行优化改进,对系统的问题进行修复,因此压力测试在整个项目研发中非常重要。
- 架构师:掌握一定的压力测试方法,压力测试是保障软件高质量交付手段之一。主要模拟海量的用户的并发,测试系统在高并发模式下,系统响应时间、TPS、BUG 等问题。
- 负载测试:确定系统在连续的负载压力模式下(梯形压力施加模式,逐渐增加压力),是否能坚持多少时间;评估系统性能:TPS 。
- 强度测试:极限施压,使得服务器一直处于满负荷的状态;测试系统在满负荷的状态运行情况(运行是否稳定)。
- 容量测试:确定系统可以同时在线的用户数量。
- 测试工具:
- AB 测试工具
- ngrinter 压力测试工具
- 阿里云测试服务(阿里云施加机器)
- jmeter工具,可视化的效果
注意问题: 开始压力测试之前,必须思考压力机的问题?施加多大的压力,单机压力是否足够?压力测试干扰问题(网络干扰)。
- jmeter镜像下载地址:https://jmeter.apache.org/

wget https://mirrors.tuna.tsinghua.edu.cn/apache//jmeter/binaries/apache-jmeter-5.4.1.tgz
# 解压到 /Volumes/D/tools/jmeter/ 目录
# jmeter环境变量
export JMETER_HOME=/Volumes/D/tools/jmeter/apache-jmeter-5.4.1
export PATH=$JAVA_HOME/bin:$JMETER_HOME/bin:$PATH- 下载地址:http://jmeter-plugins.org/downloads/all/,官网上下载 plugins-manager.jar 直接在线下载,然后执行在线下载即可。

- 注意:下载插件在英文模式下下载,如果在中文模式下下载,貌似不好使
主要插件介绍:
1、PerfMon:监控服务器硬件,如CPU,内存,硬盘读写速度等
2、Basic Graphs:主要显示平均响应时间,活动线程数,成功/失败交易数等
3、Additional Graphs:主要显示吞吐量,连接时间,每秒的点击数等
...
添加响应时间:事务控制器_添加_监听器_jp@gc – Response Times Over Time- 在线下载方法如下图所示:


- 还可以选择jmter语言:

- 修改jmeter默认语言:
vim jmeter.properties
- 新建测试计划:

- 添加取样器:

- 继续添加监听器:察看结果树、聚合报告、TPS、RT等

- 使用jmeter进行压力测试,查看几个性能指标: TPS、RT、聚合报告。


-
根据 TPS 性能曲线图:TPS 在 2400 左右,目前该接口只是做了一个简单的主键查询。
-
TPS:从发送请求到获取到响应结果的一次请求,叫做一次 TPS。
-
QPS:每秒查询数,大多数的情况下,QPS = TPS。
-
例如:访问一个页面 /index.html 是,可能还要加载一些 js、css,那么 QPS = 3、TPS = 1。如果把聚焦的点:主关注接口,QPS = TPS。
- RT:一个请求从发送到响应耗时。

- 可以看到,大部分请求都在 1、2 秒左右返回,响应时间并不是很理想。主要是因为服务部署在本地 VMware 虚拟机,测试机也都是在本地。

- #样本: 20w 个样本
- #平均值:所有请求平均耗时 1576ms
- #中位数:50%的请求在 1552ms 之内响应结束
- #90%百分位:90%的请求在 1876ms 之内响应结束
- #最小值:请求的最小耗时 0ms
- #最大值:请求的最大耗时 10018ms
- #异常率:发送异常频率
系统出现问题分类:
- 系统异常:CPU占用率高、磁盘满了、磁盘IO频繁、网络流量异常等;排查指令:top、free、dstat、pstack、vmstat、strace 获取异常信息,排查系统异常情况。
- 业务异常:流量太多系统扛不住、耗时长、线程死锁、多线程并发问题、频繁full gc、oom等;排查指令:top、jstack、pstack、strace、日志等。
- top 指令监控 CPU 使用情况,根据 CPU 使用情况分析系统整体运行情况:

- 关注指标:load average 代表系统的繁忙程度,三个参数分别是 1 分钟、5 分钟、15 分钟 CPU 的平均负载。
- 单核CPU:
- Load average < 1 , cpu比较空闲,没有出现线程等待cpu执行现象;
- Load average = 1 , cpu刚刚占满,没有空闲空间;
- Load average > 1 , cpu已经出现了线程等待,比较繁忙;
- Load average > 3 , cpu阻塞非常严重,出现了严重线程等待,必须进行优化处理。
- 4和CPU:
- Load average < 4 , cpu比较空闲,没有出现线程等待cpu执行现象;
- Load average = 4 , cpu刚刚占满,没有空闲空间;
- Load average > 4 , cpu已经出现了线程等待,比较繁忙;
- Load average > 9 , cpu阻塞非常严重,出现了严重线程等待,必须进行优化处理。
- free 指令排查线上问题重要指令,内存问题很多时候是引起 CPU 较高的原因。

- df 指令查看磁盘使用情况,有时候服务出现问题,可能就是磁盘不够了。

- dstat 指令:其集成了 vmstat、iostat、netstat 等工具的特色。。使用该命令需要先进行安装:
yum install dstat- -c 查看cpu情况;-d 磁盘读写;-n 网络状态;-l 显示系统负载…


服务调优是在什么时间点介入调优? 测试发现问题:解决业务异常,也有一部分调优;而调优更多的时候,是在上线以后介入调优。
- Tomcat 服务器:是我们现在使用的内置服务器,默认的线程数?最大连接数?

修改以上参数的大小,是否可以提升tomcat服务器性能? 答案:不考虑其他因数(硬件资源限制),改大tomcat最大线程数、最大连接数、等待队列数,理论上一定是可以提升服务器性能。
- Tomcat参数原理分析:

- 优化配置:最大线程数提升4倍


优化后的TPS并没有太大变化,是什么原因? 业务代码没有任何业务执行,只执行业主键查询,主键查询是数据库最快的查询方式,耗时0-10ms,因此此操作不是一个耗时操作,不耗时不需要调优
- 修改业务代码,模拟耗时操作,然后重新打包部署

- tomcat配置没有做优化前的TPS:稳定在 200 左右

- tomcat配置优化后的TPS:可以发现TPS提升4倍,变成了800个TPS

- 客户端和服务器连接的时候,为了防止频繁建立连接,释放连接,浪费资源,这样会消耗资源造成性能下降。
- Jmeter使用长连接进行测试:

