forked from youngyangyang04/leetcode-master
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
2caee6f
commit 139a4db
Showing
2 changed files
with
58 additions
and
116 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,120 +1,60 @@ | ||
|
|
||
| # 什么是核心代码模式,什么又是ACM模式? | ||
|
|
||
| 现在很多企业都在牛客上进行面试,**很多录友和我反馈说搞不懂牛客上输入代码的ACM模式**。 | ||
| 很多录友刷了不少题了,到现在也没有搞清楚什么是 ACM模式,什么是核心代码模式。 | ||
|
|
||
| 什么是ACM输入模式呢? 就是自己构造输入数据格式,把要需要处理的容器填充好,OJ不会给你任何代码,包括include哪些函数都要自己写,最后也要自己控制返回数据的格式。 | ||
| 平时大家在力扣上刷题,就是 核心代码模式,即给你一个函数,直接写函数实现,例如这样: | ||
|
|
||
| 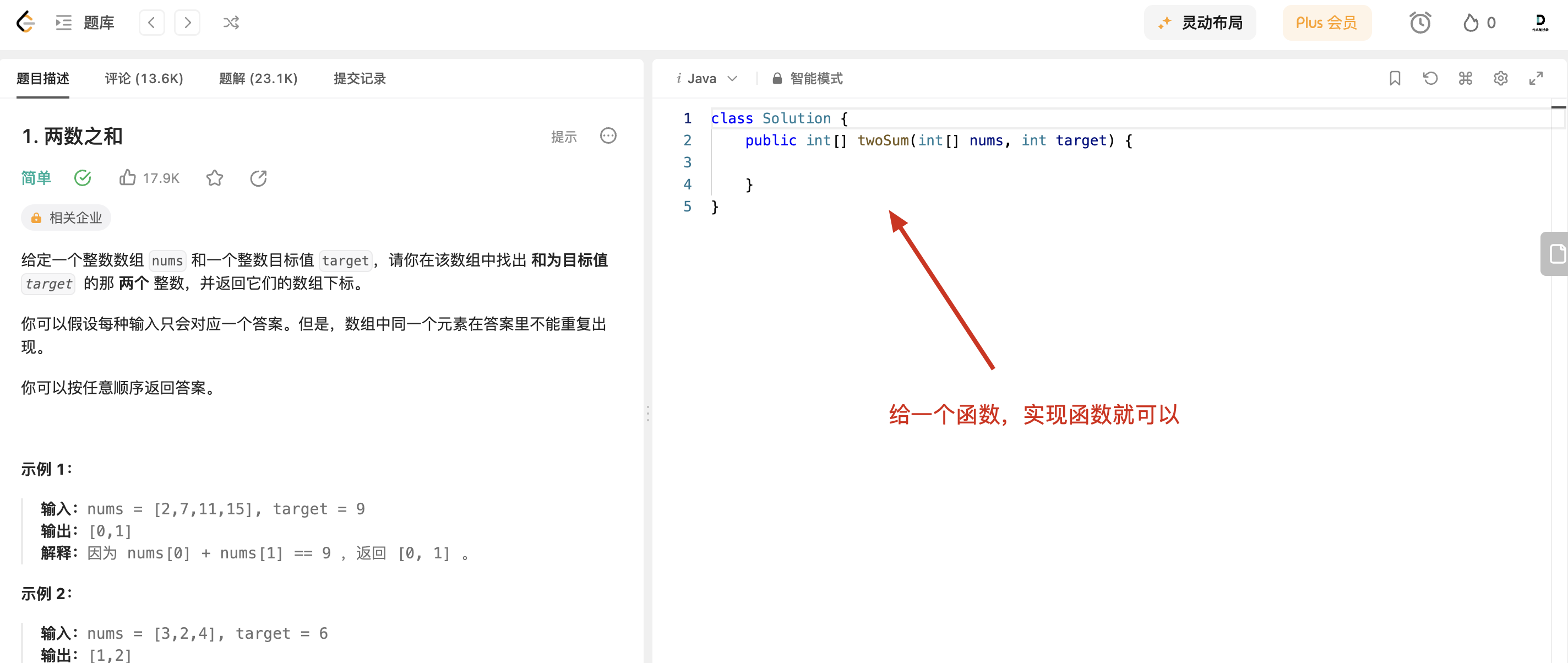 | ||
|
|
||
| **这里给大家推荐ACM模式练习网站**:[kamacoder.com](https://kamacoder.com),把上面的题目刷完,ACM模式就没问题了。 | ||
|
|
||
| 而ACM模式,是程序头文件,main函数,数据的输入输出都要自己处理,例如这样: | ||
|
|
||
| 而力扣上是核心代码模式,就是把要处理的数据都已经放入容器里,可以直接写逻辑,例如这样: | ||
| 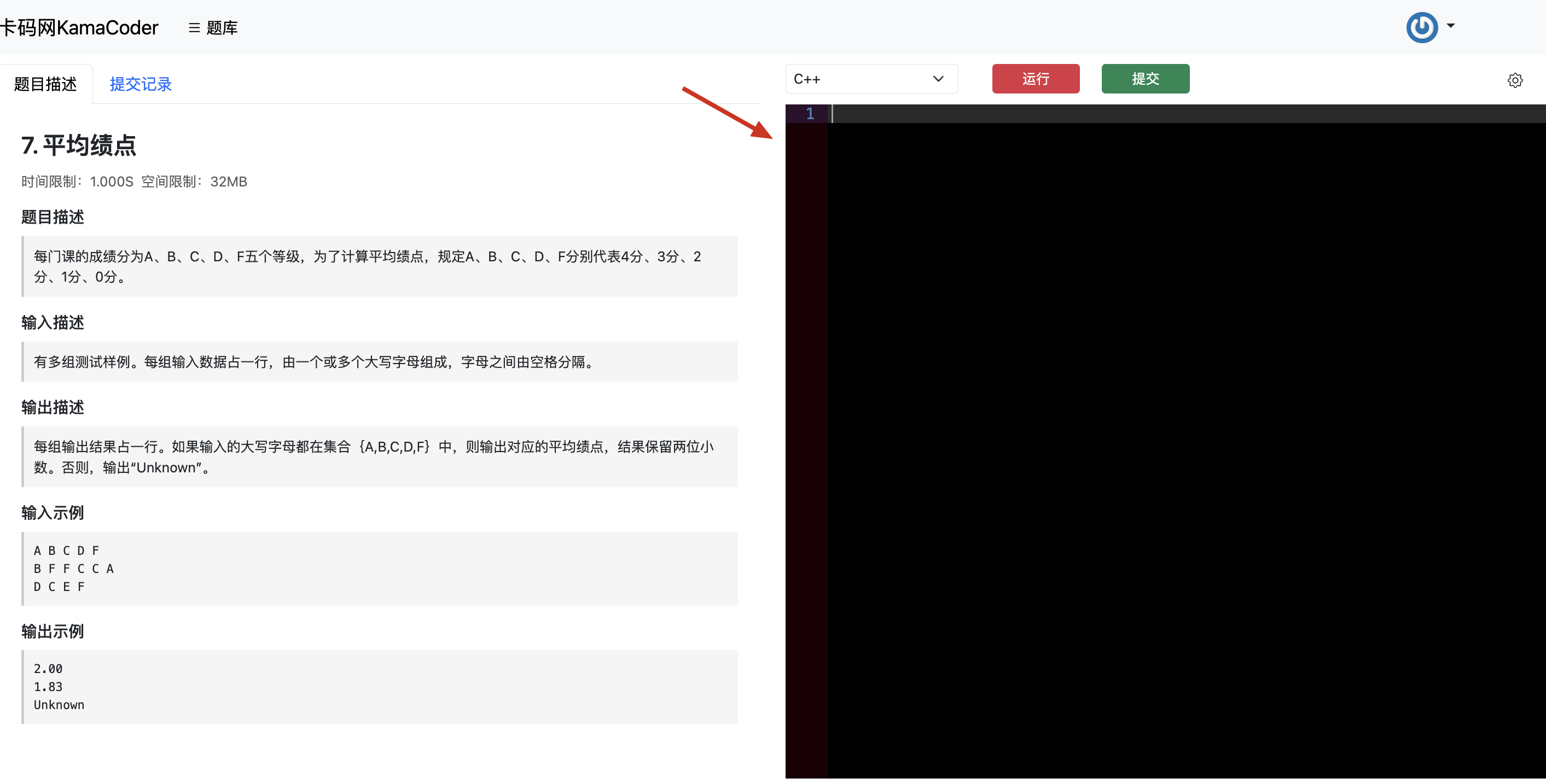 | ||
|
|
||
| ```CPP | ||
| class Solution { | ||
| public: | ||
| int minimumTotal(vector<vector<int>>& triangle) { | ||
