Hi, I'm Pius Lawal, and this course is part of my Hybrid and Multi-Cloud Developer bootcamp series.
A hybrid and multi-cloud skill is useful on-prem as well as on any cloud platform. You might learn these skills locally, or on a particular cloud platform, yet remain a ninja 🥷 in any cloud environment - Docker is a popular example.
If you like this project, but just don't have time to contribute, that's fine. There are other easy ways to support the project and show your appreciation:
- Star this project
- Tweet about it
- Reference this project in your own work
- Mention this project at local meetups and to your family/friends/colleagues
This bootcamp covers the Certified Kubernetes Application Developer (CKAD) exam curriculum plus more. In summary, you will be learning cloud application development, which is a modern approach to building and running software applications that exploits the flexibility, scalability, and resilience of cloud computing. Some highlights include:
- proficiency working on the command-line
- proficiency working with containers
- proficiency working with Kubernetes
- microservices architecture
- devops with Kubernetes
Passing the CKAD exam with confidence should be a simple 4-stage process, all of which is covered in this bootcamp:
- Learn the CKAD exam curriculum content by your preferred method
- Learn how to troubleshoot all the resources covered in the curriculum
- Familiarity with the exam-language and common exam tips
- Proficiency with
kubectland related CLI tools
How will this work?
Follow the Labs, that's all!
No prior experience required and its okay if you're not confident on the command-line, yet!
Each chapter contains several Labs to help you slowly build confidence and proficiency around the concepts covered. There are command snippet blocks provided to help you through the Labs - use them if you're stuck on any Lab and aren't yet confident using help on the terminal.
There are Tasks provided at the end of most chapters with content designed to challenge your critical understanding and troubleshooting strategy of the core concepts in that chapter. These Tasks are longer and require more time to solve than standard exam questions, which makes them more difficult. Therefore, you know you are exam-ready if you can complete all 16 Tasks under 2 hours.
What else do I need to pass CKAD?
Nothing else, this bootcamp is an All-In-One-Guide! Simply working through this bootcamp will make you proficient with Kubernetes as well as prepare you for the CKAD exam!
The Exam Readiness Mode, where you simulate the exam by completing all 16 Tasks under 2 hours, will help you identify your weak areas. Then you simply repeat those chapters/sections, and make sure to review all links to resources from the official Kubernetes documentation, until you are confident.
I know Kubernetes already?
If you have completed step [1] above, for example, you have completed a CKAD course prior or use Kubernetes day-to-day, etc, and just wish to dive into Exam Readiness Mode, skip to Ch15 - Exam tips.
I only want Kubernetes not CKAD?
Hey! CKAD is entry-level Kubernetes and covers the basic features and core components of Kubernetes. This bootcamp covers everything you need from NOOB setup to mastery. Preparing for the CKAD exam is a structured approach to learning Kubernetes. When you finish this bootcamp, you may choose not to pay for and sit the exam, but you will have acquired the ability to pass regardless.
CKAD exam curriculum?
In the CKAD exam, you will have 2 hours to complete 15-20 performance-based questions around the areas below.

Where is Table of Contents (TOC)?
GitHub has native TOC support for markdown files with filtering built-in. The TOC Header sticks to the top of the page as you scroll through the document.

A Unix-based environment running docker (Docker Engine or Docker Desktop).
macOS users
# 1. install xcode tools
sudo xcode-select --install
# 2. install homebrew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 3. install docker
brew install --cask dockerWindows users
# powershell as administrator
# 1. install wsl2
wsl --install
# 2. install terminal
winget install Microsoft.WindowsTerminal
# 3. install docker
winget install Docker.DockerDesktop
# restart deviceAfter device restart:
-
Complete Ubuntu user setup - Ubuntu terminal should auto-open
-
sudo nano /etc/wsl.conf
# /etc/wsl.conf [boot] systemd=truewsl.exe --terminate Ubuntu
-
Perform Internet connection test in WSL2 by running:
curl google.com
💡 If connection fails with
Could not resolve host, and you have a VPN program installed, see WSL2 VPN fix belowWSL2 VPN fix
See wsl-vpnkit documentation for more details.
# powershell as administrator wget -o wsl-vpnkit.tar.gz https://github.com/sakai135/wsl-vpnkit/releases/latest/download/wsl-vpnkit.tar.gz wsl --import wsl-vpnkit $env:USERPROFILE\wsl-vpnkit wsl-vpnkit.tar.gz --version 2
# wsl2 ubuntu wsl.exe -d wsl-vpnkit --cd /app cat /app/wsl-vpnkit.service | sudo tee /etc/systemd/system/wsl-vpnkit.service sudo systemctl enable wsl-vpnkit sudo systemctl start wsl-vpnkit systemctl status wsl-vpnkit # should be Active # test internet connection again curl google.com
{kind=link}
{kind=link}
{kind=link}
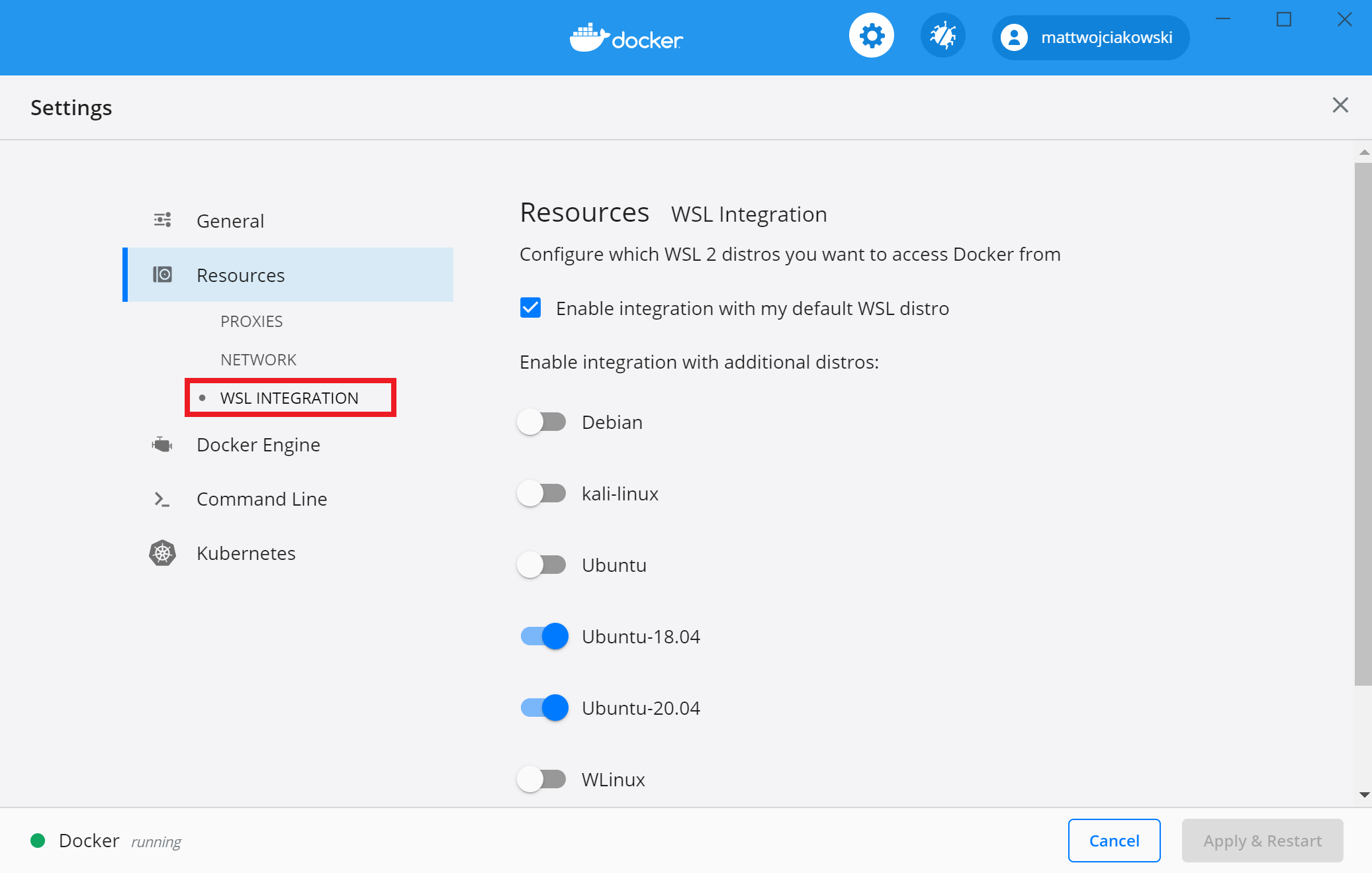
Debian users (and Windows without Docker Desktop)
See Install Docker Engine documentation for more details and other distro steps.
This is also an alternative for Windows users running WSL2.
💡 If using WSL2, be sure to:
- Enable
systemd- see the Windows users section- If installed, disable Docker Desktop integration with WSL2
# 1. uninstall old docker versions
sudo apt-get remove docker docker-engine docker.io containerd runc
# 2. setup docker repository
sudo apt-get update
sudo apt-get -y install ca-certificates curl gnupg lsb-release
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 3. install docker engine
sudo apt-get update
sudo apt-get -y install docker-ce docker-ce-cli containerd.io docker-compose-plugin
# 4. manage docker as non-root user
sudo groupadd docker
sudo usermod -aG docker $USER
# 5. start a new terminal to update group membership
docker run hello-worldA container is a standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another. A container-runtime, which relies on the host kernel, is required to run a container.
Docker is the most popular container-runtime and container-solution, but there are other runtimes like runc, cri-o, containerd, etc, However, the only significant container-solutions today are Docker and Podman
A container image is a lightweight, standalone, executable package of software that includes everything needed to run an application: code, runtime, system tools, system libraries and settings. Container images become containers at runtime.
The Open Container Initiative (OCI) creates open industry standards around container formats and runtimes.
A container registry is a repository, or collection of repositories, used to store and access container images. Container registries are a big player in cloud application development, often as part of GitOps processes.
# run busybox container, see `docker run --help`
docker run busybox
# run in interactive mode
docker run -it busybox
# run in interactive mode and delete container when stopped
docker run -it --rm busybox
# run in detached mode
docker run -d busybox
# list running containers
docker ps
# list all containers
docker ps -a
# start a stopped container, see `docker container start --help`
docker container start $CONTAINER_NAME_OR_ID
# stop a running container, see `docker container stop --help`
docker container stop $CONTAINER_NAME_OR_ID
# restart a running container, see `docker container restart --help`
docker container restart $CONTAINER_NAME_OR_ID
# delete a stopped container, see `docker container rm --help`
docker container rm $CONTAINER_NAME_OR_ID
# exit running container - container is stopped if connected to entrypoint
exit
# exit running container without stopping it
ctrl-p ctrl-qSee possible container statuses to understand more about container states
- Run
docker infoto confirm docker client and server statuses - Run
docker run hello-world
## view kernel details
uname -r # or `cat /proc/version` or `hostnamectl`
# view os version
cat /etc/*-release # or redhat `/etc/redhat-release`, other unix-based os `/etc/os-release`
# view running processes, see `ps --help`
ps aux
# view processes, alternative to `ps`
ls /proc # to find PID, then
cat /proc/$PID/cmdline- Run
ps auxto review running processes on your host device - Run a
busyboxcontainer in interactive modedocker run -it busybox - Review the container kernel details
- Review the running processes in the container and note PID
- Exit the container
- List running containers
- List all containers
- Repeat [2] and exit the container without stopping it
- List running containers
- List all containers
- Delete the containers
lab1.2 solution
# host terminal
ps aux
docker run --name box1 -it busybox
# container terminal
ps aux
uname -r
cat /proc/version
hostnamectl # not found
cat /etc/*-release # not found
busybox | head
exit
# host terminal
docker ps
docker ps -a
docker run --name box2 -it busybox
# container terminal
ctrl+p ctrl+q
# host terminal
docker ps
docker ps -a
docker stop box2
docker rm box1 box2
docker psshowing STATUS ofExited (0)means exit OK, but an Exit STATUS that's not 0 should be investigateddocker logs
CTRL+P, CTRL+Qonly works when running a container in interactive mode, see how to attach/detach containers for more details
# run container with specified name
docker run -d --name webserver httpd
# run command `date` in a new container
docker run busybox date
# get a "dash" shell to a running container, see `docker exec --help`
docker exec -it $CONTAINER_NAME_OR_ID sh
# get a "bash" shell to a running container
docker exec -it $CONTAINER_NAME_OR_ID bash
# view open ports, the commands below only work if installed in the container
netstat -tupln # see `netstat --help` - t tcp, u udp, p program-names, l listening, n port-numbers-only
ss -tulpn # see `ss --help`, alternative to netstat- Run a
nginxcontainer - List running containers (use another terminal if stuck)
- Exit the container
- List running containers
- Run another
nginxcontainer in interactive mode - Review container kernel details
- Review running processes in the container
- Exit container
- Run another
nginxcontainer in detached mode - List running containers
- Connect a shell to the new container interactively
- View open ports in the container
- Exit the container
- List running containers
- Delete all containers
lab1.3 solution
# host terminal
docker run --name webserver1 nginx
# host second terminal
docker ps
# host terminal
ctrl+c
docker ps
docker run --name webserver2 -it --rm nginx bash
# container terminal
cat /etc/*-release
ps aux # not found
ls /proc
ls /proc/1 # list processes running on PID 1
cat /proc/1/$PROCESS_NAME
exit
# host terminal
docker run --name webserver3 -d nginx
docker ps
docker exec -it webserver3 bash
# container terminal
netstat -tupln
ss -tulpn
exit
# host terminal
docker ps
docker stop webserver3
docker rm webserver1 webserver2 webserver3Containers may not always have
bashshell, but will usually have the dash shellsh
- Run a
busyboxcontainer with commandsleep 30as argument, seesleep --help - List running containers (use another terminal if stuck)
- Exit container (note that container will auto exit after 30s)
- Run another
busyboxcontainer in detached mode with commandsleep 300as argument - List running containers
- Connect to the container to execute commands
- Exit container
- List running containers
- Run another
busyboxcontainer in detached mode, no commands - List running containers
- List all containers
- Delete all containers
lab1.4 solution
# host terminal
docker run --name box1 busybox sleep 30
# host second terminal
docker ps
docker stop box1
# host terminal
docker run --name box2 -d busybox sleep 300
docker ps
docker exec -it box2 sh
# container terminal
exit
# host terminal
docker ps
docker run --name box3 -d busybox
docker ps
docker ps -a
docker stop box2
docker rm box1 box2 box3The
Entrypointof a container is the init process and allows the container to run as an executable. Commands passed to a container are passed to the container's entrypoint process.Note that
dockercommands after$IMAGE_NAMEare passed to the container's entrypoint as arguments.
❌docker run -it mysql -e MYSQL_PASSWORD=hellowill pass-e MYSQL_PASSWORD=helloto the container
✔️docker run -it -e MYSQL_PASSWORD=hello mysql
# run container with port, see `docker run --help`
docker run -d -p 8080:80 httpd # visit localhost:8080
# run container with mounted volume
docker run -d -p 8080:80 -v ~/html:/usr/local/apache2/htdocs httpd
# run container with environment variable
docker run -e MONGO_INITDB_ROOT_USERNAME=admin -e MONGO_INITDB_ROOT_PASSWORD=secret mongo
# inspect container, see `docker container inspect --help | docker inspect --help`
docker inspect $CONTAINER_NAME_OR_ID | less # press Q key to quit from less
docker container inspect $CONTAINER_NAME_OR_ID
# format inspect output to view container network information
docker inspect --format="{{.NetworkSettings.IPAddress}}" $CONTAINER_NAME_OR_ID
# format inspect output to view container status information
docker inspect --format="{{.State.Pid}}" $CONTAINER_NAME_OR_ID
# view container logs, see `docker logs --help`
docker logs $CONTAINER_NAME_OR_ID
# remove all unused data (including dangling images)
docker system prune
# remove all unused data (including unused images, dangling or not, and volumes)
docker system prune --all --volumes
# manage images, see `docker image --help`
docker image ls # or `docker images`
docker image inspect $IMAGE_ID
docker image rm $IMAGE_ID
# see `docker --help` for complete resources- Run a
nginxcontainer with namewebserver - Inspect the container (use
| lessto avoid console clutter) and review theStateandNetworkSettingsfields, quit withq - Visit
http://$CONTAINER_IP_ADDRESSin your browser (this may not work depending on your envrionment network settings) - Run another
nginxcontainer with namewebserverand exposed on port 80 - Visit localhost in your browser
- Delete the containers
lab1.5 solution
# host terminal
docker run -d --name webserver nginx
docker inspect webserver | grep -A 13 '"State"' | less
docker inspect webserver | grep -A 50 '"NetworkSettings"' | less
curl http://$(docker inspect webserver --format "{{.NetworkSettings.IPAddress}}") | less
docker stop webserver
docker rm webserver
docker run -d --name webserver -p 80:80 nginx
curl localhost | less
docker ps
docker ps -a
docker stop webserver
docker rm webserverAlways run containers in detached mode to avoid getting stuck in the container
STDOUT
- Create an
html/index.htmlfile with some content - Run any webserver containers on port 8080 and mount the
htmlfolder to the DocumentRoot- option
nginxDocumentRoot -/usr/share/nginx/html - option
httpdDocumentRoot -/usr/local/apache2/htdocs
- option
- Visit localhost:8080
- List running containers
- List all containers
- Delete containers
lab1.6 solution
# host terminal
cd ~
mkdir html
echo "Welcome to Lab 1.6 Container volumes" >> html/index.html
# with nginx
docker run -d --name webserver -v ~/html:/usr/share/nginx/html -p 8080:80 nginx
# with httpd
# docker run -d --name webserver -v ~/html:/usr/local/apache2/htdocs -p 8080:80 httpd
curl localhost:8080
docker ps
docker ps -a
docker stop webserver
docker rm webserver- Run a
mysqlcontainer in detached mode - Connect to the container
- Review the container logs and resolve the output message regarding environment variable
- Confirm issue resolved by connecting to the container
- Exit the container
- List running containers
- List all containers
- List all images
- List all volumes
- Clean up with
docker system prune - Check all resources are deleted, containers, images and volumes.
lab1.7 solution
# host terminal
docker run -d --name db mysql
docker exec -it db bash # error not running
docker logs db
docker rm db
docker run -d --name db -e MYSQL_ROOT_PASSWORD=secret mysql
docker ps
docker ps -a
docker image ls
docker volume ls
docker stop db
docker ps # no containers running
docker system prune --all --volumes
docker image ls
docker volume lsYou don't always have to run a new container, we have had to do this to apply new configuration. You can restart an existing container
docker ps -a, if it meets your needs, withdocker start $CONTAINER
Explore Docker Hub and search for images you've used so far or images/applications you use day-to-day, like databases, environment tools, etc.
Container images are created with instructions that determine the default container behaviour at runtime. A familiarity with specific images/applications may be required to understand their default behaviours
A docker image consist of layers, and each image layer is its own image. An image layer is a change on an image - every command (FROM, RUN, COPY, etc.) in your Dockerfile (aka Containerfile by OCI) causes a change, thus creating a new layer. It is recommended reduce your image layers as best possible, e.g. replace multiple RUN commands with "command chaining" apt update && apt upgrade -y.
A name can be assigned to an image by "tagging" the image. This is often used to identify the image version and/or registry.
# to view image layers/history, see `docker image history --help`
docker image history $IMAGE_ID
# tagging images, see `docker tag --help`
docker tag $IMAGE_NAME $NEW_NAME:$TAG # if tag is omitted, `latest` is used
docker tag nginx nginx:1.1
# tags can also be used to add repository location
docker tag nginx domain.com/nginx:1.1- List all images (if you've just finished lab1.7, run new container to download an image)
- Inspect one of the images with
| lessand review theContainerConfigandConfig - View the image history
- Tag the image with the repository
localhostand a version - List all images
- View the tagged image history
- Delete tagged image by ID
- Lets try that again, delete tagged image by tag
lab2.1 solution
# host terminal
docker image ls
# using nginx image
docker image inspect nginx | grep -A 40 ContainerConfig | less
docker image inspect nginx | grep -A 40 '"Config"' | less
docker image history nginx
docker tag nginx localhost/nginx:1.1
docker image ls
docker image history localhost/nginx:1.1 # tagging isn't a change
docker image rm $IMAGE_ID # error conflict
docker image rm localhost/nginx:1.1 # deleting removes tagAlthough, we can also create an image from a running container using docker commit, we will only focus on using a Dockerfile, which is the recommended method.
Build the below Dockerfile with docker build -t $IMAGE_NAME:$TAG /path/to/Dockerfile/directory, see `docker build --help
# Example Dockerfile
FROM ubuntu
MAINTAINER Piouson
RUN apt-get update && \
apt-get install -y nmap iproute2 && \
apt-get clean
ENTRYPOINT ["/usr/bin/nmap"]
CMD ["-sn", "172.17.0.0/16"] # nmap will scan docker network subnet `172.17.0.0/16` for running containersFROM # specify base image
RUN # execute commands
ENV # specify environment variables used by container
ADD # copy files from project directory to the image
COPY # copy files from local project directory to the image - ADD is recommended
ADD /path/to/local/file /path/to/container/directory # specify commands in shell form - space separated
ADD ["/path/to/local/file", "/path/to/container/directory"] # specify commands in exec form - as array (recommended)
USER # specify username (or UID) for RUN, CMD and ENTRYPOINT commands
ENTRYPOINT ["command"] # specify default command, `/bin/sh -c` is used if not specified - cannot be overwritten, so CMD is recommended for flexibility
CMD ["arg1", "arg2"] # specfify arguments to the ENTRYPOINT - if ENTRYPOINT is not specified, args will be passed to `/bin/sh -c`
EXPOSE $PORT # specify container should listen on port $PORTSee best practices for writing Dockerfile.
# find a package containing an app (debian-based)
apt-file search --regex <filepath-pattern> # requires `apt-file` installation, see `apt-file --help`
apt-file search --regex ".*/sshd$"
# find a package containing an app, if app already installed (debian-based)
dpkg -S /path/to/file/or/pattern # see `dpkg --help`
dpkg -S */$APP_NAME
# find a package containing an app (rpm-based)
dnf provides /path/to/file/or/pattern
dnf provides */sshd- Create a Dockerfile based on the following:
- Base image should be debian-based or rpm-based
- Should include packages containing
psapplication and network utilities likeip,ssandarp - Should run the
nmapprocess as theENTRYPOINTwith arguments-sn 172.17.0.0/16
- Build the Dockerfile with repository
localand version1.0 - List images
- Run separate containers from the image as follows and review behaviour
- do not specify any modes
- in interactive mode with a shell
- in detached mode, then check the logs
- Edit the Dockerfile to run the same process and arguments but not as
ENTRYPOINT - Repeat all three options in [4] and compare the behaviour
- Clean up
lab2.3 solution
# run ubuntu container to find debian-based packages
docker run -it --rm ubuntu
# container terminal
apt update
apt install -y apt-file
apt-file update
apt-file search --regex "bin/ip$"
apt-file search --regex "bin/ss$"
apt-file search --regex "bin/arp$"
# found `iproute2` and `net-tools`
exit# alternatively, run fedora container to find rpm-based packages
docker run -it --rm fedora
# container terminal
dnf provides *bin/ip
dnf provides *bin/ss
dnf provides *bin/arp
# found `iproute` and `net-tools`
exit# host terminal
mkdir test
nano test/Dockerfile# Dockerfile
FROM alpine
RUN apk add --no-cache nmap iproute2 net-tools
ENTRYPOINT ["/usr/bin/nmap"]
CMD ["-sn", "172.17.0.0/16"]# host terminal
docker build -t local/alpine:1.0 ./test
docker run --name alps1 local/alpine:1.0
docker run --name alps2 -it local/alpine:1.0 sh
docker run --name alps3 -d local/alpine:1.0
docker log alps3
nano test/Dockerfile# Dockerfile
FROM alpine
RUN apk add --no-cache nmap iproute2 net-tools
CMD ["/usr/bin/nmap", "-sn", "172.17.0.0/16"]# host terminal
docker build -t local/alpine:1.1 ./test
docker run --name alps4 local/alpine:1.0
docker run --name alps5 -it local/alpine:1.0 sh
# container terminal
exit
# host terminal
docker run --name alps6 -d local/alpine:1.0
docker log alps6
docker stop alps3 alps5 alps6
docker rm alps1 alps2 alps3 alps4 alps5 alps6
docker image rm local/alpine:1.0 local/alpine:1.1In most cases, building an image goes beyond a successful build. Some installed packages require additional steps to run containers successfully
See the official language-specific getting started guides which includes NodeJS, Python, Java and Go examples.