- 问题:keep-alive 连接数是否是越多越好呢?
- 答案:keep-alive 连接本身消耗大量的资源,如果不能及时释放,系统TPS就上不去,因此 keep-alive 连接数也必须要设置一个合理的连接数。
@Configuration
public class WebServerConfig implements WebServerFactoryCustomizer<ConfigurableWebServerFactory> {
@Override
public void customize(ConfigurableWebServerFactory factory) {
// 获取tomcat连接器
((TomcatServletWebServerFactory) factory).addConnectorCustomizers((TomcatConnectorCustomizer) connector -> {
// 获取protocol
Http11NioProtocol protocolHandler = (Http11NioProtocol) connector.getProtocolHandler();
// 如果keepalive连接30s,还没有人使用,释放此链接
protocolHandler.setKeepAliveTimeout(30000);
// 允许开启最大长连接数量
protocolHandler.setMaxKeepAliveRequests(10000);
});
}
}问题1:项目上线后,是什么原因促使必须进行jvm调优? 答案:调优的目的就是提升服务性能
- JVM 堆内存空间对象太多(Java线程、垃圾对象),导致内存被占满,程序跑不动—性能严重下降。
- 调优:及时释放内存
- 垃圾回收线程太多,频繁回收垃圾(垃圾回收线程也会占用内存资源,抢占cpu资源),必然会导致程序性能下降
- 调优:防止频繁GC
- 垃圾回收导致 STW (stop the world)
- 调优:尽可能的减少 GC 次数
问题2:JVM 调优本质是什么? 答案: JVM 调优的本质就是(对内存的调优) 及时回收垃圾对象,释放内存空间;让程序性能得以提升,让其他业务线程可以获得更多内存空间。
问题3:是否可以把 JVM 内存空设置的足够大(无限大),是不是就不需要垃圾回收呢? 前提条件:内存空间被装满了以后,才会触发垃圾回收器来回收垃圾。 理论上是的,现实情况不行的! 寻址能力:(是否有这么大的空间)32位操作系统 —— 4GB 内存;64位操作系统 —— 16384 PB 内存空间
- 堆内存空间大小的设置:必须设置一个合适的内存空间,不能太大,也不能太小。
- 考虑到寻址速度的问题,寻址一个对象消耗的时间比较长的;一旦触发垃圾回收,将会是一个灾难。(只能重启服务器)。
- 原则一:GC 的时间足够小:JVM 堆内存设置足够小。
- 垃圾回收时间足够小,意味着 JVM 堆内存空间设置小一些,这样的话,垃圾对象寻址的时候消耗的时间就非常短,然后整个垃圾回收非常快速。
- 原则二:GC 的次数足够少:JVM 堆内存设置足够大。
- GC 次数足够少,JVM 堆内存空间必须设置的足够大,这样垃圾回收触发次数就会相应减少。
- 原则一、原则二 是相互冲突的,因此需要权衡,内存空间既不能设置太大,也不能设置太小。
- 原则三:发生 Full GC 周期足够长:最好不发生 Full GC。
- MetaSpace 永久代空间设置大小合理,MetaSpace 一旦扩容,就会发生 Full GC;
- 老年代空间设置一个合理的大小,防止 Full GC;
- 尽量让垃圾对象在年轻代被回收(90%);
- 尽量防止大对象的产生,一旦大对象多了以后,就可能发生 Full GC,甚至 OOM。
- JVM调优的本质:回收垃圾,及时释放内存空间,但是什么是垃圾?
- 在内存中间中,那些没有被引用的对象就是垃圾(高并发模式下,大量的请求在内存空间中创建了大量的对象,这些对象并不会主动消失,因此必须进行垃圾回收,当然 Java 垃圾回收不需要我们自己编写垃圾回收代码,Java 提供各种垃圾回收器帮助回收垃圾,JVM垃圾回收是自动进行的)。
- 一个对象的引用消失了,这个对象就是垃圾,因此此对象就必须被垃圾回收器进行回收,及时释放内存空间。
- JVM 提供了2种方式找到这个垃圾对象:引用计数算法、根可达算法(hotspot 垃圾回收器都是使用这个算法)。
- 引用计数算法:对每一个对象的引用数量进行一个计数,当引用数为0时,那么此对象就变成了一个垃圾对象。
- 不能解决循环引用的问题,如果存在循环引用的话,无法发现垃圾。
- 根可达算法:根据根对象向下进行遍历,如果遍历不到的对象就是垃圾。
- JVM提供了3种方式清除垃圾,分别是:
- mark-sweep:标记-清除算法
- coping:复制算法
- mark-compact:标记-整理(压缩)算法
- 该算法分为”标记“和”清除“两个阶段:首先标记所有需要回收的对象,在标记完成后统一回收所有垃圾。
- 缺点:效率不高,标记和清除两个过程的效率都不高;产生碎片,碎片太多会导致提前GC。

- 该算法将可用内存按容量划分为大小相等的两块,每次只是用其中的一块,当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清除掉(Young区就是使用的这种算法)。
- 优缺点:实现简单,运行高效,但是空间利用率低。

- 标记过程仍然与”标记-清除“算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端到边界以外的内存。
- 优缺点:没有了内存碎片,但是整理内存比较耗时。

- 在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法;
- 而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用”标记-清除“或”标记-整理“算法进行收回。
- Java提供很多的垃圾回收器:10种垃圾回收器。

- 串行回收器:Serial、Serial old
- 并行回收器:ParNew、Parallel Scavenge、Parallel old
- 并发回收器:CMS、G1(分区算法)
- Serial、Serial old、ParNew、Parallel Scavenge、Parallel old、CMS 都属于物理分代垃圾收集器;年轻代、老年代分别使用不同的垃圾回收器。
- Serial、Serial old 是串行化的垃圾回收器。
- ParNew、CMS 组合是并行、并发的垃圾回收器。
- Parallel Scavenge、Parallel old 是并行的垃圾回收器
- G1是在逻辑上进行分代的,因此在使用上非常方便,关于年轻代、老年代只需要使用一个垃圾回收器即可。
- ZGC是一款JDK 11中新加入的具有实验性质的低延迟垃圾收集器。
- Shenandoah 是 OpenJDK 的垃圾回收器。
- Epsilon 是 Debug 使用的,调试环境下,验证 JVM 内存参数设置的可行性。
- Serial + Serial old:是串行化的垃圾回收器,适合单核心的 CPU 的情况;
- ParNew + CMS:是响应时间优先组合;
- Parallel Scavenge + Parallel old:是吞吐量优先组合。
- G1:逻辑上分代的垃圾回收器组合。
- Serial 是年轻代的垃圾回收器,单线程的垃圾回收器;Serial Old 是老年代的垃圾回收器,也是一个单线程的垃圾回收器,适合单核心的 CPU。

- 注意特点:
- STW:当进行 GC 的时候,整个业务线程都会被停止,如果 STW 时间过长,或者 STW 发生次数过多,都会影响程序的性能。
- 垃圾回收器线程:多线程、单线程、并发、并行。
- 并行的垃圾回收器,是吞吐量优先的垃圾回收器组合,是JDK8默认的垃圾回收器。
什么是并发、并行? 并发:在一段时间内,多个线程抢占 CPU 的执行,并发执行,这些线程就叫并发线程。 并行:多个线程在同一时刻,在多个 CPU 上同时执行,这些线程叫做并行线程。
- PS + PO 回收垃圾的时候,采用的多线程模式回收垃圾。

- 注意特点:
- STW:当进行 GC 的时候,整个业务线程都会被停止,如果 STW 时间过长,或者 STW 发生次数过多,都会影响程序的性能。
- 垃圾回收器线程:多线程、单线程、并发、并行。
- ParNew 是并行垃圾回收器,年轻代的垃圾回收器;CMS 是并发垃圾回收器,回收老年代的垃圾。

- CMS 是响应时间优先的垃圾回收器,充分考虑了 STW 时间的问题,减少 STW 的时间,延长业务执行时间。
- 注意:任何的垃圾回收器都无法避免 STW,因此 JVM 调优实际上就是调整 STW 的时间。
- 使用G1收集器时,它将整个Java堆划分成约2048个大小相同的独立 Region 块,每个 Region 块大小根据堆空间的实际大小而定,整体被控制 在1MB到32MB之间,且为2的N次幂,即1MB、2MB、4MB、8MB、16MB、32MB。可以通过
-XX:G1HeapRegionsize设定。 - 所有的Region大小相同,且在JVM生命周期内不会被改变。

- 通过内存分代模型结构:大多数对象都会在年轻代被回收掉(90%+),很多对象都在15次的垃圾回收中被回收掉了,只有超过15次还没被回收掉的才会进入到老年代区域。
- 垃圾回收触发的时机:
- PS+PO:当堆内存被装满了,才会触发垃圾回收(eden区域满了,触发了垃圾回收;old区域满了,触发垃圾回收)。
- CMS:JDK1.5 时,当 eden 区域装对象达到68%时候,就会触发垃圾回收;JDK1.6+时,92% 才会触发垃圾回收器。
一个新对象被创建了,但是这个对象是一个大对象(查询全表),eden区域已经放不下了,此时会发生什么?

- 明确 JVM 调优的本质:GC-垃圾回收,及时释放内存空间;GC 次数要少,GC 时间少,防止 Full GC。进行内存参数设置。
服务器硬件配置:4cpu、8GB 内存 --- jvm调优内存,考虑内存。
- -Xmx4000m:设置 JVM 最大堆内存(经验值:3500m ~ 4000m,内存设置大小,没有一个固定的值,根据业务实际情况来进行设置的,根据压力测试、性能反馈情况,去做参数调试);
- -Xms4000m:设置 JVM 堆内存初始化的值,一般情况下,初始化的值和最大堆内存值必须一致,防止内存抖动;
- -Xmn2g:设置年轻代内存对象(eden、s1、s2);
- -Xss256k:设置线程栈大小,JDK 1.5+ 版本线程栈默认是 1MB,相同的内存情况下,线程堆栈越小,操作系统创建的线程越多。
# 4核4G
nohup java -Xmx2000m -Xms2000m -Xmn1g -Xss256k -jar seckill-web.jar --spring.config.addition-location=application.yml > seckill-web.log 2>&1 &- 再次进行压力测试:查看在此内存设置模式下性能情况。