| 大家可以发现 右边代码框什么都没有,程序从头到尾都需要自己实现,本题如果写完代码是这样的: (细心的录友可以发现和力扣上刷题是不一样的) | ||
|
|
||
| } | ||
| }; | ||
| ``` | ||
| 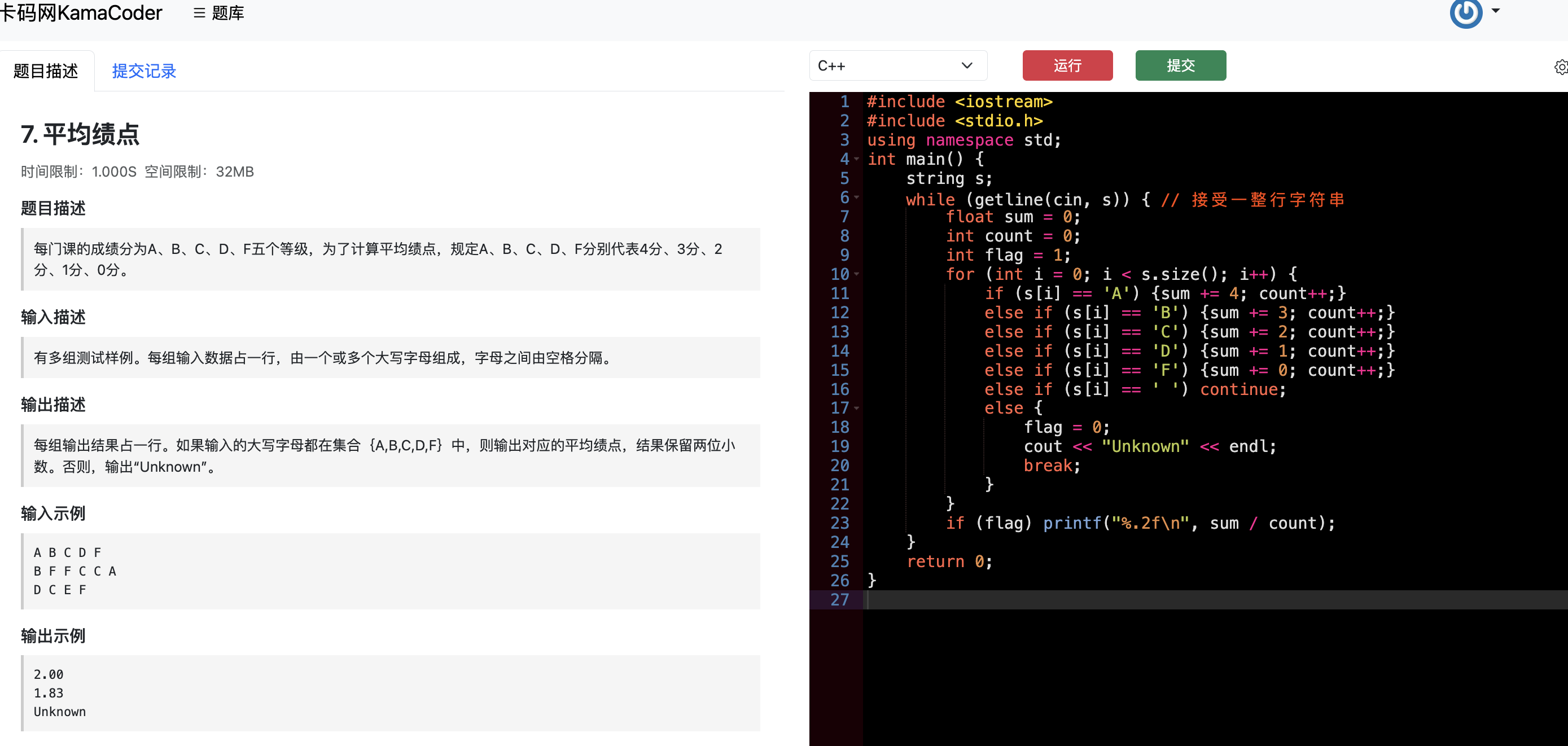 | ||
|
|
||
| **如果大家从一开始学习算法就一直在力扣上的话,突然切到牛客网上的ACM模式会很不适应**。 | ||
|
|
||
| 因为我上学的时候就搞ACM,在POJ(北大的在线判题系统)和ZOJ(浙大的在线判题系统)上刷过6、7百道题目了,对这种ACM模式就很熟悉。 | ||
| **如果大家从一开始学习算法就一直在力扣上的话,突然切到ACM模式会非常不适应**。 | ||
|
|
||
| 接下来我给大家讲一下ACM模式应该如何写。 | ||
| 知识星球里也有很多录友,因为不熟悉ACM模式在面试的过程中吃了不少亏。 | ||
|
|
||
| 这里我拿牛客上 腾讯2020校园招聘-后台 的面试题目来举一个例子,本题我不讲解题思路,只是拿本题为例讲解ACM输入输出格式。 | ||
|
|
||
| 题目描述: | ||
| <div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727163624.png' width=500 alt=''></img></div> | ||
|
|
||
| 由于业绩优秀,公司给小Q放了 n 天的假,身为工作狂的小Q打算在在假期中工作、锻炼或者休息。他有个奇怪的习惯:不会连续两天工作或锻炼。只有当公司营业时,小Q才能去工作,只有当健身房营业时,小Q才能去健身,小Q一天只能干一件事。给出假期中公司,健身房的营业情况,求小Q最少需要休息几天。 | ||
| <div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727163938.png' width=500 alt=''></img></div> | ||
|
|
||
| 输入描述: | ||