- Bootstrap a frontend/backend application project, your choice of language
- Install all dependencies and test the app works
- Create a Dockerfile to containerise the project
- Build the Dockerfile
- Run a container from the image exposed on port 8080
- Confirm you can access the app on localhost:8080
lab2.4 nodejs solution
# host terminal
npx express-generator --no-view test-app
cd test-app
yarn
yarn start # visit localhost:3000 if OK, ctrl+c to exit
echo node_modules > .dockerignore
nano Dockerfile# Dockerfile
FROM node:alpine
ENV NODE_ENV=production
WORKDIR /app
COPY ["package.json", "yarn.lock", "./"]
RUN yarn --frozen-lockfile --prod
COPY . .
CMD ["node", "bin/www"]
EXPOSE 3000# host terminal
docker build -t local/app:1.0 .
docker run -d --name app -p 8080:3000 local/app:1.0
curl localhost:8080
docker stop app
docker rm app
docker image rm local/app:1.0
cd ..
rm -rf test-appBefore we finally go into Kubernetes, it would be advantageous to have a basic understanding of unix-based systems file permissions and access control.
A user identifier (UID) is a unique number assigned to each user. This is how the system identifies each user. The root user has UID of 0, UID 1-500 are often reserved for system users and UID for new users commonly start at 1000. UIDs are stored in the plain-text /etc/passwd file: each line represents a user account, and has seven fields delimited by colons account:password:UID:GID:GECOS:directory:shell.
A group identifier (GID) is similar to UIDs - used by the system to identify groups. A group consists of several users and the root group has GID of 0. GIDs are stored in the plain-text /etc/group file: each line represents a group, and has four fields delimited by colons group:password:GID:comma-separated-list-of-members. An example of creating and assigning a group was covered in requirements - docker installation for debian users where we created and assigned the docker group.
UIDs and GIDs are used to implement Discretionary Access Control (DAC) in unix-based systems by assigning them to files and processes to denote ownership - left at owner's discretion. This can be seen by running ls -l or ls -ln: the output has seven fields delimited by spaces file_permisions number_of_links user group size date_time_created file_or_folder_name. See unix file permissions for more details.
ls -l in detail

# show current user
whoami
# view my UID and GID, and my group memberships
id
# view the local user database on system
cat /etc/passwd
# output - `account:password:UID:GID:GECOS:directory:shell`
root:x:0:0:root:/root:/bin/bash
piouson:x:1000:1000:,,,:/home/dev:/bin/bash
# view the local group database on system
cat /etc/group
# output - `group:password:GID:comma-separated-list-of-member`
root:x:0:
piouson:x:1000:
docker:x:1001:piouson
# list folder contents and their owner (user/group) names
ls -l
# show ownership by ids, output - `permision number_of_links user group size date_time_created file_or_folder_name`
ls -lnIn the context of permission checks, processes running on unix-based systems are traditionally categorised as:
- privileged processes: effective UID is 0 (root) - bypass all kernel permission checks
- unprivileged processes: effective UID is nonzero - subject to permission checks
Starting with kernel 2.2, Linux further divides traditional root privileges into distinct units known as capabilities as a way to control root user powers. Each root capability can be independently enabled and disabled.
See the overview of Linux capabilities for more details, including a comprehensive list of capabilities.
CAP_SYS_ADMINis an overloaded capability that grants privileges similar to traditional root privileges
By default, Docker containers are unprivileged and root in a docker container uses restricted capabilities
❌docker run --privilegedgives all capabilities to the container, allowing nearly all the same access to the host as processes running on the host
For practical reasons, most containers run as root by default. However, in a security context, this is bad practice:
- it voilates the principle of least privilege
- an attacker might take advantage of an application vulnerability to gain root access to the container
- an attacker might take advantage of a container-runtime, or kernel, vulnerability to gain root access to the host after gaining access to the container
We can control the users containers run with by:
- omitting the
USERcommand in Dockerfile assigns root - specify a user in the
Dockerfilewith theUSERcommand - override the UID at runtime with
docker run --user $UID
# Dockerfile
FROM ubuntu
# create group `piouson`, and create user `piouson` as member of group `piouson`, see `groupadd -h` and `useradd -h`
RUN groupadd piouson && useradd piouson --gid piouson
# specify GID/UID when creating/assigning a group/user
RUN groupadd --gid 1004 piouson && useradd --uid 1004 piouson --gid piouson
# assign user `piouson` for subsequent commands
USER piouson
# create system-group `myapp`, and create system-user `myapp` as member of group `myapp`
RUN groupadd --system myapp && useradd --system --no-log-init myapp --gid myapp
# assign system-user `myapp` for subsequent commands
USER myapp- Display your system's current user
- Display the current user's UID, GID and group memberships
- Run a
ubuntucontainer interactively, and in the container shell:- display the current user
- display the current user's UID, GID and group memberships
- list existing user accounts
- list existing groups
- create a file called
test-fileand display the file ownership info - exit the container
- Run a new
ubuntucontainer interactively with UID 1004, and in the container shell:- display the current user
- display the current user's UID, GID and group memberships
- exit the container
- Create a docker image based on
ubuntuwith a non-root user as default user - Run a container interactively using the image, and in the container shell:
- display the current user
- display the current user's UID, GID and group memberships
- exit the container
- Delete created resources
lab2.5 solution
# host terminal
whoami
id
docker run -it --rm ubuntu
# container terminal
whoami
id
cat /etc/passwd
cat /etc/group
touch test-file
ls -l
ls -ln
exit
# host terminal
docker run -it --rm --user 1004 ubuntu
# container terminal
whoami
id
exit# test/Dockerfile
FROM ubuntu
RUN groupadd --gid 1000 piouson && useradd --uid 1000 piouson --gid 1000
USER piouson# host terminal
docker build -t test-image test/
docker run -it --rm test-image
# container terminal
whoami
id
exit
# host terminal
docker image rm test-imageIf a containerized application can run without privileges, change to a non-root user
It is recommended to explicitly specify GID/UID when creating a group/user
FROM nginx:1.22-alpine
EXPOSE 80Using docker and the Dockerfile above, build an image with tag bootcamp/nginx:v1 and tag ckad/nginx:latest. Once complete, export a tar file of the image to /home/$USER/ckad-tasks/docker/nginx.tar.
Run a container named web-test from the image bootcamp/nginx:v1 accessible on port 2000, and another container named web-test2 from image ckad/nginx:latest accessible on port 2001. Leave both containers running.
What commands would you use to perform the above operations using podman? Specify these commands on separate lines in file /home/$USER/ckad-tasks/docker/podman-commands
hints
hint 1
You can specify multiple tags when building an image docker build -t tag1 -t tag2 /path//to/dockerfile-directory
hint 2
Try to find the command for exporting a docker image with docker image --help
hint 2
Did you run the containers in detached mode?
hint 3
You can export a docker image to a tar file with docker image save -o /path/to/output/file $IMAGE_NAME
hint 4
Did you expose the required ports when creating the containers? You can use docker run -p $HOST_PORT:$CONTAINER_PORT
hint 5
Did you verify the containers running at exposed ports curl localhost:2000 and curl localhost:2001?
hint 6
Docker and Podman have interchangeable commands, therefore, the only change is docker -> podman, For example, docker run -> podman run, docker build -> podman build, etc.
K8s is an open-source system for automating deployment, scaling and containerized applications management, currently owned by the Cloud Native Computing Foundation (CNCF).
K8s release cycle is 3 months and deprecated features are supported for a minimum of 2 release cycles (6 months).
You can watch kubernetes in 1 minute for a quick overview
When you've got more time, watch/listen to Kubernetes: The Documentary (PART 1 & PART 2)
A local lab setup is covered in chapter 4 with minikube
Skip this lab if you do not currently have a Google Cloud account with Billing enabled
- Signup and Login to console.cloud.google.com
- Use the "Cluster setup guide" to create "My first cluster"
- Connect to the cluster using the "Cloud Shell"
- View existing Kubernetes resources by running
kubectl get all
Entities in Kubernetes are recorded in the Kubernetes system as Objects, and they represent the state of your cluster. Kubernetes objects can describe:
- what containerized applications are running (and on which nodes)
- resources available to those applications
- policies around applications behaviour - restarts, upgrades, fault-tolerance, etc
Some common Kubernetes objects include:
- Deployment: represents the application and provides services
- ReplicaSet: manages scalability - array of pods
- Pods: manages containers (note that one container per pod is the standard)
Kubernetes architecture

Pods architecture

# help
kubectl --help | less
# view available resources
kubectl get all, see `kubectl get --help`
# create a deployment, see `kubectl create deploy -h`
kubectl create deploy myapp --image=nginx
# create a deployment with six replicas
kubectl create deploy myapp --image=nginx --replicas=6
# view complete list of supported API resources, shows api-versions and their resource types
kubectl api-resources
# view api-versions only
kubectl api-versions
# delete a deployment, see `kubectl delete --help`
kubectl delete deploy myappThis lab is repeated in chapter 4 with minikube
Skip this lab if you do not currently have a Google Cloud account with Billing enabled
- Create an
nginxapplication with three replicas - View available resources
- Delete a pod create
- View available resources, how many pods left, can you find the deleted pod?
- List supported API resources
- Delete the application
- view available resource
- Delete the Kubernetes service
- view available resources
- If nothing found, allow 5s and try [9] again
lab3.2 solution
kubectl create deploy webserver --image=nginx --replicas=3
kubectl get all
kubectl delete pod $POD_NAME
kubectl get all # new pod auto created to replace deleted
kubectl api-resources
kubectl delete deploy webserver
kubectl get all
kubectl delete svc kubernetes
kubectl get all # new kubernetes service is auto created to replace deletedRemember to delete Google cloud cluster to avoid charges if you wish to use a local environment detailed in the next chapter
# check kubernetes version
kubectl version
# list kubernetes context (available kubernetes clusters - docker-desktop, minikube, etc)
kubectl config get-contexts
# switch kubernetes context
kubectl config use-context docker-desktopEnable Kubernetes in Docker Desktop settings, then apply and restart

See Docker's Deploy on Kubernetes for more details
Note that using Docker Desktop will have network limitations when exposing your applications publicly, see alternative Minikube option below
Minikube is the recommended Kubernetes solution for this course on a local lab environment. See the official minikube installation docs.
# 1. install minikube
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-darwin-amd64
sudo install minikube-darwin-amd64 /usr/local/bin/minikube
rm minikube-darwin-amd64
# 2. start a minikube cluster
minikube start# 1. install minikube
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
chmod +x ./minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
rm minikube-linux-amd64
# 2. install minikube prereqs - conntrack
sudo apt install conntrack
sudo sysctl fs.protected_regular=0
# 3. start a minikube cluster with the latest kubernetes version and default docker driver
minikube start
# if [3] doesn't work, e.g. vpn issue, etc, try `--driver=none`
# sudo minikube start --driver=none
# 4. change the owner of the .kube and .minikube directories
sudo chown -R $USER $HOME/.kube $HOME/.minikube# show current status, see `minikube --help`
minikube status
# open K8s dashboard in local browser
minikube dashboard
# start a minikube cluster with latest k8s version and default driver, see `minikube --help`
minikube start
# start minikube with a specified driver and specified kubernetes version
minikube start --driver=docker --kubernetes-version=1.23.9
# show current IP address
minikube ip
# show current version
minikube version
# connect to minikube cluster
minikube ssh
# list addons
minikube addons list
# enable addons
minikube addons enable $ADDON_NAME
# stop running minikube cluster
minikube stop
# delete stopped minikube cluster
minikube delete- Confirm minikube running
minikube status - Create
kubectlalias in.bashrcprintf " # minikube kubectl alias kubectl='minikube kubectl --' " >> ~/.bashrc exec bash
- Start using the alias
kubectl version kubectl get all
- Enable kubectl autocompletion, see
kubectl completion --helpecho "source <(kubectl completion bash)" >> ~/.bashrc # macos replace bash with zsh exec bash
- The default
kubectl edittext editor isvi. To change this:export KUBE_EDITOR="nano" # use nano export KUBE_EDITOR="vim" # use vim
- Open the Kubernetes dashboard with
minikube dashboard - Use the Kubernetes Dashboard to deploy a webserver with three replicas
- visit url provided in browser
- click on top right plus "+" icon
- select
Create from form - enter App name:
app, Container image:nginx, Number of pods:3 - click
Deploy
- Return to the terminal and delete created resources
ctrl+c # to terminate dashboard kubectl get all kubectl delete deploy app - List Kubernetes clusters with
kubectl config get-contexts - If you have Kubernetes cluster from both Minikube and Docker Desktop, you can switch between them:
- Set Docker Desktop cluster as current cluster:
kubectl config set-context docker-desktop - Set Minikube cluster as current cluster:
kubectl config set-context minikube
- Run an
nginxPod - View resources
- Delete the Pod
- View resources
- Repeat Lab 3.2 in Minikube
lab4.2 solution
kubectl run webserver --image=nginx
kubectl get all
kubectl delete pod webserver
kubectl get all # pod gone
# see `lab3.2 solution` for remaining stepsPods started without a deployment are called Naked Pods - these are not managed by a replicaset, therefore, are not rescheduled on failure, not eligible for rolling updates, cannot be scaled, cannot be replaced automatically.
Although, Naked Pods are not recommended in live environments, they are crucial for learning how to manage Pods, which is a big part of CKAD.
Pods are the smallest deployable units of computing that you can create and manage in Kubernetes.
# run a pod, see `kubectl run --help`
kubectl run $POD_NAME $IMAGE_NAME
# run a nginx pod with custom args, args are passed to the pod's container's `ENTRYPOINT`
kubectl run mypod --image=nginx -- <arg1> <arg2> ... <argN>
# run a command in an nginx pod
kubectl run mypod --image=nginx --command -- <command>
# run a busybox pod interactively and delete after task completion
kubectl run -it mypod --image=busybox --rm --restart=Never -- date
# to specify the port exposed by the image is 8080
kubectl run mypod --port=8080 --image=image-that-uses-port-8080
# connect a shell to a running pod `mypod`
kubectl exec mypod -it -- sh
# list pods, see `kubectl get --help`
kubectl get pods # using `pod` or `pods` will work
# only show resource names when listing pods
kubectl get pods -o name | less
# display full details of pod in YAML form
kubectl get pods $POD_NAME -o yaml | less
# show details of pod in readable form, see `kubectl describe --help`
kubectl describe pods $POD_NAME | less
# view the pod spec
kubectl explain pod.spec | lessWith
kubectl, everything after the--flag is passed to the Pod
💡-- <args>corresponds to DockerfileCMDwhile--command -- <args>corresponds toENTRYPOINT
See answer tokubectl run --command vs -- argumentsfor more details
- Create a Pod with
nginx:alpineimage and confirm creation - Review full details of the Pod in YAML form
- Display details of the Pod in readable form and review the Node, IP, container start date/time and Events
- List pods but only show resource names
- Connect a shell to the Pod and confirm an application is exposed
- By default, Nginx exposes applications on port 80
- confirm exposed ports
- Delete the Pod
- Review the Pod spec
- Have a look at the Kubernetes API to determine when pods were introduced
Not all images expose their applications on port 80. Kubernetes doesn't have a native way to check ports exposed on running container, however, you can connect a shell to a Pod with
kubectl execand try one ofnetstat -tulpnorss -tulpnin the container, if installed, to show open ports.
lab5.1 solution
# host terminal
kubectl run mypod --image=nginx:alpine
kubectl get pods
kubectl describe pods mypod | less
kubectl get pods -o name
kubectl exec -it mypod -- sh
# container terminal
curl localhost # or curl localhost:80, can omit since 80 is the default
netstat -tulpn
ss -tulpn
exit
# host terminal
kubectl delete pods mypod
kubectl explain pod.spec
kubectl api-resources # pods were introduced in v1 - the first version of kubernetesExample of a Pod manifest file with a busybox image and mounted empty-directory volume.
apiVersion: v1 # api version
kind: Pod # type of resource, pod, deployment, configmap, etc
metadata:
name: box # metadata information, including labels, namespace, etc
spec:
volumes: # create an empty-directory volume
- name: varlog
emptyDir: {}
containers:
- name: box
image: busybox:1.28
volumeMounts: # mount created volume
- name: varlog
mountPath: /var/logVolumes are covered in more detail in Chapter 10 - Storage. For now it will suffice to know how to create and mount an empty-directory volume
# view description of a Kubernetes Object with `kubectl explain <object>[.field]`, see `kubectl explain --help`
kubectl explain pod
kubectl explain pod.metadata # or `pod.spec`, `pod.status` etc
# include nested fields with `--recursive`
kubectl explain --recursive pod.spec | less
# perform actions on a resource with a YAML file
kubectl {create|apply|replace|delete} -f pod.yaml
# generate YAML file of a specific command with `--dry-run`
kubectl run mynginx --image=nginx -o yaml --dry-run=client > pod.yamlObject fields are case sensitive, always generate manifest files to avoid typos
kubectl applycreates a new resource, or updates existing if previously created bykubectl apply
Always create single container Pods! However, some special scenarios require a multi-container Pod pattern:
- To initialise primary container (Init Container)
- To enhance primary container, e.g. for logging, monitoring, etc. (Sidecar Container)
- To prevent direct access to primary container, e.g. proxy (Ambassador Container)
- To match the traffic/data pattern in other applications in the cluster (Adapter Container)
In the official k8s docs, you will often find example code with a URL, e.g.
pods/commands.yaml. The file can be downloaded by appendinghttps://k8s.io/examplesto the URL, thus:https://k8s.io/examples/pods/commands.yaml
# download file `pods/commands.yaml`
wget https://k8s.io/examples/pods/commands.yaml
# save downloaded file with a new name `comm.yaml`
wget https://k8s.io/examples/pods/commands.yaml -O comm.yaml
# hide output while downloading
wget -q https://k8s.io/examples/pods/commands.yaml
# view contents of a downloaded file without saving
wget -O- https://k8s.io/examples/pods/commands.yaml
# view contents quietly without saving
wget -qO- https://k8s.io/examples/pods/commands.yaml- Generate a YAML file of a
busyboxPod that runs the commandsleep 60, see create Pod with command and args docs - Apply the YAML file.
- List created resources
- View details of the Pod
- Delete the Pod
lab5.2 solution
kubectl run mypod --image=busybox --dry-run=client -o yaml --command -- sleep 60 > lab5-2.yaml
kubectl apply -f lab5-2.yaml
kubectl get pods
kubectl describe pods mypod | less
kubectl delete -f lab5-2.yamlSome images, like busybox, do not remain in running state by default. An extra command is required, e.g.
sleep 60, to keep containers using these images in running state for as long as you need. In the CKAD exam, make sure your Pods remain in running states unless stated otherwise
Note that the main container will only be started after the init container enters STATUS=completed
# view logs of pod `mypod`
kubectl logs mypod
# view logs of specific container `mypod-container-1` in pod `mypod`
kubectl logs mypod -c mypod-container-1- Create a Pod that logs
App is running!to STDOUT- use
busybox:1.28image - the application should
Neverrestart - the application should use a Init Container to wait for 60secs before starting
- the Init Container should log
App is initialising...to STDOUT - see init container docs.
- use
- List created resources and note Pod
STATUS - View the logs of the main container
- View the logs of the init container
- View more details of the Pod and note the
Stateof both containers. - List created resources and confirm Pod
STATUS - Delete Pod
lab5.3 solution
# partially generate pod manifest
kubectl run myapp --image=busybox:1.28 --restart=Never --dry-run=client -o yaml --command -- sh -c "echo App is running!" > lab5-3.yaml# edit lab5-3.yaml to add init container spec
apiVersion: v1
kind: Pod
metadata:
labels:
run: myapp
name: myapp
spec:
containers:
- name: myapp
image: busybox:1.28
command: ["sh", "-c", "echo App is running!"]
initContainers:
- name: myapp-init
image: busybox:1.28
command: ["sh", "-c", 'echo "App is initialising..." && sleep 60']
restartPolicy: Neverkubectl apply -f lab5-3.yaml
kubectl get pods
kubectl logs myapp # not created until after 60secs
kubectl logs myapp -c myapp-init
kubectl describe -f lab5-3.yaml | less
kubectl get pods
kubectl delete -f lab5-3.yaml- Create a Pod with 2 containers and a volumne shared by both containers, see multi-container docs.
- List created resources
- View details of the Pod
- Delete the Pod
lab5.4 solution
# lab5-4.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp
spec:
containers:
- name: myapp-1
image: busybox:1.28
volumeMounts:
- name: logs
mountPath: /var/log
- name: myapp-2
image: busybox:1.28
volumeMounts:
- name: logs
mountPath: /var/log
volumes:
- name: logs
emptyDir: {}kubectl apply -f lab5-4.yaml
kubectl get pods
kubectl describe pods myapp | less
kubectl logs myapp -c myapp-1
kubectl logs myapp -c myapp-2
kubectl delete -f lab5-4.yamlAlways create single container Pods!
Remember you can prepend
https://k8s.io/examples/to any example manifest names from the official docs for direct download of the YAML file
- Create a
busyboxPod that logsdateto a file every second- expose the logs with a sidecar container's STDOUT to prevent direct access to the main application
- see example sidecar container manifest
https://k8s.io/examples/admin/logging/two-files-counter-pod-streaming-sidecar.yaml
- List created resources
- View details of the Pod
- View the logs of the main container
- View the logs of the sidecar container
- Delete created resources
lab5.5 solution
# lab5-5.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp
spec:
containers:
- name: myapp
image: busybox:1.28
args:
- /bin/sh
- -c
- >
while true;
do
echo $(date) >> /var/log/date.log;
sleep 1;
done
volumeMounts:
- name: logs
mountPath: /var/log
- name: myapp-logs
image: busybox:1.28
args: [/bin/sh, -c, "tail -F /var/log/date.log"]
volumeMounts:
- name: logs
mountPath: /var/log
volumes:
- name: logs
emptyDir: {}kubectl apply -f lab5-5.yaml
kubectl get pods
kubectl describe pods myapp | less
kubectl logs myapp -c myapp
kubectl logs myapp -c myapp-logs
kubectl delete -f lab5-5.yamlNamespaces are a way to divide/isolate cluster resources between multiple users. Names of resources need to be unique within a Namespace, but not across namespaces.
Not all Kubernetes resources are in a Namespace and Namespace-based scoping is only applicable for namespaced objects.
Namespaces should be used sensibly, you can read more about understanding the motivation for using namespaces
# create namespace called `myns`, see `kubectl create namespace -h`
kubectl create namespace myns
# run a pod in the `myns` namespace with `-n myns`
kubectl run mypod --image=imageName -n myns
# view pods in the `myns` namespaces
kubectl get pods -n myns
# list pods in all namespaces with `--all-namespaces` or `-A`
kubectl get pods --all-namespaces
# list all resources in all namespaces
kubectl get all --all-namespaces
# view the current namespace in use for commands
kubectl config view --minify | grep namespace:
# set `myns` namespace to be the namespace used for subsequent commands
kubectl config set-context --current --namespace=myns
# view kubernetes api resources in a namespace
kubectl api-resources --namespaced=true
# view kubernetes api resources not in a namespace
kubectl api-resources --namespaced=false
# view the namespace object
kubectl explain namespace | less
# view the namespace object recursively
kubectl explain namespace --recursive | lessYou can also follow the admin guide doc for namespaces
Remember you can connect a shell to a Pod with
kubectl execand try one ofnetstat -tulpnorss -tulpnin the container, if installed, to show open ports.
- Create a Namespace
myns - Create a webserver Pod in the
mynsNamespace - Review created resources and confirm
mynsNamespace is assigned to the Pod - Delete resources created
- Review the
NAMESPACEDcolumn of the Kubernetes API resources - Review the Namespace object and the Namespace spec
lab5.6 solution
kubectl create ns myns --dry-run=client -o yaml > lab5-6.yaml
echo --- >> lab5-6.yaml
kubectl run mypod --image=httpd:alpine -n myns --dry-run=client -o yaml >> lab5-6.yaml
kubectl apply -f lab5-6.yaml
kubectl get pods
kubectl describe -f lab5-6.yaml | less
kubectl delete -f lab5-6.yaml
kubectl api-resources | less
kubectl explain namespace | less
kubectl explain namespace --recursive | less
kubectl explain namespace.spec | lessRemember that namespaced resources are not visible by default unless the namespace is specified
💡kubectl get pods- only shows resources in thedefaultnamespace
💡kubectl get pods -n mynamespace- shows resources in themynamespacenamespace
Imagine a student in the CKAD Bootcamp training reached out to you for assistance to finish their homework. Their task was to create a webserver with a sidecar container for logging in the cow namespace. Find this Pod, which could be located in one of the Namespaces ape, cow or fox, and ensure it is configured as required.