- 根据压力测试结果,发现JVM参数设置,和之前没有设置吞吐能力没有太大的变化,因为测试样本不足以造成 GC、Full GC 时间上的差异。
问题:根据什么标准判断参数设置是否合理呢?根据什么指标进行调优呢?
- 发生几次 GC、是否频繁的发送GC?是否发生 Full GC、Full GC 发生是否合理?GC 的时间是否合理?OOM?
- 启动命令:
nohup java -Xmx2000m -Xms2000m -Xmn1g -Xss256k -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar seckill-web.jar --spring.config.addition-location=application.yml > seckill-web.log 2>&1 &- 输出GC日志的参数说明:
- -XX:+PrintGCDetails 打印 GC 详细信息
- -XX:+PrintGCTimeStamps 打印 GC 时间信息
- -XX:+PrintGCDateStamps 打印 GC 日期信息
- -XX:+PrintHeapAtGC 打印 GC 堆内存信息
- -Xloggc:gc.log 把 GC信息输出到 gc.log 文件中
- 执行启动命令后,就会产生 GC 日志:

- 可以使用 GCeasy进行 GC日志分析:导入gc.log 进行在线分析即可。



- 总结:可以发现业务线程执行时间占比达到99%+,说明 GC 时间在整个业务执行期间所占用的时间非常少,几乎不会影响程序性能;导致业务线程执行时间占比高的原因是:
- 程序样本数不够;
- 程序运行的时间不够;
- 业务场景不符合要求(查询没有太多的对象数据)
- 在一开始就发生了FullGC:

- GC 详细数据分析:

- 查询 GC 内存模型:
jstat -gcutil PID查询此进程的内存模型

- Metaspace 永久代空间:默认为 20 M(初始化大小),当 Metaspace 被占满后,就会发生扩容,一旦metaspace 发生一次扩容,就会同时发送一次 Full GC。
- 启动命令:参数设置
-XX:MetaspaceSize=256m
nohup java -Xmx2000m -Xms2000m -Xmn1g -Xss256k -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar seckill-web.jar --spring.config.addition-location=application.yml > seckill-web.log 2>&1 &- 调整参数后,重启项目,并进行压力测试,重新生成 GC 日志,并进行分析

- 经过参数调优后,发现 Full GC 已经没有发生了。

- Sun公司推荐设置:整个堆的大小 = 年轻代 + 老年代 + 永久代(256m),推荐年轻代占整个堆内存 3/8, 因此当整个堆内存设置大小为 2000m 时,也就是说年轻代大小应该设置为 750m。
- 所以,定义年轻代 -Xmn750m,剩下的空间就是老年代空间。或者定义参数 -XX:NewRatio=4,表示年轻代(eden、s0、s1)和老年代区域占比是 1:4。
- 年轻代大小、老年代大小比值可以根据业务实际情况设置比例,通过设置相应的比例来减少相应 YoungGC、Full GC。
- 启动命令:修改参数
-Xmn750m
nohup java -Xmx2000m -Xms2000m -Xmn750m -Xss256k -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar seckill-web.jar --spring.config.addition-location=application.yml > seckill-web.log 2>&1 - 调整参数后,重启项目,并进行压力测试,重新生成 GC 日志,并进行分析

- Young GC 增多了几次,但是在 JVM调优的原则中:要求尽量防止 Full GC 的发生,因此可以把 Full GC 设置的稍微大一些,意味着 Old 区域装载对象很长时间才能装满(或者永远都装不满),发生 Full GC 概率就非常小。
- 官方给定设置:可以设置 eden、s 区域大小为 8:1:1,即 -XX:SurvivorRatio=8。
- 此调优的原理:尽量让对象在年轻代被回收,调大了eden区域的空间,让更多对象进入到 eden 区域,触发 GC 时,更多的对象被回收。
- 启动命令:增加参数
-XX:SurvivorRatio=8
nohup java -Xmx2000m -Xms2000m -Xmn750m -Xss256k -XX:MetaspaceSize=256m -XX:SurvivorRatio=8 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar seckill-web.jar --spring.config.addition-location=application.yml > seckill-web.log 2>&1 &- 调整参数后,重启项目,并进行压力测试,重新生成 GC 日志,并进行分析

- 发现 Young GC 次数和时间有所减少和降低。
- JVM 调优(调整 JVM 内存大小、比例),降低 GC 次数,减少 GC 时间,从而提升服务性能。
- 调优标准:项目上线后,遇到问题,调优。
- GC 消耗时间:业务时间占比
- 频繁发生 Full GC:调优 STW——程序暂停时间比较长,发生阻塞可能导致整个程序崩溃
- OOM:调优
- 并行的垃圾回收器:Parallel Scavenge(年轻代) + Parallel Old(老年代) ---- 是JDK默认的垃圾回收器。
- 显式的配置PS+PO垃圾回收器:-XX:+UseParallelGC -XX:+UseParallelOldGC。

- 并行垃圾回收器(年轻代),并发垃圾回收器(老年代) :ParNew + CMS (响应时间优先垃圾回收器)。
- 显式配置:ParNew + CMS 垃圾回收器组合:-XX:+UseParNewGC -XX:+UseConcMarkSweepGC。

- CMS 只有在发生 Full GC 时才起到作用,CMS一般情况下不会发生,因此在 JVM 调优原则中表示尽量防止发生 FullGC,因此 CMS 在 JDK14 已经被废弃。
- G1 垃圾回收器是逻辑上分代模型,使用配置简单。
- 显式配置:-XX:+UseG1GC

- 调整参数后,重启项目,并进行压力测试,重新生成 GC 日志,并进行分析

- 经过测试,发现 G1 GC 次数减少了,但是 GC 总时长增加很多;时间增加,意味着服务性能就没有提升上去。
- 避免网页出现错误:Timeout 5xx 错误、慢查询导致页面无法加载、阻塞导致数据无法提交。
- 增加数据库稳定性:很多的数据库问题,都是由于低效的SQL语句造成的(写SQL语句)。
- 优化用户体验:流畅的业务访问体验、良好的网站功能体验。
- 影响数据库性能的原因可能有:
- 低效的 SQL 语句;
- 并发 CPU 问题:SQL语句不支持多核心的 CPU 并发计算,也就是说一个 SQL 只能在一个 CPU 执行结束;
- 连接数:max_connections;
- 超高 CPU 使用率;
- 磁盘 IO 性能问题;
- 大表(字段多,数据多);
- 大事务。
- 数据库数据处理(困难):数据库扩容非常困难,想要通过扩容提升数据库性能是很困难的
- Web服务器扩容是非常简单的,web服务器是无状态服务,可以随时进行扩容;但是数据库不能随意进行扩容,一旦扩容就会影响数据完整性,数据一致性。
- 项目架构中提升性能:
- 对项目架构、项目业务、缓存各方面进行优化,真正数据库请求比较少—减少数据库压力;
- 数据库设计,架构,优化。
- 大多数企业:数据库采用主从架构解决问题,数据分表、分库,数据归档数据,能热分离。

- 添加MySQL驱动,添加测试用例:

- 添加JDBC连接配置:

- 添加取样器-JDBC请求:

- 继续添加监听器:察看结果树、TPS、RT、聚合报告,先测试一个请求,测试OK。

- 接下来设置线程数,进行并发测试20W样本:调整最大连接数找到最合理的连接数量

- 本地压测遇到的问题:
Uncaught Exception java.lang.OutOfMemoryError: unable to create new native thread in thread Thread[StandardJMeterEngine,6,main]. See log file for details.- windows环境下,修改jmeter:
set HEAP=-Xms256m -Xmx256m
set NEW=-XX:NewSize=128m -XX:MaxNewSize=128m
改为:
set HEAP=-Xms256m -Xmx1024m
set NEW=-XX:NewSize=128m -XX:MaxNewSize=512m- linux环境下,修改jmeter:

- 还有一点要注意:不要直接点击工具栏的开始按钮,因为这个会把所有的测试用例跑起来,可能就会导致Jmeter OOM。测试某一个case,可以右键该用例启动即可。

- connectionTimeout:配置建立TCP连接的超时时间,客户端和mysql建立连接超时,断开连接(释放连接)。
- socketTimeout:配置发送请求后等待响应的超时时间(客户端和mysql建立连接是socket连接, 一旦发送网络异常,客户端无法感知,客户端一直阻塞状态,一直等待服务端给相应结果,其实由于网络异常,这个链接变成死链接)
jdbc:mysql://127.0.0.1:3306/vshop?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true&connectionTimeout=3000&socketTimeout=1200