| 第一行一个整数 表示放假天数 | ||
| 第二行 n 个数 每个数为0或1,第 i 个数表示公司在第 i 天是否营业 | ||
| 第三行 n 个数 每个数为0或1,第 i 个数表示健身房在第 i 天是否营业 | ||
| (1为营业 0为不营业) | ||
| <div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727164042.png' width=500 alt=''></img></div> | ||
|
|
||
| 输出描述: | ||
| 一个整数,表示小Q休息的最少天数 | ||
| <div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727164151.png' width=500 alt=''></img></div> | ||
|
|
||
| 示例一: | ||
| 输入: | ||
| 4 | ||
| 1 1 0 0 | ||
| 0 1 1 0 | ||
| <div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727164459.png' width=500 alt=''></img></div> | ||
|
|
||
| 输出: | ||
| 2 | ||
| ## 面试究竟怎么考? | ||
|
|
||
| 笔试的话,基本都是 ACM模式。 | ||
|
|
||
| 这道题如果要是力扣上的核心代码模式,OJ应该直接给出如下代码: | ||
| 面试的话,看情况,有的面试官会让你写一个函数实现就可以,此时就是核心代码模式。 | ||
|
|
||
| ```CPP | ||
| class Solution { | ||
| public: | ||
| int getDays(vector<int>& work, vector<int>& gym) { | ||
| // 处理逻辑 | ||
| } | ||
| }; | ||
| ``` | ||
| 有的面试官会 给你一个编辑器,让你写完代码运行一下看看输出结果,此时就是ACM模式。 | ||
