
This repository contains multiple Jupyter notebooks used for fine-tuning open source Language Learning Models (LLMs). The models include but are not limited to, Gemma, Falcon7B, Phi-2, and Zephyr7B.
Each notebook provides a detailed walkthrough of the fine-tuning, including data preprocessing, and model training. They serve as comprehensive guides for those interested in understanding and applying LLMs in their projects.
Here are the major steps involved in each notebook:
- Set Up the Development Environment: Prepare the necessary software and libraries for the project.
- Load and Prepare the Dataset: Import the dataset and preprocess it for the model.
- Load the Base Model: Load the model for fine-tuning.
- Fine-Tune the LLM: Adjust the LLM model parameters on our dataset.
- Push the Fine-Tuned Model to the Hugging Face Hub.
Quantization is the process of constraining an input from a continuous (large set of values) to a discrete set.
Mathematically, a linear quantization is an affine mapping of integers to floating points, we can write the equation as:
Where:
-
$r:$ Floating-point -
$q:$ Integer -
$Z:$ Zero point -
$S:$ Scale -
$r_{max}:$ maximum float in Tensor -
$r_{min}:$ minimum float in Tensor -
$q_{max}:$ maximum integer ($N$ bits,$2^{N-1} -1$ ) -
$q_{min}:$ minimum integer ($N$ bits,$-2^{N-1}$ )
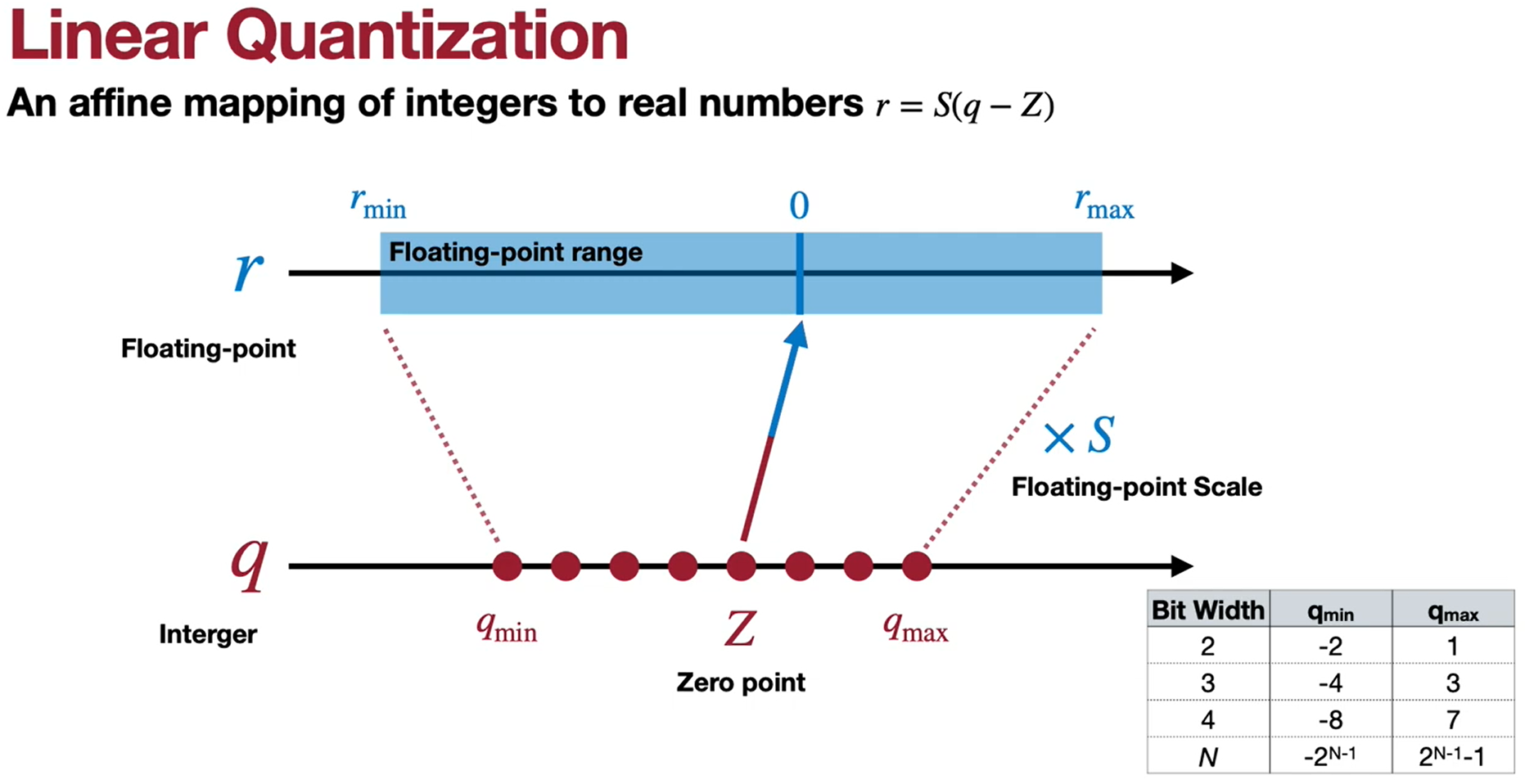
The basic concept of neural network quantization is converting the weights and activations of a neural network into a limited discrete set of numbers. The most well-known quantization methods are:
- Post-Training Quantization (PTQ): The quantization is done after the model is trained.
