- IBM Cloud Account - www.bluemix.net
Login to www.bluemix.net and create the following services:
- Watson Machine Learning
- Cloud Object Storage
- Apache Spark
In order to do so, go to the Catalog find the wanted service.

1. IBM Machine Learning
IBM Watson Machine Learning is an IBM Cloud service that enables users to perform two fundamental operations of machine learning: training and scoring. - Training is the process of refining an algorithm so that it can learn from a data set. The output of this operation is called a model. A model encompasses the learned coefficients of mathematical expressions. - Scoring is the operation of predicting an outcome by using a trained model. The output of the scoring operation is another data set containing predicted values. Watson Machine Learning service is under the Data & Analytics category.

Make sure you have the correct region and space where you want to create your service and click on create.

2. Apache Spark
Apache Spark is an open source cluster computing framework optimized for extremely fast and large scale data processing, which you can access via the newly integrated notebook interface IBM Analytics for Apache Spark. You can connect to your existing data sources or take advantage of the on-demand big data optimization of Object Storage. Spark plans are based on the maximum number of executors available to process your analytic jobs. Executors exist only as long as they're needed for processing, so you're charged only for processing done.
Go back to the Catalog and repeat the process for Apache Spark also located under Data & Analytics

Make sure you have the correct region and space where you want to create your service and click on create.

3. Cloud Object Storage
IBM Cloud Object Storage is a highly scalable cloud storage service, designed for high durability, resiliency and security. Store, manage and access your data via our self-service portal and RESTful APIs. Connect applications directly to Cloud Object Storage use other IBM Cloud Services with your data.
Go back to the Catalog and repeat the process for Cloud Object Storage, located under Storage.

Make sure you have the correct region and space where you want to create your service and click on create.

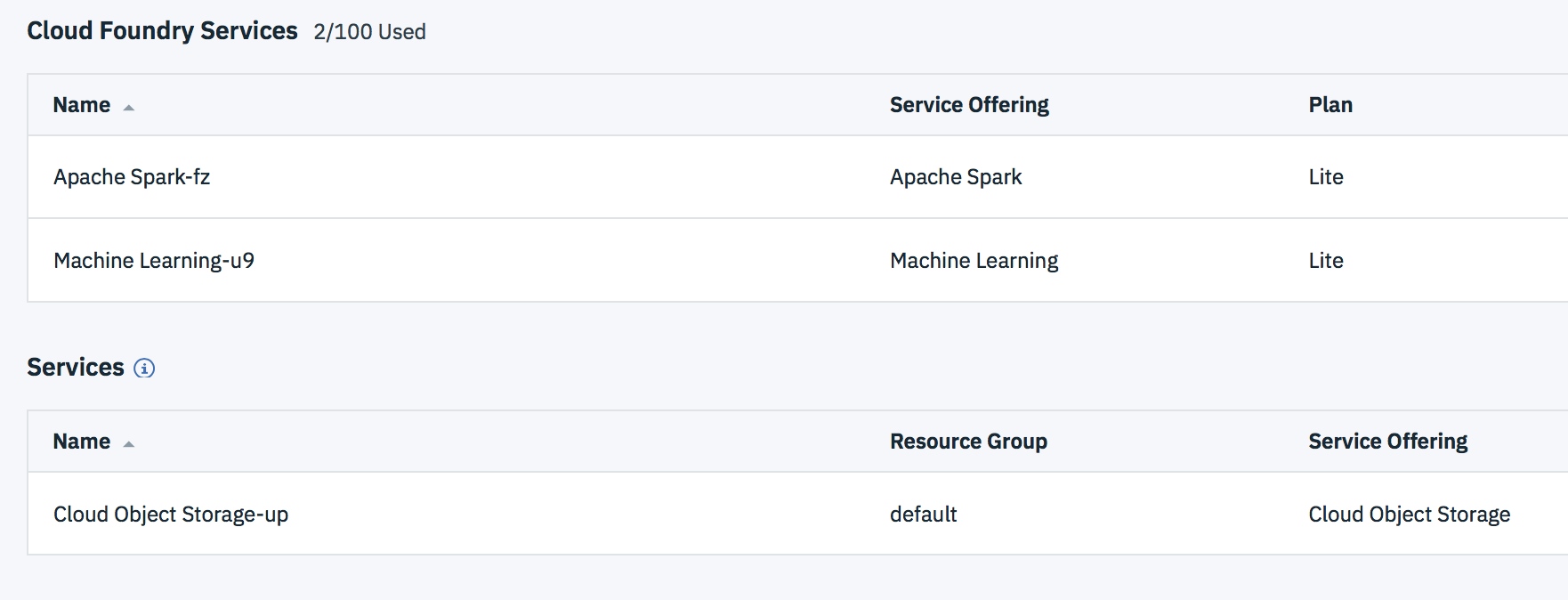
Once you have created the three services click on the IBM Cloud logo on the top left corner to go to your Dashboard.

