
![]()
This project is part of a set of projects that make up Face2Face (still in development).
It allows to extract and align faces from an image. Those output images could be used as input for any machine learning algorithm that learn how to recognize faces.
This is the first phase in order to build a face recognition pipeline.
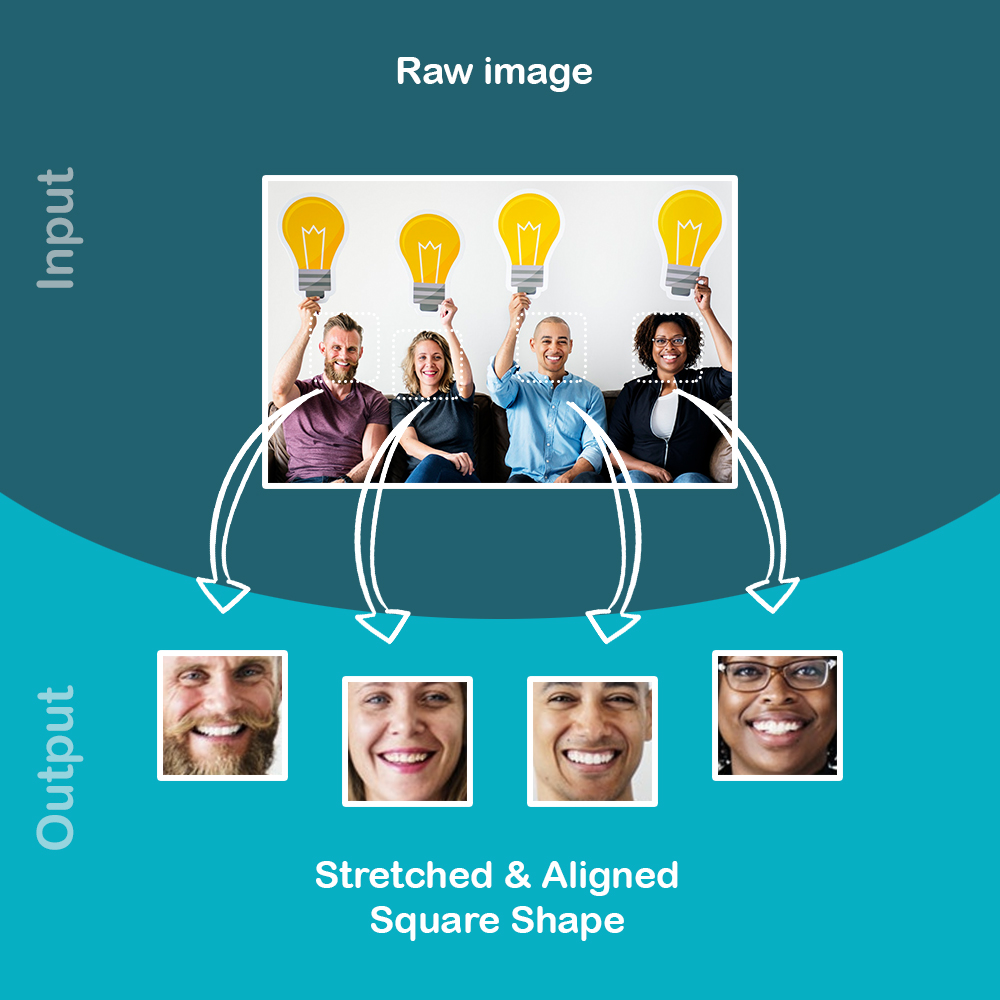
The process uses a 68 face landmark shape predictor trained by C. Sagonas, E. Antonakos, G, Tzimiropoulos, S. Zafeiriou, M. Pantic.
from https://ibug.doc.ic.ac.uk/resources/facial-point-annotations/ to detect, crop, stretch and align faces in the same way. This allow us to get high quality faces for our algorithms.

- Python3
- Pip
- Docker
- Make
- Clone this repository in your local system and navigate to root folder.