At the end of your task, copy the log file used by the logging container to directory /home/$USER/ckad-tasks/pods/
- Command to setup environment:
printf '\nlab: environment setup in progress...\n'; echo '{"apiVersion":"v1","items":[{"kind":"Namespace","apiVersion":"v1","metadata":{"name":"fox"}},{"kind":"Namespace","apiVersion":"v1","metadata":{"name":"ape"}},{"kind":"Namespace","apiVersion":"v1","metadata":{"name":"cow"}},{"apiVersion":"v1","kind":"Pod","metadata":{"labels":{"run":"box"},"name":"box","namespace":"ape"},"spec":{"containers":[{"args":["sleep","3600"],"image":"busybox","name":"box"}],"dnsPolicy":"ClusterFirst","restartPolicy":"Always"}},{"apiVersion":"v1","kind":"Pod","metadata":{"labels":{"run":"for-testing"},"name":"for-testing","namespace":"fox"},"spec":{"containers":[{"args":["sleep","3600"],"image":"busybox","name":"for-testing"}],"dnsPolicy":"ClusterFirst","restartPolicy":"Always"}},{"apiVersion":"v1","kind":"Pod","metadata":{"labels":{"run":"webserver"},"name":"webserver","namespace":"fox"},"spec":{"containers":[{"name":"server","image":"ngnx:1.20-alpine","volumeMounts":[{"name":"serverlog","mountPath":"/usr/share/nginx/html"}]},{"name":"logger","image":"busybox:1.28","args":["/bin/sh","-c","while true; do echo $(date) >> /usr/share/nginx/html/1.log;\n sleep 30;\ndone\n"],"volumeMounts":[{"name":"serverlog","mountPath":"/usr/share/nginx/html"}]}],"volumes":[{"name":"serverlog","emptyDir":{}}]}}],"metadata":{"resourceVersion":""},"kind":"List"}' | kubectl apply -f - >/dev/null; echo 'lab: environment setup complete!' - Command to destroy environment:
kubectl delete ns ape cow fox
hints
hint 1
Did you search for Pods in specific namespaces, e.g. kubectl get pod -n ape?
hint 2
Did you review the Pod error message under STATUS column of kubectl get po command? You can reveal more information with kubectl get -owide.
hint 3
Did you review more details of the Pod, especially details under Containers section of kubectl describe po command?
hint 4
Is the webserver Pod up and running in the cow Namespace? Remember this is the requirement, so migrate the Pod if not in correct Namespace. No other resources should be migrated.
hint 5
Did you delete the webserver Pod in wrong Namespace fox?
hint 6
You can use kubectl cp --help to copy files and directories to and from containers. See kubectl cheatsheet for more details.
In the rat Namespace (create if required), create a Pod named webapp that runs nginx:1.22-alpine image and has env-var NGINX_PORT=3005 which determines the port exposed by the container. The Pod container should be named web and should mount an emptyDir volume to /etc/nginx/templates.
The Pod should have an Init Container named web-init, running busybox:1.28 image, that creates a file in the same emptyDir volume, mounted to /tempdir, with below command:
echo -e "server {\n\tlisten\t\${NGINX_PORT};\n\n\tlocation / {\n\t\troot\t/usr/share/nginx/html;\n\t}\n}" > /tempdir/default.conf.templatehints
hint 1
Did you create the Pod in Namespace rat?
hint 2
Did you set environment variable NGINX_PORT=3005 in container web? See kubectl run --help for how to set an environment variable in a container.
hint 3
Did you set Pod's containerPort parameter to be same value as env-var NGINX_PORT? Since the env-var NGINX_PORT determines the container port, you must change set the containerPort parameter to this value. See kubectl run --help for how to set port exposed by container.
hint 4
Did you specify an emptyDir volume and mounted it to /etc/nginx/templates in Pod container web? See example pod manifest.
hint 5
Did you create web-init as an Init Container under pod.spec.initContainers? See lab 5.3 - init containers.
hint 6
Did you run appropriate command in Init Container? You can use list-form, or array-form with single quotes.
# list form
command:
- /bin/sh
- -c
- echo -e "..." > /temp...
# array form with single quotes
command: ["/bin/sh", "-c", "echo -e '...' > /temp..."]hint 7
Did you specify an emptyDir volume, mounted to /tempdir in Init Container web-init? See example pod manifest.
hint 8
Did you confirm that a webpage is being served by container web on specified port? Connect a shell to the container and run curl localhost:3005.
Whilst a Pod is running, the kubelet is able to restart containers to handle some faults. Within a Pod, Kubernetes tracks different container states and determines what action to take to make the Pod healthy again.
Kubernetes tracks the phase of a Pod
- Pending - Pod starts here and waits to be scheduled, image download, etc
- Running - at least one container running
- Succeeded - all containers terminated successfully
- Failed - all containers have terminated, at least one terminated in failure
- Unknown - pod state cannot be obtained, either node communication breakdown or other
Kubernetes also tracks the state of containers running in a Pod
- Waiting - startup not complete
- Running - executing without issues
- Terminated - ran into issues whilst executing
The first step in debugging a Pod is taking a look at it. Check the current state of the Pod and recent events with:
kubectl describe pods $POD_NAMEWhen running commands locally in a Terminal, you can immediately see the output STDOUT. However, applications running in a cloud environment have their own way of showing their outputs - for Kubernetes, you can view a Pod STDOUT with:
kubectl logs $POD_NAME
# to view only events
kubectl get events --field-selector=involvedObject.name=$POD_NAMEA Pod
STATUS=CrashLoopBackOffmeans the Pod is in a cool off period following container failure. The container will be restarted after cool off
You will usually find more clues in the logs when a Pod shows a none-zeroExit Code
See the official debug running pods tutorial for more details
- Create a Pod with mysql image and confirm Pod state
- Get detailed information on the Pod and review Events (any multiple attempts?), 'State', 'Last State' and their Exit codes.
- Note that Pod
STATESmight continue to change for containers in error due to defaultrestartPolicy=Always
- Note that Pod
- Review cluster logs for the Pod
- Apply relevant fixes until you have a mysql Pod in 'Running' state
- Delete created resources
lab6.1 solution
kubectl run mydb --image=mysql --dry-run=client -o yaml > lab6-1.yaml
kubectl apply -f lab6-1.yaml
kubectl get pods
kubectl describe -f lab6-1.yaml | less
kubectl get pods --watch # watch pods for changes
ctrl+c
kubectl delete -f lab6-1.yaml
kubectl run mydb --image=mysql --env="MYSQL_ROOT_PASSWORD=secret" --dry-run=client -o yaml > lab6-1.yaml
kubectl apply -f lab6-1.yaml
kubectl get pods
kubectl describe -f lab6-1.yaml | less
kubectl delete -f lab6-1.yamlEphemeral containers are useful for interactive troubleshooting when kubectl exec is insufficient because a container has crashed or a container image doesn't include debugging utilities, such as with distroless images.
# create a `mysql` Pod called `mypod` (assume the pod fails to start)
kubectl run mydb --image=mysql
# add ephemeral container to Pod `mypod`
kubectl debug -it ephemeral-pod --image=busybox:1.28 --target=ephemeral-demoThe
EphemeralContainersfeature must be enabled in the cluster and the--targetparameter must be supported by the container runtime
When not supported, the Ephemeral Container may not be started, or started without revealing processes
Port forwarding in Kubernetes should only be used for testing purposes.
# get a list of pods with extra information, including IP Address
kubectl get pods -o wide
# view port forwarding help
kubectl port-forward --help
# forward host port 8080 to container `mypod` port 80, requires `ctrl+c` to terminate
kubectl port-forward mypod 8080:80When a program runs in a unix-based environment, it starts a process. A foreground process prevents further execution of commands, e.g.
sleep
# run any foreground command in the background by adding an ampersand &
sleep 60 &
# view running background processes and their ids
jobs
# bring a background process to the foreground
fg $ID
# run the `kubectl port-forward` command in the background
kubectl port-forward mypod 8080:80 &- Create a webserver Pod
- List created resources and determine Pod IP address
- Access the webserver with the IP address (you can use
curl) - Use port forwarding to access the webserver on http://localhost:5000
- Terminate port forwarding and delete created resources
lab6.2 solution
kubectl run webserver --image=httpd
kubectl get pods -o wide
curl $POD_IP_ADDRESS
kubectl port-forward webserver 5000:80 &
curl localhost:5000
fg 1
ctrl+c
kubectl delete pods webserverThis section requires a basic understanding of unix-based systems file permissions and access control covered in ch2 - container access control
A security context defines privilege and access control settings for a Pod or Container. Security context can be controlled at Pod-level pod.spec.securityContext as well as at container-level pod.spec.containers.securityContext. A detailed explanation of security context is provided in the linked docs, however, for CKAD, we will only focus on the following:
runAsGroup: $GID- specifies the GID of logged-in user in pod containers (pod and container level)runAsNonRoot: $boolean- specifies whether the containers run as a non-root user at image level - containers will not start if set totruewhile image uses root (pod and container)runAsUser: $UID- specifies the UID of logged-in user in pod containers (pod and container)fsGroup: $GID- specifies additional GID used for filesystem (mounted volumes) in pod containers (pod level)privileged: $boolean- controls whether containers will run as privileged or unprivileged (container level)allowPrivilegeEscalation: $boolean- controls whether a process can gain more privileges than its parent process - alwaystruewhen the container is run as privileged, or hasCAP_SYS_ADMIN(container level)readOnlyRootFilesystem: $boolean- controls whether the container has a read-only root filesystem (container level)
# show pod-level security context options
kubectl explain pod.spec.securityContext | less
# show container-level security context options
kubectl explain pod.spec.containers.securityContext | less
# view pod details for `mypod`
kubectl get pods mypod -o yamlUsing the official docs manifest example pods/security/security-context.yaml as base to:
- Use the official manifest example
pods/security/security-context.yamlas base to create a Pod manifest with these security context options:- all containers have a logged-in user of
UID: 1010, GID: 1020 - all containers set to run as non-root user
- mounted volumes for all containers in the pod have group
GID: 1110 - escalating to root privileges is disabled (more on privilege escalation)
- all containers have a logged-in user of
- Apply the manifest file and review details of created pod
- Review pod details and confirm security context applied at pod-level and container-level
- Connect an interactive shell to a container in the pod and confirm the following:
- current user
- group membership of current user
- ownership of entrypoint process
- ownership of the mounted volume
/data/demo - create a new file
/data/demo/new-fileand confirm file ownership - escalate to a shell with root privileges
sudo su
- Edit the pod manifest file to the following:
- do not set logged-in user UID/GID
- do not set root privilege escalation
- all containers set to run as non-root user
- Create a new pod with updated manifest
- Review pod details and confirm events and behaviour
- what were your findings?
- Delete created resources
- Explore the Pod spec and compare the
securityContextoptions available at pod-level vs container-level
lab6.3 solution
# host terminal
kubectl explain pod.spec.securityContext | less
kubectl explain pod.spec.containers.securityContext | less
wget -qO lab6-3.yaml https://k8s.io/examples/pods/security/security-context.yaml
nano lab6-3.yaml# lab6-3.yaml
spec:
securityContext:
runAsUser: 1010
runAsGroup: 1020
fsGroup: 1110
containers:
- name: sec-ctx-demo
securityContext:
allowPrivilegeEscalation: false
# etc# host terminal
kubectl apply -f lab6-3.yaml
kubectl describe pods security-context-demo | less
kubectl get pods security-context-demo -o yaml | grep -A 4 -E "spec:|securityContext:" | less
kubectl exec -it security-context-demo -- sh
# container terminal
whoami
id # uid=1010 gid=1020 groups=1110
ps
ls -l /data # root 1110
touch /data/demo/new-file
ls -l /data/demo # 1010 1110
sudo su # sudo not found - an attacker might try other ways to gain root privileges
exit
# host terminal
nano lab6-3.yaml# lab6-3.yaml
spec:
securityContext:
runAsNonRoot: true
fsGroup: 1110
containers:
- name: sec-ctx-demo
securityContext:
allowPrivilegeEscalation: false
# etc# host terminal
kubectl delete -f lab6-3.yaml
kubectl apply -f lab6-3.yaml
kubectl get pods security-context-demo
kubectl describe pods security-context-demo | less
# found error creating container - avoid conflicting rules, enforcing non-root user `runAsNonRoot: true` requires a non-root user specified `runAsUser: $UID`A Job creates one or more Pods and will continue to retry execution of the Pods until a specified number of them successfully terminate - a Completed status. Deleting a Job will clean up the Pods it created. Suspending a Job will delete its active Pods until the Job is resumed again. The default restartPolicy for Pods is Always, while the default restartPolicy for Jobs is Never.
A Job type is determined by the values of the completions and parallelism fields - you can view all Job fields with kubectl explain job.spec:
completions=1; parallelism=1- one pod started per job, unless failurecompletions=1; parallelism=x- multiple pods started, until one successfully completes taskcompletions=n; parallelism=x- multiple pods started, untilnsuccessful task completionsttlSecondsAfterFinished=x- automatically delete a job afterxseconds
# view resource types you can create in kubernetes
kubectl create -h
# create a job `myjob` that runs `date` command, see `kubectl create job -h`
kubectl create job myjob --image=busybox -- date
# generate a job manifest
kubectl create job myjob --image=busybox --dry-run=client -o yaml -- date
# list jobs
kubectl get jobs
# list jobs and pods
kubectl get jobs,pods
# view the manifest of an existing job `myjob`
kubectl get jobs myjob -o yaml
# view details of a job `myjob`
kubectl describe job myjob
# view the job spec
kubectl explain job.spec | less- Create a Job
myjob1with a suitable image that runs the commandecho Lab 6.4. Jobs! - List jobs and pods
- Review the details of
myjob1 - Review the yaml form of
myjob1 - Create another Job
myjob2with a suitable image that runs the commanddate - List jobs and pods
- Repeat [4] using a manifest file with name
myjob3 - List jobs and pods
- Delete all jobs created
- List jobs and pods
- Edit the manifest file and add the following:
- 5 pods successfully run the command
- pods are auto deleted after 30secs
- Apply the new manifest and:
- confirm the new changes work as expected
- note the total number of resources created
- note the behaviour after 30secs
- Delete created resources
- Review the Job spec to understand fields related to working with jobs
- Review the Kubernetes API Resources to determine when jobs was introduced
lab6.4 solution
kubectl explain job.spec | less
kubectl create job myjob1 --image=busybox -- echo Lab 6.4. Jobs!
kubectl get jobs,pods
kubectl describe job myjob1
kubectl get jobs myjob1 -o yaml
kubectl create job myjob2 --image=busybox -- date
kubectl get jobs,pods
kubectl create job myjob3 --image=busybox --dry-run=client -o yaml -- date >> lab6-4.yaml
kubectl apply -f lab6-4.yaml
kubectl get jobs,pods # so many pods!
kubectl delete jobs myjob1 myjob2 myjob3
kubectl get jobs,pods # pods auto deleted!
nano lab6-4.yaml# lab6-4.yaml
kind: Job
spec:
template:
spec:
completions: 5
ttlSecondsAfterFinished: 30
containers:
# etckubectl apply -f lab6-4.yaml
kubectl get jobs,pods
kubectl get pods --watch # watch pods for 30secsA CronJob creates Jobs on a repeating schedule. It runs a job periodically on a given schedule, written in Cron format. This isn't very different from the Linux/Unix crontab (cron table).
Note that 1 minute is the lowest you can set a crontab schedule. Anything lower will require additional logic or hack If you are not familiar with Linux/Unix crontab, have a look at this beginner guide or this beginner tutorial
# cronjob time syntax: * * * * * - minute hour day_of_month month day_of_week
kubectl create cronjob -h
# create a cronjob `cj` that run a job every minute
kubectl create cronjob cj --image=busybox --schedule="* * * * *" -- date
# view the cronjob spec
kubectl explain cronjob.spec | less
# view the job spec of cronjobs
kubectl explain cronjobs.spec.jobTemplate.spec
kubectl api-resources # jobs was introduced in batch/v1- Create a job with a suitable image that runs the
datecommand every minute - Review details of the created CronJob
- Review the YAML form of the created CronJob
- List created resources and compare results before and after 1 minute
- Delete created resources
- Review the CronJob spec to understand fields related to working with cronjobs
- Review the Job spec of a CronJob and compare this to a standard Job spec
- Review the Kubernetes API Resources to determine when jobs was introduced
lab6.5 solution
kubectl explain cronjob.spec | less
kubectl explain cronjob.spec.jobTemplate.spec | less
kubectl create cronjob mycj --image=busybox --schedule="* * * * *" -- date
kubectl describe cj mycj | less
kubectl get cj mycj -o yaml | less
kubectl get all
kubectl get pods --watch # watch pods for 60s to see changes
kubectl delete cj mycj # deletes associated jobs and pods!
kubectl api-resources # cronjobs was introduced in batch/v1All CronJob
scheduletimes are based on the timezone of the kube-controller-manager
Since a CronJob runs a Job periodically, the Job spec auto delete featurettlSecondsAfterFinishedis quite handy
By default, Linux will not limit resources available to processes - containers are processes running on Linux. However, when creating Pod, you can optionally specify how much of each resource a container needs. The most common resources to specify are CPU and RAM, but there are others.
Request is the initial/minimum amount of a particular resource provided to a container, while Limit is the maximum amount of the resource available - the container cannot exceed this value. See resource management for pods and containers for more details.
A Pod resource request/limit is the sum of the resource requests/limits of containers in the Pod A Pod remains in "Pending" status until a Node with sufficient resources becomes available
Note that Requests and Limits management at the Namespace-level is not for CKAD but covered in CKA
spec.containers[].resources.limits.cpu- in cores and millicores, 500m = 0.5 CPUspec.containers[].resources.limits.memory- Ki (1024) / k (1000) | Mi/M | Gi/G | Ti/T | Pi/P | Ei/Espec.containers[].resources.limits.hugepages-<size>spec.containers[].resources.requests.cpuspec.containers[].resources.requests.memoryspec.containers[].resources.requests.hugepages-<size>
# view container resources object within the pod spec
kubectl explain pod.spec.containers.resources
# pod resource update is forbidden, but you can generate YAML, see `kubectl set -h`
kubectl set resources pod --help
# generate YAML for pod `mypod` that requests 0.2 CPU and 128Mi memory
kubectl set resources pod mypod --requests=cpu=200m,memory=128Mi --dry-run=client -oyaml|less
# generate YAML for requests 0.2 CPU, 128Mi memory, and limits 0.5 CPU, 256Mi memory
kubectl set resources pod mypod --requests=cpu=200m,memory=128Mi --limits=cpu=500m,memory=256Mi --dry-run=client -oyaml|lessYou may use the official container resource example manifest or generate a manifest file with kubectl set resources.
- Create a Pod with the following spec:
- runs in
devnamespace - runs two containers, MongoDB database and webserver frontend
- restart only on failure, see
pod.spec.restartPolicy - both containers starts with 0.25 CPU, 64 mebibytes RAM
- both containers does not exceed 1 CPU, 256 mebibytes RAM
- runs in
- List created pods
- Review pod details and confirm the specified resource quotas are applied
- Edit the Pod manifest as follows:
- both containers starts with an insufficient amount RAM, e.g 4 mebibytes
- both containers does not exceed 8 mebibytes RAM
- Apply the manifest and review behaviour
- Review logs for both containers
- Compare the logs output in [6] to details from
kubectl describe - Edit the Pod manifest as follows:
- both containers starts with an amount of RAM equal to host RAM (run
cat /proc/meminfoorfree -h) - both containers starts with an amount CPU equal to host CPU (run
cat /proc/cpuinfoorlscpu) - both containers does not exceed x2 the amount of host RAM
- both containers starts with an amount of RAM equal to host RAM (run
- Apply the manifest and review behaviour
- Delete created resources
- Review the Pod spec fields related to limits and requests
lab6.6 solution
kubectl create ns dev --dry-run=client -o yaml >> lab6-6.yaml
echo --- >> lab6-6.yaml
# add the contents of the example manifest to lab6-6.yaml and modify accordingly
nano lab6-6.yaml# lab6-6.yaml
kind: Namespace
metadata:
name: dev
# etc
---
kind: Pod
metadata:
name: webapp
namespace: dev
spec:
restartPolicy: OnFailure
containers:
- image: mongo
name: database
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "256Mi"
cpu: 1
- image: nginx
name: frontend
resources: # same as above
# etckubectl apply -f lab6-6.yaml
kubectl get pods -n dev
kubectl describe pods webapp -n dev | less
kubectl describe pods webapp -n dev | grep -A 4 -E "Containers:|State:|Limits:|Requests:" | less
nano lab6-6.yaml# lab6-6.yaml
kind: Pod
spec:
containers:
- resources:
requests:
memory: "4Mi"
cpu: "250m"
limits:
memory: "8Mi"
cpu: 1
# etc - use above resources for both containerskubectl delete -f lab6-6.yaml
kubectl apply -f lab6-6.yaml
kubectl get pods -n dev --watch # watch for OOMKilled | CrashLoopBackOff
kubectl get logs webapp -n dev -c database # not very helpful logs
kubectl get logs webapp -n dev -c frontend
kubectl describe pods webapp -n dev | less # helpful logs - Last State: Terminated, Reason: OutOfMemory (OOMKilled)
kubectl describe pods webapp -n dev | grep -A 4 -E "Containers:|State:|Limits:|Requests:" | less
cat /proc/cpuinfo # check for host memory
cat /proc/meminfo # check for host ram
nano lab6-6.yaml# lab6-6.yaml
kind: Pod
spec:
containers:
- resources:
requests:
memory: "8Gi" # use value from `cat /proc/meminfo`
cpu: 2 # use value from `cat /proc/cpuinfo`
limits:
memory: "16Gi"
cpu: 4
# etc - use above resources for both containerskubectl delete -f lab6-6.yaml
kubectl apply -f lab6-6.yaml
kubectl get pods -n dev --watch # remains in Pending until enough resources available
kubectl describe pods webapp
kubectl delete -f lab6-6.yaml
kubectl explain pod.spec.containers.resources | lessRemember a multi-container Pod is not recommended in live environments but only used here for learning purposes
This lab requires a Metrics Server running in your cluster, please run minikube addons enable metrics-server to enable Metrics calculation.
# enable metrics-server on minikube
minikube addons enable metrics-server
# list available nodes
kubectl get nodes
# view allocated resources for node and % resource usage for running (non-terminated) pods
kubectl describe node $NODE_NAME
# view nodes resource usage
kubectl top node
# view pods resource uage
kubectl top podoutput from kubectl describe node

- Enable Metrics Server in your cluster
- What is the cluster Node's minimum required CPU and memory?
- Create a Pod as follows:
- image
nginx:alpine - does not restart, see
kubectl explain pod.spec - only pulls a new image if not present locally, see
kubectl explain pod.spec.containers - requires 0.2 CPU to start but does not exceed half of the cluster Node's CPU
- requires 64Mi memory to start but does not exceed half of the cluster Node's memory
- image
- Review the running Pod and confirm resources configured as expected
- Delete created resources
lab 6.7 solution
minikube addons enable metrics-server
kubectl get node # show node name
kubectl describe node $NODE_NAME | grep -iA10 "allocated resources:" # cpu 0.95, memory 460Mi
kubectl run mypod --image=nginx:alpine --restart=Never --image-pull-policy=IfNotPresent --dry-run=client -oyaml>lab6-7.yml
kubectl apply -f lab6-7.yml # cannot use `kubectl set` if pod don't exist
kubectl set resources pod mypod --requests=cpu=200m,memory=64Mi --limits=cpu=475m,memory=230Mi --dry-run=client -oyaml|less
nano lab6-7.yml # copy resources section of above output to pod yamlkind: Pod
spec:
containers:
- name: mypod
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 475m
memory: 230Mi
requests:
cpu: 200m
memory: 64Mikubectl delete -f lab6-7.yml
kubectl apply -f lab6-7.yml
kubectl describe -f lab6-7.yml | grep -iA6 limits:
kubectl delete -f lab6-7.ymlIn the boa Namespace, create a Pod that runs the shell command date, in a busybox container, once every hour, regardless success or failure. Job should terminate after 20s even if command still running. Jobs should be automatically deleted after 12 hours. A record of 5 successful Jobs and 5 failed Jobs should be kept. All resources should be named bootcamp, including the container. You may create a new Namespace if required.