Listed you will find the needed services as shown in the image.
Go to https://eu-gb.datascience.ibm.com to access IBM Data Science Experience.

Sign in using your IBM Cloud credentials.
First time you log in the service will prompt a window with you account information. Confirm your information by clicking on Continue.

After few seconds your Data Science Experience environment will be ready. Click on Done.

Click on New Project.

Give the project a name and connect with your Spark and Object Storage instances. You should see the services you created in Step 1.

Then click on Create and your project will be ready!
Go to the Settings tab and confirm that your project is connected to your Machine Learning, Spark and Object Storage services created in Step 1.


If you are missing a service click on add new service, from existing and select from the list your service.

You can create a machine learning model by using the model builder, the flow editor, or a notebook to prepare data, train the model, and deploy the model. In this example we will use the model builder.
Next click on the Assets tab.

Under the section Models, click on New model.

We will build a logistic regression model that assesses the likelihood that a customer of an outdoor equipment company will buy a tent. Give the model a name and a description, select Model builder and Manual.
-
Automatic method: you rely on automatic data preparation (ADP) completely.
-
Manual method: in addition to some functions that are handled by the ADP transformer, you can add and configure your own estimators, which are the algorithms used in the analysis.

Click on Create.
Let's add some data! Download the GoSales_Tx_LogisticRegression.csv file from this repository and click on Add data assets.
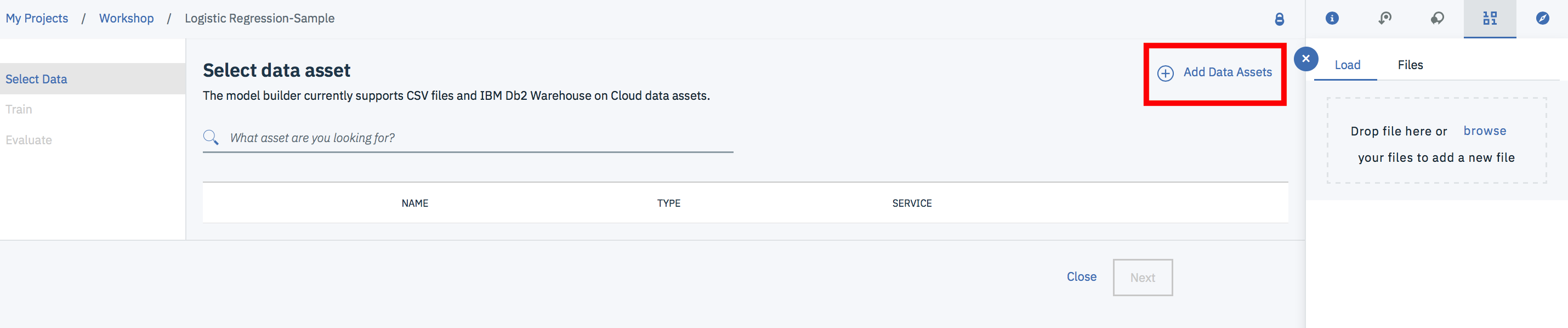
Browse for the csv file and open it. Once it finished loading you will see it in the data assets. Select it and click on Next.

After you load the data you must train the data. This consists of choosing the appropiate technique and estimator to apply to the raw data.
For the label colum select IS_TENT and keep the default feature columns. Select Binary Classification, next add an estimator using Logistic regression and click Next. This may take few minutes.

After the training is complete save the model.

After you create, train, and evaluate a model, you can deploy it. Although it is possible to score a model without deploying it, a model has to be deployed before it can be scored from the Watson Machine Learning APIs. Also, a model can only have a single deployment. For a trial account, a user can have only one deployed model at a time.
Go to the deployments tab and click on add a deployment.

Give your deployment a name and click save.

When the model deployment is complete, view the deployment by clicking on the three dots on under Actions and then view.
Go to the test tab and interact with the model. Change the model inputs and check the prediction.
