forked from llSourcell/YOLO_Object_Detection
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
4eabd29
commit 7b7e56b
Showing
1 changed file
with
215 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,215 @@ | ||
| { | ||
| "cells": [ | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "# YOLO Object Detection\n", | ||
| "\n", | ||
| "## Demo - We're going to use a newer popular algorithm called YOLO to perform real-time object detection on video! \n", | ||
| "\n", | ||
| "### Some Object Detection History (2001-2017)\n", | ||
| "\n", | ||
| "#### The first efficient Face Detector (Viola-Jones Algorithm, 2001)\n", | ||
| "\n", | ||
| "- An efficient algorithm for face detection was invented by Paul Viola & Michael Jones \n", | ||
| "- Their demo showed faces being detected in real time on a webcam feed.\n", | ||
| "- Was the most stunning demonstration of computer vision and its potential at the time. \n", | ||
| "- Soon, it was implemented in OpenCV & face detection became synonymous with Viola and Jones algorithm.\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "##### Much more efficient detection technique (Histograms of Oriented Gradients, 2005)\n", | ||
| "\n", | ||
| "- Navneet Dalal and Bill Triggs invented \"HOG\" for pedestrian detection\n", | ||
| "- Their feature descriptor, Histograms of Oriented Gradients (HOG), significantly outperformed existing algorithms in this task\n", | ||
| "- Handcoded features, just like before\n", | ||
| "\n", | ||
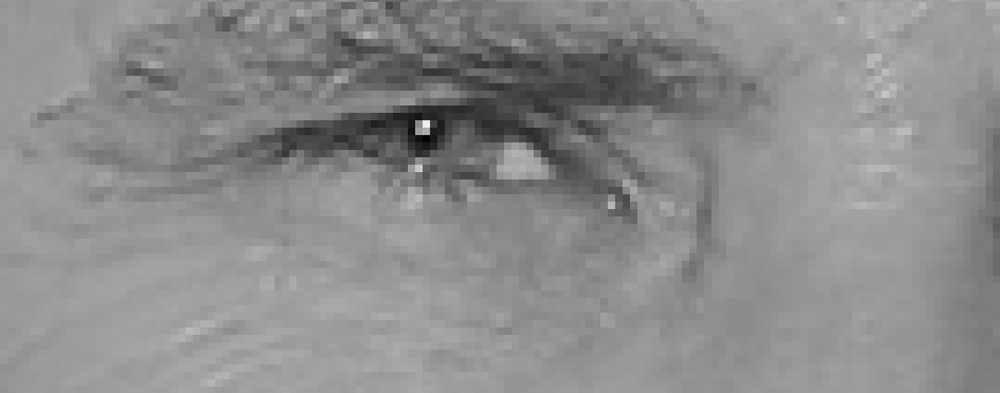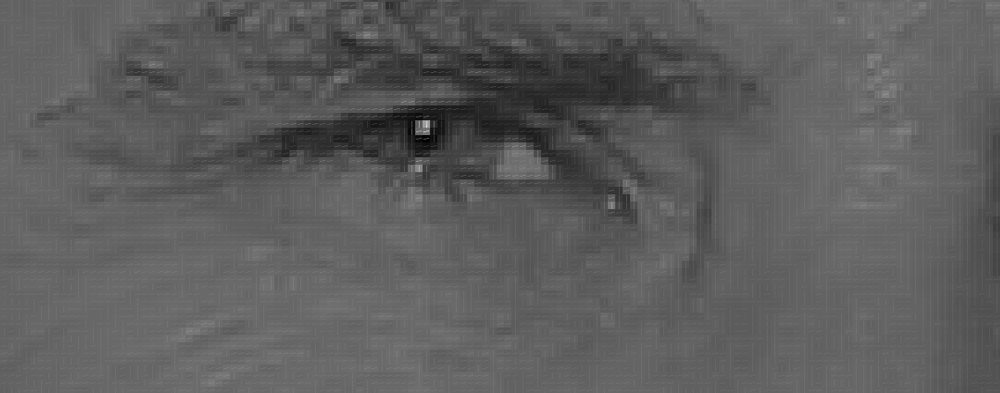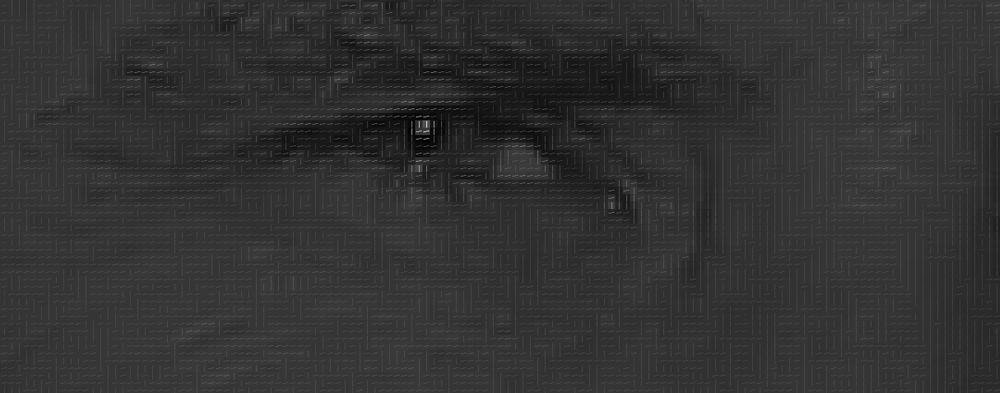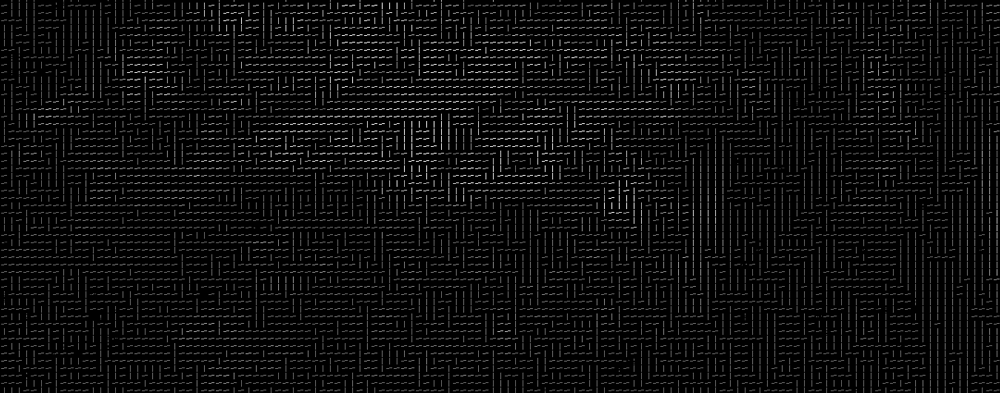
| "- For every single pixel, we want to look at the pixels that directly surrounding it:\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "- Goal is, how dark is current pixel compared to surrounding pixels?\n", | ||
