
这是一个信息聚合阅读的项目,采用 Flask + React + Redux 的技术栈:
- Flask 用于在后台提供 api 服务
- React 用于构建 UI
- Redux 用于数据流管理
本项目相关博文:实例讲解基于 Flask+React 的全栈开发和部署。
目前项目已经实现了基本功能,界面大概如下:
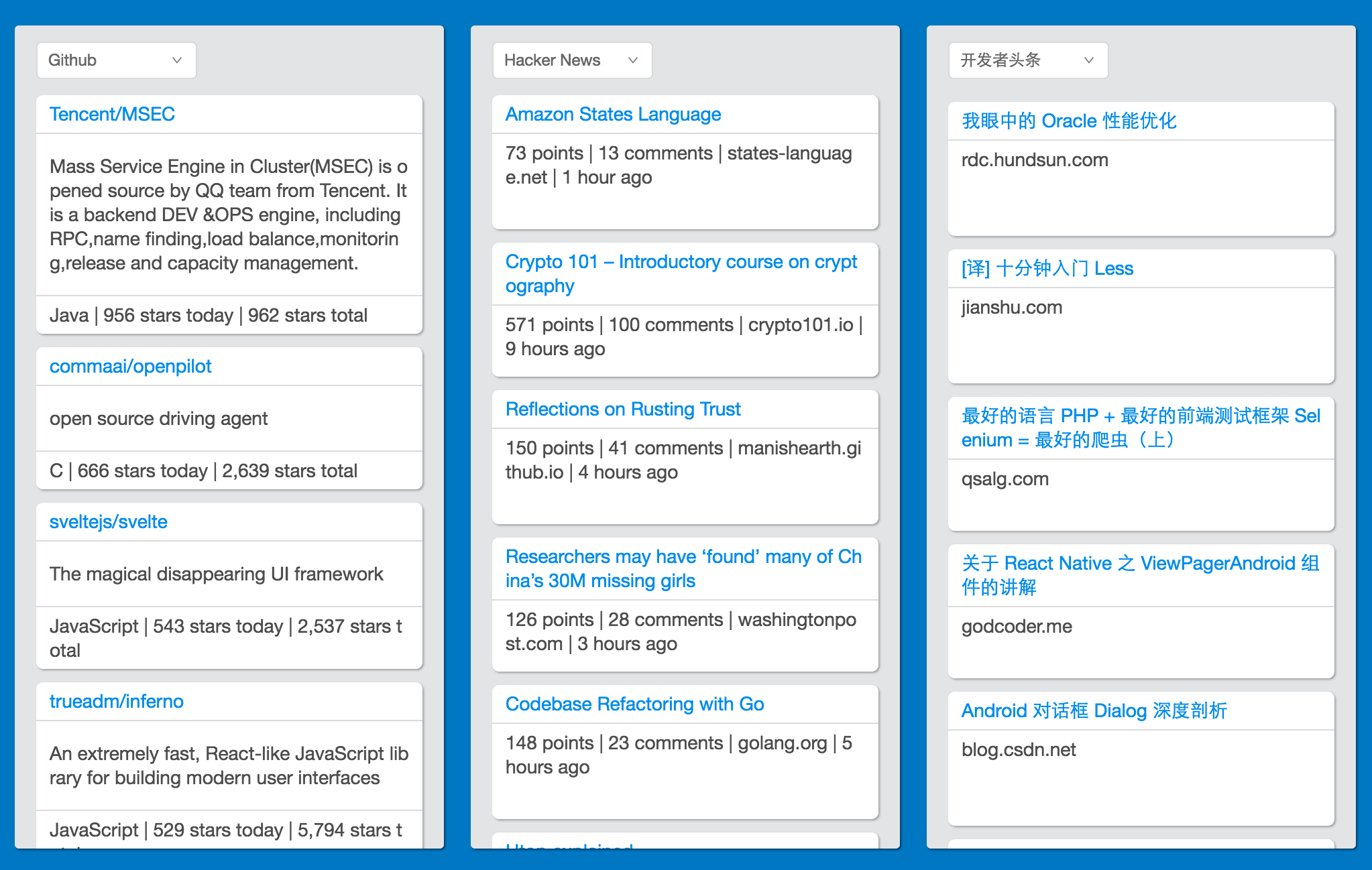
$ git clone https://github.com/ethan-funny/react-news-board.git
$ cd react-news-board
$ pip install -r requirements.txt
$ cd client
$ npm install
其中,pip install -r requirements.txt 是安装 Python 的第三方库,也可使用 virtualenv 来安装,然后,进入到 client 目录,使用 npm 安装 Node 的相关模块。
要让项目跑起来,需启动前端和后台。
进入项目的根目录,执行下面命令:
react-news-board $ python manage.py runserver
* Running on http://127.0.0.1:2345/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger pin code: 201-208-541
进入项目根目录下的 client 目录,执行 npm start 的命令,如下:
react-news-board $ cd client
react-news-board: client $ npm start
> [email protected] start /Users/Ethan/Documents/Code/react-news-board/client
> webpack-dev-server --progress
70% 1/1 build modules[HPM] Proxy created: /api -> http://127.0.0.1:2345
http://localhost:8080/
webpack result is served from /
content is served from /Users/Ethan/Documents/Code/react-news-board/client/public
404s will fallback to /index.html
95% emitHash: 6ade44d13faadad08ce7
Version: webpack 1.13.3
Time: 16944ms
Asset Size Chunks Chunk Names
