Tiling
The Tiling node is responsible for splitting the input image into smaller tiles and processing each tile individually. It computes and stores the information neccessary for each tile.
- Divide the input frame into tiles based on the grid size and overlap.
- Resize each tile to match the neural network’s input size.
Calculates the dimensions of each tile based on the image size, grid size, and overlap. We can rephrase the problem to have a simple system of equations that we can solve using a little bit of Linear Algebra.
We are given the total image dimensions
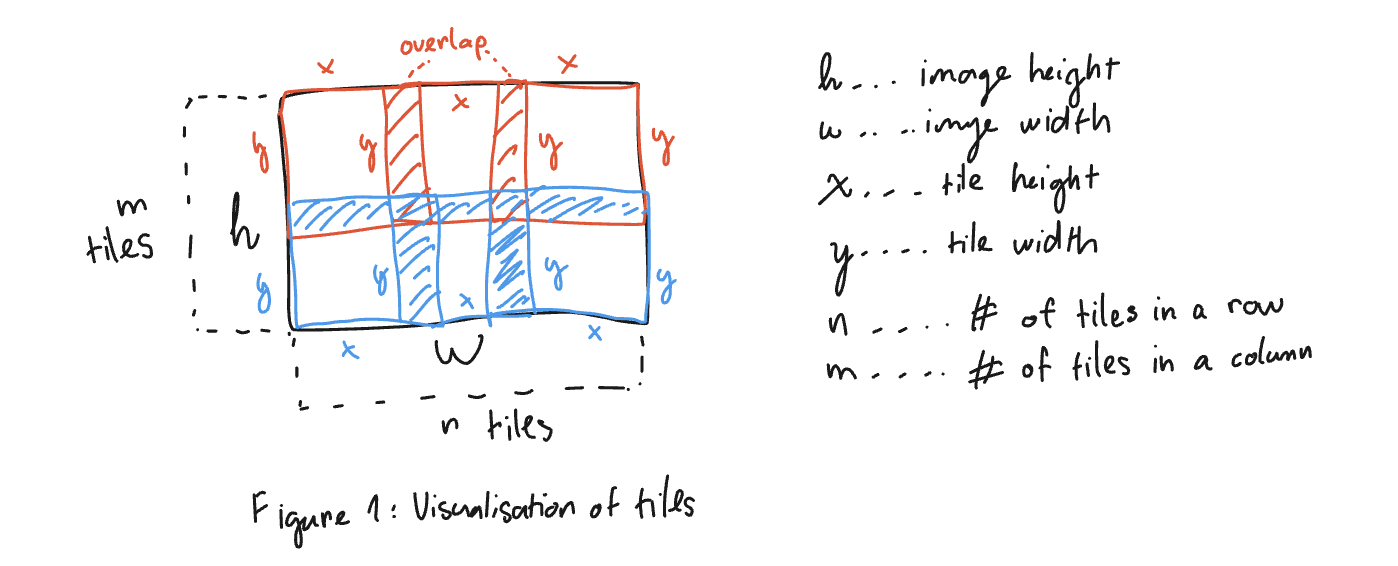
We can express this using the following two equations:
Where:
-
$x$ is the height of a tile. -
$y$ is the width of a tile. -
$\text{{overlap}}$ is the fractional amount of overlap between tiles. -
$w$ is the image width. -
$h$ is the image height.
We can rewrite the system of equations as:
Let:
To solve for the tile dimensions
Computes the positions of the tiles in the image based on the previously computed tile dimensions and the grid's matrix. Here's a breakdown of the function.
Checking if all neccessary variables are avaiable.
The function labels the tiles using a breadth-first search (BFS) approach to identify components, which are groups of adjacent tiles with the same index value in the grid matrix.
-
A 2D
labelsarray is initialized with all entries set to -1, indicating that no tiles have been assigned a component ID yet. -
For each unvisited tile (i.e., a tile with label -1), a new component is started. The function uses BFS to group together adjacent tiles with the same index value, labeling them with the same component ID.
The BFS algorithm creates "components" of adjacent tiles. Each component is stored in a dictionary where the key is the component ID, and the value is a list of tile coordinates (row, column). If tiles in the grid matrix share the same index, they will be merged into a single component.
Once the components are created, the function computes the bounding box of each component by finding the minimum and maximum x and y coordinates for the tiles within that component.
For each component:
- The top-left corner
$(x_1, y_1)$ is the minimum of the tile's x and y coordinates. - The bottom-right corner
$(x_2, y_2)$ is the maximum of the tile's x and y coordinates.
These corners define the bounding box of the merged tile.
If the global_detection flag is set, the entire image is added as a single tile at the beginning of the tile_positions list.
For each tile, the width and height are scaled to fit the neural network's input size. The scaling factor is computed as:
The scaled width and height are then used to resize the tile to fit the neural network's expected input dimensions. This is computed at this step and stored to save computation.
Finally, each tile's position and scaled size are appended to the tile_positions list.
To map these tiles back to the global coordinate system, we need a way to distinguish the tile positions once sent to the neural network. To do this, the sequence number to identify the tile is set using img_frame.setSequenceNum(tile_index) where img_frame is a ImgFrame object.