| "- We will then draw an arrow showing in which direction the image is getting darker:\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "- We repeat that process for every single pixel in the image\n", | ||
| "- Every pixel is replaced by an arrow. These arrows are called gradients\n", | ||
| "- Gradients show the flow from light to dark across the entire image:\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "- We'll break up the image into small squares of 16x16 pixels each\n", | ||
| "- In each square, we’ll count up how many gradients point in each major direction\n", | ||
| "- Then we’ll replace that square in the image with the arrow directions that were the strongest.\n", | ||
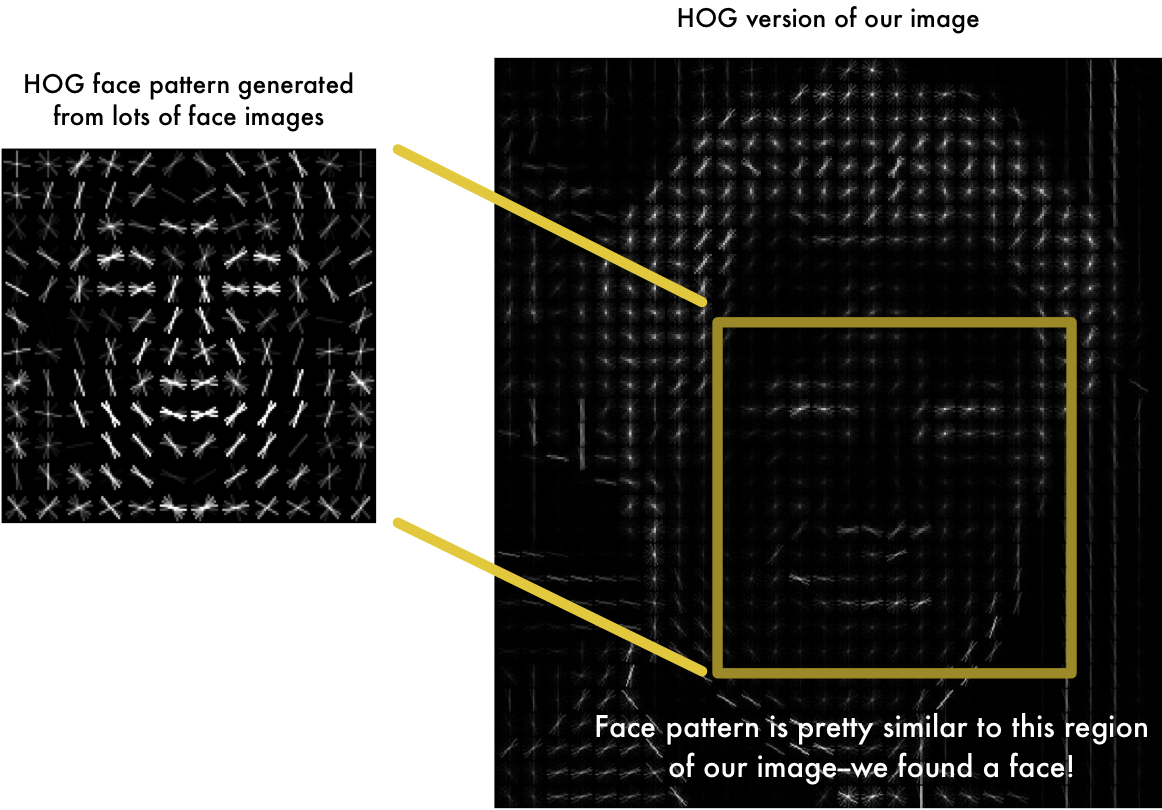
| "- End result? Original image converted into simple representation that captures basic structure of a face in a simple way:\n", | ||
| "- Detecting faces means find the part of our image that looks the most similar to a known HOG pattern that was extracted from a bunch of other training faces:\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "#### The Deep Learning Era begins (2012)\n", | ||
| "\n", | ||
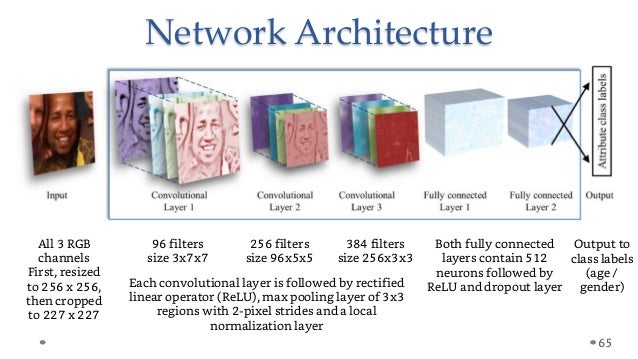
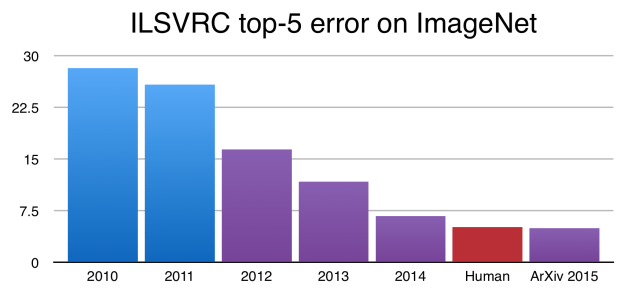
| "- Convolutional Neural Networks became the gold standard for image classification after Kriszhevsky's CNN's performance during ImageNet\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "While these results are impressive, image classification is far simpler than the complexity and diversity of true human visual understanding.\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "In classification, there’s generally an image with a single object as the focus and the task is to say what that image is\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "But when we look at the world around us, we carry out far more complex task\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "We see complicated sights with multiple overlapping objects, and different backgrounds and we not only classify these different objects but also identify their boundaries, differences, and relations to one another!\n", | ||