- 秒杀系统,mysql 会抢占同一个服务器 CPU 资源、内存资源;一旦 CPU 资源、内存资源出现满负荷状态,就会影响服务性能。

- 通过分离部署后,发现性能提升非常不明显,TPS还是800,因为无论是在单机,还是在分布式情况下,机器性能都不是满负荷运作的情况。


- 从上往下看:openresty 是否会存在性能瓶颈?目前来看性能瓶颈不在 openresty,因为openresty(nginx) 底层使用 C 语言开发的,吞吐能力 5W TPS。
- 性能瓶颈一定出现在项目,数据库这个位置。
- 项目优化:扩容、缓存;数据库优化:扩容、数据库其他优化。
- 配置nginx:

- 此时此刻对这个架构进行TPS 预测: TPS = 1600。出现一些抖动,可能原因是所有应用都是在本地一台机器上完成,服务部署在本地虚拟机中。

- 在系统架构设计中,多级缓存非常重要,尤其是构建亿级流量的系统,缓存是必不可少优化选项;因此缓存可以成倍的提升系统性能(吞吐能力),使用了缓存后,尽可能把请求拦截在上游服务器因此下游服务器来说,压力就会变小。
- 在系统架构中应该使用那些缓存:
- 浏览器缓存
- CDN缓存(静态资源:js、css、视频、文件)
- 接入层 nginx、openrestry 缓存
- 堆内存缓存(JVM进程级别缓存)
- 分布式缓存(redis、memcached)
- 数据库缓存(压力非常小了)

- 本系统中要实现缓存有:堆内存缓存、Redis分布式缓存、OpenResty内存字典(lua)、lua+redis
思考:JVM进程级别的缓存(缓存数据放入JVM堆内存中),存在以下问题? 1)JVM 堆内存资源非常宝贵(classloader文件,java对象,对象管理),改如何考量? 2)内存脏数据非常的不敏感(Map: key,value)? 3)内存资源分配不可控?
- 内存资源非常宝贵,不能放入太多缓存数据,只需要放入热点数据即可,提升服务性能;
- 定时消耗内存对象数据(定时器),数据有过期时间(定时销毁)--非常麻烦 --- GuavaCache;
- 可能把所有的资源都放入内存中,只放入热点数据即可。
- 分布式缓存:Redis --- AP模型,在海量的缓存数据中,存储一定概率的数据丢失;接入层缓存:OpenResty + Lua。
- 配置 GuavaCache:
@Configuration
public class GuavaCacheConfig {
/**
* 定义一个GuavaCache对象
*/
private Cache<String, Object> guavaCache = null;
@PostConstruct
public void init() {
guavaCache = CacheBuilder.newBuilder()
.initialCapacity(10)
.maximumSize(100)
// 设置缓存写入后过期时间
.expireAfterWrite(60, TimeUnit.SECONDS)
.build();
}
@Bean
public Cache<String, Object> getGuavaCache() {
return guavaCache;
}
}- 缓存业务实现:
@Override
public TbSeckillGoods queryGoodsDetailsByCache(Integer id) {
String cacheKey = SECKILL_GOODS_CACHE_PREFIX + id;
// 1、先从JVM堆内存中读取数据,使用 guava 缓存
TbSeckillGoods seckillGoods = (TbSeckillGoods) guavaCacche.getIfPresent(cacheKey);
if (seckillGoods != null) {
return seckillGoods;
}
// 2、如果JVM堆内存中不存在,则从分布式缓存(redis)中查询
seckillGoods = redisService.getObjValue(cacheKey);
if (seckillGoods != null) {
// 添加进guava缓存
guavaCacche.put(cacheKey, seckillGoods);
return seckillGoods;
}
// 3、如果分布式缓存(redis)中还没有,则从数据库查询
seckillGoods = seckillGoodsMapper.selectByPrimaryKey(id);
if (seckillGoods != null && seckillGoods.getStatus() == 1) {
// 添加进分布式缓存(redis)中
redisService.setObjValue(cacheKey, seckillGoods, 30, TimeUnit.MINUTES);
}
return seckillGoods;
}- 这里实现的两级缓存(堆内存缓存,redis缓存): 对于系统来说性能提升情况如何呢?

- 根据压力测试结果显示: TPS吞吐能力提升效果相当显著; 没有缓存:TPS = 800 , 加缓存:TPS = 8000+

- RT 响应时间: 400ms左右,基本上满足接口性能需求。
- 这里,探索 OpenResty 接入层缓存,使用 OpenResty 内存字典来实现接入层缓存;如果缓存数据在接入层命中,后端服务器就不会再收到请求了。
问题: 什么样的缓存,性能最好的? 离请求越近的地方,缓存数据性能越好,意味着系统性能越强。
- 参考我之前的博客:https://blog.csdn.net/yangwei234/article/details/113838826
- lua接入指令:https://www.nginx.com/resources/wiki/modules/lua/#directives
- 开启 OpenResty 内存字典
# 在openresty服务器开辟一块128m空间存储缓存数据
lua_shared_dict ngx_cache 128m;- Lua 脚本方式,实现缓存接入:
-- 基于内存字典实现缓存
-- 添加缓存实现
local set_to_cache = function(key, value, expire)
if not expire then
expire = 0
end
-- 获取本地内存字典对象
local ngx_cache = ngx.shared.ngx_cache
-- 向本地内存字典添加缓存数据
local succ, err, forcible = ngx_cache:set(key, value, expire)
return succ
end
-- 获取缓存实现
local get_from_cache = function(key)
-- 获取本地内存字典对象
local ngx_cache = ngx.shared.ngx_cache
-- 从本地内存字典对象中获取数据
local value = ngx_cache:get(key)
return value
end
-- 利用 Lua 脚本实现一些简单的业务
-- 获取请求参数对象
local params = ngx.req.get_uri_args()
-- 获取参数
local id = params.id
local cache_key = "seckill_goods_" .. id
-- 先从内存字典获取缓存数据
local goods = get_from_cache(cache_key)
-- 若内存字典中没有数据,则从后端服务(缓存,数据库)查询数据,完毕在放入内存字典缓存即可
if goods == nil then
local res = ngx.location.capture("/proxy/http/192.168.254.128/9000/seckill/goods/detail/" .. id)
-- 获取查询结果
goods = res.body
-- 向本地内存字典添加缓存数据
set_to_cache(cache_key, goods, 60)
end
-- 返回结果
ngx.say(goods)- openresty 配置:
# conf.d/vshop.conf
server {
listen 9000;
server_name localhost;
location /seckill/goods/detail {
default_type application/json;
content_by_lua_file /lua/shared_dict.lua;
}
# 反向代理转发
location ~ ^/proxy/(http?)/([^/]+)/(\d+)/(.*) {
internal;
proxy_pass $1://$2:$3/$4;
}
}- 注意:这里我们的OpenResty地址和后端需要访问的地址是不同的,因此,利用 proxy_pass 做了一层转发。
- 利用 curl 测试一下是否可以正常访问:可以看到是没有问题的!

- 下面做下压测:修改下HTTP请求

- 使用80W个样本测试:TPS能达到2W,响应时间,RT响应时间也是非常之快速。

- 使用lua+redis缓存结构,尽可能把请求拦截在上游服务器,减轻后端服务器压力,提升项目吞吐能力使用lua+redis缓存结构,尽可能把请求拦截在上游服务器,减轻后端服务器压力,提升项目吞吐能力。
- OpenResty 集成Redis库: 使用 lua 脚本操作 Redis,只需要引入 Redis 库即可实现。
# lua_redis.lua
-- 引入redis库
local redis = require("resty.redis")
-- 调用方法,获取redis对象
local red = redis:new()
-- 基于lua+redis实现缓存
local connect_redis = function()
red:set_timeout(100000)
local ok, err = red:connect("192.168.254.128", 6379)
if not ok then
ngx.say("failed to connect: ", err)
return false
end
return true
end
-- 获取缓存实现
local get_from_redis = function(key)
if not connect_redis() then
return
end
local res, err = red:get(key)
if not res then
ngx.say("failed get redis cache: ", err)
return ngx.null
end
ngx.say("get cache from redis.")
return res
end
-- 获取缓存实现
local get_from_cache = function(key)
-- 获取本地内存字典对象
local ngx_cache = ngx.shared.ngx_cache
-- 从本地内存字典对象中获取数据
local value = ngx_cache:get(key)
-- 如果内存字典中没有缓存数据,则从redis中获取数据
if not value then
local rev, err = get_from_redis(key)
if not rev then
ngx.say("redis cache not exists")
return
end
-- 把redis缓存数据放入本地内存字典
set_to_cache(key, rev, 60)
end
return value
end
-- 其它省略...- 之前经过服务器优化实现:JVM 优化实现、数据库连接池优化实现、多级缓存优化、部署拓扑结构变化对性能影响——压力测试验证优化结果,这些优化操作都是对读操作进行的优化。
- 系统中对写操作进行优化,需要根据涉及到的具体业务实现:例如下单。
- 前提:一系列的验证(身份信息、token、手机号、商品是否上架、是否是秒杀商品、商品状态、库存是否OK、活动是否开始,...)
- 业务实现:
- 检查库存是否存在;
- 扣减库存;
- 更新库存;
- 下单实现。
- 秒杀实现,业务上是非常之简单的,但是在高并发压力下,也面临一系列的挑战:
- 如何在高并发情况下,保证库存不会出现超卖现象;
- 如何在高并发模式下,解决下单性能问题;
- 如何在高并发模式下,保证数据一致性问题。
- 超卖产生的原因是什么?

