


This repository serves as a point of reference when developing a streaming application with Memgraph and a message broker such as Kafka.
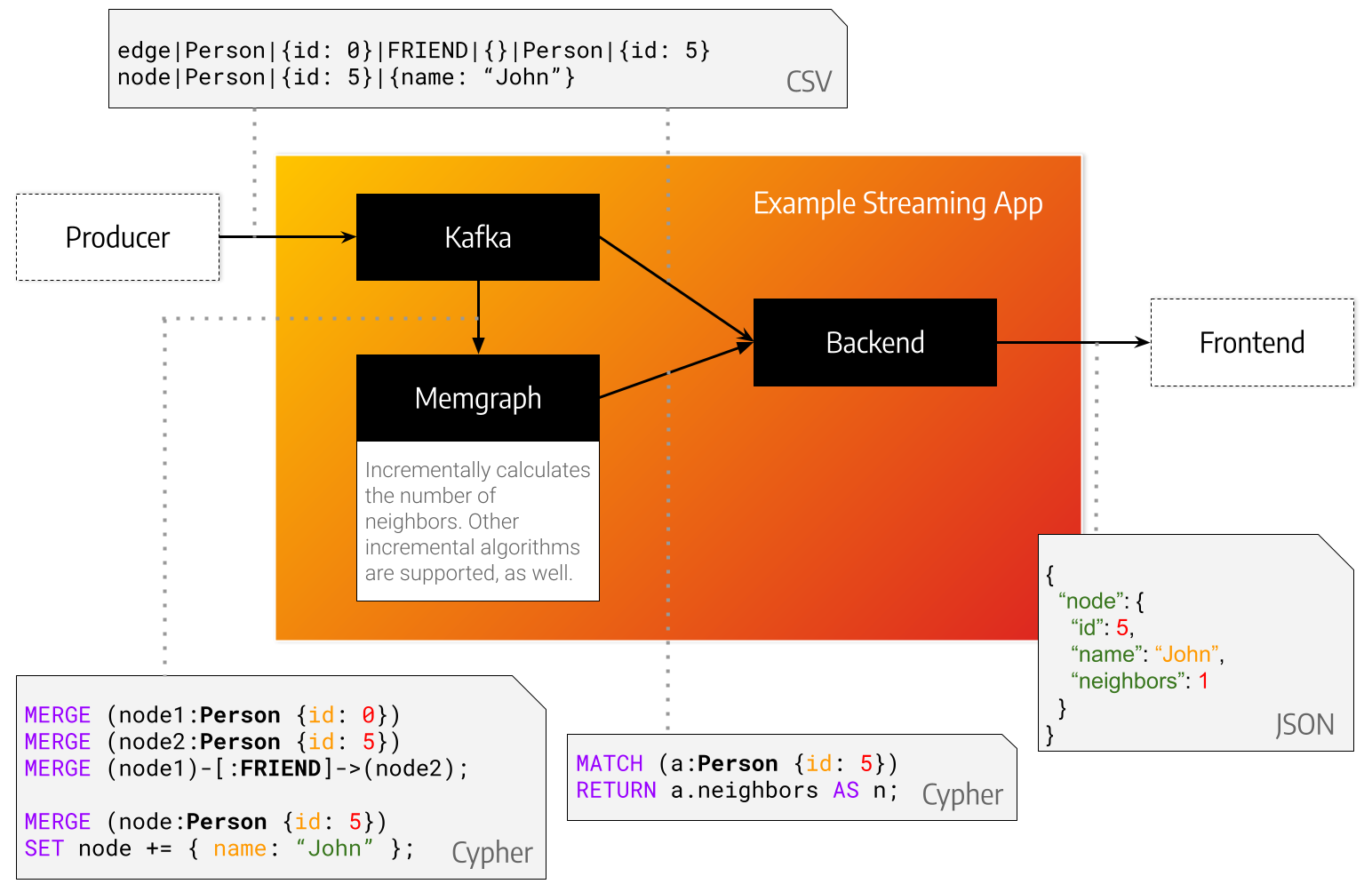
KafkaProducer represents the source of your data. That can be transactions, queries, metadata or something different entirely. In this minimal example we propose using a special string format that is easy to parse. The data is sent from the KafkaProducer to Kafka under a topic aptly named topic. The Backend implements a KafkaConsumer. It takes data from Kafka, consumes it, but also queries Memgraph for graph analysis, feature extraction or storage.
Install Kafka and Memgraph using the instructions in the homonymous directories. Then choose a programming language from the list of supported languages and follow the instructions given there.
The KafkaProducer in ./kafka/producer creates nodes with a label Person that are connected with edges of type CONNECTED_WITH. In this repository we provide a static producer that reads entries from a file and a stream producer that produces entries every X seconds.
The backend takes a message at a time from kafka, parses it with a csv parser as a line, converts it into a openCypher query and sends it to Memgraph.
After storing a node in Memgraph the backend asks Memgraph how many adjacent nodes does it have and prints it to the terminal.
You can think of Memgraph as two separate components: a storage engine and an algorithm execution engine. First we create a trigger: an algorithm that will be run every time a node is inserted. This algorithm calculates and updates the number of neighbors of each affected node after every query is executed.