| "\n", | ||
| "Can CNNs help us with such complex tasks? Yes.\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "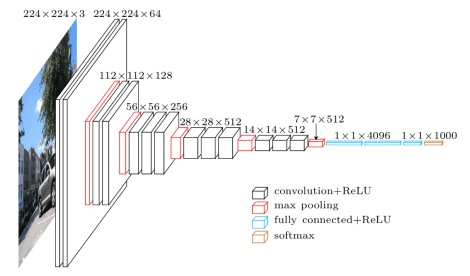\n", | ||
| "\n", | ||
| "- We can take a classifier like VGGNet or Inception and turn it into an object detector by sliding a small window across the image\n", | ||
| "- At each step you run the classifier to get a prediction of what sort of object is inside the current window. \n", | ||
| "- Using a sliding window gives several hundred or thousand predictions for that image, but you only keep the ones the classifier is the most certain about.\n", | ||
| "- This approach works but it’s obviously going to be very slow, since you need to run the classifier many times.\n", | ||
| "\n", | ||
| "##### A better approach, R-CNN\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "- R-CNN creates bounding boxes, or region proposals, using a process called Selective Search \n", | ||
| "- At a high level, Selective Search looks at the image through windows of different sizes, and for each size tries to group together adjacent pixels by texture, color, or intensity to identify objects.\n", | ||
| "\n", | ||
| "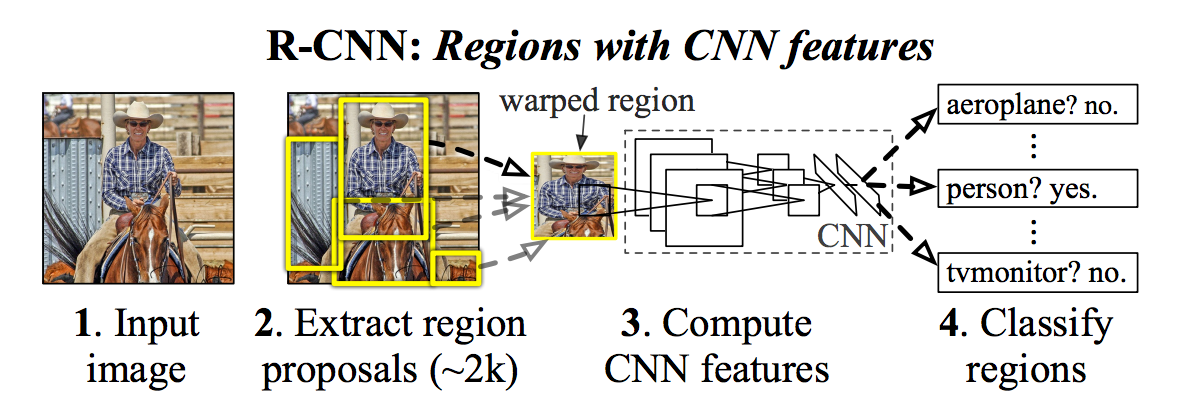\n", | ||
| "\n", | ||
| "1. Generate a set of proposals for bounding boxes.\n", | ||
| "2. Run the images in the bounding boxes through a pre-trained AlexNet and finally an SVM to see what object the image in the box is.\n", | ||
| "3. Run the box through a linear regression model to output tighter coordinates for the box once the object has been classified.\n", | ||
| " \n", | ||
| "###### Some improvements to R-CNN\n", | ||
| "R-CNN: https://arxiv.org/abs/1311.2524\n", | ||