- Quantization Aware Training (QAT): The quantization is applied to the model, and then it is retrained or fine-tuned.
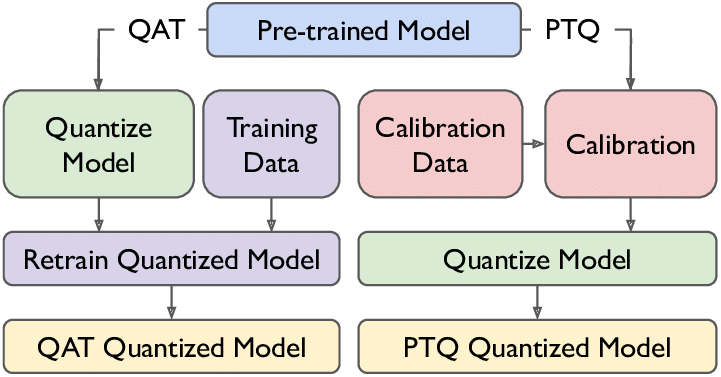
In our notebooks, we are using QAT quantization using bits and bytes.
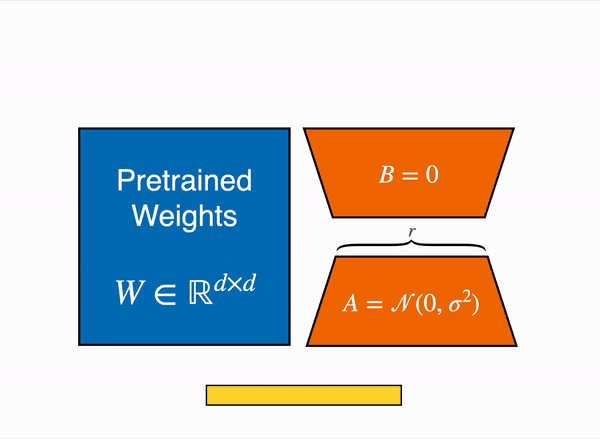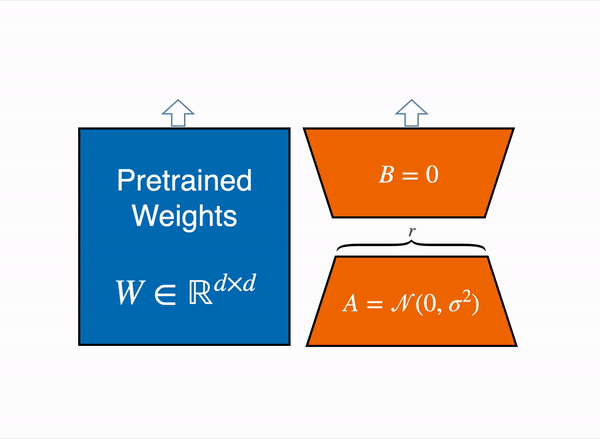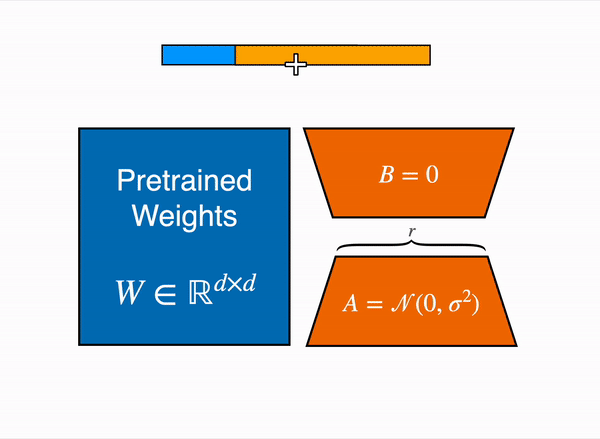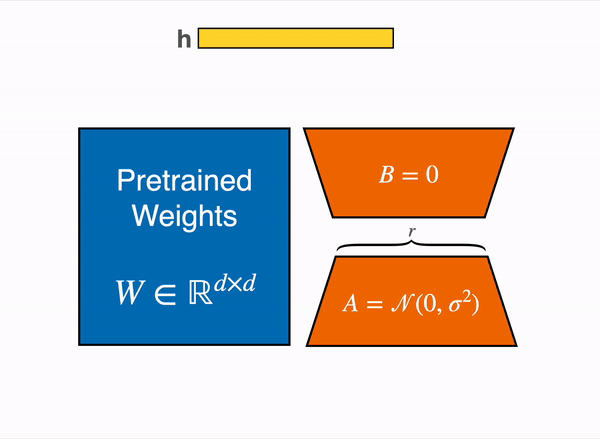
For efficient fine-tuning, we are using the Lasso technique known as LoRA which focuses only on training the adapters rather than the entire model. These adapters are two low-rank matrices A and B. The idea came into existence when Aghajanyan et al. (2020) showed that when adapting to specific tasks, the pre-trained language models have a low intrinsic dimension. Inspired by that, Edward Hu et al. (2021) suggest that the updates to the weights of an LLM also have a low "intrinsic dimension" during adaptation.
