Reinforcement learning is a training method of rewarding the good and punishing the bad. It will learn by trial and error
Ofcourse there are multiply kinds of reinforcement learning:
- Q-learning
- Policy Gradient
- Deep Q Neural Network
I choose deep-Q neural network: but what is it?
To understand deep-Q neural network you first have to understand Q-learning.
Q-learning is a Reinformcent Learning policy that will find the next best aciton, given a current state. This will depent on where the agent is in the environment. Its model-free meaning that the agent uses predictions of the environments expected response to move forward.
- States: The state, S, represents the current position of an agent in an environment
- Action: The action, A, is the step taken by the agent when it is in a particular state
- Rewards: For every action, the agent will get a positive or negative reward
- Episodes: When an agent ends up in a terminating state and can't take a new action
- Q-values: Used to determine how good an action, A, taken at a particular state, S, is. Q(a, s)
- Q-table: repesentation of all action and states
It uses The Bellman Equation.
The bellman equation is used to determine the value of a particular state and deduce how good it is to be in that state. The optimal state will give us the highest optimal value.
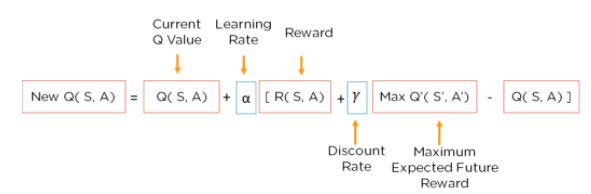
A Q-table helps us to find the best action for each state in the environment.
We Use the bellman Equation at each state tot get the excpected future state and reward and save it in a table to compare with other states.
An example of a q-table may look like this:
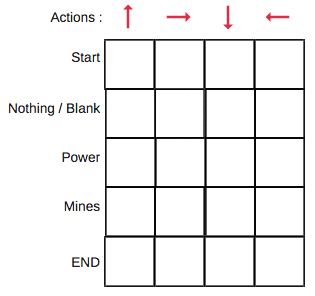
With Start, Nothing, Power, Mines and end, representing the states
and the arrows the actions
At first all Q-values will be initialed with 0, making it so the agent knows nothing. This means his first action will be random because no action reward is bigger then another. This makes the agent explore.
After that, the Q-values will be calculated with the reward from that action and the bellman equation, updating the Q-value on that state and action Q(a, s).
As I said earlier I use deep Q-learning but why?
The Q-table needs all action and states, this works well with a small amount of states with just a in this or not in this states.
But in Galaga there are more then a few states, Each position of the player, bullets, and enemy would need to be state, these can go in the 100 states per making it a very large Q-table, this would make training it take very long and not effecient. Thats why I chose deep Q-learning
Deep Q-learning is Q-learning but with a neural network
Instead of using a Q-table, deep Q-learning uses a neural network to take the states and convert their values into the right action.

A neural network has weight connecting all neurons. for every connection of a neuron there is a calculation done, the result is the value of the connected neuron. By training the Neural network the weight value of these connections change changing the outcome.
I run 500 batches(games) at the same times, and when they are all done, either dead, no time left or killed all the enemies. I compare them all, take the 2 with the highest score and run a MergeAndMutate function, this will create a new neural network with connections from those 2 neural network and adding a random chance of mutating a weight to a complete random value. Making the new episode better than the last one.
Ofcourse some inputs values can scale very high making them having a bigger impact, this is solved by using an activation function
You have different kind of activation function, I use sigmoid scaling the values [0, 1].
In this project I have a character(the deep Q-leanring character) that train his neural network to defeat the enemies.
He has 17 inputs:
- bulletOneX
- bulletOneY
- distanceToBulletOne
- bulletTwoX
- bulletTwoY
- distanceToBulletTwo
- bulletThreeX
- bulletThreeY
- distanceToBulletThree
- playerX
- DistanceToLeftBorder
- DistanceToRightBorder
- Distance to closestEnemy
- EnemyCount
- ShootDelay
- EpisodeTime
He has 3 ouputs:
- MoveLeft
- MoveRight
- Shoot
And 8 Hidden neurons divided in 2 hidden layers

Green are inputs
red the hidden layers
blue the outputs
And depending on the highest output, this will be action he takes.
This all result in this

This is one episode of the AI, when the current batch dies, you switch to the next one that isnt dead, this until all are dead, starting the next episode