| "Fast R-CNN: https://arxiv.org/abs/1504.08083\n", | ||
| "Faster R-CNN: https://arxiv.org/abs/1506.01497\n", | ||
| "Mask R-CNN: https://arxiv.org/abs/1703.06870\n", | ||
| "\n", | ||
| "But YOLO takes a different approach\n", | ||
| "\n", | ||
| "### What is YOLO?\n", | ||
| "\n", | ||
| "- YOLO takes a completely different approach. \n", | ||
| "- It’s not a traditional classifier that is repurposed to be an object detector. \n", | ||
| "- YOLO actually looks at the image just once (hence its name: You Only Look Once) but in a clever way.\n", | ||
| "\n", | ||
| "YOLO divides up the image into a grid of 13 by 13 cells:\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "- Each of these cells is responsible for predicting 5 bounding boxes. \n", | ||
| "- A bounding box describes the rectangle that encloses an object.\n", | ||
| "- YOLO also outputs a confidence score that tells us how certain it is that the predicted bounding box actually encloses some object.\n", | ||
| "- This score doesn’t say anything about what kind of object is in the box, just if the shape of the box is any good.\n", | ||
| "\n", | ||
| "The predicted bounding boxes may look something like the following (the higher the confidence score, the fatter the box is drawn):\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "- For each bounding box, the cell also predicts a class. \n", | ||
| "- This works just like a classifier: it gives a probability distribution over all the possible classes. \n", | ||
| "- YOLO was trained on the PASCAL VOC dataset, which can detect 20 different classes such as:\n", | ||
| "\n", | ||
| "- bicycle\n", | ||
| "- boat\n", | ||
| "- car\n", | ||
| "- cat\n", | ||
| "- dog\n", | ||
| "- person\n", | ||
| "\n", | ||
| "- The confidence score for the bounding box and the class prediction are combined into one final score that tells us the probability that this bounding box contains a specific type of object. \n", | ||