At the end of your task, to avoid waiting an hour to confirm all works, manually run the Job from the Cronjob and verify expected outcome.
hints
hint 1
Did you create the Cronjob in the boa Namespace? You can generate YAML with Namespace specified, see lab 5.6
hint 2
You can generate YAML for Cronjob schedule and command, see lab 6.5 - working with cronjobs
hint 3
See kubectl explain job.spec for terminating and auto-deleting Jobs after specified time.
hint 4
See kubectl explain cronjob.spec for keeping successful/failed Jobs.
hint 5
You can create a Job to manually run a Cronjob, see kubectl create job --help
hint 6
Did you create the Job in the boa Namespace?
hint 7
Did you specify cronjob.spec.jobTemplate.spec.activeDeadlineSeconds and cronjob.spec.jobTemplate.spec.ttlSecondsAfterFinished?
hint 8
Did you specify cronjob.spec.failedJobsHistoryLimit and cronjob.spec.successfulJobsHistoryLimit?
hint 9
After Cronjob creation, did you verify configured parameters in kubectl describe?
hint 10
After manual Job creation, did you verify Job successfully triggered?
A client requires a Pod running the nginx:1.21-alpine image with name webapp in the dog Namespace. The Pod should start with 0.25 CPU and 128Mi memory, but shouldn't exceed 0.5 CPU and half of the Node's memory. All processes in Pod containers should run with user ID 1002 and group ID 1003. Containers mustn't run in privileged mode and privilege escalation should be disabled. You may create a new Namespace if required.
When you are finished with the task, the client would also like to know the Pod with the highest memory consumption in the default Namespace. Save the name the Pod in the format <namespace>/<pod-name> to a file /home/$USER/ckad-tasks/resources/pod-with-highest-memory
hints
hint 1
Did you create the resource in the dog Namespace? You can generate YAML with Namespace specified, see lab 5.6
hint 2
You can separately generate YAML for the pod.spec.containers.resources section, see lab 6.7 - resource allocation and usage
hint 3
See lab 6.3 for security context. You will need to add four separate rules for user ID, group ID, privileged and privilege escalation.
hint 4
You can use a combination of the output-name and sorting format kubectl -oname --sort-by=json-path-to-field. The JSON path can be derived from viewing the resource with output-json -ojson. See kubectl cheatsheet for more details
Deployments manages Pods with scalability and reliability. This is the standard way to manage Pods and ReplicaSets in live environments.
# create a deployment `myapp` with 1 pod, see `kubectl create deploy --help`
kubectl create deployment myapp --image=nginx
# create a deployment `myapp` with 3 pods
kubectl create deploy myapp --image=nginx --replicas=3
# list existing resources in `default` namespace
kubectl get all
# list existing resources filtered by selector `app=myapp`
kubectl get all --selector="app=myapp" # or `--selector app=myapp`
# show details of deployment `myapp`, see `kubectl describe deploy --help`
kubectl describe deploy myapp
# scale deployment `myapp`, see `kubectl scale deploy --help`
kubectl scale deploy myapp --replicas=4
# edit deployment `myapp` (not all fields are edittable), see `kubectl edit deploy --help`
kubectl edit deploy myapp
# edit deployment `myapp` with specified editor
KUBE_EDITOR=nano kubectl edit deploy myapp
# set deployment image for `webserver` container to `nginx:1.8`, see `kubectl set --help` for editable fields
kubectl set image deployment/myapp webserver=nginx:1.8
# set deployment image for all containers to `nginx:1.8`, see `kubectl set image --help`
kubectl set image deployment/myapp *=nginx:1.8
# view the deployment spec
kubectl explain deploy.specDeployments can be used to rollout a ReplicaSet which manages the number of Pods. In CKAD you will only work with ReplicaSets via Deployments
- Create a deployment with three replicas using a suitable image
- Show more details of the deployment and review available fields:
- namespace, labels, selector, replicas, update strategy type, pod template, conditions, replicaset and events
- List all created resources
- Delete a Pod and monitor results
- Compare results to using naked Pods (run a pod and delete it)
- Delete the ReplicaSet with
kubectl delete rs $rsNameand monitor results - Delete created resources
- Explore the deployment spec
- Explore the Kubernetes API Resources to determine when deployments and replicasets was introduced
lab7.1 solution
kubectl create deploy myapp --image=httpd --replicas=3
kubectl describe deploy myapp | less
kubectl get all
kubectl delete pod $POD_NAME
kubectl get all
kubectl get pods --watch # watch replicaset create new pod to replace deleted
kubectl run mypod --image=httpd
kubectl get all
kubectl delete pod mypod
kubectl get all # naked pod not recreated
kubectl delete replicaset $REPLICASET_NAME # pods and replicaset deleted
kubectl get all
kubectl get pods --watch # deployment creates new replicaset, and replicaset creates new pods
kubectl delete deploy myapp nginx-deployment
kubectl explain deploy.spec
kubectl api-resources # deployments & replicasets were introduced in apps/v1
# replicasets replaced v1 replicationcontrollersA deployment creates a ReplicaSet that manages scalability. Do not manage replicasets outside of deployments.
- Create a deployment using the official deployment manifest example
controllers/nginx-deployment.yaml - List created resources
- Edit the deployment with
kubectl editand change thenamespaceto dev - Save the editor and confirm behaviour
- Edit the deployment again using a different editor, change the replicas to 12 and upgrade the image version
- Save the editor and confirm behaviour, then immediately list all resources and review:
- deployment status for
READY,UP-TO-DATEandAVAILABLE - replicaset status for
DESIRED,CURRENTandREADY - pod status for
NAME,READYandSTATUS - compare the ID-suffix in the Pods name to the ReplicaSets name
- deployment status for
- View details of deployment to confirm edit applied, including image change
- Scale down the deployment back to 3 replicas using
kubectl scaleand review same in [6] - List all resources and confirm scaling applied
- Delete created resources
- Edit the
apiVersionof the manifest example file toapps/v0 - Apply the edited manifest and confirm behaviour
lab7.2 solution
wget -O lab7-2.yaml https://k8s.io/examples/controllers/nginx-deployment.yaml
kubectl apply -f lab7-2.yaml
kubectl get all
kubectl edit -f lab7-2.yamlkind: Deployment
metadata:
name: nginx-deployment
namespace: dev
# etc (save failed: not all fields are editable - cancel edit)KUBE_EDITOR=nano kubectl edit -f lab7-2.yamlkind: Deployment
spec:
replicas: 12
template:
spec:
containers:
- image: nginx:1.3
# etc - save successfulkubectl get all
kubectl describe -f lab7-2.yaml | less
kubectl scale deploy myapp --replicas=3
kubectl get all
kubectl delete -f lab7-2.yaml
nano lab7-2.yamlapiVersion: apps/v0
kind: Deployment
# etckubectl apply -f lab7-2.yaml # recognise errors related to incorrect manifest fieldsLabels are used for groupings, filtering and providing metadata. Selectors are used to group related resources. Annotations are used to provide additional metadata but are not used in queries.
When a deployment is created, a default Label app=$appName is assigned, and a similar Selector is also created. When a pod is created, a default Label run=$podName is assigned
Labels added after creating a deployment are not inherited by the resources
# add new label `state: test` to deployment `myapp`, see `kubectl label --help`
kubectl label deployment myapp state=test
# list deployments and their labels, see `kubectl get deploy --help`
kubectl get deployments --show-labels
# list all resources and their labels
kubectl get all --show-labels
# list deployments filtered by specific label
kubectl get deployments --selector="state=test"
# list all resources filtered by specific label
kubectl get all --selector="app=myapp"
# remove the `app` label from deployment `myapp`
kubectl label deploy myapp app-
# remove the `run` label from pod `mypod`
kubectl label pod mypod run-- Create a deployment
myappwith three replicas using a suitable image - List all deployments and their labels to confirm default labels assigned
- Add a new label
pipeline: testto the deployment - List all deployments and their labels
- View more details of the deployment and review labels/selectors
- View the YAML form of the deployment to see how labels are added in the manifest
- Verify the default label/selector assigned when you created a new Pod
- List all resources and their labels filtered by default label of the deployment
- List all resources and their labels, filtered by new label added, compare with above
- Remove the default label from one of the pods in the deployment and review behaviour
- List all pods and their labels
- List all pods filtered by the default label
- Delete the deployment
- Delete the naked Pod from [10]
lab7.3 solution
kubectl create deploy myapp --image=httpd --dry-run=client -o yaml >> lab7-3.yaml
kubectl apply -f lab7-3.yaml
kubectl get deploy --show-labels
kubectl label deploy myapp pipeline=test
kubectl get deploy --show-labels
kubectl describe -f lab7-3.yaml
kubectl get -o yaml -f lab7-3.yaml | less
kubectl run mypod --image=nginx --dry-run=client -o yaml | less
kubectl get all --selector="app=myapp"
kubectl get all --selector="pipeline=test"
kubectl label pod $POD_NAME app- # pod becomes naked/dangling and unmanaged by deployment
kubectl get pods --show-labels # new pod created to replace one with label removed
kubectl get pods --selector="app=myapp" # shows 3 pods
kubectl delete -f lab7-3.yaml # $POD_NAME not deleted! `deploy.spec.selector` is how a deployment find pods to manage!Rolling updates is the default update strategy, triggered when a field in the deployment's Pod template deployment.spec.template is changed. A new ReplicaSet is created that creates updated Pods one after the other, and the old ReplicaSet is scaled to 0 after successful update. At some point during the update, both old version and new version of the app will be live. By default, ten old ReplicaSets will be kept, see deployment.spec.revisionHistoryLimit
The other type of update strategy is Recreate, where all Pods are killed before new Pods are created. This is useful when you cannot have different versions of an app running simultaneously, e.g database.
deploy.spec.strategy.rollingUpdate.maxUnavailable: control number of Pods upgraded simultaneouslydeploy.spec.strategy.rollingUpdate.maxSurge: controls the number of additional Pods, more than the specified replicas, created during update. Aim to have a highermaxSurgethanmaxUnavailable.
A Deployment's rollout is only triggered if a field within the Pod template
deploy.spec.templateis changed
Scaling down a Deployment to 0 is another way to delete all resources, saving costs, while keeping the config for a quick scale up when required
# view the update strategy field under deployment spec
kubectl explain deployment.spec.strategy
# view update strategy field recursively
kubectl explain deployment.spec.strategy --recursive
# edit the image of deployment `myapp` by setting directly, see `kubectl set -h`
kubectl set image deployment myapp nginx=nginx:1.24
# edit the environment variable of deployment `myapp` by setting directly
kubectl set env deployment myapp dept=MAN
# show recent update history - entries added when fields under `deploy.spec.template` change
kubectl rollout history deployment myapp -h
# show update events
kubectl describe deployment myapp
# view rolling update options
kubectl get deploy myapp -o yaml
# view all deployments history, see `kubectl rollout -h`
kubectl rollout history deployment
# view `myapp` deployment history
kubectl rollout history deployment myapp
# view specific change revision/log for `myapp` deployment (note this shows fields that affect rollout)
kubectl rollout history deployment myapp --revision=n
# revert `myapp` deployment to previous version/revision, see `kubectl rollout undo -h`
kubectl rollout undo deployment myapp --to-revision=n- Review the update strategy field under the deployment spec
- Create a deployment with a suitable image
- View more details of the deployment
- by default, how many pods can be upgraded simultaneously during update?
- by default, how many pods can be created in addition to the number of replicas during update?
- Create a new deployment with the following parameters:
- 5 replicas
- image
nginx:1.18 - additional deployment label
update: feature - maximum of 2 Pods can be updated simultaneously
- no more than 3 additional Pod created during updates
- List all resources filtered by the default label
- List all resources filtered by the additional label
- List rollout history for all deployments - how many revisions does the new deployment have?
- Upgrade/downgrade the image version
- List all resources specific to the new deployment
- List rollout history specific to the new deployment - how many revisions?
- View more details of the deployment and note the image and Events messages
- Compare the latest change revision of the new deployment's rollout history to the previous revision
- Revert the new deployment to its previous revision
- List all resources specific to the new deployment twice or more to track changes
- List rollout history specific to the new deployment - any new revisions?
- Scale the new deployment to 0 Pods
- List rollout history specific to the new deployment - any new revisions?
- List all resources specific to the new deployment
- Delete created resources
lab7.4 solution
kubectl explain deploy.spec.strategy | less
kubectl create deploy myapp --image=nginx --dry-run=client -o yaml > lab7-4.yaml
kubectl apply -f lab7-4.yaml
kubectl describe -f lab7-4.yaml
kubectl get deploy myapp -o yaml | less # for manifest example to use in next step
nano lab7-4.yaml # edit to new parameterskind: Deployment
metadata:
labels: # labels is `map` not `array` so no `-` like containers
app: myapp
updates: feature
name: myapp
spec:
replicas: 5
strategy:
rollingUpdate:
maxSurge: 3
maxUnavailable: 2
template:
spec:
containers:
- image: nginx:1.18
name: webserver
# etckubectl get all --selector="app=myapp"
kubectl get all --selector="updates=feature" # extra deployment label not applied on pods
kubectl rollout history deploy
kubectl set image deploy myapp nginx=n -f lab7-4.yaml
kubectl set image deploy myapp webserver=nginx:1.23
kubectl get all --selector="app=myapp"
kubectl rollout history deploy myapp # 2 revisions
kubectl describe deploy myapp
kubectl rollout history deploy myapp --revision=2
kubectl rollout history deploy myapp --revision=1
kubectl rollout undo deploy myapp --to-revision=1
kubectl get all --selector="app=myapp"
kubectl rollout history deploy myapp # 2 revisions, but revision count incremented
kubectl scale deploy myapp --replicas=0
kubectl rollout history deploy myapp # replicas change does not trigger rollout, only `deploy.spec.template` fields
kubectl get all --selector="app=myapp"
kubectl delete -f lab7-4.yamlA DaemonSet is a kind of deployment that ensures that all (or some) Nodes run a copy of a particular Pod. This is useful in a multi-node cluster where specific application is required on all nodes, e.g. running a - cluster storage, logs collection, node monitoring, network agent - daemon on every node. As nodes are added to the cluster, Pods are added to them. As nodes are removed from the cluster, those Pods are garbage collected. Deleting a DaemonSet will clean up the Pods it created.
# create daemonset via yaml file
kubectl create -f daemonset.yaml
# view daemonsets pods
kubectl get ds,pods
# view daemonset in kube system namespace
kubectl get ds,pods -n kube-system
# view the daemonset spec
kubectl explain daemontset.spec | less
# view the daemonset spec recursively
kubectl explain daemontset.spec --recursive | lessDaemonSets can only be created by YAML file, see an official example manifest controllers/daemonset.yaml.
- Compare the DaemonSet manifest to a Deployment manifest - differences/similarities?
- Apply the example manifest
- List all resources and note resources created by the DaemonSet
- View more details of the DaemonSet
- Delete created resources
- Review the Kubernetes API Resources to determine when DaemonSets was introduced
- List existing DaemonSets in the kube-system namespace and their labels
- what does Kubernetes use a DaemonSet for?
- List all resources in the kube-system namespace matching the DaemonSet label
- Review the DaemonSet spec
lab7.5 solution
kubectl create deploy myapp --image=nginx --dry-run=client -o yaml | less # view fields required
wget -qO- https://k8s.io/examples/controllers/daemonset.yaml | less # similar to deployment, except Kind and replicas
kubectl apply -f https://k8s.io/examples/controllers/daemonset.yaml
kubectl get all # note daemonset and related pod
kubectl describe -f https://k8s.io/examples/controllers/daemonset.yaml
kubectl delete -f https://k8s.io/examples/controllers/daemonset.yaml
kubectl api-resources # introduced in version apps/v1
kubectl get ds -n=kube-system --show-labels # used to add network agent `kube-proxy` to all cluster nodes
kubectl get all -n=kube-system --selector="k8s-app=kube-proxy"
kubectl explain daemonset.spec | less
kubectl explain daemonset.spec --recursive | lessAutoscaling is very important in live environments but not covered in CKAD. Visit HorizontalPodAutoscaler Walkthrough for a complete lab on autoscaling.
The lab requires a metrics-server so install one via Minikube if you plan to complete the lab
# list minikube addons
minikube addons list
# enable minikube metrics-server
minikube addons enable metrics-server
# disable minikube metrics-server
minikube addons disable metrics-serverSome bootcamp students have been messing with the webapp Deployment for the test environment's webpage in the default Namespace, leaving it broken. Please rollback the Deployment to the last fully functional version. Once on the fully functional version, update the Deployment to have a total of 10 Pods, and ensure that the total number of old and new Pods, during a rolling update, do not exceed 13 or go below 7.
Update the Deployment to nginx:1.22-alpine to confirm the Pod count stays within these thresholds. Then rollback the Deployment to the fully functional version. Before you leave, set the Replicas to 4, and just to be safe, Annotate all the Pods with description="Bootcamp Test Env - Please Do Not Change Image!".
- Command to setup environment:
printf '\nlab: environment setup in progress...\n'; echo '{"apiVersion":"apps/v1","kind":"Deployment","metadata":{"labels":{"appid":"webapp"},"name":"webapp"},"spec":{"replicas":2,"revisionHistoryLimit":15,"selector":{"matchLabels":{"appid":"webapp"}},"template":{"metadata":{"labels":{"appid":"webapp"}},"spec":{"volumes":[{"name":"varlog","emptyDir":{}}],"containers":[{"image":"nginx:1.12-alpine","name":"nginx","volumeMounts":[{"name":"varlog","mountPath":"/var/logs"}]}]}}}}' > k8s-task-6.yml; kubectl apply -f k8s-task-6.yml >/dev/null; cp k8s-task-6.yml k8s-task-6-bak.yml; sed -i -e 's/nginx:1.12-alpine/nginx:1.13alpine/g' k8s-task-6.yml 2>/dev/null; sed -i '' 's/nginx:1.12-alpine/nginx:1.13alpine/g' k8s-task-6.yml 2>/dev/null; kubectl apply -f k8s-task-6.yml >/dev/null; sleep 1; sed -i -e 's/nginx:1.13alpine/nginx:1.14-alpine/g' k8s-task-6.yml 2>/dev/null; sed -i '' 's/nginx:1.13alpine/nginx:1.14-alpine/g' k8s-task-6.yml 2>/dev/null; kubectl apply -f k8s-task-6.yml >/dev/null; sleep 4; sed -i -e 's/nginx:1.14-alpine/nginx:1.15-alpine/g' k8s-task-6.yml 2>/dev/null; sed -i -e 's/\/var\/logs/\/usr\/share\/nginx\/html/g' k8s-task-6.yml 2>/dev/null; sed -i '' 's/nginx:1.14-alpine/nginx:1.15-alpine/g' k8s-task-6.yml 2>/dev/null; sed -i '' 's/\/var\/logs/\/usr\/share\/nginx\/html/g' k8s-task-6.yml 2>/dev/null; kubectl apply -f k8s-task-6.yml >/dev/null; sleep 2; sed -i -e 's/nginx:1.15-alpine/ngnx:1.16-alpine/g' k8s-task-6.yml 2>/dev/null; sed -i -e 's/\/var\/logs/\/usr\/share\/nginx\/html/g' k8s-task-6.yml 2>/dev/null; sed -i '' 's/nginx:1.15-alpine/ngnx:1.16-alpine/g' k8s-task-6.yml 2>/dev/null; sed -i '' 's/\/var\/logs/\/usr\/share\/nginx\/html/g' k8s-task-6.yml 2>/dev/null; kubectl apply -f k8s-task-6.yml >/dev/null; sleep 4; kubectl apply -f k8s-task-6-bak.yml >/dev/null; sleep 4; kubectl rollout undo deploy webapp --to-revision=5 >/dev/null; kubectl delete $(kubectl get rs --sort-by=".spec.replicas" -oname | tail -n1) >/dev/null; rm k8s-task-6.yml k8s-task-6-bak.yml; echo 'lab: environment setup complete!' - Command to destroy environment:
kubectl delete deploy webapp
hints
hint 1
ReplicaSets store the Pod configuration used by a Deployment.
hint 2
You can reveal more resource details with kubectl get -owide. You might be able to find defective Pods/ReplicaSets quicker this way.
hint 3
You will need to review the Deployment's rollout history, see lab 7.4 - rolling updates
hint 4
You can view more details of a rollout revision with kubectl rollout history --revision=$REVISION_NUMBER
hint 5
Did you test that the Pods are serving an actual webpage? This task isn't complete without testing the webpage - Pods in Running state doesn't mean fully functional version.
hint 6
You can test a Pod with kubectl port-forward, by creating a temporary Pod kubectl run --rm -it --image=nginx:alpine -- sh and running curl $POD_IP, etc.
hint 7
Always remember kubectl explain when you encounter new requirements. Use this to figure out what rolling update parameters are required.
hint 8
You can update a Deployment's image quickly with kubectl set image --help. You're not required to count Pods during rolling update, all should be fine long as you have maxSurge and maxUnavailable set correctly.
hint 9
Any change that triggers a rollout (changing anything under deploy.spec.template) will create a new ReplicaSet which becomes visible with kubectl rollout history.
Be sure to perform updates one after the other, without batching, as an exam question dictates, especially if the changes trigger a rollout. For example, apply replicas and update strategy changes before applying image changes.
hint 10
You can set replicas quickly with kubectl scale --help.
hint 11
You can Annotate all 4 Pods in a single command, see kubectl annotate --help.
A Service provides access to applications running on a set of Pods. A Deployment creates and destroys Pods dynamically, so you cannot rely on Pod IP. This is where Services come in, to provide access and load balancing to the Pods.
Like Deployments, Services targets Pods by selector but exists independent from a Deployment - not deleted during Deployment deletion and can provide access to Pods in different Deployments.
- ClusterIP: this is a service inside a cluster responsible for routing traffic between apps running in the cluster - no external access
- NodePort: as the name implies, a specific port is opened on each Worker Node's IP to allow external access to the cluster at
$NodeIP:$NodePort- useful for testing purposes - LoadBalancer: Exposes the Service using a cloud provider (not for CKAD)
- ExternalName: Uses DNS records (not for CKAD)
ClusterIP and NodePort example

Kubernetes supports two primary modes of finding a Service - environment variables and DNS.
In the env-vars mode, the kubelet adds a set of env-vars ({SVCNAME}_SERVICE_HOST and {SVCNAME}_SERVICE_PORT) to each Pod for each active Service. Services must be created before Pods to auto-populate the env-vars. You can disable this mode by setting the pod.spec field enableServiceLinks: false.
The DNS mode is the recommended discovery method. A cluster-aware DNS server, such as CoreDNS, watches the Kubernetes API for new Services and creates a set of DNS records for each one. If DNS has been enabled throughout your cluster, then for a Service called my-service in a Kubernetes namespace my-ns, Pods in the my-ns namespace can find the service by a name lookup for my-service, while Pods in other namespaces must qualify the name my-service.my-ns.
Always remember that a Service will only target Pods that have Labels matching the Service's Label Selector
Not all images expose their applications on port 80. When unsure, try one ofnetstat -tulpnorss -tulpnin the container.
# service
kind: Service
metadata:
name: webapp
spec:
selector:
appid: webapp # this must match the label of a pod to be targeted by a Service
ports:
- nodePort: 32500 # node port
port: 80 # service port
targetPort: 8080 # container port - do not assume port 80, always check container
---
# pod targeted
kind: Pod
metadata:
labels:
appid: webapp # matches label selector of service
name: mypod
---
# pod not targeted
kind: Pod
metadata:
labels:
app: webapp # does not match label selector of service
name: mypod# view the service spec
kubectl explain svc.spec | less
# create a ClusterIP service by exposing a deployment `myapp` on port 80, see `kubectl expose -h`
kubectl expose deploy myapp --port=80
# specify a different service name, the deployment name is used if not specified
kubectl expose deploy myapp --port=80 --name=myappsvc
# specify container port 8000
kubectl expose deploy myapp --port=80 --target-port=8000
# create a NodePort service
kubectl expose deploy myapp --type=NodePort --port=80
# print a pod's service environment variables
kubectl exec $POD_NAME -- printenv | grep SERVICE
# view more details of the service exposing deployment `myapp`
kubectl describe svc myapp
# view the yaml form of service in yaml
kubectl get svc myapp -o yaml | less
# edit service
kubectl edit svc myapp
# list all endpoints
kubectl get endpoints
# list pods and their IPs
kubectl get pods -o wide- Create a simple deployment with name
webserver - List created resources
- List endpoints, and pods with their IPs
- Can you spot the relationship between the Service, Endpoints and Pods?
- Create a Service for the deployment, exposed on port 80
- List created resources and note services fields
TYPE,CLUSTER-IP,EXTERNAL-IPandPORT(S) - View more details of the Service and note fields
IPs,Port,TargetPortandEndpoints - View the YAML form of the Service and compare info shown with output in [6]
- Print the Service env-vars from one of the pods
- Scale the deployment down to 0 replicas first, then scale up to 2 replicas
- List all pods and their IPs
- Print the Service env-vars from one of the pods and compare to results in [3]
- List endpoints, and pods with their IPs
- Access the app by the Service:
curl $ClusterIP:$Port - Access the app by the Service from the container host:
minikube sshthencurl $ClusterIP:$Port - Run a
busyboxPod with a shell connected interactively and perform the following commands:- run
cat /etc/resolv.confand review the output - run
nslookup webserver(service name) and review the output - what IPs and/or qualified names do these match?
