This is a reference implementation of Video Frame Interpolation via Adaptive Separable Convolution [1] using PyTorch. Given two frames, it will make use of adaptive convolution [2] in a separable manner to interpolate the intermediate frame. Should you be making use of our work, please cite our paper [1].

For the Torch version of this work, please see: https://github.com/sniklaus/torch-sepconv
To build the implementation and download the pre-trained networks, run bash install.bash and make sure that you configured the CUDA_HOME environment variable. After successfully completing this step, run python run.py to test it. Should you receive an error message regarding an invalid device function during execution, configure the utilized CUDA architecture within install.bash to something your graphics card supports.
To run it on your own pair of frames, use the following command. You can either select the l1 or the lf model, please see our paper for more details.
Image:
python run.py --model lf --first ./images/first.png --second ./images/second.png --out ./result.png
Video:
python run.py --model lf --video ./video.mp4 --video-out ./result.mp4
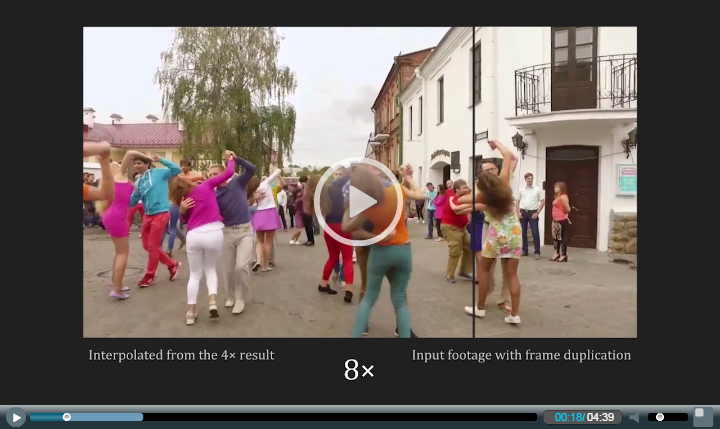
The provided implementation is strictly for academic purposes only. Should you be interested in using our technology for any commercial use, please feel free to contact us.
[1] @inproceedings{Niklaus_ICCV_2017,
author = {Simon Niklaus and Long Mai and Feng Liu},
title = {Video Frame Interpolation via Adaptive Separable Convolution},
booktitle = {IEEE International Conference on Computer Vision},
year = {2017}
}
[2] @inproceedings{Niklaus_CVPR_2017,
author = {Simon Niklaus and Long Mai and Feng Liu},
title = {Video Frame Interpolation via Adaptive Convolution},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
year = {2017}
}
This work was supported by NSF IIS-1321119. The video above uses materials under a Creative Common license or with the owner's permission, as detailed at the end.