|
|
||
| 以上代码中我们直接写核心逻辑就行了,work数组,gym数组都是填好的,直接拿来用就行,处理完之后 return 结果就完事了。 | ||
| 有的录友想,那我平时在力扣刷题,写的是核心代码模式,我也可以运行,为啥一定要用ACM模式。 | ||
|
|
||
| 那么看看ACM模式我们要怎么写呢。 | ||
| **大家在力扣刷题刷多了,已经忘了程序是如何运行的了**,力扣上写的代码,脱离力扣环境,那个函数,你怎么运行呢? | ||
|
|
||
| ACM模式要求写出来的代码是直接可以本地运行的,所以我们需要自己写include哪些库函数,构造输入用例,构造输出用例。 | ||
| 想让程序在本地运行起来,是不是需要补充 库函数,是不是要补充main函数,是不是要补充数据的输入和输出。 那不就是ACM模式了。 | ||
|
|
||
| 拿本题来说,为了让代码可以运行,需要include这些库函数: | ||
| 综合来看,** ACM模式更考察综合代码能力, 核心代码模式是更聚焦算法的实现逻辑**。 | ||
|
|
||
| ```CPP | ||
| #include<iostream> | ||
| #include<vector> | ||
| using namespace std; | ||
| ``` | ||
| ## 去哪练习ACM模式? | ||
|
|
||
| 这里给大家推荐卡码网: [kamacoder.com](https://kamacoder.com/) | ||
|
|
||
| 然后开始写主函数,来处理输入用例了,示例一 是一个完整的测试用例,一般我们测了一个用例还要测第二个用例,所以用:while(cin>>n) 来输入数据。 | ||
| 你只要能把卡码网首页的25道题目 都刷了 ,就把所有的ACM输入输出方式都练习到位了,不会有任何盲区。 | ||
|
|
||
| 这里输入的n就是天数,得到天数之后,就可以来构造work数组和gym数组了。 | ||
|  | ||
|
|
||
| 此时就已经完成了输入用例构建,然后就是处理逻辑了,最后返回结果。 | ||