- run
- Run a temporary
nginx:alpinePod to query the Service by name:- first run
kubectl run mypod --rm -it --image=nginx:alpine -- sh - then once in container, run
curl $SERVICE_NAME:$PORT - you should run
curl $SERVICE_NAME.$SERVICE_NAMESPACE:$PORTif the Service and the temporary Pod are in separate Namespaces
- first run
- Delete created resources
- Explore the Service object and the Service spec
lab 8.1 solution
# host terminal
kubectl create deploy webserver --image=httpd --dry-run=client -o yaml > lab8-1.yaml
kubectl apply -f lab8-1.yaml
kubectl get all
kubectl get svc,ep,po -o wide # endpoints have <ip_address:port> of pods targeted by service
echo --- >> lab8-1.yaml
kubectl expose deploy webserver --port=80 --dry-run=client -o yaml >> lab8-1.yaml
kubectl apply -f lab8-1.yaml
kubectl get svc,pods
kubectl describe svc webserver | less
kubectl get svc webserver -o yaml | less # missing endpoints IPs
kubectl exec $POD_NAME -- printenv | grep SERVICE # no service env-vars
kubectl scale deploy webserver --replicas=0; kubectl scale deploy webserver --replicas=2
kubectl get pods -o wide # service env-vars applied to pods created after service
kubectl exec $POD_NAME -- printenv | grep SERVICE
kubectl get endpoints,pods -o wide
curl $CLUSTER_IP # docker-desktop connection error, docker-engine success
minikube ssh
# cluster node terminal
curl $CLUSTER_IP # success with both docker-desktop and docker-engine
exit
# host terminal
kubectl run mypod --rm -it --image=busybox
# container terminal
cat /etc/resolv.conf # shows service ip as dns server
nslookup webserver # shows dns search results, read more at https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/#namespaces-of-services
exit
# host terminal
kubectl run mypod --rm -it --image=nginx:alpine -- sh
# container terminal
curl webserver # no need to add port cos default is 80
curl webserver.default # this uses the namespace of the service
exit
# host terminal
kubectl delete -f lab8-1.yaml
kubectl explain service | less
kubectl explain service.spec | lessIn this lab, we will implement a naive example of a backend-frontend microservices architecture - expose frontend to external traffic with NodePort Service while keeping backend hidden with ClusterIP Service.
Note that live environments typically use Ingress (covered in the next chapter) to expose applications to external traffic
Backend-Frontend microservices architecture example

- Create a simple Deployment, as our
backendapp, with the following spec:- image
httpd(for simplicity) - name
backend - has Labels
app: backendandtier: webapp - has Selectors
app: backendandtier: webapp
- image
- Create a Service for the backend app with the following spec:
- type
ClusterIP - port 80
- same name, Labels and Selectors as backend Deployment
- type
- Confirm you can access the app by
$CLUSTER-IPor$SERVICE_NAME - Configure an nginx upstream in
nginx/default.confto redirect traffic for the/route to the backend service# nginx/default.conf upstream backend-server { server backend; # dns service discovery within the same namespace use service name } server { listen 80; location / { proxy_pass http://backend-server; } }
- Create a simple Deployment, as our
frontendapp, with the following spec:- image
nginx - name
frontend - has Labels
app: webappandtier: frontend - has Selectors
app: webappandtier: frontend - Remember that Services target Pods by Selector (the Label Selector of the Service must match the Label of the Pod)
- mounts the nginx config file to
/etc/nginx/conf.d/default.conf(use fullpath$(pwd)/nginx/default.conf) - see example hostPath volume mount manifest
- image
- Create a Service for the frontend app with the following spec:
- type
NodePort - port 80
- same name, Labels and Selectors as frontend Deployment
- Remember that Services target Pods by Selector
- type
- Confirm you can access the backend app from the Minikube Node
$(minikube ip):NodePort - Delete created resources
lab 8.2 solution
kubectl create deploy backend --image=httpd --dry-run=client -o yaml > lab8-2.yaml
echo --- >> lab8-2.yaml
kubectl expose deploy backend --port=80 --dry-run=client -o yaml >> lab8-2.yaml
nano lab8-2.yaml# backend deploymemt
kind: Deployment
metadata:
labels:
app: backend
tier: webapp
name: backend
spec:
selector:
matchLabels:
app: backend
tier: webapp
template:
metadata:
labels:
app: backend
tier: webapp
# backend service
kind: Service
metadata:
labels:
app: backend
tier: webapp
name: backend
spec:
selector:
app: backend
tier: webappkubectl apply -f lab8-2.yaml
curl $CLUSTER_IP # or run in node terminal `minikube ssh`
mkdir nginx
nano nginx/default.conf # use snippet from step [4]
echo --- >> lab8-2.yaml
kubectl create deploy frontend --image=nginx --dry-run=client -o yaml >> lab8-2.yaml
echo --- >> lab8-2.yaml
kubectl expose deploy frontend --port=80 --dry-run=client -o yaml >> lab8-2.yaml
nano lab8-2.yaml# frontend deploymemt
kind: Deployment
metadata:
labels:
app: frontend
tier: webapp
name: frontend
spec:
selector:
matchLabels:
app: frontend
tier: webapp
template:
metadata:
labels:
app: frontend
tier: webapp
spec:
containers:
- image: nginx
volumeMounts:
- mountPath: /etc/nginx/conf.d/default.conf
name: conf-volume
volumes:
- name: conf-volume
hostPath:
path: /full/path/to/nginx/default.conf # `$(pwd)/nginx/default.conf`
# frontend service
kind: Service
metadata:
labels:
app: frontend
tier: webapp
name: frontend
spec:
type: NodePort
selector:
app: frontend
tier: webappkubectl apply -f lab8-2.yaml
kubectl get svc,pods
curl $(minikube ip):$NODE_PORT # shows backend httpd page
kubectl delete -f lab8-2.yamlCreate a Pod named webapp in the pig Namespace (create new if required), running nginx:1.20-alpine image. The Pod should have a Annotation motd="Welcome to Piouson's CKAD Bootcamp". Expose the Pod on port 8080.
hints
hint 1
Did you create the Pod in the pig Namespace? You should create the Namespace if it doesn't exist.
hint 2
You can set Annotation when creating a Pod, see kubectl run --help
hint 3
Actually, besides creating the Namespace, you can complete the rest of the task in a single command. Completing this task any other way is not but time wasting. Have a deeper look at kubectl run --help.
hint 4
Did you test you are able to access the app via the Service? This task is not complete until you confirm the application is accessible via the Service.
hint 5
You can test the Service by connecting a shell to a temporary Pod kubectl run -it --rm --image=nginx:alpine -n $NAMESPACE -- sh and run curl $SERVICE_NAME:$PORT. If you did not create the temporary Pod in the same Namespace, you will need to add the Namespace to the hostname curl $SERVICE_NAME.$NAMESPACE:$PORT.
Testing this way, with Service hostname, is also a way to confirm DNS is working in the cluster.
A bootcamp student is stuck on a simple task and would appreciate your expertise. Their goal is to create a webapp Deployment running gcr.io/google-samples/node-hello:1.0 image in the bat Namespace, exposed on port 80 and NodePort 32500. The student claims everything was setup as explained in class but still unable to access the application via the Service. Swoop down like a superhero and save the day by picking up where the student left off.
- Command to setup environment:
printf '\nlab: environment setup in progress...\n'; echo '{"apiVersion":"v1","kind":"List","items":[{"apiVersion":"v1","kind":"Namespace","metadata":{"name":"bat"}},{"apiVersion":"apps/v1","kind":"Deployment","metadata":{"labels":{"appid":"webapp"},"name":"webapp","namespace":"bat"},"spec":{"replicas":2,"selector":{"matchLabels":{"appid":"webapp"}},"template":{"metadata":{"labels":{"appid":"webapp"}},"spec":{"containers":[{"image":"gcr.io/google-samples/node-hello:1.0","name":"nginx"}]}}}},{"apiVersion":"v1","kind":"Service","metadata":{"labels":{"appid":"webapp"},"name":"webapp","namespace":"bat"},"spec":{"ports":[{"port":80,"protocol":"TCP","targetPort":80}],"selector":{"app":"webapp"}}}]}' | kubectl apply -f - >/dev/null; echo 'lab: environment setup complete!'
- Command to destroy environment
kubectl delete ns bat
hints
hint 1
Did you check for the relationship between the Service, Endpoint and Pods? When a Service with a Selector is created, an Endpoint with the same name is automatically created. See lab 8.1 - connecting applications with services.
hint 2
Did you confirm that the Service configuration matches the requirements with kubectl describe svc? You should also run some tests, see discovering services and lab 8.1 - connecting applications with services.
hint 3
If you're still unable to access the app but Endpoints have correct IP addresses, you might want to check if there is a working application to begin with. See lab 5.1 - creating pods
hint 4
Now you have the container port? Is the Service configured to use this container port? Is the Pod configured to use this container port? 💡
hint 5
Remember a Service can specify three types of ports: port | targetPort | nodePort. Which is the container port?
hint 6
For a Service, you can quickly verify the configured container port by reviewing the IP addresses of the Service Endpoint, they should be of the form $POD_IP:CONTAINER_PORT
Once resolved, you should be able to access the application via the Service with curl.
hint 7
For a Pod, you can quickly verify the configured container port by reviewing the ReplicaSet config with kubectl describe rs.
Once resolved, you should be able to access the application via the Service with curl.
Ingress exposes HTTP and HTTPS routes from outside the cluster to services within the cluster. Traffic routing is controlled by rules defined on the Ingress resource. Ingress may be configured to give Services externally-reachable URLs, load balance traffic, terminate SSL/TLS, and offer name-based virtual hosting.
💡 Only creating an Ingress resource has no effect! You must have an Ingress controller to satisfy an Ingress. In our local lab, we will use the Minikube Ingress controller
ingress-service topology

# list existing minikube addons
minikube addons list
# enable ingress on minikube
minikube addons enable ingress
# enable ingress manually
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.44.0/deploy/static/provider/cloud/deploy.yaml
# list existing namespaces
kubectl get ns
# list resources in the ingress namespace
kubectl get all -n ingress-nginx
# list ingressclass resource in the ingress namespace
kubectl get ingressclass -n ingress-nginx
# view ingress spec
kubectl explain ingress.spec | lessYou can remove the need for a trailing slash
/in urls by adding annotationnginx.ingress.kubernetes.io/rewrite-target: /to ingress specingress.metadata.annotations
- List existing namespaces
- Enable Ingress on minikube
- List Namespaces and confirm new Ingress Namespace added
- List all resources in the Ingress Namespace, including the ingressclass
- Review the ingress-nginx-controller Service in YAML form, note service type and ports
- Review the ingressclass in YAML form, is this marked as the default?
- Review the Ingress spec
lab9.1 solution
kubectl get ns # not showing ingress-nginx namespace
minikube addons list # ingress not enable
minikube addons enable ingress
minikube addons list # ingress enabled
kubectl get ns # shows ingress-nginx namespace
kubectl get all,ingressclass -n ingress-nginx # shows pods, services, deployment, replicaset, jobs and ingressclass
kubectl get svc ingress-nginx-controller -o yaml | less
kubectl get ingressclass nginx -o yaml | less # annotations - ingressclass.kubernetes.io/is-default-class: "true"
kubectl explain ingress.spec | less- single-service ingress defines a single rule to access a single service
- simple fanout ingress defines two or more rules of different paths to access different services
- name-based virtual hosting ingress defines two or more rules with dynamic routes based on host header - requires a DNS entry for each host header
# create ingress with a specified rule, see `kubectl create ingress -h`
kubectl create ingress $INGRESS_NAME --rule="$PATH=$SERVICE_NAME:$PORT"
# create single-service ingress `myingress`
kubectl create ingress myingress --rule="/=app1:80"
# create simple-fanout ingress
kubectl create ingress myingress --rule="/=app1:80" --rule="/about=app2:3000" --rule="/contact=app3:8080"
# create name-based-virtual-hosting ingress
kubectl create ingress myingress --rule="api.domain.com/*=apiservice:80" --rule="db.domain.com/*=dbservice:80" --rule="app.domain.com/*=appservice:80"-
Create a Deployment called
webusing ahttpdimage -
Expose the deployment with a Cluster-IP Service called
web-svc -
Create an Ingress called
web-ingwith a Prefix rule to redirect/requests to the Service -
List all created resources - what is the value of Ingress
CLASS,HOSTS&ADDRESS?- think about why the
CLASSandHOSTShave such values..
- think about why the
-
Access the app
webvia ingresscurl $(minikube ip)- note that unlike Service, a NodePort isn't specified
-
What if we want another application on
/testpath, will this work? Repeat steps 3-7 to confirm:- create a new deployment
web2with imagehttpd - expose the new deployment
web2-svc - add new Prefix path to existing ingress rule to redirect
/testtoweb2-svc - are you able to access the new
web2app viacurl $(minikube ip)/test? - are you still able to access the old
webapp viacurl $(minikube ip)? - what's missing?
- create a new deployment
-
Let's fix this by adding the correct Annotation to the Ingress config,
kubectl edit ingress web-ing:fix ingress
metadata: name: web-ing annotations: nginx.ingress.kubernetes.io/rewrite-target: /
-
Try to access both apps via URLs
curl $(minikube ip)/testandcurl $(minikube ip) -
Can you access both apps using HTTPS?
-
Review the ingress-nginx-controller by running:
kubectl get svc -n ingress-nginx- what is the ingress-nginx-controller Service type?
- what are the ports related to HTTP
80and HTTPS443?
-
Can you access both apps via the ingress-nginx-controller NodePorts for HTTP and HTTPS?
-
Delete all created resources
lab9.2 solution
kubectl create deploy web --image=httpd --dry-run=client -oyaml > lab9-2.yml
kubectl apply -f lab9-2.yml
echo --- >> lab9-2.yml
kubectl expose deploy web --name=web-svc --port=80 --dry-run=client -oyaml >> lab9-2.yml
echo --- >> lab9-2.yml
kubectl create ingress web-ing --rule="/*=web-svc:80" --dry-run=client -oyaml >> lab9-2.yml
kubectl apply -f lab9-2.yml
kubectl get deploy,po,svc,ing,ingressclass # CLASS=nginx, HOSTS=*, ADDRESS starts empty then populated later
curl $(minikube ip) # it works
echo --- >> lab9-2.yml
kubectl create deploy web2 --image=httpd --dry-run=client -oyaml > lab9-2.yml
kubectl apply -f lab9-2.yml
echo --- >> lab9-2.yml
kubectl expose deploy web2 --name=web2-svc --port=80 --dry-run=client -oyaml >> lab9-2.yml
KUBE_EDITOR=nano kubectl edit ingress web-ingKind: Ingress
spec:
rules:
- http:
paths:
- path: /
pathType: Prefix
...
- path: /test
pathType: Prefix
backend:
service:
name: web2-svc
port:
number: 80
# etccurl $(minikube ip)/test # 404 not found ???
curl $(minikube ip) # it works
KUBE_EDITOR=nano kubectl edit ingress web-ingKind: Ingress
metadata:
name: web-ing
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
# etccurl $(minikube ip)/test # it works
curl $(minikube ip) # it works
curl https://$(minikube ip)/test --insecure # it works, see `curl --help`
curl https://$(minikube ip) --insecure # it works
kubectl get svc -n ingress-nginx # NodePort, 80:$HTTP_NODE_PORT/TCP,443:$HTTPS_NODE_PORT/TCP
curl $(minikube ip):$HTTP_NODE_PORT
curl $(minikube ip):$HTTP_NODE_PORT/test
curl https://$(minikube ip):$HTTPS_NODE_PORT --insecure
curl https://$(minikube ip):$HTTPS_NODE_PORT/test --insecure
kubectl delete deploy web web2
kubectl delete svc web-svc web2-svc
kubectl delete ingress web-ing web2-ingIngress relies on Annotations to specify additional configuration. The supported Annotations depends on the Ingress controller type in use - in this case Ingress-Nginx
Please visit the Ingress-Nginx official Rewrite documentation for more details
- Create an Ingress
webapp-ingressthat:- redirects requests for path
myawesomesite.com/to a Servicewebappsvc:80 - redirects requests for path
myawesomesite.com/helloto a Servicehellosvc:8080 - remember to add the Rewrite Annotation
- redirects requests for path
- List created resources - compare the value of Ingress
HOSTSto the previous lab - View more details of the Ingress and review the notes under Rules
- View the Ingress in YAML form and review the structure of the Rules
- Create a Deployment
webappwith imagehttpd - Expose the
webappDeployment as NodePort with service namewebappsvc - List all created resources - ingress, service, deployment and other resources associated with the deployment
- View more details of the Ingress and review the notes under Rules
- Can you access
webappvia the minikube Nodecurl $(minikube ip)orcurl myawesomesite.com? - Create a second Deployment
hellowith imagegcr.io/google-samples/hello-app:1.0 - Expose
helloas NodePort with service namehellosvc - List newly created resources - service, pods, deployment etc
- View more details of the Ingress and review the notes under Rules
- Can you access
helloviacurl $(minikube ip)/helloormyawesomesite.com/hello? - Add an entry to
/etc/hoststhat maps the minikube Node IP to an hostname$(minikube ip) myawesomesite.com - Can you access
webappviacurl $(minikube ip)ormyawesomesite.comwith HTTP and HTTPS - Can you access
helloviacurl $(minikube ip)/helloormyawesomesite.com/hellowith HTTP and HTTPS - Can you access
webappandhelloonmyawesomesite.comvia the NodePorts specified by theingress-nginx-controller,webappsvcandhellosvcServices? - Delete created resources
lab9.3 solution
kubectl create ingress webapp-ingress --rule="myawesomesite.com/*=webappsvc:80" --rule="myawesomesite.com/hello/*=hellosvc:8080" --dry-run=client -oyaml > lab9-3.yaml
echo --- >> lab9-3.yaml
kubectl apply -f lab9-3.yaml
kubectl get ingress
kubectl describe ingress webapp-ingress | less # endpoints not found
kubectl get ingress webapp-ingress -oyaml | less
kubectl create deploy webapp --image=httpd --dry-run=client -oyaml >> lab9-3.yaml
echo --- >> lab9-3.yaml
kubectl apply -f lab9-3.yaml
kubectl expose deploy webapp --name=webappsvc --type=NodePort --port=80 --dry-run=client -o yaml >> lab9-3.yaml
echo --- >> lab9-3.yaml
kubectl apply -f lab9-3.yaml
kubectl get ingress,all
kubectl describe ingress webapp-ingress | less # only webappsvc endpoint found
curl $(minikube ip) # 404 not found
curl myawesomesite.com # 404 not found
kubectl create deploy hello --image=gcr.io/google-samples/hello-app:1.0 --dry-run=client -o yaml >> lab9-3.yaml
echo --- >> lab9-3.yaml
kubectl apply -f lab9-3.yaml
kubectl expose deploy hello --name=hellosvc --type=NodePort --port=8080 --dry-run=client -o yaml >> lab9-3.yaml
echo --- >> lab9-3.yaml
kubectl apply -f lab9-3.yaml
kubectl get all --selector="app=hello"
kubectl describe ingress webapp-ingress | less # both endpoints found
curl $(minikube ip)/hello # 404 not found
curl myawesomesite.com/hello # 404 not found
echo "$(minikube ip) myawesomesite.com" | sudo tee -a /etc/hosts # see `tee --help`
curl $(minikube ip) # 404 not found
curl $(minikube ip)/hello # 404 not found
curl myawesomesite.com # it works
curl myawesomesite.com/hello # hello world
curl https://myawesomesite.com --insecure # it works
curl https://myawesomesite.com/hello --insecure # hello world
kubectl get svc -A # find NodePorts for ingress-nginx-controller, webappsvc and hellosvc
curl myawesomesite.com:$NODE_PORT_FOR_WEBAPPSVC # it works
curl myawesomesite.com:$NODE_PORT_FOR_HELLOSVC # hello world
curl myawesomesite.com:$HTTP_NODE_PORT_FOR_NGINX_CONTROLLER # it works
curl myawesomesite.com:$HTTP_NODE_PORT_FOR_NGINX_CONTROLLER/hello # hello world
curl https://myawesomesite.com:$HTTPS_NODE_PORT_FOR_NGINX_CONTROLLER --insecure
curl https://myawesomesite.com:$HTTPS_NODE_PORT_FOR_NGINX_CONTROLLER/hello --insecure
kubectl delete -f lab9-3.yamlThis is similar to defining API routes on a backend application, except each defined route points to a separate application/service/deployment.
- if no host is specified, the rule applies to all inbound HTTP traffic
- paths can be defined with a POSIX regex
- each path points to a resource backend defined with a
service.nameand aservice.port.nameorservice.port.numberposix_002dextended-regular-expression-syntax.html) - both the host and path must match the content of an incoming request before the load balancer directs traffic to the referenced Service
- a default path
.spec.defaultBackendcan be defined on the Ingress or Ingress controller for traffic that doesn't match any known paths, similar to a 404 route - ifdefaultBackendis not set, the default 404 behaviour will depend on the type of Ingress controller in use
Each rule-path in an Ingress must have a pathType. Paths without a pathType will fail validation.
There are three supported path types:
ImplementationSpecific- matching is up to the IngressClassExact- case sensitive matching of exact URL pathPrefix- case sensitive matching of URL path prefix, split into elements by/, on element by element basis
Please read the official docs on path matching examples and using wildcards
Ingresses can be implemented by different controllers, often with different configuration. Each Ingress should specify a class, a reference to an IngressClass resource that contains additional configuration including the name of the controller that should implement the class.
Depending on your ingress controller, you may be able to use parameters that you set cluster-wide, or just for one namespace.
- cluster-wide IngressClass: this is the default scope configured if you set the
ingressclass.spec.parametersfield without settingingressclass.spec.parameters.scope, or settingingressclass.spec.parameters.scope: Cluster - namespace IngressClass: if you set the
ingressclass.spec.parametersfield and setingressclass.spec.parameters.scope: Namespace
A particular IngressClass can be configured as default for a cluster by setting the ingressclass.kubernetes.io/is-default-class annotation to true
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
annotations:
ingressclass.kubernetes.io/is-default-class: "true"
# etc, see https://k8s.io/examples/service/networking/external-lb.yaml# list existing namespaces
kubectl get ns
# list ingressclasses in the ingress namespace
kubectl get ingressclass -n ingress-nginx
# list ingressclasses in the default namespace - present in all namespaces
kubectl get ingressclass
# view ingressclass object
kubectl explain ingressclass | less- Review the IngressClass resource object
- List the Ingress classes created by the minikube ingress addon
- Create two Deployments
nginxandhttpd - Expose both deployments as
Cluster-IPon port 80 - Create an Ingress with the following:
- redirects requests for
nginx.yourchosenhostname.comto thenginxService - redirects requests for
httpd.yourchosenhostname.comto thehttpdService - both rules should use a
Prefixpath type
- redirects requests for
- Review created resources
- Confirm Ingress PathType and IngressClass
- Review the IngressClass resource YAML form to determine why it was assigned by default
- Add an entry to
/etc/hoststhat maps the minikube Node IP to hostnames below:$(minikube ip) nginx.yourchosenhostname.com$(minikube ip) httpd.yourchosenhostname.com
- Verify you can access both deployments via their subdomains
- Delete created resources
lab9.4 solution
kubectl explain ingressclass | less
kubectl explain ingressclass --recursive | less
kubectl create deploy nginx --image=nginx --dry-run=client -o yaml > lab9-4.yaml
echo --- >> lab9-4.yaml
kubectl expose deploy nginx --port=80 --dry-run=client -o yaml >> lab9-4.yaml
echo --- >> lab9-4.yaml
kubectl create deploy httpd --image=httpd --dry-run=client -o yaml >> lab9-4.yaml
echo --- >> lab9-4.yaml
kubectl expose deploy httpd --port=80 --dry-run=client -o yaml >> lab9-4.yaml
echo --- >> lab9-4.yaml
kubectl create ingress myingress --rule="nginx.yourchosenhostname.com/*=nginx:80" --rule="httpd.yourchosenhostname.com/*=httpd:80" --dry-run=client -o yaml > lab9-4.yaml
echo --- >> lab9-4.yaml
kubectl apply -f lab9-4.yaml
kubectl get ingress,all
kubectl get ingress myingress -o yaml | less # `pathType: Prefix` and `ingressClassName: nginx`
kubectl get ingressclass nginx -o yaml | less # annotation `ingressclass.kubernetes.io/is-default-class: "true"` makes this class the default
echo "
$(minikube ip) nginx.yourchosenhostname.com
$(minikube ip) httpd.yourchosenhostname.com
" | sudo tee -a /etc/hosts
curl nginx.yourchosenhostname.com
curl httpd.yourchosenhostname.com
kubectl delete -f lab9-4.yaml
# note that when specifying ingress path, `/*` creates a `Prefix` path type and `/` creates an `Exact` path typeThere are two kinds of Pod isolation: isolation for egress (outbound), and isolation for ingress (inbound). By default, all ingress and egress traffic is allowed to and from pods in a namespace, until you have a NetworkPolicy in that namespace.
