Botasaurus Proxy Authentication provides SSL support for authenticated proxies.
Proxy providers like BrightData, IPRoyal, and others typically provide authenticated proxies in the format "http://username:password@proxy-provider-domain:port". For example, "http://greyninja:[email protected]:12321".
However, if you use an authenticated proxy with a library like seleniumwire to scrape a Cloudflare protected website like G2.com, you will surely be blocked because you are using a non-SSL connection.
To verify this, run the following code:
First, install the necessary packages:
python -m pip install selenium_wire chromedriver_autoinstallerThen, execute this Python script:
from seleniumwire import webdriver
from chromedriver_autoinstaller import install
# Define the proxy
proxy_options = {
'proxy': {
'http': 'http://username:password@proxy-provider-domain:port', # TODO: Replace with your own proxy
'https': 'http://username:password@proxy-provider-domain:port', # TODO: Replace with your own proxy
}
}
# Install and set up the driver
driver_path = install()
driver = webdriver.Chrome(driver_path, seleniumwire_options=proxy_options)
# Navigate to the desired URL
driver.get("https://ipinfo.io/")
# Prompt for user input
input("Press Enter to exit...")
# Clean up
driver.quit()You will definetely encounter a block by Cloudflare:
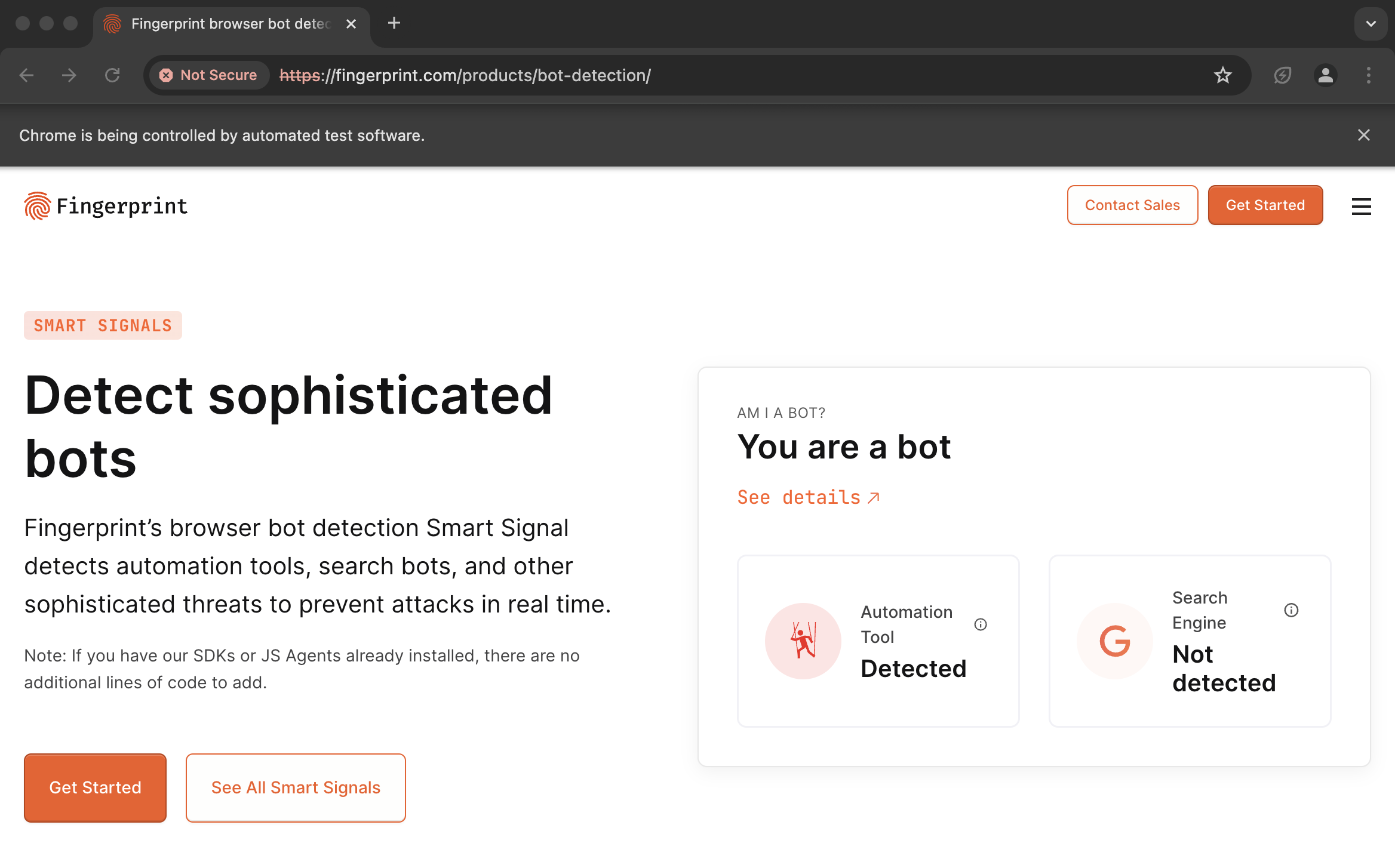
However, using proxies with botasaurus_proxy_authentication prevents this issue. See the difference by running the following code:
First, install the necessary packages:
python -m pip install botasaurusThen, execute this Python script:
from botasaurus import *