| "- For example, the big fat yellow box on the left is 85% sure it contains the object “dog”:\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "- Since there are 13×13 = 169 grid cells and each cell predicts 5 bounding boxes, we end up with 845 bounding boxes in total. \n", | ||
| "- It turns out that most of these boxes will have very low confidence scores, so we only keep the boxes whose final score is 30% or more (you can change this threshold depending on how accurate you want the detector to be).\n", | ||
| "\n", | ||
| "The final prediction is then:\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "- From the 845 total bounding boxes we only kept these three because they gave the best results. \n", | ||
| "- But note that even though there were 845 separate predictions, they were all made at the same time — the neural network just ran once. And that’s why YOLO is so powerful and fast.\n", | ||
| "\n", | ||
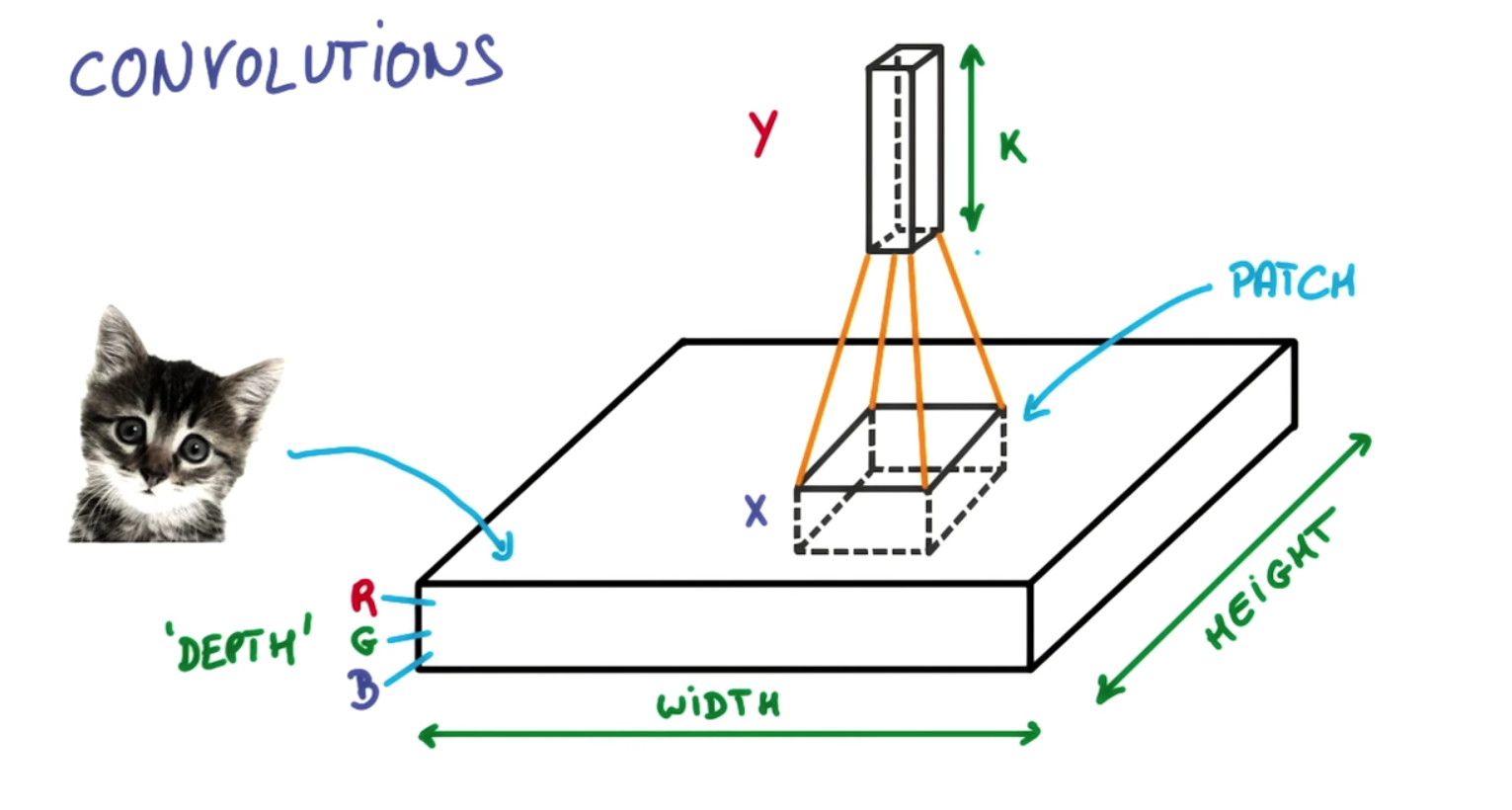
| "The architecture of YOLO is simple, it’s just a convolutional neural network:\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "This neural network only uses standard layer types: convolution with a 3×3 kernel and max-pooling with a 2×2 kernel. No fancy stuff. There is no fully-connected layer in YOLOv2.\n", | ||
| "\n", | ||
| "The very last convolutional layer has a 1×1 kernel and exists to reduce the data to the shape 13×13×125. This 13×13 should look familiar: that is the size of the grid that the image gets divided into.\n", | ||
| "\n", | ||
| "So we end up with 125 channels for every grid cell. These 125 numbers contain the data for the bounding boxes and the class predictions. Why 125? Well, each grid cell predicts 5 bounding boxes and a bounding box is described by 25 data elements:\n", | ||
| "\n", | ||
| "- x, y, width, height for the bounding box’s rectangle\n", | ||