Network policies are implemented by a network plugin. A NetworkPolicy will have no effect if a network plugin that supports NetworkPolicy is not installed in the cluster.
There are three different identifiers that controls entities that a Pod can communicate with:
podSelector: selects pods within the NetworkPolicy namespace allowed for ingress/egress using selector matching (note: a pod cannot block itself)namespaceSelector: selects all pods in specific namespaces allowed for ingress/egress using selector matchingipBlock: selects IP CIDR ranges (cluster-external IPs) allowed for ingress/egress (note: node traffic is always allowed - not for CKAD)
minikube stop
minikube delete
# start minikube with calico plugin
minikube start --kubernetes-version=1.23.9 --cni=calico
# verify calico plugin running, allow enough time (+5mins) for all pods to enter `running` status
kubectl get pods -n kube-system --watch
# create network policy
kubectl apply -f /path/to/networkpolicy/manifest/file
# list network policies
kubectl get networkpolicy
# view more details of network policies `mynetpol`
kubectl describe networkpolicy mynetpolapiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-netpol
# create default deny all ingress/egress traffic
spec:
podSelector: {}
policyTypes:
- Ingress # or Egress
# create allow all ingress/egress traffic
spec:
podSelector: {}
ingress: # or egress
- {}You may follow the official declare network policy walkthrough
⚠ A Network Policy will have no effect without a network provider with network policy support (e.g. Calico)
⚠ Minikube Calico plugin might conflict with future labs, so remember to disable Calico after this lab
ℹ You can prependhttps://k8s.io/examples/to example filepaths from the official docs to use the file locally
- Create a Kubernetes cluster in minikube with Calico enabled
- delete existing cluster, or create an additional cluster, if Calico is not enabled
- Confirm Calico is up and running
- Create a Deployment called
webappusing imagehttpd - Expose the Deployment on port 80
- Review created resources and confirm pods running
- Create a busybox Pod and connect an interactive shell
- Run command in the Pod container
wget --spider --timeout=1 webapp - Limit access to the Service so that only Pods with label
tier=frontendhave access - see official manifest exampleservice/networking/nginx-policy.yaml - View more details of the NetworkPolicy created
- Create a busybox Pod and connect an interactive shell
- Run command in the Pod container
wget --spider --timeout=1 webapp - Create another busybox Pod with label
tier=frontendand connect an interactive shell - Run command in the Pod container
wget --spider --timeout=1 webapp - Delete created resources
- Revert to a cluster without Calico
lab9.5 solution
# host terminal
minikube stop
minikube delete
minikube start --kubernetes-version=1.23.9 --driver=docker --cni=calico
kubectl get pods -n kube-system --watch # allow enough time, under 5mins if lucky, more than 10mins if you have bad karma 😼
kubectl create deploy webapp --image=httpd --dry-run=client -o yaml > lab9-5.yaml
kubectl apply -f lab9-5.yaml
echo --- >> lab9-5.yaml
kubectl expose deploy webapp --port=80 --dry-run=client -o yaml > lab9-5.yaml
kubectl apply -f lab9-5.yaml
kubectl get svc,pod
kubectl get pod --watch # wait if pod not in running status
kubectl run mypod --rm -it --image=busybox
# container terminal
wget --spider --timeout=1 webapp # remote file exists
exit
# host terminal
echo --- >> lab9-5.yaml
wget -qO- https://k8s.io/examples/service/networking/nginx-policy.yaml >> lab9-5.yaml
nano lab9-5.yamlapiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: mynetpol
spec:
podSelector:
matchLabels:
app: webapp
ingress:
- from:
- podSelector:
matchLabels:
tier: frontendkubectl apply -f lab9-5.yaml
kubectl describe networkpolicy mynetpol | less
kubectl run mypod --rm -it --image=busybox
# container terminal
wget --spider --timeout=1 webapp # wget: download timed out
exit
# host terminal
kubectl run mypod --rm -it --image=busybox --labels="tier=frontend"
# container terminal
wget --spider --timeout=1 webapp # remote file exists
exit
# host terminal
kubectl delete -f lab9-5.yaml
minikube stop
minikube delete
minikube start --kubernetes-version=1.23.9 --driver=dockerThe application is meant to be accessible at ckad-bootcamp.local. Please debug and resolve the issue without creating any new resource.
- Command to setup environment:
printf '\nlab: environment setup in progress...\n'; echo '{"apiVersion":"v1","kind":"List","items":[{"apiVersion":"v1","kind":"Namespace","metadata":{"name":"bat"}},{"apiVersion":"apps/v1","kind":"Deployment","metadata":{"labels":{"appid":"webapp"},"name":"webapp","namespace":"bat"},"spec":{"replicas":2,"selector":{"matchLabels":{"appid":"webapp"}},"template":{"metadata":{"labels":{"appid":"webapp"}},"spec":{"containers":[{"image":"gcr.io/google-samples/node-hello:1.0","name":"nginx"}]}}}},{"apiVersion":"v1","kind":"Service","metadata":{"labels":{"appid":"webapp"},"name":"webapp","namespace":"bat"},"spec":{"ports":[{"port":80,"protocol":"TCP","targetPort":80}],"selector":{"app":"webapp"}}},{"kind":"Ingress","apiVersion":"networking.k8s.io/v1","metadata":{"name":"webapp","namespace":"bat"},"spec":{"ingressClassName":"ngnx","rules":[{"http":{"paths":[{"path":"/","pathType":"Prefix","backend":{"service":{"name":"webapp","port":{"number":80}}}}]}}]}}]}' | kubectl apply -f - >/dev/null; echo 'lab: environment setup complete!' - Command to destroy environment:
kubectl delete ns bat
Given several Pods in Namespaces pup and cat, create network policies as follows:
-
Pods in the same Namespace can communicate together
-
webappPod in thepupNamespace can communicate withmicroservicePod in thecatNamespace -
DNS resolution on UDP/TCP port 53 is allowed for all Pods in all Namespaces
-
Command to setup environment:
printf '\nlab: environment setup in progress...\n'; echo '{"apiVersion":"v1","kind":"List","items":[{"apiVersion":"v1","kind":"Namespace","metadata":{"name":"pup"}},{"apiVersion":"v1","kind":"Namespace","metadata":{"name":"cat"}},{"apiVersion":"v1","kind":"Pod","metadata":{"labels":{"server":"frontend"},"name":"webapp","namespace":"pup"},"spec":{"containers":[{"image":"nginx:1.22-alpine","name":"nginx"}],"dnsPolicy":"ClusterFirst","restartPolicy":"Always"}},{"apiVersion":"v1","kind":"Pod","metadata":{"labels":{"server":"backend"},"name":"microservice","namespace":"cat"},"spec":{"containers":[{"image":"node:16-alpine","name":"nodejs","args":["sleep","7200"]}],"dnsPolicy":"ClusterFirst","restartPolicy":"Always"}}]}' | kubectl apply -f - >/dev/null; echo 'lab: environment setup complete!'
-
Command to destroy environment:
kubectl delete ns cat pup
PersistentVolume (PV) is a piece of storage in the cluster that has been provisioned by an administrator or dynamically provisioned using Storage Classes, with a lifecycle independent of any individual Pod that uses the PV.
PersistentVolumeClaim (PVC) is a request for storage by a user. It is similar to a Pod. Pods consume node resources and PVCs consume PV resources. Claims can request specific size and access modes (ReadWriteOnce, ReadOnlyMany, ReadWriteMany, or ReadWriteOncePod).
- Pods connect to the PVC, and a PVC connects to the PV, both in a 1-1 relationship (only one PVC can connect to a PV)
- PVC can be created from an existing PVC
- PVC will remain in
STATUS=Pendinguntil it finds and connects to a matching PV and thusSTATUS=Bound - PV supports a number of raw block volumes
- ReadWriteOnce: volume can be mounted as read-write by a single node - allows multiple pods running on the node access the volume
- ReadOnlyMany: volume can be mounted as read-only by many nodes
- ReadWriteMany: volume can be mounted as read-write by many nodes
- ReadWriteOncePod: volume can be mounted as read-write by a single Pod
| PV attributes | PVC attributes |
|---|---|
| capacity | resources |
| volume modes | volume modes |
| access modes | access modes |
| storageClassName | storageClassName |
| mount options | selector |
| reclaim policy | |
| node affinity | |
| phase |
A StorageClass provides a way for administrators to describe the "classes" of storage they offer. It enables automatic PV provisioning to meet PVC requests, thus removing the need to manually create PVs. StorageClass must have a specified provisioner that determines what volume plugin is used for provisioning PVs.
- A PV with a specified
storageClassNamecan only be bound to PVCs that request thatstorageClassName - A PV with
storageClassNameattribute not set is intepreted as a PV with no class, and can only be bound to PVCs that request a PV with no class. - A PVC with
storageClassName=""(empty string) is intepreted as a PVC requesting a PV with no class. - A PVC with
storageClassNameattribute not set is not quite the same and behaves different whether theDefaultStorageClassadmission plugin is enabled- if the admission plugin is enabled, and a default StorageClass specified, all PVCs with no
storageClassNamecan be bound to PVs of that default - if a default StorageClass is not specified, PVC creation is treated as if the admission plugin is disabled
- if the admission plugin is disabled, all PVCs that have no
storageClassNamecan only be bound to PVs with no class
- if the admission plugin is enabled, and a default StorageClass specified, all PVCs with no
If a PVC doesn't find a PV with matching access modes and storage, StorageClass may dynamically create a matching PV
hostPathvolumes is created on the host, in minikube use theminikube sshcommand to access the host (requires starting the cluster with--driver=docker)
# list PVCs, PVs
kubectl get {pvc|pv|storageclass}
# view more details of a PVC
kubectl decribe {pvc|pv|storageclass} $NAME- Create a PV with 3Gi capacity using official docs
pods/storage/pv-volume.yamlmanifest file as base - Create a PVC requesting 1Gi capacity using official docs
pods/storage/pv-claim.yamlmanifest file as base - List created resources
- What
STATUSandVOLUMEdoes the PVC have? - Does the PVC use the existing PV and why or why not?
- What
- What happens when a PV and PVC are created without specifying a
StorageClass?- repeat steps 1-3 after removing
storageClassNamefrom both YAML files - what was the results?
- repeat steps 1-3 after removing
lab 10.1 solution
wget -q https://k8s.io/examples/pods/storage/pv-volume.yaml
wget -q https://k8s.io/examples/pods/storage/pv-claim.yaml
nano pv-volume.yaml
nano pv-claim.yaml# pv-volume.yaml
kind: PersistentVolume
spec:
storageClassName: manual
capacity:
storage: 3Gi
# pv-claim.yaml
kind: PersistentVolumeClaim
spec:
storageClassName: manual
resources:
requests:
storage: 1Gi
# etckubectl get pv,pvc # STATUS=Bound, task-pv-volume uses task-pv-claim
# when `storageClassName` is not specified, the StorageClass creates a new PV for the PVCThe benefit of configuring Pods with PVCs is to decouple site-specific details.
You can follow the official configure a Pod to use a PersistentVolume for storage docs to complete this lab.
- Create a
/mnt/data/index.htmlfile on cluster hostminikube sshwith some message, e.g. "Hello, World!" - Create a PV with the following parameters, see
https://k8s.io/examples/pods/storage/pv-volume.yaml- uses
hostPathstorage - allows multiple pods in the Node access the storage
- uses
- Create a Pod running a webserver to consume the storage, see
https://k8s.io/examples/pods/storage/pv-pod.yaml- uses PVC, see
https://k8s.io/examples/pods/storage/pv-claim.yaml - image is
httpdand default documentroot is/usr/local/apache2/htdocsor/var/www/html
- uses PVC, see
- Verify all resources created
pod,pv,pvc,storageclass, and also review each detailed information- review
STATUSfor PV and PVC - did the PVC in [3] bind to the PV in [2], why or why not?
- review
- Connect to the Pod via an interactive shell and confirm you can view the contents of cluster host file
curl localhost - Clean up all resources created
lab 10.2 solution
# host terminal
minikube ssh
# node terminal
sudo mkdir /mnt/data
sudo sh -c "echo 'Hello from Kubernetes storage' > /mnt/data/index.html"
cat /mnt/data/index.html
exit
# host terminal
echo --- > lab10-2.yaml
wget https://k8s.io/examples/pods/storage/pv-volume.yaml -O- >> lab10-2.yaml
echo --- >> lab10-2.yaml
wget https://k8s.io/examples/pods/storage/pv-claim.yaml -O- >> lab10-2.yaml
echo --- >> lab10-2.yaml
wget https://k8s.io/examples/pods/storage/pv-pod.yaml -O- >> lab10-2.yaml
echo --- >> lab10-2.yaml
nano lab10-2.yaml # edit the final file accordingly
kubectl apply -f lab10-2.yaml
kubectl get pod,pv,pvc,storageclass
kubectl describe pod,pv,pvc,storageclass | less
kubectl exec -it task-pv-pod -- /bin/bash
kubectl delete -f lab10-2.yamlFor further learning, see mounting the same persistentVolume in two places and access control
In the kid Namespace (create if required), create a Deployment webapp with two replicas, running the nginx:1.22-alpine image, that serves an index.html HTML document (see below) from the Cluster Node's /mnt/data directory. The HTML document should be made available via a Persistent Volume with 5Gi storage and no class name specified. The Deployment should use Persistent Volume claim with 2Gi storage.
<!-- index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>K8s Bootcamp (CKAD)</title>
</head>
<body>
<h1>Welcome to K8s Bootcamp!</h1>
</body>
</html>Variables can be specified via the command-line when creating a naked Pod with kubectl run mypod --image=nginx --env="MY_VARIABLE=myvalue". However naked Pods are not recommended in live environments, so our main focus is creating variables for deployments.
The kubectl create deploy command does not currently support the --env option, thus the easiest way to add variables to a deployment is to use kubectl set env deploy command after the deployment is created.
Note that doing
kubectl set env deploy --dry-run=clientwill only work if the deployment is already created
To generate a YAML file with variables via command-line, firstkubectl create deploy, thenkubectl set env deploy --dry-run=client -o yamland edit to remove unnecessary metadata and statuses
- Create a
dbDeployment usingmysqlimage - Troubleshoot and fix any deployment issues to get a running
STATUS - View more details of the Deployment and note where env-var is specified
- Review the Deployment in YAML form and note how the env-var is specified
- Create a
dbPod with an appropriate environment variable specified - Confirm Pod running as expected
- View more details of the Pod and note where env-var is specified
- Review the Pod in YAML form and note how the env-var is specified
- Delete created resources
lab11.1 solution
kubectl create deploy db --image=mysql
kubectl get po --watch # status=containercreating->error->crashloopbackoff->error->etc, ctrl+c to quit
kubectl describe po $POD_NAME # not enough info to find issue, so check logs
kubectl logs $POD_NAME|less # found issue, must specify one of `MYSQL_ROOT_PASSWORD|MYSQL_ALLOW_EMPTY_PASSWORD|MYSQL_RANDOM_ROOT_PASSWORD`
kubectl set env deploy db MYSQL_ROOT_PASSWORD=mysecret
kubectl get po # status=running
kubectl describe deploy db # review deployment env-var format
kubectl get deploy db -oyaml|less # review deployment env-var format
kubectl run db --image=mysql --env=MYSQL_ROOT_PASSWORD=mypwd
kubectl get po # status=running
kubectl describe deploy db # review pod env-var format
kubectl describe deploy,po db | grep -iEA15 "pod template:|containers:" | less # see `grep -h`
kubectl get po db -oyaml|less # review pod env-var format
kubectl delete deploy,po dbNote that you can use Pod fields as env-vars, as well as use container fields as env-vars
ConfigMaps are used to decouple configuration data from application code. The configuration data may be variables, files or command-line args.
- ConfigMaps should be created before creating an application that relies on it
- A ConfigMap created from a directory includes all the files in that directory and the default behaviour is to use the filenames as keys
# create configmap `mycm` from file or directory, see `kubectl create cm -h`
kubectl create configmap mycm --from-file=path/to/file/or/directory
# create configmap from file with specified key
kubectl create configmap mycm --from-file=key=path/to/file
# create configmap from a varibales file (file contains KEY=VALUE on each line)
kubectl create configmap mycm --from-env-file=path/to/file.env
# create configmap from literal values
kubectl create configmap mycm --from-literal=KEY1=value1 --from-literal=KEY2=value2
# display details of configmap `mycm`
kubectl describe cm mycm
kubectl get cm mycm -o yaml
# use configmap `mycm` in deployment `web`, see `kubectl set env -h`
kubectl set env deploy web --from=configmap/mycm
# use specific keys from configmap with mutliple env-vars, see `kubectl set env deploy -h`
kubectl set env deploy web --keys=KEY1,KEY2 --from=configmap/mycm
# remove env-var KEY1 from deployment web
kubectl set env deploy web KEY1-- Create a
file.envfile with the following content:MYSQL_ROOT_PASSWORD=pwd MYSQL_ALLOW_EMPTY_PASSWORD=true
- Create a File ConfigMap
mycm-filefrom the file using--from-fileoption - Create an Env-Var ConfigMap
mycm-envfrom the file using--from-env-fileoption - Compare details of both ConfigMaps, what can you find?
- Compare the YAML form of both ConfigMaps, what can you find?
- Create manifest files for the two Deployments with
mysqlimage using the ConfigMaps as env-vars:- a Deployment called
web-filefor ConfigMapmycm-file - a Deployment called
web-envfor ConfigMapmycm-env
- a Deployment called
- Review both manifest files to confirm if env-vars configured correctly, what did you find?
- any Deployment with correctly configured env-var?
- which ConfigMap was used for the working Deployment?
- Are you aware of the issue here?
- Create a Deployment with two env-vars from the working ConfigMap
- Connect a shell to a Pod from the Deployment and run
printenvto confirm env-vars - Create a Pod with env-vars from the working ConfigMap
- how will you set the env-vars for the Pod?
- Confirm Pod running or troubleshoot/fix any issues
- Connect a shell to the new Pod and run
printenvto confirm env-vars - Delete all created resources
lab11.2 solution
echo "MYSQL_ROOT_PASSWORD=mypwd
MYSQL_ALLOW_EMPTY_PASSWORD=true" > file.env
kubectl create cm mycm-file --keys=MYSQL_ROOT_PASSWORD,MYSQL_ALLOW_EMPTY_PASSWORD --from-file=file.env
kubectl create cm mycm-env --keys=MYSQL_ROOT_PASSWORD,MYSQL_ALLOW_EMPTY_PASSWORD --from-env-file=file.env
kubectl describe cm mycm-file mycm-env |less # mycm-file has one filename key while mycm-env has two env-var keys
kubectl get cm mycm-file mycm-env -oyaml|less
kubectl create deploy web-file --image=mysql --dry-run=client -oyaml > webfile.yml
kubectl apply -f webfile.yml # need an existing deployment to generate yaml for env-vars
kubectl set env deploy web-file --keys=MYSQL_ROOT_PASSWORD,MYSQL_ALLOW_EMPTY_PASSWORD --from=configmap/mycm-file --dry-run=client -oyaml
kubectl create deploy web-env --image=mysql --dry-run=client -oyaml | less # no output = keys not found in configmap
kubectl create deploy web-env --image=mysql --dry-run=client -oyaml > webenv.yml
kubectl apply -f webenv.yml # need an existing deployment to generate yaml for env-vars
kubectl set env deploy web-env --keys=MYSQL_ROOT_PASSWORD,MYSQL_ALLOW_EMPTY_PASSWORD --from=configmap/mycm-env --dry-run=client -oyaml|less # output OK and two env-var keys set
# copy the working env-var within the container spec to webenv.yml to avoid adding unnecessary fields
kubectl apply -f webenv.yml
kubectl get deploy,po # deployment web-env shows 1/1 READY, copy pod name
kubectl exec -it $POD_NAME -- printenv # shows MYSQL_ROOT_PASSWORD,MYSQL_ALLOW_EMPTY_PASSWORD
kubectl run mypod --image=mysql --dry-run=client -oyaml > pod.yml
kubectl apply -f pod.yml # need existing pod to generate yaml for env-vars
kubectl set env pod mypod --keys=MYSQL_ROOT_PASSWORD,MYSQL_ALLOW_EMPTY_PASSWORD --from=configmap/mycm-env --dry-run=client -oyaml|less
# copy env-var from output container spec to pod.yml to avoid clutter
kubectl delete -f pod.yml # naked pod cannot update env-var, only deployment
kubectl apply -f pod.yml
kubectl get all,cm # mypod in running state
kubectl exec -it mypod -- printenv
kubectl delete deploy,po,cm mycm-file mycm-env web-file web-env mypod
rm file.envIn the previous lab, only the Env-Var ConfigMap worked for our use-case. In this lab we will see how we can use the File ConfigMap.
You may also follow the offical add ConfigMap data to a Volume docs
- Create a
file.envfile with the following content:MYSQL_ROOT_PASSWORD=pwd
- Create a File ConfigMap
mycmfrom the file and verify resource details - Create a manifest file for a Pod with the following:
- uses
mysqlimage - specify an env-var
MYSQL_ROOT_PASSWORD_FILE=/etc/config/file.env, see the Docker Secrets section of MYSQL image - mount ConfigMap
mycmas a volume to/etc/config/, see Populate a volume with ConfigMap
- uses
- Create the Pod and verify all works and env-var set in container
- Create a
html/index.htmlfile with any content - Create a ConfigMap from the file and verify resource details
- Create a
webserverdeployment with an appropriate image and mount the file to the DocumentRoot via ConfigMap- option
nginxDocumentRoot - /usr/share/nginx/html - option
httpdDocumentRoot - /usr/local/apache2/htdocs
- option
- Connect a shell to the container and confirm your file is being served
- Delete created resources
lab11.3 solution
echo "MYSQL_ROOT_PASSWORD=pwd" > file.env
kubectl create cm mycm --from-file=file.env --dry-run=client -oyaml > lab11-3.yml
echo --- >> lab11-3.yml
kubectl run mypod --image=mysql --env=MYSQL_ROOT_PASSWORD_FILE=/etc/config/file.env --dry-run=client -oyaml >> lab11-3.yml
wget -qO- https://k8s.io/examples/pods/pod-configmap-volume.yaml | less # copy relevant details to lab11-3.yml
nano lab11-3.ymlkind: Pod
spec:
volumes:
- name: config-volume
configMap:
name: mycm
containers:
- name: mypod
volumeMounts:
- name: config-volume
mountPath: /etc/config
# etc, rest same as generatedkubectl apply -f lab11-3.yml
kubectl get po # mypod in running state
kubectl exec mypod -it -- printenv # shows MYSQL_ROOT_PASSWORD_FILE
# part 2 of lab
mkdir html
echo "Welcome to Lab 11.3 - Part 2" > html/index.html
kubectl create cm webcm --from-file=html/index.html
echo --- >> 11-3.yml
kubectl create deploy webserver --image=httpd --dry-run=client -oyaml > lab11-3.yml
nano lab11-3.yml # copy yaml format above and fix indentationkind: Deployment
spec:
template:
spec:
volumes:
- name: config-volume
configMap:
name: webcm
containers:
- name: httpd
volumeMounts:
- name: config-volume
mountPath: /usr/local/apache2/htdocskubectl get deploy,po # note pod name and running status
kubectl exec $POD_NAME -it -- ls /usr/local/apache2/htdocs # index.html
kubectl port-forward pod/$POD_NAME 3000:80 & # bind port 3000 in background
curl localhost:3000 # Welcome to Lab 11.3 - Part 2
fg # bring job to fore-ground, then ctrl+c to terminate
kubectl delete -f lab11-3.ymlPay attention to the types of ConfigMaps, File vs Env-Var, and also note their YAML form differences
Secrets are similar to ConfigMaps but specifically intended to hold sensitive data such as passwords, auth tokens, etc. By default, Kubernetes Secrets are not encrypted but base64 encoded.
To safely use Secrets, ensure to:
- Enable Encryption at Rest for Secrets.
