This python script guesses the race and gender (probabilistically) of the first and last authors for papers in your citation list (in the form of a .bib file) and compares your list to expected distributions based on a model that accounts for paper characteristics (e.g., author location, author seniority, journal, et cetera.) unrelated to race and gender.
Usage Example: python unbiasedciter.py -authors 'Maxwell Bertolero Danielle Bassett' -bibfile '/path/to/my/main.bib' -gender_key 'my_gender_key' -homedir '/you/where/you/keep/this_repo/' -bibname 'my_bib_results'
Requirements: (1) ethnicolr and pybtex; when you run the code, it will install then on the fly for you if you do not have them. (2) You also need a key from gender-api.com. This is free. (3) a .bib file that contains the citations you want to analyze.
This will create:

We only provide the usage of the Florida voter data first and last name model (a) from ethnicolr. This is because the census model (b) that only uses last names very often guesses that a Black author is white. Here is a "confusion" matrix, which measures the model's predictions, during cross validation. The diagonal number are the number of authors who are appropriately classified. The off diagonal entries are the number of errors.
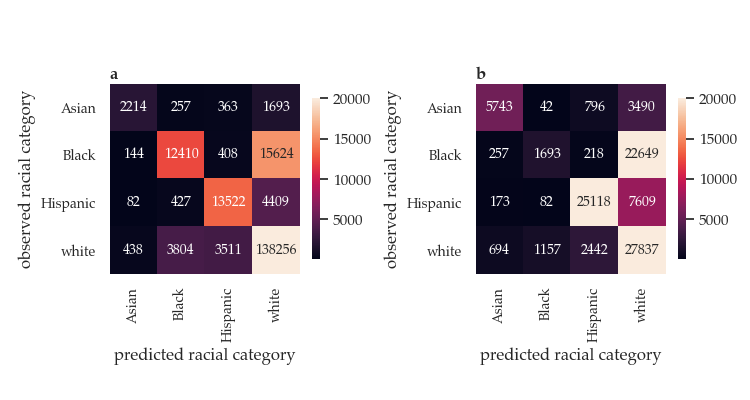
Moreover, we use probabilities, not binary classifications, so a single author's race, for example, is represented as weights across Asian, Black, Hispanic, and white. As such, this code should provide a sanity check / red flag for unbalanced refrences lists, not a ground truth.