- 如何避免超卖现象的发生呢?请提出你的解决方案。
- 回答:1、对共享资源(库存)加锁;2、Redis原子操作特性;3、队列(利用队列的单线程特性)
- 对象共享资源库存加锁,让共享资源被多个线程互斥访问。

- 加锁目的:防止多个线程对共享资源的并发修改。一旦加锁,多个线程就进行排队执行,因此在高并发模式,这样的操作是一个灾难。明确一下:任何的加锁动作,都会导致性能急剧下降。
- Redis单线程服务器,利用单线程的特性。
- 例如,Redis 中数据结构如下:
# 秒杀商品
key: seckill_goods_1
value: {"id": 1, "name": "vivo", "stockCouunt": 6}
# 商品库存
key: seckill_goods_stock_1
value: 6- 进行扣减库存操作:此操作是一个原子操作 --- 多个线程也是要排队
hincrement("seckill_goods_stock_1", -1);- 以上操作既解决性能问题,又解决库存超卖的问题。

- 此队列的特点:
- 队列的长度等于商品个数:POP 一个队列,就相当于扣减了一个库存,且队列操作是一个原子操作;
- 队列中存储的数据是对应商品的ID值;
- 每一个商品都对应一个队列。
- 接口及其服务实现:
@Api(tags = "秒杀下单模块")
@RestController
@RequestMapping("seckill")
public class SeckillOrderController {
@Resource
private UserService userService;
@Resource
private SeckillOrderService seckillOrderService;
@ApiOperation("普通下单操作")
@GetMapping("/order/{id}/{token}")
public RestResponse<Boolean> generalKilled(@PathVariable Long id,
@PathVariable String token) {
BaseUser baseUser = userService.queryUserByToken(token);
if (baseUser == null) {
return RestResponse.error(RestResponseCode.TOKEN_OVERTIME);
}
return RestResponse.success(seckillOrderService.generalKilled(id, baseUser.getGuid()));
}
}
@Slf4j
@Service
public class SeckillOrderServiceImpl implements SeckillOrderService {
@Resource
private TbSeckillGoodsMapper seckillGoodsMapper;
@Resource
private TbSeckillOrderMapper seckillOrderMapper;
@Override
public boolean generalKilled(Long id, String userId) {
// 1、从数据库查询商品数据,并进行校验
TbSeckillGoods seckillGoods = seckillGoodsMapper.selectByPrimaryKey(id);
validateSeckillGoods(seckillGoods);
// 2、扣减库存
seckillGoods.setStockCount(seckillGoods.getStockCount() - 1);
// 3、更新库存
seckillGoodsMapper.updateByPrimaryKeySelective(seckillGoods);
// 4、下单
TbSeckillOrder seckillOrder = new TbSeckillOrder()
.setSeckillId(id)
.setUserId(userId)
.setCreatedTime(System.currentTimeMillis())
.setStatus(0)
.setMoney(seckillGoods.getCostPrice());
return seckillOrderMapper.insertSelective(seckillOrder) >= 1;
}
private void validateSeckillGoods(TbSeckillGoods seckillGoods) {
if (seckillGoods == null) {
throw new SeckillOrderException(RestResponseCode.SEC_GOODS_NOT_EXSISTS);
}
if (seckillGoods.getStartTime() > System.currentTimeMillis()) {
throw new SeckillOrderException(RestResponseCode.SEC_ACTIVE_NOT_START);
}
if (seckillGoods.getEndTime() <= System.currentTimeMillis()) {
throw new SeckillOrderException(RestResponseCode.SEC_ACTIVE_END);
}
if (seckillGoods.getStatus() != 1) {
throw new SeckillOrderException(RestResponseCode.SEC_NOT_UP);
}
if (seckillGoods.getStockCount() <= 0) {
throw new SeckillOrderException(RestResponseCode.SEC_GOODS_END);
}
}
}- 项目启动,然后访问 swagger 文档,登录并调用普通下单接口测试一下:

- 下面我们使用 Jmeter 并发测试一下,1000个线程秒杀1000个库存商品,看下是否会出现超卖现象

- 1000个线程秒杀成功,但是库存还有982,出现超卖了

- 现在直接进行加锁,控制共享资源库存防止并发修改,看能否解决超卖的问题。
/**
* 互斥锁,参数默认false:不公平锁
*/
private Lock lock = new ReentrantLock(true);
@Transactional
@Override
public boolean generalKilled(Long id, String userId) {
boolean result = false;
lock.lock();
try {
// ...
} finally {
lock.unlock();
}
return result;
}
- 经过验证,发现这样加 lock 锁,没有控制住库存。那么,以上加锁操作无法控制库存, 原因是什么?
- 原因是锁和事务冲突,导致此时这个锁根本不起作用。
- 下面分析:事务何时提交的?

- 针对于以上问题(锁事务冲突的问题),你的解决方案是什么?
- 解决方案: 锁上移 (锁包住事务,表现层加 AOP 锁(√))
@Override
public boolean generalKilledByLock(Long id, String userId) {
boolean result = false;
lock.lock();
try {
result = generalKilled(id, userId);
} finally {
lock.unlock();
}
return result;
}
@Transactional
@Override
public boolean generalKilled(Long id, String userId) {
// ...
}
- 定义一个加锁的注解:
/**
* 自定义注解,实现aop锁
*/
@Target({ElementType.PARAMETER, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface ServiceLock {
String description() default "";
}- 定义AOP切面:
@Slf4j
@Component
@Scope
@Aspect
@Order(1)
public class LockAspect {
/**
* 定义锁对象
*/
private static Lock LOCK = new ReentrantLock(true);
/**
* Service切入点
*/
@Pointcut("@annotation(com.veli.vshop.seckill.aop.lock.ServiceLock)")
public void lockAspect() {
}
@Around("lockAspect()")
public Object around(ProceedingJoinPoint joinPoint) {
// 初始化一个对象
Object obj = null;
// 加锁
LOCK.lock();
try {
// 执行业务
obj = joinPoint.proceed();
} catch (Throwable cause) {
log.error(cause.getMessage(), cause);
} finally {
// 业务执行结束后,释放锁
LOCK.unlock();
}
return obj;
}
}- 使用我们定义的 AOP 锁:

- 重启服务,再次使用 1000 个线程秒杀1000个库存

- 发现此时,1000 个线程秒杀成功,并且库存也控制成功,减少到 0。发现库存都可以进行完美的控制,因此aop锁可以实现库存控制的,不会出现超卖的问题。
- Lock锁只能在单机环境下起作用:只能在单个 JVM 进程中起作用,属于进程级别的锁,只对当前 JVM 进程起作用,而对于其他节点中 JVM 进程,这个锁无法控制库存的。

- 上图所示,JVM 进程中一个线程,和另一个 JVM 进程中的线程不是互斥访问的关系,因此就会导致系统A、系统B出现数据脏读的线程,出现并发修改。
- AOP锁颗粒度比较粗,对系统的性能影响是非常大的。
- 要实现进程级别的锁,实现共享资源的互斥访问,必须使用第三方的锁(第三方的加锁的东西:Redis、zookeeper、etcd)。