| "- the confidence score\n", | ||
| "- the probability distribution over the classes\n", | ||
| "\n", | ||
| "Using YOLO is simple: you give it an input image (resized to 416×416 pixels), it goes through the convolutional network in a single pass, and comes out the other end as a 13×13×125 tensor describing the bounding boxes for the grid cells. All you need to do then is compute the final scores for the bounding boxes and throw away the ones scoring lower than 30%.\n", | ||
| "\n", | ||
| "### Improvements to YOLO v1\n", | ||
| "\n", | ||
| "YoLO v2 vs YoLO v1\n", | ||
| "\n", | ||
| "- Speed (45 frames per second — better than realtime)\n", | ||
| "- Network understands generalized object representation (This allowed them to train the network on real world images and predictions on artwork was still fairly accurate).\n", | ||
| "- faster version (with smaller architecture) — 155 frames per sec but is less accurate.\n", | ||
| "\n", | ||
| "Paper here\n", | ||
| "https://arxiv.org/pdf/1612.08242v1.pdf\n", | ||
| "\n", | ||
| "### Code Walkthrough & demo\n", | ||
| "\n", | ||
| "1. Using pretrained network\n", | ||
| "2. Training on your own dataset \n", | ||
| "\n" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "execution_count": null, | ||
| "metadata": { | ||
| "collapsed": true | ||
| }, | ||
| "outputs": [], | ||
| "source": [] | ||
| } | ||
| ], | ||
| "metadata": { | ||
| "kernelspec": { | ||
| "display_name": "Python 3", | ||
| "language": "python", | ||
| "name": "python3" | ||
| }, | ||
| "language_info": { | ||
| "codemirror_mode": { | ||
| "name": "ipython", | ||
| "version": 3 | ||
| }, | ||
| "file_extension": ".py", | ||
| "mimetype": "text/x-python", | ||
| "name": "python", | ||
| "nbconvert_exporter": "python", | ||
| "pygments_lexer": "ipython3", | ||
| "version": "3.6.0" | ||
| } | ||
| }, | ||
| "nbformat": 4, | ||
| "nbformat_minor": 2 | ||
| } |