$ git clone repository-url- Navigate to
srcfolder and create a virtual environment.
$ cd src
$ make create-env- Install required dependencies via prepare make target.
$ make install- Run your own copy!
$ make run- (OPTIONAL) If you want to run the application with Gunicorn, execute the specific target.
$ make gunicornOr if you need custom parameters do the following.
$ ARGS="--bind 0.0.0.0:8000 --workers 16 --worker-class gthread --threads 16" make gunicornThe tests are implemented using PyTest. In order to run them execute:
$ cd src
$ make testYou can use the project via Docker using the following image https://cloud.docker.com/repository/docker/jtorregrosa/face2face-face-align-api
$ docker run -it -e NUM_WORKERS=2 -p "8000:8000" jtorregrosa/face2face-face-align-apiThis will expose on http://127.0.0.1:8000 the Swagger API docs and that's all!
- APP_ENV: Application environment (dev|prod)
- SECRET_KEY: Application secret key
- NUM_WORKERS: Number of workers (recommended 2 * available_cores)
- WORKER_CLASS: Gunicorn worker classes (http://docs.gunicorn.org/en/stable/settings.html#worker-class)
- NUM_THREADS_PER_WORKER: Number of threads per worker (recommended 2 * available_cores)
When the project is fully deployed, you will get a set of endpoints. Those endpoint will allow to extract faces present in an image.
This endpoint will extract only the largest face in the provided image:
{base-url}/api/align/single/{size}
You must provide a path parameter indicating the desired output size. This value must be > 0.
The endpoint accept a content-type of application/x-www-form-urlencoded with a parameter file holding your image.
An example of the response:
{
"processTime": 0.49076399999999865,
"targetSize": 12,
"inputType": "png",
"data": "base64-image-1"
}This endpoint will extract all the faces present in the provided image.
{base-url}/api/align/multiple/{size}
You must provide a path parameter indicating the desired output size. This value must be > 0.
The endpoint accept a content-type of application/x-www-form-urlencoded with a parameter file holding your image.
An example of the response:
{
"processTime": 0.49076399999999865,
"targetSize": 12,
"inputType": "png",
"imageCount": 1,
"data": [
"base64-image-1",
"base64-image-2",
"base64-image-3"
]
}- Flask - The web framework used
- Flask-RESTPlus - Flask REST Extensions
- Swagger - API Documentation
- DLib - C++ toolkit containing machine learning algorithms
Please read CONTRIBUTING.md for details on our code of conduct, and the process for submitting pull requests to us.
We use SemVer for versioning. For the versions available, see the tags on this repository.
- Jorge Torregrosa - Main Developer - jtorregrosa
See also the list of contributors who participated in this project.
This project is licensed under the MIT License - see the LICENSE.md file for details
The license for this dataset excludes commercial use. So you should contact a lawyer or talk to Imperial College London to find out if it's OK for you to use this model in a commercial product.
https://ibug.doc.ic.ac.uk/resources/facial-point-annotations/
C. Sagonas, E. Antonakos, G, Tzimiropoulos, S. Zafeiriou, M. Pantic.
300 faces In-the-wild challenge: Database and results.
Image and Vision Computing (IMAVIS), Special Issue on Facial Landmark Localisation "In-The-Wild". 2016.
You may need a self-trained model to use this project for commercial purposes.
- C. Sagonas, E. Antonakos, G, Tzimiropoulos, S. Zafeiriou, M. Pantic - For their amazing job in face annotation tasks
- Greg Obinna - For his post about Flask fro production (https://medium.freecodecamp.org/structuring-a-flask-restplus-web-service-for-production-builds-c2ec676de563)
- Cole Murray - For his post about Facial Recognition using TensorFlow (https://hackernoon.com/building-a-facial-recognition-pipeline-with-deep-learning-in-tensorflow-66e7645015b8)
- David Sanberg - For his research and work on FaceNet (https://github.com/davidsandberg/facenet)