- 锁:单进程的系统中,存在多线程同时操作一个公共变量,此时需要加锁对变量进行同步操作,保证多线程的操作线性执行消除并发修改。解决的是单进程中的多线程并发问题。
- 分布式锁:只要的应用场景是在集群模式的多个相同服务,可能会部署在不同机器上,解决进程间安全问题,防止多进程同时操作一个变量或者数据库。解决的是多进程的并发问题。
- 事务:解决一个会话过程中,上下文的修改对所有数据库表的操作要么全部成功,要不全部失败。所以应用在service层。解决的是一个会话中的操作的数据一致性。
- 分布式事务:解决一个联动操作,比如一个商品的买卖分为:① 添加商品到购物车;②修改商品库存-1。此时购物车服务和商品库存服务可能部署在两台电脑,这时候需要保证对两个服务的操作都全部成功或者全部回退。解决的是组合服务的数据操作的一致性问题。
- 分布式锁: MySQL、Redis、Zookeeper 三个服务都可以作为第三方加锁的服务。
悲观锁(for update) 加锁实现方式

- 以上查询库存的操作,加上for update,表示所有的线程执行此方法的时候,都是互斥的访问关系。
- 经过测试: 在分布式集群模式下,通过 openresty 分发请求实现测试,发现库存是可以实现控制的,说明使用的悲观锁是完全 OK 的。
乐观锁(添加一个字段: version)
- 乐观锁操作的核心:匹配版本,如果版本相同,获得执行权限,否则没有执行权限(没有下单操作),因此也不会出现超卖。
@Update(value = "update tb_seckill_goods set stock_count=stock_count-1, version=version+1 where id = #{id} and version = #{version}")
int updateByPrimaryKeyWithVersion(@Param("id") Long id, @Param("version") Integer version);- 注意:乐观锁方式不一定要求库存 1000 一定要卖完,下单成功 300 个,订单只会有 300 个,还剩下 700 个库存(不是订单),这不是超卖。
- 并且使用乐观锁方式,能提高TPS。
- Redis分布式锁:基于内存的高性能的锁,但是存在问题(Redis 是AP模型的数据库,因此在海量的数据模式下,存在数据丢失的可能,Redis丢失的概率 < MySQL),Redis 使用 RedLock 解决锁丢失的问题。
- Redisson 分布式锁实现框架:可重入锁、锁续航,RedLock 都已经实现了。
- 使用 Redission 实现加锁动作:
@Target({ElementType.PARAMETER, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface ServiceRedisLock {
String description() default "";
}
@Slf4j
@Component
@Scope
@Aspect
@Order(1)
public class LockRedisAspect {
private static final String SECKILL_GOODS_PREFIX = "seckill_goods_lock_";
/**
* 定义锁对象
*/
@Resource
private HttpServletRequest request;
/**
* Service切入点
*/
@Pointcut("@annotation(com.veli.vshop.seckill.aop.lock.ServiceRedisLock)")
public void lockAspect() {
}
@Around("lockAspect()")
public Object around(ProceedingJoinPoint joinPoint) {
// 获取id
String uri = request.getRequestURI();
String id = uri.substring(uri.lastIndexOf("/") - 1, uri.lastIndexOf("/"));
// 初始化一个对象
Object obj = null;
// 加锁: 先获取一把锁
String lockKey = SECKILL_GOODS_PREFIX + id;
boolean result = RedissonLockUtils.tryLock(lockKey, 3, 10, TimeUnit.SECONDS);
try {
if (result) {
// 执行业务
obj = joinPoint.proceed();
}
} catch (Throwable cause) {
if (cause instanceof CustomException) {
throw (CustomException) cause;
} else {
log.error(cause.getMessage());
}
} finally {
// 业务执行结束后,释放锁
if (result) {
RedissonLockUtils.unlock(lockKey);
}
}
return obj;
}
}
- 所谓的防止超卖,就是解决下单的订单数和库存扣减数一致就可以;只要解决了这个问题,就不会出现超卖的问题。
- 任何加锁的动作,都会导致性能的严重下降,因此考虑在互联网高并发模式,服务性能问题。
- 业务优化的法则:读缓存,写异步。
- 为了提高性能,解决业务库存的问题:库存进入 Redis 缓存进行存储,使用 Redis 原子性操作解决库存超卖的问题,因此这样既兼顾服务性能问题,也解决了超卖的问题。

- 库存优化存储方案:
- 存储方式一:Redis String 类型单独存储一份库存;
- 存储方式二:List队列存储商品ID(库存)
- 以下就是 Redis 商品数据存储的方案:
# 秒杀商品
key: seckill_goods_1
value: {"id": 1, "name": "vivo", "stockCouunt": 6}
# 商品库存
key: seckill_goods_stock_1
value: 6- 查询秒杀商品数据:从 Redis 中查询
- 扣减库存实现:从 Redis 中扣减库存
@Transactional(rollbackFor = Exception.class)
@Override
public boolean redisCacheKilled(Long id, String userId) {
// 优化一:从缓存中获取秒杀商品数据
TbSeckillGoods seckillGoods = redisService.getObjValue(SEC_KILL_GOODS_CACHE_PREFIX + id);
validateSeckillGoods(seckillGoods);
// 优化二:利用Redis的原子性操作扣减库存,不需要上锁
boolean result = reduceStock(id);
if (!result) {
throw new SeckillOrderException(RestResponseCode.SEC_GOODS_STOCK_FAIL, "扣减库存失败");
}
// 下单
TbSeckillOrder seckillOrder = new TbSeckillOrder()
.setSeckillId(id)
.setUserId(userId)
.setCreatedTime(System.currentTimeMillis())
.setStatus(0)
.setMoney(seckillGoods.getCostPrice());
// 3、异步实现(blockingQueue,disruptor,rocketMQ队列实现异步)
// 队列实现异步下单操作
return seckillOrderMapper.insertSelective(seckillOrder) >= 1;
}
private boolean reduceStock(Long id) {
Long result = redisService.incrInt(SEC_KILL_GOODS_STOCK_CACHE_PREFIX + id, -1);
if (result > 0) {
// TODO 发送消息
//
return true;
} else if (result == 0) {
//
// 记录标识,表示此商品已经售卖结束
redisService.setIntValue(SEC_KILL_GOODS_STOCK_END_CACHE_PREFIX + id, 1);
return true;
} else {
// 扣减库存失败
redisService.incrInt(SEC_KILL_GOODS_STOCK_CACHE_PREFIX + id, 1);
return false;
}
}- 经过压力测试,经过缓存优化后,TPS对写操作来说,有了明显的提升。
- 定义一个异步队列:
public class SeckillQueue {
/**
* 队列大小
*/
private static final int MAX_SIZE = 100;
/**
* 定义一个队列:用于多线程间下单的队列
*/
private static final BlockingQueue<TbSeckillOrder> QUEUE = new LinkedBlockingQueue<>(MAX_SIZE);
private SeckillQueue() {
}
/**
* 静态内部类实现单例
*/
private static class Holder {
private static SeckillQueue INSTANCE = new SeckillQueue();
}
public static SeckillQueue getInstance() {
return Holder.INSTANCE;
}
/**
* 生产入队
* add(e) 队列未满时,返回true;队列满则抛出IllegalStateException(“Queue full”)异常——AbstractQueue
* put(e) 队列未满时,直接插入没有返回值;队列满时会阻塞等待,一直等到队列未满时再插入。
* offer(e) 队列未满时,返回true;队列满时返回false。非阻塞立即返回。
* offer(e, time, unit) 设定等待的时间,如果在指定时间内还不能往队列中插入数据则返回false,插入成功返回true。
*/
public boolean produce(TbSeckillOrder order) {
return QUEUE.offer(order);
}
/**
* 消费出队
* poll() 获取并移除队首元素,在指定的时间内去轮询队列看有没有首元素有则返回,否者超时后返回null
* take() 与带超时时间的poll类似不同在于take时候如果当前队列空了它会一直等待其他线程调用notEmpty.signal()才会被唤醒
*/
public TbSeckillOrder consume() throws InterruptedException {
return QUEUE.take();
}
/**
* 获取队列大小
*/
public static int getSize() {
return QUEUE.size();
}
}- 定义一个线程去监听这个队列,一旦队列中有订单数据,就去下单:
@Slf4j
@Component
public class TaskRunner implements ApplicationRunner {
private static final ExecutorService EXECUTOR = Executors.newSingleThreadExecutor();
@Resource
private SeckillOrderService seckillOrderService;
@Override
public void run(ApplicationArguments args) throws Exception {
// 提交一个任务,一直监听bockingQueue队列
EXECUTOR.submit(() -> {
log.info("==>> TaskRunner started");
while (true) {
try {
TbSeckillOrder order = SeckillQueue.getInstance().consume();
if (order != null) {
// 从队列中获取订单,执行下单操作
seckillOrderService.generalKilled(order.getSeckillId(), order.getUserId());
}
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
});
}
}- 异步实现下单:

- 再次进行压力测试,可以发现 TPS 又有了显著提升。
- 在计算机科学中,CAP定理(CAP throrem)又被称做【布鲁尔定理(Brewer's theorem)】,它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency):所有节点在同一时间具有相同的数据。
- 可用性(Availability):保证每个请求不管成功或者失败都有响应。
- 分区容错性(Partition tolerance):系统中任意信息的丢失或失败不会影响系统的继续运行。
- CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性、可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
- Redis AP模型:保证服务可用性,不保证服务数据一致性;因此处理业务问题的时候,也不能同时兼顾数据一致性,可用性(性能)。
- 业务处理方面:既要兼顾一致性,又要性能,采用最终的一致性。
- 问题一:扣减库存(扣减Redis的)成功,但是下单(写MySQL)失败了,层次是下单操作是可以进行事务回滚的,但是 Redis 不能回滚。
- 问题二:扣减库存是 Redis 的库存,数据库的库存却没有发生扣减,此时数据库的库存和缓存的库存就不一致了。
- 解决方案:扣减库存成功后,发送消息,通知 MySQL 同步库存即可; 保证 Redis 库存与 MySQL 的库存是一致性的状态。
- 消息发送者:
private boolean reduceStock(Long id) {
Long result = redisService.incrInt(SEC_KILL_GOODS_STOCK_CACHE_PREFIX + id, -1);
if (result >= 0) {
// 扣减库存成功发送消息
producer.sendSyncStockMsg(id);
if (result == 0) { // 记录标识,表示此商品已经售卖结束
redisService.setIntValue(SEC_KILL_GOODS_STOCK_END_CACHE_PREFIX + id, 1);
}
return true;
} else {
// 扣减库存失败
redisService.incrInt(SEC_KILL_GOODS_STOCK_CACHE_PREFIX + id, 1);
return false;
}
}- 消息消费者:
consumer.registerMessageListener((MessageListenerConcurrently) (messages, context) -> {
try {
for (MessageExt messageExt : messages) {
String message = new String(messageExt.getBody(), RemotingHelper.DEFAULT_CHARSET);
// 同步数据库的库存
seckillGoodsMapper.updateByPrimaryKeyWithLock(Long.valueOf(message));
log.info("[Consumer] msgID: {}, msgBody: {}", messageExt.getMsgId(), message);
}
} catch (Exception e) {
// 如果出现异常,必须告知消息进行重试
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});- 通过发送消息,解决了缓存的库存,和数据库的库存的数据一致性问题。
- 扣减库存(扣减的是 Redis 的)成功,但是下单失败了,此时下单操作是可以进行事务回滚,但是 Redis 不能回滚,数据不一致。
- 消息发送失败了怎么办?
- 库存回补又失败了,如何解决?

- 发送消息与本地事务本身就不是一个原子操作,做不到要么都成功,要么都失败。
- 存在的问题:发送消息成功了,但是本地事务失败了,导致本地回滚。

- 存在的问题:本地事务执行成功了,发送消息失败了。

- 利用RocketMQ事务消息,解决数据最终消息一致性;为了性能提升,必须采用这样的方案。

需要解决的问题:
- 业务问题:考虑在高并发模式下库存超卖的问题——利用 Redis 单线程模型【已解决】。
- 下单操作性能问题:既考虑库存的问题,又要考虑性能的问题——缓存+异步【已解决】。
- 数据一致性问题:利用 RocketMQ 事务消息,实现消息的最终一致性,充分考虑到了性能的问题。
@Slf4j
@Component
public class TransactMQProducer {
private TransactionMQProducer producer = new TransactionMQProducer();
@Resource
private RocketmqConfig rocketmqConfig;
@Resource
private SeckillOrderService seckillOrderService;
@Resource
private TbSeckillGoodsMapper seckillGoodsMapper;
@PostConstruct
public void init() {
try {
producer.setProducerGroup(rocketmqConfig.getGroupName());
producer.setNamesrvAddr(rocketmqConfig.getNamesrvAddr());
producer.setRetryTimesWhenSendFailed(rocketmqConfig.getRetryTimes());
producer.setVipChannelEnabled(false);
producer.start();
addListener();
log.info("[Producer] Started ...");
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
public void addListener() {
// 注入一个监听器
producer.setTransactionListener(new TransactionListener() {
/**
* 执行本地业务的方法
*/
@Override
public LocalTransactionState executeLocalTransaction(Message message, Object o) {
Long seckillId = 0L;
try {
// 获取消息内容
String msg = new String(message.getBody(), RemotingHelper.DEFAULT_CHARSET);
SeckillDto seckillDto = JsonUtils.toObj(msg, SeckillDto.class);
if (seckillDto != null) {
seckillId = seckillDto.getSeckillId();
seckillOrderService.redisCacheKilled(seckillDto.getSeckillId(), seckillDto.getUserId());
}
} catch (SeckillOrderException e) {
// 业务处理中出现一个预知的异常,设置事务回滚状态
TbSeckillGoods updateObj = new TbSeckillGoods()
.setId(Integer.parseInt(seckillId.toString()))
.setTransactionStatus(-1);
seckillGoodsMapper.updateByPrimaryKeySelective(updateObj);
return LocalTransactionState.ROLLBACK_MESSAGE;
} catch (Exception e) {
log.error(e.getMessage(), e);
return LocalTransactionState.UNKNOW;
}
// 业务执行成功,确定事务提交状态
return LocalTransactionState.COMMIT_MESSAGE;
}
/**
* 事务状态回查方法
*/
@Override
public LocalTransactionState checkLocalTransaction(MessageExt messageExt) {
try {
// 获取消息内容
String msg = new String(messageExt.getBody(), RemotingHelper.DEFAULT_CHARSET);
SeckillDto seckillDto = JsonUtils.toObj(msg, SeckillDto.class);
// 查询事务状态
TbSeckillGoods seckillGoods = seckillGoodsMapper.selectByPrimaryKey(seckillDto.getSeckillId());
// 根据事务状态,判定事务 commit, rollback, unkown
switch (seckillGoods.getTransactionStatus()) {
case -1:
return LocalTransactionState.ROLLBACK_MESSAGE;
case 1:
return LocalTransactionState.COMMIT_MESSAGE;
default:
return LocalTransactionState.UNKNOW;
}
} catch (Exception e) {
log.error(e.getMessage(), e);
}
return LocalTransactionState.COMMIT_MESSAGE;
}
});
}
/**
* 发送消息,使用事务型消息把所有的操作原子化
*/
public boolean sendTransactionMsg(Long seckillId, String userId) {
try {
SeckillDto seckillDto = new SeckillDto(seckillId, userId);
byte[] bytes = JsonUtils.toStr(seckillDto).getBytes(RemotingHelper.DEFAULT_CHARSET);
Message message = new Message(rocketmqConfig.getTopic(), bytes);
producer.sendMessageInTransaction(message, null);
} catch (Exception e) {
log.error(e.getMessage(), e);
return false;
}
return true;
}
@PreDestroy
public void destroy() {
if (producer != null) {
producer.shutdown();
}
}
}- 只扣减redis库存,最终还必须同步数据库库存,让数据库库存和redis库存保持一个一致的状态。
@Slf4j
@Component
public class RocketmqConsumer {
@Resource
private TbSeckillGoodsMapper seckillGoodsMapper;
@Resource
private RocketmqConfig rocketmqConfig;
@Bean
public DefaultMQPushConsumer seckillMqConsumer() {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer(rocketmqConfig.getGroupName());
consumer.setNamesrvAddr(rocketmqConfig.getNamesrvAddr());
try {
// 广播模式消费
consumer.subscribe(rocketmqConfig.getTopic(), "*");
// 如果是第一次启动,从队列头部开始消费;如果不是第一次启动,从上次消费的位置继续消费
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
consumer.setVipChannelEnabled(false);
consumer.registerMessageListener((MessageListenerConcurrently) (messages, context) -> {
try {
for (MessageExt messageExt : messages) {
String message = new String(messageExt.getBody(), RemotingHelper.DEFAULT_CHARSET);
SeckillDto seckillDto = JsonUtils.toObj(message, SeckillDto.class);
// 同步数据库的库存
seckillGoodsMapper.updateByPrimaryKeyWithLock(seckillDto.getSeckillId());
log.info("[Consumer] msgID: {}, msgBody: {}", messageExt.getMsgId(), JsonUtils.toStr(seckillDto));
}
} catch (Exception e) {
// 如果出现异常,必须告知消息进行重试
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
consumer.start();
log.info("[Consumer] Started ...");
} catch (Exception e) {
log.error(e.getMessage(), e);
}
return consumer;
}
}- 业务的操作中,必须在可能出现问题的代码出抛出异常,让消息生产者感知到问题所在,且做出合理的反应(设置事务状态为回滚状态)。
@Transactional(rollbackFor = Exception.class)
@Override
public boolean redisCacheKilled(Long id, String userId) {
// 优化一:从缓存中获取秒杀商品数据
TbSeckillGoods seckillGoods = redisService.getObjValue(SEC_KILL_GOODS_CACHE_PREFIX + id);
validateSeckillGoods(seckillGoods);
// 优化二:利用Redis的原子性操作扣减库存,不需要上锁
boolean result = reduceStock(id);
if (!result) {
throw new SeckillOrderException(RestResponseCode.SEC_GOODS_STOCK_FAIL, "扣减库存失败");
}
// 下单
TbSeckillOrder seckillOrder = new TbSeckillOrder()
.setSeckillId(id)
.setUserId(userId)
.setCreatedTime(System.currentTimeMillis())
.setStatus(0)
.setMoney(seckillGoods.getCostPrice());
// 优化三:异步实现(blockingQueue,disruptor,rocketMQ队列实现异步)
// 队列实现异步下单操作
boolean produceRes = SeckillQueue.getInstance().produce(seckillOrder);
if (!produceRes) {
throw new SeckillOrderException(RestResponseCode.SEC_GOODS_STOCK_FAIL);
}
// 设置事务状态
seckillGoods.setTransactionStatus(1).setStockCount(null);
// 更新事务状态
seckillGoodsMapper.updateByPrimaryKeySelective(seckillGoods);
return true;
}// SeckillOrderController
@ApiOperation("⑥ 使用MQ异步下单,实现库存控制和缓存优化")
@GetMapping("/order/mq/{id}/{token}")
public RestResponse<Boolean> mqKilled(@PathVariable Long id,
@PathVariable String token) {
BaseUser baseUser = userService.queryUserByToken(token);
if (baseUser == null) {
return RestResponse.error(RestResponseCode.TOKEN_OVERTIME);
}
return RestResponse.success(seckillOrderService.mqKilled(id, baseUser.getGuid()));
}
// SeckillOrderService
@Override
public boolean mqKilled(Long id, String userId) {
Future<Object> future = TaskUtils.submit(() -> {
boolean result = transactMQProducer.sendTransactionMsg(id, userId);
if (!result) {
throw new SeckillOrderException();
}
return null;
});
try {
future.get();
} catch (Exception e) {
throw new SeckillOrderException(RestResponseCode.SEC_GOODS_STOCK_FAIL, "消息发送失败");
}
return true;
}开发 + 运营(测试,运维,文档,代码……)
- 开发+运维: 一种文化系统,旨在建立一套流水线生产模式,提高代码生产效率;从开发,测试,发布能够更加快速,高效;DevOps旨在构建一套能够快速迭代的项目开发流程(架构),使得项目的发布可以更可靠的发生;
- 软件开发交付的自动化实现(利用一些工具),实现CI/CD。