For a given matrix weight
Where:
$$W: (d, k)$$ $$B: (d, r)$$ $$A: (r, k)$$ -
$$r << min(d,k):$$ the rank -
$B, A$ represent the low-rank adapters
For the forward pass:
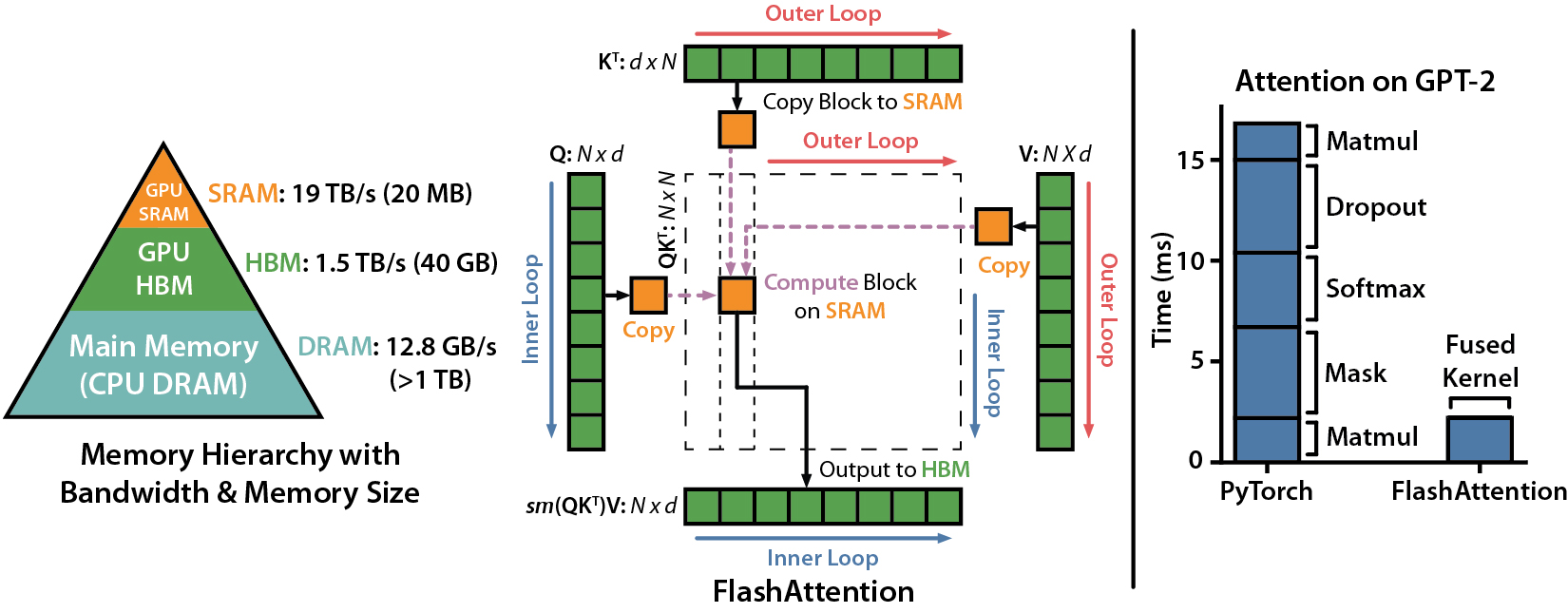
Flash Attention is a technique used to accelerate the computation of attention. The standard attention algorithm can be decomposed as follows:
- For each block of Q and K:
- Load the block from High Bandwidth Memory (HBM) to Static Random-Access Memory (SRAM).
- Compute the corresponding block of the similarity matrix S (
$S = Q \times K^T$ ). - Write the computed block of S to HBM.
- For each block of S:
- Load the block from HBM to SRAM.
- Compute the corresponding block of P ($P = softmax(S)$).
- Write the computed block of P to HBM.
- For each block of P and V:
- Load the block from HBM.
- Compute the corresponding block of O (
$O = PV$ ). - Write the computed block of O to HBM.
At the end of this process, S, P, and O are stored in HBM, resulting in a space complexity of
However, Flash Attention differs in its approach: it doesn't store S, P, and O in HBM. Instead, it only stores O and the softmax normalization values. During the backward pass, it recomputes P and S based on O and the normalization values. This results in a more efficient use of memory and faster computations.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
You can access my Hugging Face account here.