Pratyusha Sharma, Deepak Pathak, Abhinav Gupta
Carnegie Mellon University
University of California, Berkeley
We study a generalized setup for learning from demonstration to build an agent that can manipulate novel objects in unseen scenarios by looking at only a single video of human demonstration from a third-person perspective. If you find this work useful in your research, please cite:
@inproceedings{sharma19thirdperson,
Author = {Sharma, Pratyusha and Pathak, Deepak
and Gupta, Abhinav},
Title = {Third-Person Visual Imitation Learning via
Decoupled Hierarchical Controller},
Booktitle = {NeurIPS},
Year = {2019}
}
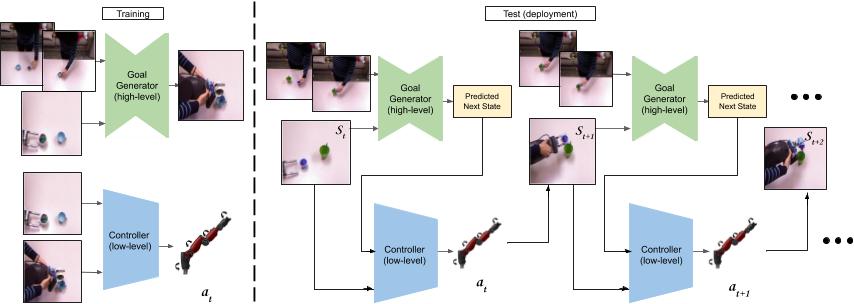
The code for the paper consists of two modules:
-
The Goal Generator: The goal generator takes in consecutive frames of a human video along with the present image of the table to hallucinate a possible next visual state of the robot's trajectory. It is contained inside the directory named 'pix2pix'.
-
Low-level Controller: The low-level controller takes as input the current visual state and the predicted visual state and outputs an action.
The two models are trained independently and are run together in alternation at test time. The code to run the models in alternation at test time is also in this repository.
- Python 3
- Pytorch 0.4+
- Linux or macOS
- CPU or NVIDIA GPU + CUDA CuDNN
- Clone this repo
git clone https://github.com/pathak22/hierarchical-imitation.git
cd hierarchical-imitation
The code for the goal generator is built using code from the wonderful pix2pix repository.
Before training the goal generator the steps listed under creating your own datasets for pix2pix need to be followed.
Since we want to translate intent from human videos to robot videos the folders should be as follows: Folder A: Human demonstration frames Folder B: Robot demonstration frames
The code used to subsample the trajectories to equal lengths to roughly align them can be found in utils as subsample.py.
Train the model:
cd pix2pix
python train.py --dataroot /location/of/the/dataset --model pix2pix
Evaluating the model:
python test.py --dataroot /location/of/the/dataset --model pix2pix
At training time the inputs to the low-level controller are consecutive images from the robot trajectory and the joint angle of the robot at the end of the two frames. Subsample the robot trajectories using the code for subsample.py.
Train the low-level controller using:
python controller_train.py --dataroot /location/of/the/dataset
Evaluate the low-level controller using:
python controller_test.py --dataroot /location/of/the/dataset
To finally test the controllers together on the robot use:
python run_on_robot.py --goal_generator /location/of/checkpoint --inverse_model /location/of/checkpoint --dataroot /location/of/the/humandemo
- Test how good the models are indivdually before running the joint run to get an estimate of how best can each of the models do in isolation
- Look at the predictions of the goal generator while running the final experiment on the robot
- A good place to start could be downloading the [MIME Dataset]. Alternatively, one could also collect their own dataset and follow the training protocol above.
- In case of a query, feel free to reach out Pratyusha Sharma at [email protected].