@browser(proxy="http://username:password@proxy-provider-domain:port") # TODO: Replace with your own proxy
def scrape_heading_task(driver: AntiDetectDriver, data):
driver.get("https://ipinfo.io/")
driver.prompt()
scrape_heading_task() Result:
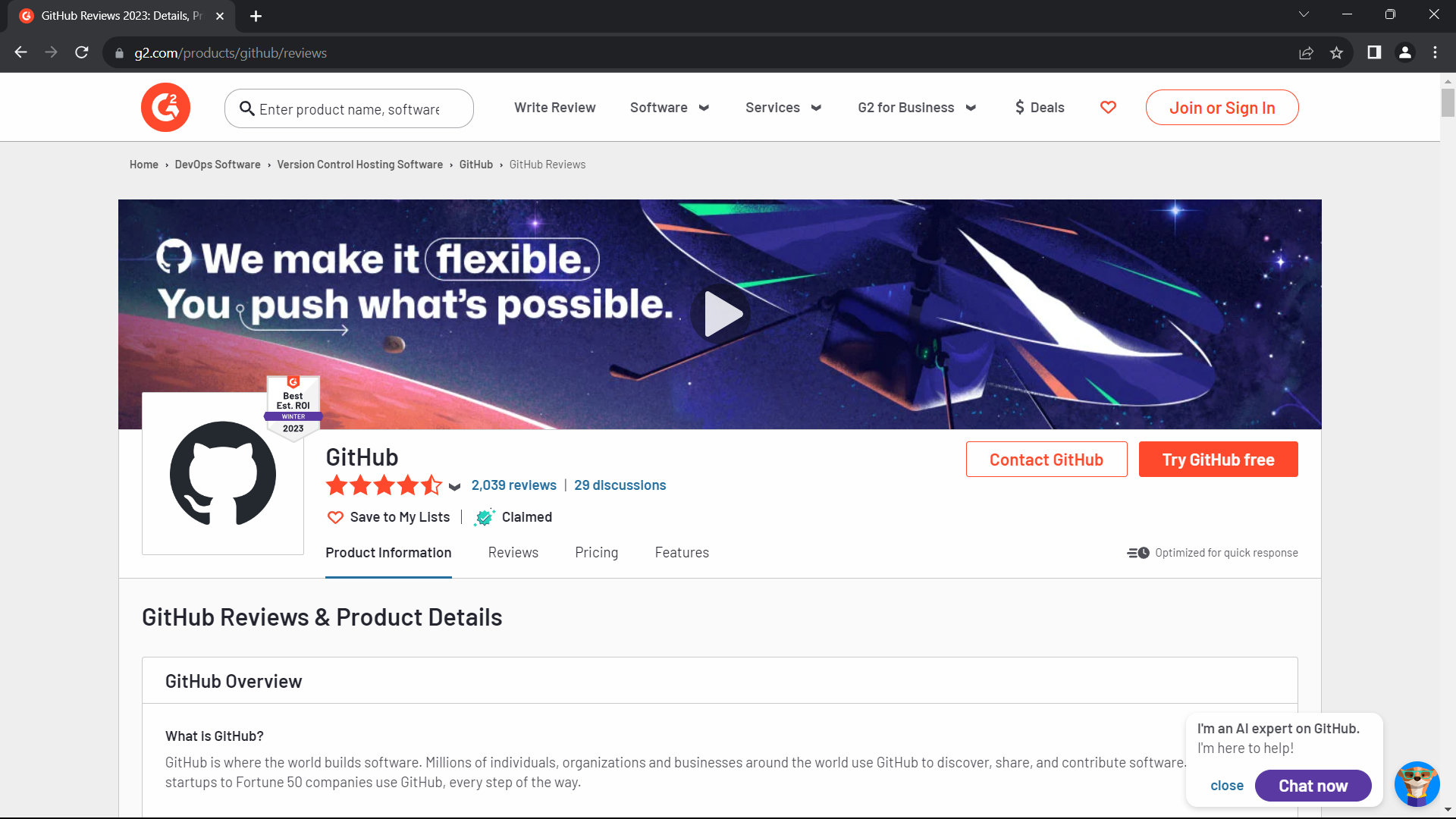
NOTE: To run the code above, you will need Node.js installed.
from botasaurus import *
@browser(proxy="http://username:password@proxy-provider-domain:port") # TODO: Replace with your own proxy
def visit_ipinfo(driver: AntiDetectDriver, data):
driver.get("https://ipinfo.io/")
driver.prompt()
visit_ipinfo() from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from chromedriver_autoinstaller import install
from botasaurus_proxy_authentication import add_proxy_options
# Define the proxy settings
proxy = 'http://username:password@proxy-provider-domain:port' # TODO: Replace with your own proxy
# Set Chrome options
chrome_options = Options()
add_proxy_options(chrome_options, proxy)
# Install and set up the driver
driver_path = install()
driver = webdriver.Chrome(driver_path, options=chrome_options)
# Navigate to the desired URL
driver.get("https://ipinfo.io/")
# Prompt for user input
input("Press Enter to exit...")
# Clean up
driver.quit()We encourage you to learn about Botasaurus. The All-in-One Web Scraping Framework with Anti-Detection, Parallelization, Asynchronous, and Caching Superpowers.
- Kudos to the Apify Team for creating
proxy-chainlibrary. The implementation of SSL-based Proxy Authentication wouldn't be possible without their groundbreaking work onproxy-chain.
Love It? Star It! ⭐
Become one of our amazing stargazers by giving us a star ⭐ on GitHub!
It's just one click, but it means the world to me.