- Enable or configure RBAC rules to
- restrict read/write
- limit access to create/replace secrets
- as files which may be mounted in Pods, e.g. accessing secret data in a Pod, TLS, etc
- consider using
defaultModewhen mounting secrets to set file permissions touser:readonly - 0400 - mounted secrets are automatically updated in the Pod when they change
- consider using
- as container environment variable which may be managed with
kubectl set env - as
image registry credentials, e.g. docker image registry creds
Secrets are basically encoded ConfigMaps and are both managed with
kubectlin a similar way, seekubectl create secret -hfor more details
# secret `myscrt` as file for tls keys, see `kubectl create secret tls -h`
kubectl create secret tls myscrt --cert=path/to/file.crt --key=path/to/file.key
# secret as file for ssh private key, see `kubectl create secret generic -h`
kubectl create secret generic myscrt --from-file=ssh-private-key=path/to/id_rsa
# secret as env-var for passwords, ADMIN_PWD=shush
kubectl create secret generic myscrt --from-literal=ADMIN_PWD=shush
# secrets as image registry creds, `docker-registry` works for other registry types
kubectl create secret docker-registry myscrt --docker-username=dev --docker-password=shush [email protected] --docker-server=localhost:3333
# view details of the secret, shows base64 encoded value
kubectl describe secret myscrt
kubectl get secret myscrt -o yaml
# view the base64 encoded contents of secret `myscrt`
kubectl get secret myscrt -o jsonpath='{.data}'
# for secret with nested data, '{"game":{".config":"yI6eyJkb2NrZXIua"}}'
kubectl get secret myscrt -o jsonpath='{.data.game.\.config}'
# decode secret ".config" in '{"game":{".config":"yI6eyJkb2NrZXIua"}}'
kubectl get secret myscrt -o jsonpath='{.data.game.\.config}' | base --decode
# get a service account `mysa`
kubectl get serviceaccount mysa -o yamlSee the Kubernetes JSONPath support docs to learn more about using
jsonpath
You may follow the official managing secrets using kubectl docs
- Review the CoreDNS Pod in the
kube-systemnamespace and determine itsserviceAccountName - Review the ServiceAccount and determine the name of the
Secretin use - View the contents of the
Secretand decode the value of its keys:ca.crtnamespaceandtoken.
lab11.4 solution
kubectl -nkube-system get po # shows name of coredns pod
kubectl -nkube-system get po $COREDNS_POD_NAME -oyaml | grep serviceAccountName
kubectl -nkube-system get sa $SERVICE_ACCOUNT_NAME -oyaml # shows secret name
kubectl -nkube-system get secret $SECRET_NAME -ojsonpath="{.data}" | less # shows the secret keys
kubectl -nkube-system get secret $SECRET_NAME -ojsonpath="{.data.ca\.crt}" | base64 -d # decode ca.crt, BEGIN CERTIFICATE... long string
kubectl -nkube-system get secret $SECRET_NAME -ojsonpath="{.data.namespace}" | base64 -d # decode namespace, kube-system
kubectl -nkube-system get secret $SECRET_NAME -ojsonpath="{.data.token}" | base64 -d # decode token, ey... long stringRepeat lab 11.2 with secrets
lab11.5 solution
# very similar to configmap solution, accepting pull-requestsRepeat lab 11.3 with secrets.
lab11.6 solution
# very similar to configmap solution, accepting pull-requests- Create a secret with the details of your docker credentials
- View more details of the resource created
kubectl describe - View details of the secret in
yaml - Decode the contents of the
.dockerconfigjsonkey withjsonpath
lab11.7 solution
# one-line command can be found in `kubectl create secret -h` examples, accepting pull-requestsThe latest Bootcamp cohort have requested a new database in the rig Namespace. This should be created as a single replica Deployment named db running the mysql:8.0.22 image with container named mysql. The container should start with 128Mi memory and 0.25 CPU but should not exceed 512Mi memory and 1 CPU.
The Resource limit values should be available in the containers as env-vars MY_CPU_LIMIT and MY_MEM_LIMIT for the values of the cpu limit and memory limit respectively. The Pod IP address should also be available as env-var MY_POD_IP in the container.
A Secret named db-secret should be created with variables MYSQL_DATABASE=bootcamp and MYSQL_ROOT_PASSWORD="shhhh!" to be used by the Deployment as the database credentials. A ConfigMap named db-config should be used to load the .env file (see below) and provide environment variable DEPLOY_ENVIRONMENT to the Deployment.
# .env
DEPLOY_CITY=manchester
DEPLOY_REGION=north-west
DEPLOY_ENVIRONMENT=stagingWhilst a Pod is running, the kubelet is able to restart containers to handle some kind of faults. Within a Pod, Kubernetes tracks different container states and determines what action to take to make the Pod healthy again. See Pod lifecycle for more details.
Pod states can be viewed with kubectl get pods under STATUS column:
- Pending - Pod starts here and waits to be scheduled, image download, etc
- Running - at least one container running
- Completed - all containers terminated successfully
- Failed - all containers have terminated, at least one terminated in failure
- CrashLoopbackOff - the Pod had failed and was restarted
- Terminating - the Pod is being deleted
- Unknown - pod state cannot be obtained, either node communication breakdown or other
A Pod's status field is a PodStatus object, which has a phase field that can have the values: Pending | Running | Succeeded | Failed | Unknown.
A probe is a diagnostic performed periodically by the kubelet on a container, either by executing code within the container, or by network request. A probe will either return: Success | Failure | Unknown. There are four different ways to check a container using a probe:
exec: executes a specified command within the container, status code 0 meansSuccess.grpc: performs a remote procedure call using gRPC, this feature is inalphastage (not for CKAD)httpGet: performs HTTP GET request against the Pod's IP on a specified port and path, status code greater than or equal to 200 and less than 400 meansSuccess.tcpSocket: performs a TCP check against the Pod's IP on a specified port, port is open meansSuccess, even if connection is closed immediately.
The kubelet can optionally perform and react to three kinds of probes on running containers:
livenessProbe: indicates if container is running, On failure, the kubelet kills the container which triggers restart policy. Defaults toSuccessif not set. See when to use liveness probe.readinessProbe: indicates if container is ready to respond to requests. On failure, the endpoints controller removes the Pod's IP address from the endpoints of all Services that match the Pod. Defaults toSuccessif not set. If set, starts asFailure. See when to use readiness probe?.startupProbe: indicates if application within container is started. All other probes are disabled if a startup probe is set, until it succeeds. On failure, the kubelet kills the container which triggers restart policy. Defaults toSuccessif not set. See when to use startup probe?.
For more details, see configuring Liveness, Readiness and Startup Probes
Many applications running for long periods of time eventually transition to broken states, and cannot recover except by being restarted. Kubernetes provides liveness probes to detect and remedy such situations.
You may follow the official define a liveness command tutorial to complete this lab.
# get events
kubectl get events
# get events of a specific resource, pod, deployment, etc
kubectl get events --field-selector=involvedObject.name=$RESOURCE_NAME
# watch events for updates
kubectl get events --watch- Using the official manifest file
pods/probe/exec-liveness.yamlas base, create a Deploymentmyappmanifest file as follows:- busybox image
- commandline arguments
mkdir /tmp/healthy; sleep 30; rm -d /tmp/healthy; sleep 60; mkdir /tmp/healthy; sleep 600; - a liveness probe that checks for the presence of
/tmp/healthydirectory - the Probe should be initiated 10secs after container starts
- the Probe should perform the checks every 10secs
the container creates a directory
/tmp/healthyon startup, deletes the directory 30secs later, recreates the directory 60secs later
your goal is to monitor the Pod behaviour/statuses during these events, you can repeat this lab until you understand liveness probes - Apply the manifest file to create the Deployment
- Review and monitor created Pod events for 3-5mins
- Delete created resources
lab12.1 solution
kubectl create deploy myapp --image=busybox --dry-run=client -oyaml -- /bin/sh -c "touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 60; touch /tmp/healthy; sleep 600;" >lab12-1.yml
wget -qO- https://k8s.io/examples/pods/probe/exec-liveness.yaml | less # copy the liveness probe section
nano lab12-1.yml # paste, edit and fix indentationkind: Deployment
spec:
template:
spec:
containers:
livenessProbe:
exec:
command:
- ls # `cat` for file
- /tmp/healthy
initialDelaySeconds: 10
periodSeconds: 10kubectl apply -f lab12-1.yml
kubectl get po # find pod name
kubectl get events --field-selector=involvedObject.name=$POD_NAME --watch
kubectl delete -f lab12-1.ymlProbes have a number of fields that you can use to more precisely control the behavior of liveness and readiness checks:
initialDelaySeconds: Seconds to wait after container starts before initiating liveness/readiness probes - default 0, minimum 0.periodSeconds: How often (in seconds) to perform the probe - default 10, minimum 1.timeoutSeconds: Seconds after which the probe times out - default 1, minimum 1.successThreshold: Number of consecutive successes after a failure for the probe to be considered successful - default 1, minimum 1, must be 1 for liveness/startup ProbesfailureThreshold: Number of consecutive retries on failure before giving up, liveness probe restarts the container after giving up, readiness probe marks the Pod as Unready - defaults 3, minimum 1.
Sometimes, applications are temporarily unable to serve traffic, for example, a third party service become unavailable, etc. In such cases, you don't want to kill the application, but you don't want to send it requests either. Kubernetes provides readiness probes to detect and mitigate these situations. Both readiness probe and liveness probe use similar configuration.
- Using the official manifest files
pods/probe/http-liveness.yamlas base, create a Deploymentmyappmanifest file as follows:nginx:1.22-alpineimage- 2 replicas
- a readiness probe that uses an HTTP GET request to check that the root endpoint
/on port 80 returns a success status code - the readiness probe should be initiated 3secs after container starts, and perform the checks every 5secs
- a liveness probe that uses an HTTP GET request to check that the root endpoint
/on port 80 returns a success status code - the liveness probe should be initiated 8secs after the container is ready, and perform checks every 6secs
- Apply the manifest file to create the Deployment
- View more details of the Deployment and:
- confirm how Probe configuration appear, note values for
delay | timeout | period | success | failure, how do you set these values? - review Events for probe-related entries
- note that no Events generated when Probes successful
- confirm how Probe configuration appear, note values for
- List running Pods
- View more details of one of the Pods and:
- confirm both probes are configured
- review Events for probe-related entries
- Lets trigger a probe failure to confirm all works, edit the Deployment and change readiness probe port to 8080
- Review more details of the Deployment and individual Pods and determine how Probe failures are recorded, on Deployment or Pod?
- Lets overload our Probe configuration, using official manifest
pods/probe/tcp-liveness-readiness.yamlas example, edit the Deployment as follows:- replace the readiness probe with one that uses TCP socket to check that port 80 is open
- the readiness probe should be initiated 5secs after container starts, and perform the checks every 10secs
- replace the liveness probe with one that uses TCP socket to check that port 80 is open
- the liveness probe should be initiated 15secs after the container starts, and perform checks every 10secs
- note that these changes trigger a rolling update - chainging parameters within
deploy.spec.template
- Review more details of one of the Pod
- Delete created resources
lab 12.2 solution
kubectl create deploy myapp --image=nginx:1.22-alpine --replicas=2 --dry-run=client -oyaml > lab12-2.yml
wget -qO- https://k8s.io/examples/pods/probe/http-liveness.yaml | less # copy probe section
nano lab12-2.yml # paste, fix indentation, edit correctlykind: Deployment
spec:
template:
spec:
containers:
- name: nginx
readinessProbe:
httpGet:
path: /
port: 80 # change this to 8080 in later steps
initialDelaySeconds: 3
periodSeconds: 5
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 8
periodSeconds: 6
# etckubectl apply -f lab12-2.yml
kubectl describe deploy myapp # review `Pod Template > Containers` and Events
kubectl get po
kubectl describe po $POD_NAME # review Containers and Events
KUBE_EDITOR=nano kubectl edit deploy myapp # change port to 8080 and save
kubectl describe deploy myapp # only shows rollout events
kubectl get po # get new pod names
kubectl describe po $NEW_POD_NAME # review Containers and Events
KUBE_EDITOR=nano kubectl edit deploy myapp # replace probes config with belowkind: Deployment
spec:
template:
spec:
containers:
- name: nginx
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 15
periodSeconds: 10
# etckubectl get po # get new pod names
kubectl describe po $ANOTHER_NEW_POD_NAME # review Containers and Events, no news is good news
kubectl delete -f lab12-2.ymlSometimes, you have to deal with legacy applications that might require additional startup time on first initialization. In such cases, it can be tricky to set up liveness probe without compromising the fast response to deadlocks that motivated such a probe. The trick is to set up a startup probe with the same command, HTTP or TCP check, with a failureThreshold * periodSeconds long enough to cover the worse case startup time.
- Using the official manifest files
pods/probe/http-liveness.yamlas base, create a Deploymentmyappmanifest file as follows:nginx:1.22-alpineimage- 2 replicas
- a readiness probe that uses an HTTP GET request to check that the root endpoint
/on port 80 returns a success status code - the readiness probe should be initiated 3secs after container starts, and perform the checks every 5secs
- a liveness probe that uses an HTTP GET request to check that the root endpoint
/on port 80 returns a success status code - the liveness probe should be initiated 8secs after the container is ready, and perform checks every 6secs
- a startup probe with the same command as the liveness probe but checks every 5secs up to a maximum of 3mins
- Apply the manifest file to create the Deployment
- View more details of the Deployment and confirm how all Probe configuration appear
- List running Pods
- View more details of one of the Pods and confirm how Probe configuration appear
- Delete created resources
lab 12.3 solution
kubectl create deploy myapp --image=nginx:1.22-alpine --replicas=2 --dry-run=client -oyaml > lab12-3.yml
nano lab12-3.yml # add probeskind: Deployment
spec:
template:
spec:
containers:
- name: nginx
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 3
periodSeconds: 5
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 8
periodSeconds: 6
startupProbe:
httpGet:
path: /
port: 80
periodSeconds: 5
failureThreshold: 36 # 5secs x 36 = 3mins
# etckubectl apply -f lab12-3.yml
kubectl describe deploy myapp
kubectl get po
kubectl describe po $POD_NAME
kubectl delete -f lab12-2.ymlBlue/green deployment is a update-strategy used to accomplish zero-downtime deployments. The current version application is marked blue and the new version application is marked green. In Kubernetes, blue/green deployment can be easily implemented with Services.
blue/green update strategy

- Create a
blueDeployment- three replicas
- image
nginx:1.19-alpine - on the cluster Node, create an HTML document
/mnt/data/index.htmlwith any content - mount the
index.htmlfile to the DocumentRoot as a HostPath volume
- Expose
blueDeployment on port 80 with Service namebg-svc - Verify created resources and test access with
curl - Create a new
greenDeployment using [1] as base- three replicas
- use a newer version of the image
nginx:1.21-alpine - on the cluster Node, create a new HTML document
/mnt/data2/index.htmlwith different content - mount the
index.htmlfile to the DocumentRoot as a HostPath volume
- Verify created resources and test access with
curl - Edit
bg-svcService Selector asapp=greento redirect traffic togreenDeployment - Confirm all working okay with
curl - Delete created resources
lab 12.4 solution
# host terminal
minikube ssh
# node terminal
sudo mkdir /mnt/data /mnt/data2
echo "This is blue deployment" | sudo tee /mnt/data/index.html
echo "Green deployment" | sudo tee /mnt/data2/index.html
exit
# host terminal
kubectl create deploy blue --image=nginx:1.19-alpine --replicas=3 --dry-run=client -oyaml>12-4.yml
nano 12-4.yml # add hostpath volume and pod template labelkind: Deployment
spec:
template:
spec:
containers:
volumeMounts:
- mountPath: /usr/share/nginx/html
name: testvol
volumes:
- name: testvol
hostPath:
path: /mnt/datakubectl apply -f lab12-4.yml
kubectl expose deploy blue --name=bg-svc --port=80
kubectl get all,ep -owide
kubectl run mypod --rm -it --image=nginx:alpine -- sh
# container terminal
curl bg-svc # This is blue deployment
exit
# host terminal
cp lab12-4.yml lab12-4b.yml
nano lab12-4b.yml # change `blue -> green`, hostpath `/mnt/data2`, image `nginx:1.21-alpine
kubectl apply -f lab12-4b.yml
kubectl edit svc bg-svc # change selector `blue -> green`
kubectl run mypod --rm -it --image=nginx:alpine -- sh
# container terminal
curl bg-svc # Green deployment
exit
kubectl delete -f lab12-4.yml,lab12-4b.ymlCanary deployment is an update strategy where updates are deployed to a subset of users/servers (canary application) for testing prior to full deployment. This is a scenario where Labels are required to distinguish deployments by release or configuration.
canary update strategy

- Create a webserver application
- three replicas
- Pod Template label
updateType=canary - use image
nginx:1.19-alpine - create an HTML document
index.htmlwith any content - mount the
index.htmlfile to the DocumentRoot as a ConfigMap volume
- Expose the Deployment on port 80 with Service name
canary-svc - Verify created resources and test access with
curl - Create a new application using [1] as base
- one replica
- Pod Template label
updateType=canary - use a newer version of the image
nginx:1.22-alpine - create a new HTML document
index.htmlwith different content - mount the
index.htmlfile to the DocumentRoot as a ConfigMap volume
- Verify created resources and confirm the Service targets both webservers
- Run multiple
curlrequests to the IP in [2] and confirm access to both webservers - Scale up the new webserver to three replicas and confirm all Pods running
- Scale down the old webserver to zero and confirm no Pods running
- Delete created resources
Scaling down to zero instead of deleting provides an easy option to revert changes when there are issues
lab 12.5 solution
# host terminal
kubectl create cm cm-web1 --from-literal=index.html="This is current version"
kubectl create deploy web1 --image=nginx:1.19-alpine --replicas=3 --dry-run=client -oyaml>12-5.yml
nano 12-5.yml # add configmap volume and pod template labelkind: Deployment
spec:
selector:
matchLabels:
app: web1
updateType: canary
template:
metadata:
labels:
app: web1
updateType: canary
spec:
containers:
volumeMounts:
- mountPath: /usr/share/nginx/html
name: testvol
volumes:
- name: testvol
configMap:
name: cm-web1kubectl apply -f lab12-5.yml
kubectl expose deploy web1 --name=canary-svc --port=80
kubectl get all,ep -owide
kubectl run mypod --rm -it --image=nginx:alpine -- sh
# container terminal
curl canary-svc # This is current version
exit
# host terminal
cp lab12-5.yml lab12-5b.yml
kubectl create cm cm-web2 --from-literal=index.html="New version"
nano lab12-5b.yml # change `web1 -> web2`, image `nginx:1.22-alpine`, replicas 1, add pod template label
kubectl apply -f lab12-5b.yml
kubectl get all,ep -owide # more ip addresses added to endpoint
kubectl run mypod --rm -it --image=nginx:alpine -- sh
# container terminal
watch "curl canary-svc" # both "New version" and "This is current version"
kubectl scale deploy web2 --replicas=3
kubectl get rs,po -owide
kubectl scale deploy web1 --replicas=0
kubectl get rs,po -owide
kubectl delete -f lab12-5.yml,lab12-5b.ymlYou have a legacy application legacy running in the dam Namespace that has a long startup time. Once startup is complete, the /healthz:8080 endpoint returns 200 status. If this application is down at anytime or starting up, this endpoint will return a 500 status. The container port for this application often changes and will not always be 8080.
Create a probe for the existing Deployment that checks the endpoint every 10secs, for a maximum of 5mins, to ensure that the application does not receive traffic until startup is complete. 20 secs after startup, a probe should continue to check, every 30secs, that the application is up and running, otherwise, the Pod should be killed and restarted anytime the application is down.
You do not need to test that the probes work, you only need to configure them. Another test engineer will perform all tests.
- Command to setup environment:
printf '\nlab: lab environment setup in progress...\n'; echo '{"apiVersion":"v1","kind":"List","items":[{"apiVersion":"v1","kind":"Namespace","metadata":{"name":"dam"}},{"apiVersion":"apps/v1","kind":"Deployment","metadata":{"labels":{"app":"legacy"},"name":"legacy","namespace":"dam"},"spec":{"replicas":1,"selector":{"matchLabels":{"app":"legacy"}},"template":{"metadata":{"labels":{"app":"legacy"}},"spec":{"containers":[{"args":["/server"],"image":"registry.k8s.io/liveness","name":"probes","ports":[{"containerPort":8080}]}],"restartPolicy":"OnFailure"}}}}]}' | kubectl apply -f - >/dev/null; echo 'lab: environment setup complete!'
- Command to destroy environment:
kubectl delete ns dam
In the hog Namespace, you will find a Deployment named high-app, and a Service named high-svc. It is currently unknown if these resources are working together as expected. Make sure the Service is a NodePort type exposed on TCP port 8080 and that you're able to reach the application via the NodePort.
Create a single replica Deployment named high-appv2 based on high-app.json file running nginx:1.18-alpine.
- Update
high-appv2Deployment such that 20% of all traffic going to existinghigh-svcService is routed tohigh-appv2. The total Pods betweenhigh-appandhigh-appv2should be 5. - Next, update
high-appandhigh-appv2Deployments such that 100% of all traffic going tohigh-svcService is routed tohigh-appv2. The total Pods betweenhigh-appandhigh-appv2should be 5.
Finally, create a new Deployment named high-appv3 based on high-app.json file running nginx:1.20-alpine with 5 replicas and Pod Template label box: high-app-new.
-
Update
high-svcService such that 100% of all incoming traffic is routed tohigh-appv3. -
Since
high-appv2Deployment will no longer be used, perform a cleanup to delete all Pods related tohigh-appv2only keeping the Deployment and ReplicaSet. -
Command to setup environment (also creates
high-app.jsonfile):printf '\nlab: environment setup in progress...\n'; echo '{"apiVersion":"v1","kind":"List","items":[{"apiVersion":"v1","kind":"Namespace","metadata":{"name":"hog"}},{"apiVersion":"v1","kind":"Service","metadata":{"labels":{"kit":"high-app"},"name":"high-svc","namespace":"hog"},"spec":{"ports":[{"port":8080,"protocol":"TCP","targetPort":8080}],"selector":{"box":"high-svc-child"}}}]}' | kubectl apply -f - >/dev/null; echo '{"apiVersion":"apps/v1","kind":"Deployment","metadata":{"labels":{"kit":"high-app"},"name":"high-app","namespace":"hog"},"spec":{"replicas":4,"selector":{"matchLabels":{"box":"high-app-child"}},"template":{"metadata":{"labels":{"box":"high-app-child"}},"spec":{"containers":[{"image":"nginx:1.15-alpine","name":"nginx","ports":[{"containerPort":80}]}]}}}}' > high-app.json; kubectl apply -f high-app.json >/dev/null; echo 'lab: environment setup complete!';
-
Command to destroy environment:
kubectl delete ns hog
When you deploy Kubernetes, you get a cluster. See Kubernetes cluster components for more details.
kubectl flow diagram

- kubectl forwards command to the API Server
- API Server validates the request and persists it to etcd
- etcd notifies the API Server
- API Server invokes the Scheduler
- Scheduler will lookup eligible nodes to run the pod and return that to the API Server
- API Server persists it to etcd
- etcd notifies the API Server
- API Server invokes the Kubelet in the corresponding node
- Kubelet talks to the Docker daemon using the API over the Docker socket to create the container
- Kubelet updates the pod status to the API Server (success or failure, failure invokes RestartPolicy)
- API Server persists the new state in etcd
Use kubectl api-resources | less for an overview of available API resources.
APIVERSIONv1core Kubernetes API groupapps/v1first extension to the core group- during deprecation/transition, multiple versions of the same resource may be available, e.g.
policy/v1andpolicy/v1beta1
NAMESPACEDcontrols visibility
The Kubernetes release cycle is 3 months and deprecated features are supported for a minimum of 2 release cycles (6 months). Respond to deprecation message swiftly, you may use
kubectl api-versionsto view a short list of API versions andkubectl explain --recursiveto get more details on affected resources.
The current API docs at time of writing ishttps://kubernetes.io/docs/reference/generated/kubernetes-api/v1.25/
The Kubernetes API server kube-apiserver is the interface to access all Kubernetes features, which include pods, services, replicationcontrollers, and others.
From within a Pod, the API server is accessible via a Service named kubernetes in the default namespace. Therefore, Pods can use the kubernetes.default.svc hostname to query the API server.
In our minikube lab so far, we have been working with direct access to a cluster node, which removes the need for kube-proxy. When using the Kubernetes CLI kubectl, it uses stored TLS certificates in ~/.kube/config to make secured requests to the kube-apiserver.
However, direct access is not always possible with K8s in the cloud. The Kubernetes network proxy kube-proxy runs on each node and make it possible to access kube-apiserver securely by other applications like curl or programmatically.
See the official so many proxies docs for the different proxies you may encounter when using Kubernetes.
# view a more verbose pod detais
kubectl --v=10 get pods
# start kube-proxy
kubectl proxy --port=PORT
# explore the k8s API with curl
curl localhost:PORT/api
# get k8s version with curl
curl localhost:PORT/version
# list pods with curl
curl localhost:PORT/api/v1/namespaces/default/pods
# get specific pod with curl
curl localhost:PORT/api/v1/namespaces/default/pods/$POD_NAME
# delete specific pod with curl
curl -XDELETE localhost:PORT/api/v1/namespaces/default/pods/$POD_NAMETwo things are required to access a cluster - the location of the cluster and the credentials to access it. Thus far, we have used kubectl to access the API by running kubectl commands. The location and credentials that kubectl uses were automatically configured by Minikube during our Minikube environment setup.
Run kubectl config view to see the location and credentials configured for kubectl.
kubectl config view

Rather than run kubectl commands directly, we can use kubectl as a reverse proxy to provide the location and authenticate requests. See access the API using kubectl proxy for more details.
You may follow the official accessing the rest api docs
- Expose the API with
kube-proxy - Confirm k8s version information with
curl - Explore the k8s API with curl
- Create a deployment
- List the pods created with
curl - Get details of a specific pod with
curl - Delete the pod with
curl - Confirm pod deletion
kubectl provides the auth can-i subcommand for quickly querying the API authorization layer.
# check if deployments can be created in a namespace
kubectl auth can-i create deployments --namespace dev
# check if pods can be listed
kubectl auth can-i get pods
# check if a specific user can list secrets
kubectl auth can-i list secrets --namespace dev --as daveJust as user accounts identifies humans, a service account identifies processes running in a Pod.
- Service Accounts are the recommended way to authenticate to the API server within the k8s cluster
- A Pod created without specifying a ServiceAccount is automatically assigned the
defaultServiceAccount - When a new ServiceAccount is created, a Secret is auto-created to hold the credentials required to access the API server
- The ServiceAccount credentials of a Pod are automounted with the Secret in each container within the Pod at:
- token
/var/run/secrets/kubernetes.io/serviceaccount/token - certificate (if available)
/var/run/secrets/kubernetes.io/serviceaccount/ca.crt - default namespace
/var/run/secrets/kubernetes.io/serviceaccount/namespace
- token
- You can opt out of automounting API credentials for a ServiceAccount by setting
automountServiceAccountToken: falseon the ServiceAccount. Note that the pod spec takes precedence over the service account if both specify aautomountServiceAccountTokenvalue
This requires using the token of the default ServiceAccount. The token can be read directly (see lab 11.4 - decoding secrets), but the recommended way to get the token is via the TokenRequest API.
You may follow the official access the API without kubectl proxy docs.
- Request the ServiceAccount token by YAML. You can also request by
kubectl create token $SERVICE_ACCOUNT_NAMEon Kubernetes v1.24+. - Wait for the token controller to populate the Secret with a token
- Use
curlto access the API with the generated token as credentials
lab 13.2 solution
# request token
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: default-token
annotations:
kubernetes.io/service-account.name: default
type: kubernetes.io/service-account-token
EOF
# confirm token generated (optional)
kubectl get secret default-token -o yaml
# use token
APISERVER=$(kubectl config view --minify -o jsonpath='{.clusters[0].cluster.server}')
TOKEN=$(kubectl get secret default-token -o jsonpath='{.data.token}' | base64 --decode)
curl $APISERVER/api --header "Authorization: Bearer $TOKEN" --insecureUsing
curlwith the--insecureoption skips TLS certificate validation
You may follow the official access the API from within a Pod docs.
From within a Pod, the Kubernetes API is accessible via the
kubernetes.default.svchostname
- Connect an interactive shell to a container in a running Pod (create one or use existing)
- Use
curlto access the API atkubernetes.default.svc/apiwith the automounted ServiceAccount credentials (tokenandcertificate) - Can you access the Pods list at
kubernetes.default.svc/api/v1/namespaces/default/pods?
lab 13.3 solution
# connect an interactive shell to a container within the Pod
kubectl exec -it $POD_NAME -- /bin/sh
# use token stored within container to access API
SA=/var/run/secrets/kubernetes.io/serviceaccount
CERT_FILE=$($SA/ca.crt)
TOKEN=$(cat $SA/token)
curl --cacert $CERT_FILE --header "Authorization: Bearer $TOKEN" https://kubernetes.default.svc/apiRole-based access control (RBAC) is a method of regulating access to computer or network resources based on the roles of individual users within your organization. RBAC authorization uses the rbac.authorization.k8s.io API group for dynamic policy configuration through the Kubernetes API. RBAC is beyond CKAD, however, a basic understanding of RBAC can help understand ServiceAccount permissions.
The RBAC API declares four kinds of Kubernetes object: Role, ClusterRole, RoleBinding and ClusterRoleBinding.
- Role is a namespaced resource; when you create a Role, you have to specify its namespace
- ClusterRole, by contrast, is a non-namespaced resource
- RoleBinding grants the permissions defined in a Role/ClusterRole to a user or set of users within a specific namespace
- ClusterRoleBinding grants permissions that access cluster-wide.
The Default RBAC policies grant scoped permissions to control-plane components, nodes, and controllers, but grant no permissions to service accounts outside the kube-system namespace (beyond discovery permissions given to all authenticated users).
There are different ServiceAccount permission approaches, but we will only go over two:
- Grant a role to an application-specific service account (best practice)
- requires the
serviceAccountNamespecified in the pod spec, and for the ServiceAccount to have been created
- requires the
- Grant a role to the
defaultservice account in a namespace- permissions given to the
defaultservice account are available to any pod in the namespace that does not specify aserviceAccountName. This is a security concern in live environments without RBAC
- permissions given to the
# create a service account imperatively
kubectl create service account $SERVICE_ACCOUNT_NAME
# assign service account to a deployment
kubectl set serviceaccount deploy $DEPLOYMENT_NAME $SERVICE_ACCOUNT_NAME
# create a role that allows users to perform get, watch and list on pods, see `kubectl create role -h`
kubectl create role $ROLE_NAME --verb=get --verb=list --verb=watch --resource=pods
# grant permissions in a Role to a user within a namespace
kubectl create rolebinding $ROLE_BINDING_NAME --role=$ROLE_NAME --user=$USER --namespace=$NAMESPACE
# grant permissions in a ClusterRole to a user within a namespace
kubectl create rolebinding $ROLE_BINDING_NAME --clusterrole=$CLUSTERROLE_NAME --user=$USER --namespace=$NAMESPACE
# grant permissions in a ClusterRole to a user across the entire cluster
kubectl create clusterrolebinding $CLUSTERROLE_BINDING_NAME --clusterrole=$CLUSTERROLE_NAME --user=$USER
# grant permissions in a ClusterRole to an application-specific service account within a namespace
kubectl create rolebinding $ROLE_BINDING_NAME --clusterrole=$CLUSTERROLE_NAME --serviceaccount=$NAMESPACE:$SERVICE_ACCOUNT_NAME --namespace=$NAMESPACE
# grant permissions in a ClusterRole to the "default" service account within a namespace
kubectl create rolebinding $ROLE_BINDING_NAME --clusterrole=$CLUSTERROLE_NAME --serviceaccount=$NAMESPACE:default --namespace=$NAMESPACEIn lab 13.3 we were unable to access the PodList API at kubernetes.default.svc/api/v1/namespaces/default/pods. Lets apply the required permissions to make this work.
- Create a ServiceAccount and verify
- Create a Role with permissions to list pods and verify
- Create a RoleBinding that grants the Role permissions to the ServiceAccount, within the
defaultnamespace, and verify - Create a "naked" Pod bound to the ServiceAccount
- Connect an interactive shell to the Pod and use
curlto PodList API - Can you access the API to get a specific Pod like the one you're running? Hint: Role permissions
- Can you use a deployment instead of a "naked" Pod?
lab 13.4 solution
# create service account yaml
kubectl create serviceaccount test-sa --dry-run=client -o yaml > lab13-4.yaml
echo --- >> lab13-4.yaml
# create role yaml
kubectl create role test-role --resource=pods --verb=list --dry-run=client -o yaml >> lab13-4.yaml
echo --- >> lab13-4.yaml
# create rolebinding yaml
kubectl create rolebinding test-rolebinding --role=test-role --serviceaccount=default:test-sa --namespace=default --dry-run=client -o yaml >> lab13-4.yaml
echo --- >> lab13-4.yaml
# create configmap yaml
kubectl create configmap test-cm --from-literal="SA=/var/run/secrets/kubernetes.io/serviceaccount" --dry-run=client -o yaml >> lab13-4.yaml
echo --- >> lab13-4.yaml
# create pod yaml
kubectl run test-pod --image=nginx --dry-run=client -o yaml >> lab13-4.yaml
# review & edit yaml to add configmap and service account in pod spec, see `https://k8s.io/examples/pods/pod-single-configmap-env-variable.yaml`
nano lab13-4.yaml
# create all resources
kubectl apply -f lab13-4.yaml
# verify resources
kubectl get sa test-sa
kubectl describe sa test-sa | less
kubectl get role test-role
kubectl describe role test-role | less
kubectl get rolebinding test-rolebinding
kubectl describe rolebinding test-rolebinding | less
kubectl get configmap test-cm
kubectl describe configmap test-cm | less
kubectl get pod test-pod
kubectl describe pod test-pod | less
# access k8s API from within the pod
kubectl exec -it test-pod -- bash
TOKEN=$(cat $SA/token)
HEADER="Authorization: Bearer $TOKEN"
curl -H $HEADER https://kubernetes.default.svc/api --insecure
curl -H $HEADER https://kubernetes.default.svc/api/v1/namespaces/default/pods --insecure
curl -H $HEADER https://kubernetes.default.svc/api/v1/namespaces/default/pods/$POD_NAME --insecure
curl -H $HEADER https://kubernetes.default.svc/api/v1/namespaces/default/deployments --insecure
exit
# clean up
kubectl delete -f lab13-4.yamlThere are thousands of people and companies packaging their applications for deployment on Kubernetes. A best practice is to package these applications as Helm Charts.
Helm is a package manager you can install, like winget, npm, yum and apt, and Charts are packages stored locally or on remote Helm repositories, like msi, debs and rpms.
# helm installation steps
VER=$(curl -s https://api.github.com/repos/helm/helm/releases/latest | grep tag_name | cut -d '"' -f 4 | sed 's/v//g')
wget https://get.helm.sh/helm-v$VER-linux-amd64.tar.gz # macOS replace with `darwin-amd64`
tar xvf helm-v3.9.3-linux-amd64.tar.gz
sudo install linux-amd64/helm /usr/local/bin
rm helm-v$VER-linux-amd64.tar.gz
helm versionArtifactHUB is a Helm Charts registry, like docker hub or the npm registry, used to find, install and publish Charts.
# add a helm repo
helm repo add $RELEASE_NAME $RELEASE_URL
# install helm chart from an added repo
helm install $RELEASE_NAME $RELEASE_NAME/$CHART_NAME
# list helm repo
helm repo list
# search for charts in a repo
helm search repo $RELEASE_NAME
# update helm repos (running update command after adding new repo is good practice)
helm repo update
# list currently installed charts
helm list
# show details of a chart
helm show chart $RELEASE_NAME/$CHART_NAME
helm show all $RELEASE_NAME/$CHART_NAME
# view status of a chart
helm status $CHART_NAME
# delete currently installed charts
helm delete
# uninstall helm chart
helm uninstall $RELEASE_NAME- Install Helm
- List installed Helm Charts
- List installed Helm repos
- Find and install a Chart from ArtifactHUB
- View resources created in your cluster by the Helm Chart
- Update Helm repo
- List installed Helm Charts
- List installed Helm repos
- View details of installed Chart
- View status of installed Chart
- Search for available Charts in added Helm repo
Helm Charts come with preset configuration stored in a YAML file, some of which may not be of use to you. One powerful feature of Helm is the option to customise the base chart configuration before installation.
# view chart preset configuration
helm show values $RELEASE_NAME/$CHART_NAME | less
# download a copy of a chart configuation file
helm pull $RELEASE_NAME/$CHART_NAME
# verify a chart template
helm template --debug /path/to/template/directory
# install chart from template
helm install -f /path/to/values.yaml {$NAME|--generate-name} /path/to/template/directory
# working with {tar,tar.gz,tgz,etc} archives, see `tar --help`
# extract tar file to current directory, `-x|--extract`, `-v|--verbose, `-f|--file`
tar -xvf file.tgz
# extract tar file to specified directory, `-C|--directory`
tar -xvf file.tgz -C /path/to/directory
# list contents of a tar file, `-t|--list`
tar -tvf file.tar- Download a Chart template and extract the content to a specified directory
- Edit the template and change any value
- Verify the edited template
- Install the edited template
- View resources created by the Helm Chart
- List installed Charts
- List installed Helm repos
Kustomize is a Kubernetes standalone tool to customize Kubernetes resources through a kustomization.yaml file.
Kustomize is not currently part of the CKAD curriculum but good to know for general DevOps practice.
Kustomize can manage configuration files in three ways:
-
generating resources from other sources, e.g. generate with
secretGeneratorandconfigMapGeneratorconfigmap generator example
cat <<EOF >./kustomization.yaml configMapGenerator: - name: example-configmap-2 literals: - FOO=Bar EOF
-
composing and customising collections of resources, e.g. composing two resources together or adding a patch, see example:
composing & customising example
cat <<EOF >./kustomization.yaml resources: - deployment.yaml # uses 1 replica - service.yaml patchesStrategicMerge: - patch.yaml # change Deployment to 3 replicas EOF
-
setting cross-cutting fields for resources, e.g. setting same namespaces, name prefix/suffix, labels or annotations to all resources
cross-cutting fields example
cat <<EOF >./kustomization.yaml namespace: my-namespace namePrefix: dev- nameSuffix: "-001" commonLabels: app: bingo commonAnnotations: oncallPager: 800-555-1212 resources: - deployment.yaml - service.yaml EOF
# create resources from a kustomization file
kubectl apply -k /path/to/directory/containing/kustomization.yaml
# view resources found in a directory containing a kustomization file
kubectl kustomize /path/to/directory/containing/kustomization.yaml
# view resources found in a directory containing a kustomization file
kubectl kustomize /path/to/directory/containing/kustomization.yamlWe can take advantage of Kustomization's "composing and customising" feature to create deployment pipelines by using a directory layout where multiple overlay kustomizations (variants) refer to a base kustomization:
pipeline layout example
├── base
│ ├── deployment.yaml
│ ├── kustomization.yaml
│ └── service.yaml
└── overlays
├── dev
│ ├── kustomization.yaml # `bases: ['../../base']`, `namePrefix: dev-`
│ └── patch.yaml
├── prod
│ ├── kustomization.yaml # `bases: ['../../base']`, `namePrefix: prod-`
│ └── patch.yaml
└── staging
├── kustomization.yaml # `bases: ['../../base']`, `namePrefix: staging-`
└── patch.yaml- Create a
service.yamlresource file for a service - Create a
deployment.yamlresource file for an app using the service - Create a
kustomization.yamlfile with name prefix/suffix and common labels for both resource files - Apply the Kustomization file to create the resources
- Review resources created and confirm that the prefix/suffix and labels are applied
A Resource is an endpoint in the Kubernetes API that stores a collection of API objects of a certain kind; for example, the Pods resource contains a collection of Pod objects.
A Custom Resource is an extension of the Kubernetes API that is not necessarily available in a default Kubernetes installation. Many core Kubernetes functions are now built using custom resources, making Kubernetes more modular.
Although, we only focus on one, there are two ways to add custom resources to your cluster:
- CRDs allows user-defined resources to be added to the cluster. They are simple and can be created without any programming. In reality, Operators are preferred to CRDs.
- API Aggregation requires programming, but allows more control over API behaviors like how data is stored and conversion between API versions.
# CRD example "resourcedefinition.yaml"
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: crontabs.stable.example.com # must match `<plural>.<group>` spec fields below
spec:
group: stable.example.com # REST API: /apis/<group>/<version>
versions: # list of supported versions
- name: v1
served: true # enabled/disabled this version, controls deprecations
storage: true # one and only one version must be storage version.
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
image:
type: string
replicas:
type: integer
scope: Namespaced # or Cluster
names:
plural: crontabs # REST API: /apis/<group>/<version>/<plural>
singular: crontab # used for display and as alias on CLI
kind: CronTab # CamelCased singular type for resource manifests.
shortNames:
- ct # allow `crontab|ct` to match this resource on CLIYou can follow the official CRD tutorial.
- Create a custom resource from the snippet above
- Confirm a new API resource added
- Create a custom object of the custom resource
apiVersion: "stable.example.com/v1" kind: CronTab metadata: name: my-new-cron-object spec: cronSpec: "* * * * */5" image: my-awesome-cron-image
- Review all resources created and confirm the
shortNameworks - Directly access the Kubernetes REST API and confirm endpoints for:
- group
/apis/<group> - version
/apis/<group>/<version> - plural
/apis/<group>/<version>/<plural>
- group
- Clean up by deleting with the manifest files
Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. The operator pattern captures how you can write code to automate a task beyond what Kubernetes itself provides.
Kubernetes' operator pattern concept lets you extend the cluster's behaviour without modifying the code of Kubernetes itself by linking controllers (a non-terminating loop, or control loop, that regulates the cluster to a desired state) to one or more custom resources. Operators are clients of the Kubernetes API that act as controllers for a Custom Resource.
Although, you can write your own operator, majority prefer to find ready-made operators on community websites like OperatorHub.io. Many Kubernetes solutions are provided as operators like Prometheus or Tigera (calico).
This lab requires the Calico plugin. You will need to delete and start a new cluster if your current one doesn't support Calico
See the official Calico install steps.
# 1. start a new cluster with network `192.168.0.0/16` or `10.10.0.0/16` whichever subnet is free in your network
minikube start --kubernetes-version=1.23.9 --network-plugin=cni --extra-config=kubeadm.pod-network-cidr=10.10.0.0/16
# 2. install tigera calico operator
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.24.0/manifests/tigera-operator.yaml
# 3. install custom resource definitions
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.24.0/manifests/custom-resources.yaml
# 4. view an installation resource
kubectl get installation -o yaml | less
# 5. verify calico installation
watch kubectl get pods -l k8s-app=calico-node -A
# you can use wget to view a file without saving
wget -O- https://url/to/file | less
wget -qO- https://url/to/file | less # quiet mode- Start a Minikube cluster with the
cninetwork plugin and a suitable subnet - List existing namespaces
- Install the Tigera Calico operator
- Confirm resources added:
- new API resources for
tigera - new namespaces
- resources in the new namespaces
- new API resources for
- Review the CRDs manifest file and ensure matching
cidr, then install - Confirm resources added:
- new
Installationresource - new namespaces
- resources in the new namespaces (Calico Pods take awhile to enter
Runningstatus)
- new
StatefulSet is similar to Deployments but provides guarantees about the ordering and uniqueness of managed Pods. Unlike Deployments, StatefulSet Pods are not interchangeable: each has a persistent identifier and storage volume that it maintains across any rescheduling.
StatefulSets are valuable for applications that require one or more of the following.
- Stable - persistence across Pod (re)scheduling, unique network identifiers.
- Stable, persistent storage.
- Ordered, graceful deployment and scaling.
- Ordered, automated rolling updates.
- Storage must either be provisioned by a PersistentVolume Provisioner based on StorageClass, or pre-provisioned by an admin
- To ensure data safety, deleting and/or scaling a StatefulSet down will not delete associated volumes
- You are responsible for creating a Headless Service to provide network access to the Pods
- To achieve ordered and graceful termination of Pods, scale the StatefulSet down to 0 prior to deletion
- It's possible to get into a broken state that requires manual repair when using Rolling Updates with the default Pod Management Policy (
OrderedReady)
See the example manifest
- Create a StatefulSet based on the example manifest
- Verify resources created and compare to a regular deployment
- Confirm persistent volume claims created
In the Certified Kubernetes Application Developer (CKAD) exam, you are expected to solve about 15 questions in 2 hours. What makes this exam difficult is the time required to verify all your answers. Just providing a solution to a question is not enough, you must always test that your solutions work as expected, otherwise, you are guaranteed to fail.
Please read through the kubectl cheat sheet before taking the exam.
The Tasks provided in this bootcamp require more time to solve than standard exam question, which makes them more difficult. Therefore, you can simulate an exam by completing all Tasks under 2 hours.
In addition, after paying for the exam, you will be provided access to an exam simulation from Killer.sh which you can attempt twice. The simulation environment will be similar to the exam environment, and the questions are also similar in difficulty to exam questions. However, you will need to solve about 20 questions in the same time, which makes the simulation more difficult.
If you are able to complete all 16 Tasks provided here under 2 hours, you will find that you are also able to complete Killer exam simulation under 2 hours. This is all the confidence you need to pass your CKAD exam, you really don't need anything else.
Remember to use the rest of the tips below during your simulation!
Tasks: Docker image | Pods | Pods II | CronJobs | Resources and Security Context | Deployment | Service | Service II | Ingress | Network policy | Persistent volumes | ConfigMap and Secrets | Probes | Zero Downtime Updates | Service account | Helm
As soon as your exam starts, you will want to setup kubectl and your chosen text editor as follows:
- Setup
kubectlalias k=kubectl # this is usually preconfigured in exam export dr="--dry-run=client -oyaml"
- Setup text editor
# vim printf "set tabstop=2\nset shiftwidth=2\nset expandtab" > ~/.vimrc # nano printf "set tabsize 2\nset tabstospaces" > ~/.nanorc
Questions use different Clusters and different Namespaces. Therefore, for each question:
- Make sure you always run the command to switch to the Cluster for that question - command will be provided
- Create a variable for the question's Namespace
ns=$QUESTION_NAMESPACEto make things easy for yourself - Do not assume the default Namespace is
default, always set and use your variablens=default
# example using variable/alias
k create deploy webapp --image=nginx:alpine $dr $ns > 2.ymlRemember that copy/paste works different in a terminal:
- Copy - right click on mouse or two finger tap on touchpad (or check your touchpad settings if different)
- Paste - right click on mouse or two finger tap on touchpad
Get familiar with your text editor to improve your speed:
- Use search and replace for bulk changes (assume
^C = Ctrl+CandM-C = Alt+C)- vim:
:s/foo/bar/g- find eachfooin current line and replace withbar:s/foo/bar/g- find eachfooin all lines and replace withbar
- nano:
- press keyboard
^\ - type search word and hit
Enter - type replacement word and hit
Enter - press
Yto replace a match,Nto skip a match,Ato replace all matches
- press keyboard
- vim:
- Indent multiple lines using markers - in many situations, you might want to copy Pod YAML into a Deployment YAML or vice-versa
- vim (indent size =
shiftwidth):- move cursor to the start/end of lines
- press keyboard
Vto enter visual mode - press arrow keys up/down/left/right to highlight text in arrow direction
- to indent highlighted text forwards, press
>to indent once, or3>to indent 3 times - to indent highlighted text backwards, press
<to indent once, or4<to indent 4 times
- nano (indent size =
tabsize):- move cursor to the start/end of lines
- press keyboard
M-Ato set mark - press arrow up/down/left/right to highlight text in arrow direction
- to indent highlighted text, press
TABto indent forwards orSHIFT+TABto indent backwards - press keyboard
M-Aagain to unset mark
- vim (indent size =
- Undo/Redo
- vim: in normal mode
:undoto undo last change,^Rto redo - nano:
M-Uto undo,M-Eto redo
- vim: in normal mode
This is not a bootcamp on
vimornano, there are more flashy magic you can achieve with these tools, especiallyvim, but the above should get you through CKAD!
Do not begin your exam from Question 1! Each question has a Task Weight and you should aim to complete higher score questions first.
When your exam starts, and after going through the other setup above, you will want to review all your questions to create a question-to-score-grid to help you decide the best order to answer them. See the scenarios below:
# scenario 1, 5-by-x grid to easily identify questions - lines ends in multiples of 5: Q5, Q10, Q15, etc
4 4 4 8 4
8 4 4 8 8
4 8 8 8 8
8
# Start from Q9-Q16, then Q1-Q8# scenario 2, 5-by-x grid to easily identify questions - lines ends in multiples of 5: Q5, Q10, Q15, etc
1 2 2 5 3
7 4 4 5 4
7 8 6 4 5
6 4 4 9
# Start from Q11-Q19, then Q4-Q10, then Q1-Q3Store the grid in a Text Editor. When you encounter a troublesome question and its been more than 5mins without a clear idea of solution, update the question on the grid with an asterix and move on. Trust me, you do not want to waste additional 2mins on a question you will fail when you can answer another question in the same time!
# update troublesome questions with * and return to them after completing all other questions
4 4 4 8 4
8 4 4 8* 8
4 8 8* 8 8
8Best of luck 👍 and please star this repo to say thank you!