| 而且你不用担心,题目难度太大,直接给自己劝退,**卡码网的前25道题目都是我精心制作的,难度也是循序渐进的**,大家去刷一下就知道了。 | ||
|
|
||
| 完整代码如下: | ||
|
|
||
| ```CPP | ||
| #include<iostream> | ||
| #include<vector> | ||
| using namespace std; | ||
| int main() { | ||
| int n; | ||
| while (cin >> n) { | ||
| vector<int> gym(n); | ||
| vector<int> work(n); | ||
| for (int i = 0; i < n; i++) cin >> work[i]; | ||
| for (int i = 0; i < n; i++) cin >> gym[i]; | ||
| int result = 0; | ||
|
|
||
| // 处理逻辑 | ||
|
|
||
| cout << result << endl; | ||
| } | ||
| return 0; | ||
| } | ||
| ``` | ||
|
|
||
| 可以看出ACM模式要比核心代码模式多写不少代码,相对来说ACM模式更锻炼代码能力,而核心代码模式是把侧重点完全放在算法逻辑上。 | ||
|
|
||
| **国内企业现在很多都用牛客来进行面试,所以这种ACM模式大家还有必要熟悉一下**,以免面试的时候因为输入输出搞不懂而错失offer。 | ||
|
|
||
| 如果大家有精力的话,也可以去POJ上去刷刷题,POJ是ACM选手首选OJ,输入模式也是ACM模式。 | ||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
| ----------------------- | ||
| <div align="center"><img src=https://code-thinking.cdn.bcebos.com/pics/01二维码.jpg width=450> </img></div> |