- 对于后端开发人员:
- 和运维进行深度结合,协同工作,编写一些运维相关的代码(脚本:shell、kubernetes相关、dockerfile),创建一个更好、更高效的产品。
- 云原生架构:项目符合云原生的架构体系,考虑写代码(JDK、Spring、SpringCloud)
- 对于运维开发人员:
- 帮助企业实现更加自动化(编写自动化脚本)、智能化、无人化 – 更加高效的生产环境。
- DevOps工程师:开发一些自动化的脚本,实现项目自动化发布,使得项目发布更加智能化,从而使得企业降本增效。
- Jenkins:实现项目代码编译、构建、打包、构建镜像,push 到镜像仓库,借助一些自动化的脚本实现流水线生产模式。
- Docker:容器化可以跨平台,实现服务从测试环境,生产环境的无缝迁移;更好的使用微服务架构(PHP、GO、Java)。
- Kubernetes:容器云的操作系统,容器越来越多,需要使用kubernetes管理这些容器,调度这些容器。
- 互联网软件的开发和发布,已经形成了一套标准流程,假如把开发工作流程分为以下几个阶段:
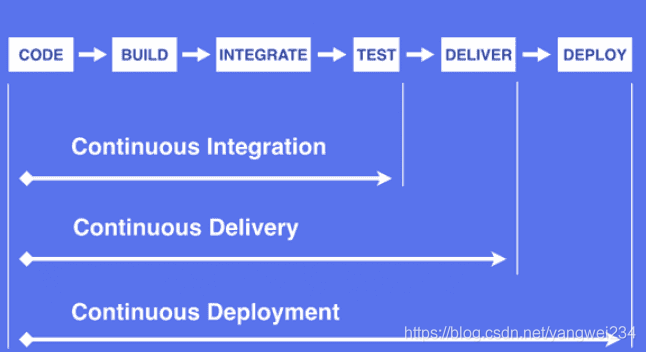
- 正如你在上图中看到,[持续集成(Continuous Integration)]、[持续交付(Continuous Delivery)]和[持续部署(Continuous Deployment)]有着不同的软件自动化交付周期。
- 可以参考我之前的文章 Jenkins持续集成&部署
- 不使用容器,直接使用shell脚本,构建一套自动化发布流程。


- 部署流程有多种构建方式:
- 脚本化的方式构建:由运维开发自动化的脚本,整合 Dockerfile、Kubernetes 流水线生产环境,来进行项目部署。
- Java查询构建镜像,Push到镜像仓库,实现服务部署。
- Dockerfile是由一系列命令和参数构成的脚本,这些命令应用于基础镜像并最终创建一个 新的镜像。
- 对于开发人员:可以为开发团队提供一个完全一致的开发环境;
- 对于测试人员:可以直接拿开发时所构建的镜像或者通过Dockerfile文件构建一个新 的镜像开始工作了;
- 对于运维人员:在部署时,可以实现应用的无缝移植。
- 使用自己做的JDK镜像:hub.veli.com/library/jdk1.8.0:241,可以请参考我之前的博客:https://blog.csdn.net/yangwei234/article/details/97831360
FROM hub.veli.com/library/jdk1.8.0:241
MAINTAINER admin
VOLUME /tmp
WORKDIR /
ADD vshop-web.jar /
ENTRYPOINT ["java","-jar","vshop-web.jar"]- 镜像构建&推送镜像:
docker build -t hub.veli.com/vshop/vshop-web:v1 .
docker push hub.veli.com/vshop/vshop-web:v1 <plugin>
<groupId>com.spotify</groupId>
<artifactId>docker-maven-plugin</artifactId>
<version>0.4.13</version>
<configuration>
<!--dockerfile 指令:变成插件配置-->
<!--用于指定镜像名称-->
<imageName>hub.veli.com/vshop/${project.artifactId}:${project.version}</imageName>
<!--用于指定基础镜像,相当于Dockerfile中的FROM指令-->
<baseImage>hub.veli.com/library/jdk1.8.0:241</baseImage>
<!--指定工作目录-->
<!--<workdir>/</workdir>-->
<maintainer>[email protected]</maintainer>
<cmd>["java","-version"]</cmd>
<!--相当于Dockerfile的ENTRYPOINT指令-->
<!--dockerfile : entryPoint-->
<entryPoint>["java","-jar","/${project.build.finalName}.jar"]</entryPoint>
<!--指定harbor镜像仓库地址,指定:镜像仓库用户名,密码-->
<serverId>my-docker-registry</serverId>
<!--是否跳过docker build-->
<!--<skipDockerBuild>true</skipDockerBuild>-->
<resources>
<resource>
<!--workdir ADD xx.jar / -->
<!--workdir 工作目录-->
<targetPath>/</targetPath>
<!--用于指定需要复制的根目录,${project.build.directory}表示target目录-->
<directory>${project.build.directory}</directory>
<!--用于指定需要复制的文件。${project.build.finalName}.jar指的是打包后的jar包文件-->
<include>${project.build.finalName}.jar</include>
</resource>
</resources>
<!--使用本地镜像仓库使用-->
<!-- <dockerHost>http://192.168.254.116:2375</dockerHost>-->
</configuration>
</plugin>- my-docker-registry:配置harbor镜像仓库的地址,使得可以把镜像推送到harbor镜像中去。


- Push 推送镜像到我们的镜像仓库中去:

- 到harbor仓库查看镜像:
