This is a stripped down version of my submission of the final project (logging and benchmarking code removed) from Udacity's Intel Edge AI for IoT Developers Nanodegree Program. This project uses a inference engine pipeline involving 4 OpenVINO™ Toolkit Pre-Trained Models to capture the direction at which a person's eye is looking at to move the location of the mouse pointer.
This project uses InferenceEngine API from Intel's OpenVino ToolKit to run the inference using the gaze estimation model from Intel's OpenVino Pre-Trained Model Zoo. The gaze estimation model requires three inputs:
- The head pose
- The left eye image
- The right eye image.
To get these inputs, we have to use three other OpenVino models:
The flow of data will look like this:
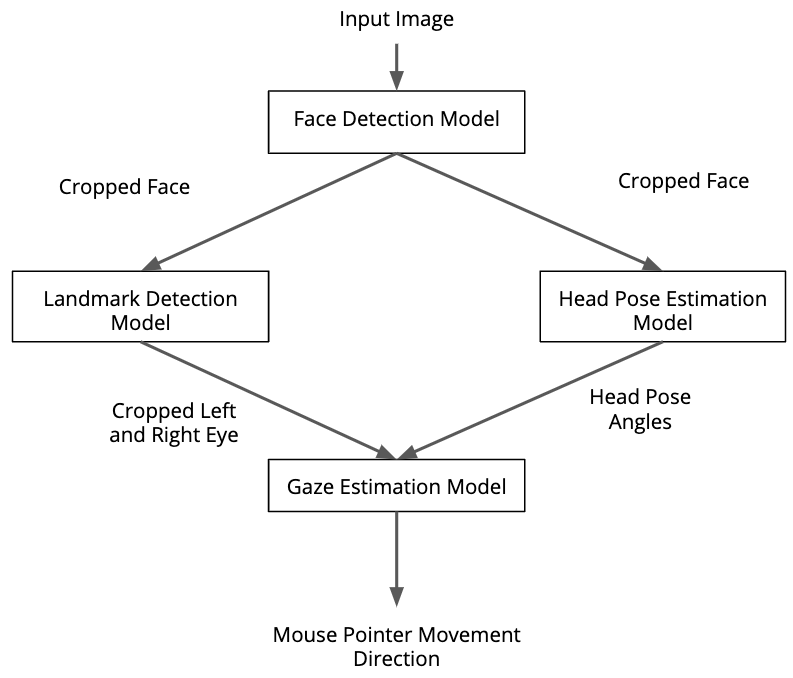
Before you use anything from this repository for any of your Udacity project submission make sure you abide by Udacity Honor Code to avoid penalty from Udacity.
- Install Openvino Toolkit latest version along with it's dependencies.
- Open a terminal window and initialize OpenVINO environment (setupvars).
- Clone this repository, create a virtual environment for it and activate it.
- Install pip dependencies, command:
yarnorpython -m pip install -r requirements.txt - Download following openvino models via openvino model downloader to your desired location. you can also use the default intel openvino model directory.
- Take a note of the directory where you downloaded your models.
To start the app, just run yarn start or python src/main.py, this will run the inference
on your webcam feed with CPU device and FP32 precision and models from default openvino
model install location on windows. For other locations of model download directory you
can use --model-dir command line switch to pass the absolute path of the directory.
To customize the app you can use the following command line arguments:
--model-dir Path to intel model deirectory e.g ...openvino_models/models/intel
--device Device for running inference e.g CPU GPU etc.
--precision Precision FP32, FP16 or INT8 only.
--input-type Input Type cam, video or image only.
--input-file Input video or image file absolute path.
Run yarn start --help to see all available command line switches.
The following are the important files and directories within project src directory
main.py Contains the app
app_args.py Command line arguments builder
models Directory of model classes
input_feeder.py Feeds the input image, video to model
mouse_controller.py Controls mouse pointer using pyautogui
Just using the start_async method for inference does not make it an async inference if
you wait for it. In other words if you are waiting for an operation to complete it's not
an async operation.
In this project async inference was used to run facial_landmarks_detection and head_pose_estimation simultaneously to reduce the inference time.
I could not apply async inference to the whole pipeline, if you wanna share your ideas feel free to open an issue about it, PR's are welcome too.
The pipeline image has been hot-linked from one of my coursemate's repository.