In this project, we will be looking at how to implement a Generative Adversarial Network (GAN), an unsupervised machine learning algorithm, that can generate new art images based on actual images.
A GAN consists of 2 neural networks (a discriminator and generator) that competes with one another. The discriminator aims to discriminate between legitimate art images (from the actual dataset) and generated images (generated by the generator network). On the other hand, the generator aims to generate images that can 'fool' the discriminator into thinking that they are images of real artworks.
As we are dealing with images, our GAN architecture will be that of a Deep Convolutional Generative Adversarial Network (DCGAN); you can read the original paper here.
For the discriminator network, we will be using convolutional layers to transform the images (both generated and real) and passing them through a sigmoid activation layer to predict whether these images are real or fake.
Here's a look at a sample convolutional neural network (the discriminator network in a GAN will not have any pooling layers, and will use leaky ReLUs instead of the vanilla flavoured ReLUs:

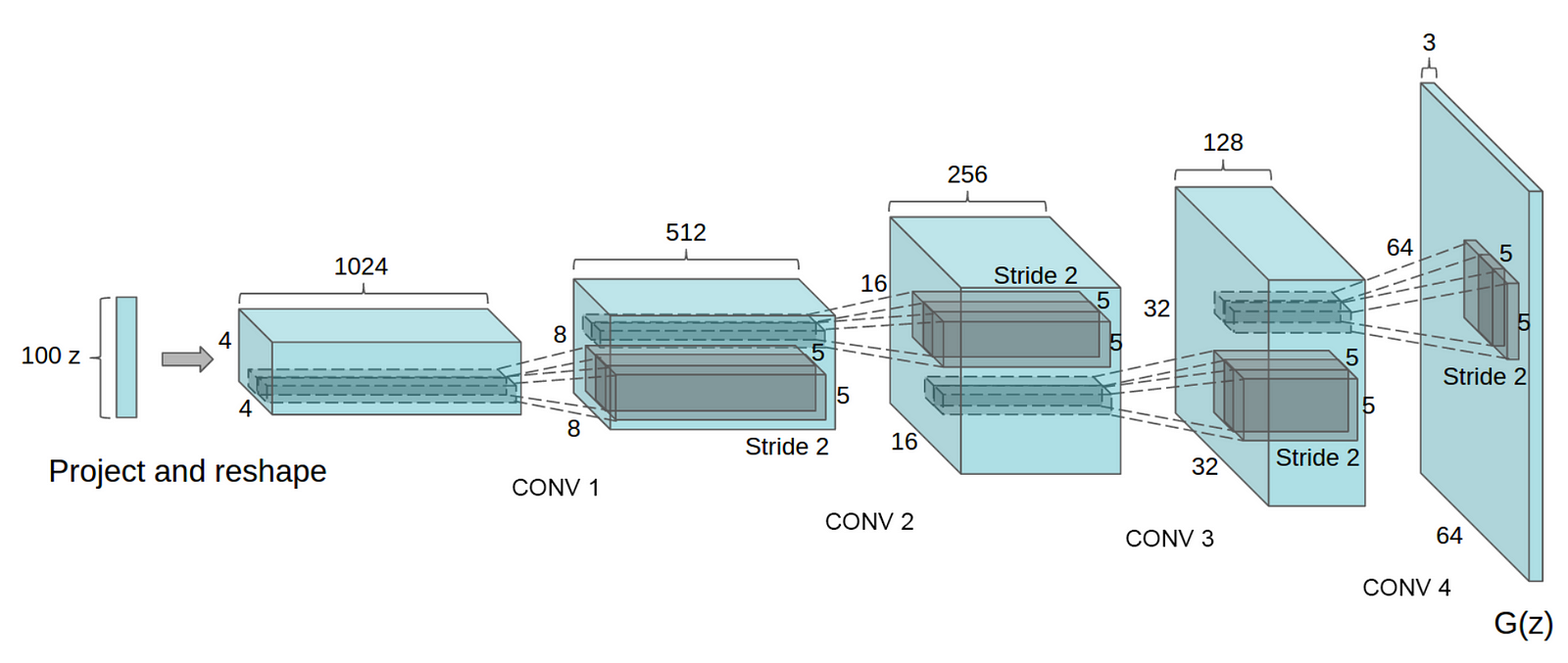
For the generator network, we will be using convolutional transpose to augment the shape of the data sampled from latent space to form an image with dimensions similar to that of the actual image (known as a deconvolutional neural network). For the final layer, we will be using a hyperbolic tangent activation function, tanh to transform the values of our generated images so that they have a range between -1 and 1. Thus, we will have to conduct normalisation on the actual images, as they have a range between 0 and 255.
Here's a look at a sample generator architecture:
Additional Resources:
Wikipedia: Generative Adversarial Networks