bundle.js 5.07 MB 0 [emitted] main
bundle.js.map 6.05 MB 0 [emitted] main
index.html 290 bytes [emitted]
上面两部操作完成后,在浏览器打开 http://localhost:8080/ 即可看到效果。
本项目的部署采用 nginx+gunicorn+supervisor 的方式,其中:
- nginx 用来做反向代理服务器:通过接收 Internet 上的连接请求,将请求转发给内网中的目标服务器,再将从目标服务器得到的结果返回给 Internet 上请求连接的客户端(比如浏览器);
- gunicorn 是一个高效的 Python WSGI Server,我们通常用它来运行 WSGI (Web Server Gateway Interface,Web 服务器网关接口) 应用(比如本项目的 Flask 应用);
- supervisor 是一个进程管理工具,可以很方便地启动、关闭和重启进程等;
项目部署需要用到的文件在 deploy 目录下:
deploy
├── fabfile.py # 自动部署脚本
├── nginx.conf # nginx 通用配置文件
├── nginx_geekvi.conf # 站点配置文件
└── supervisor.conf # supervisor 配置文件
本项目采用了 Fabric 自动部署神器,它允许我们不用直接登录服务器就可以在本地执行远程操作,比如安装软件,删除文件等。
在部署之前,我们应该先对前端的资源进行加载和构建,在 deploy 目录使用如下命令:
$ fab build
当然,你也可以直接到 client 目录下,运行命令:
$ npm run build
如果构建没有出现错误,就可以进行部署了,在 deploy 目录使用如下命令进行部署:
$ fab deploy
注意,请根据实际情况修改 fabfile.py 脚本的相关参数,比如服务器地址,用户名,服务器端口和项目路径等。
如果你对本项目感兴趣的话,欢迎加入开发。
后台部分主要是爬虫,目前爬虫的站点只有 Github Trending, Hacker News,SegmentFault 和开发者头条等几个,稀土掘金,知乎日报(貌似有 api),简书等站点后续也会考虑。本项目的爬虫使用 Python,第三方库有 requests 和 lxml,爬虫要提取的内容主要有标题,时间和描述等,最后还会对它们进行格式化,以便提供给前端,这部分可以参考 server/spiders 目录下的爬虫文件。
前端部分还有不少需要完善和优化,比如支持滚动到底部进行分页加载,页面 CSS 美化等。
- 稀土掘金
- 知乎日报(或专栏等)
- 支持滚动到底部进行分页加载