Implementing a JGroups Transport Layer Protocol Using Netty
This project experiments with implementing a JGroups protocol using Netty; a powerful NIO Java networking framework. JGroups is a reliable Java messaging service built by Bela Ban and used by many applications such as Infinispan and the JBoss clustering service. The current JGroups transport layer is a bespoke blocking TCP protocol. In this project, a Netty based protocol was created and benchmarked on throughput against the TCP protocol. The benchmarking was done using the UPerf test included in JGroups and was run with an exponentially increasing payload and cluster size. The results from this test showed up to a 62% increase in throughput with Netty when the payload size was at 1MB with a cluster size of 12 nodes on 12 VMs. Furthermore, Netty on average had a 14% increase in throughput than TCP with a limited amount of threads, while TCP thrived with a higher thread count due to the one thread per connection model used in JGroups[1]. Moreover, at 45 nodes with a thread pool of 500 threads, Netty performance was down by -11% on average compared to the 200 thread where it was up by 13%. The results of this project suggest Netty could potentially be used instead of TCP for use-cases that have limited resources and are expecting many concurrent users.
The use of distributed systems in the industry has increased
dramatically over the last decade. One of the key technologies behind a
successful distributed system is its ability to efficiently communicate
with other systems. The communication needs to be stable and have the
capacity to produce high throughput during peak loads. A common choice
within the industry is JGroups[2][3]; a widely used Java toolkit for
reliable messaging exchange created and maintained by Bela Ban. Features
of the JGroup stack includes the support of protocols such as TCP/UDP,
reliable unicast and multicast, failure detection, node and cluster
creation, cluster management and more. Currently, JGroups uses the
built-in java.net package to handle the transport layer and
networking. This can be extended to use a different implementation if
needed that can be adapted for different requirements.
The current implementation of JGroups transport layer includes blocking I/O operations that could hinder performance with many concurrent connections. It uses a thread per connection model that creates a significant amount of overhead, which could impact the scalability of the implementation. An implementation of the transport layer can be made using a non-blocking I/O (NIO) framework, that can be integrated with JGroups. Using an NIO framework will decrease the number of resources required for concurrent connections. Netty is an increasingly popular [4] non-blocking I/O framework for implementing client-server protocols in Java. Using an NIO framework underneath JGroups is strongly believed to enhance the performance under higher loads. Furthermore, using Netty is believed to make the process of integrating new features such as SSL simpler. Additionally, Netty is maintained by the Netty Project team who will constantly release new updates and releases which is likely to increase performance overtime.his can be useful for projects such as JGroups since their key commitment is not to micro-optimize their transport layer. Therefore, by having the transport layer made a third-party dependency, JGroups can have up to date code that will improve over time.
The primary motivation for this project is to experiment with Netty to see if any performance advantages could benefit JGroups. Besides, making the transport layer more independent than the rest of the JGroups application is also a motive for the maintainer of JGroups. Ban indicates that the vast majority of the customers who use the JGroups project also have Netty as an existing dependency. This makes deploying JGroups with Netty to existing customers trivial, in conjunction with the added benefit of performance improvement through an NIO framework.
Throughout this project, Netty will be integrated into JGroups to the point where it is possible to run the performance tests shipped with JGroups. Collecting and analysing the test results will provide key metrics and statistics that can be used as a comparison against the industry-standard custom TCP protocol developed by JGroups for their application. Also, several optimization techniques for Netty will be studied and used to evaluate the performance difference.
To develop a Netty based transport layer for JGroups and evaluate the performance of the implementation with the current standard.
-
Research a number of optimization techniques for Netty and apply them during development.
-
Implement a TCP based transport layer using Netty and integrate it into JGroups so that the existing performance tests successfully work.
-
Evaluate the performance of the Netty implementation against the industry standard JGroups TCP protocol.
For the project, the development process will be closely integrated with the lead developer of JGroups, Bela Ban. He will be able to provide feedback and improve the solution through each iteration. There will be several tasks that will need to be implemented to achieve the final solution. This would be best suited to follow use the principles of the Scrum framework, in the sense that there will not be any sprints or stories but by working in an agile development mindset, where there is constant collaboration and quickly reacting to changes in requirement.
JGroups is a Java framework for reliable messaging created by Bela Ban while being a postdoctoral researcher at Cornell University [1]. JGroups was then used by JBoss where Ban continued to work on the project alongside the JBoss group. Today, it is still used within JBoss and many other open-source applications across the industry.
JGroups uses the notion of members and groups or more commonly known as nodes and clusters. Each node can be a part of a cluster and can reside on different hosts machines. Moreover, it is also possible for one host to have multiple nodes and those nodes could belong to different clusters. Every node has the ability to join, send and receive messages from a cluster. Similarly, a cluster can notify other nodes in the cluster when a new node has joined or left the cluster. JGroups manages the member to member communications and other low-level details which the user does not need to be too concerned about. Since JGroups is built using different layers the user only needs to be concerned with the top-level abstraction. The layers used can be described as the protocol stack. Different configuration of the stack can be made for different needs. This can include using different protocols for the transport layer which will be the key focus of this project.
One of the protocol stacks JGroups needs to function is the Discovery
protocol. JGroups ships with multiple discovery protocols that can be
used to find the other members in the cluster. This is very simple for
UDP as all members can broadcast messages to discover each other.
However, for TCP since there is no multicast support, the members need
to find each other through a predefined way. TCPPING included in
JGroups is a way for other members to find each other. The basic idea
behind TCPPING is that some selected cluster member assumes the role
of well-known hosts from which the initial membership can be retrieved
[1]. TCPPING will also probe the known hosts on a specified port
range to find other members. This will affect how the Netty
implementation will be designed later in the section.
For JGroups members to communicate with each other, they must first
create a JChannel, which behaves like a socket. When a client connects
to a channel, it passes the name of the group as the parameter. The
protocol layer is responsible to ensure that channels with the same name
can connect. Thus each connected channel will have an associated group
name. If the protocol cannot find a channel with the given name, then it
will create a new group with the name and connect the member to it. If
the channel exists then it will connect the new member to it and create
a new view that will be passed to all other members; notifying them of
the new member. In some cases groups may become split into subgroups
however JGroups can handle this partition by merging the subgroups back
together through a merge event. The task of merging the substates must
be done at the application level since JGroups will not have any
knowledge of the states of the application. There are multiple ways to
handle the merging task, one of the more simplistic solutions being the
primary partition approach. This approach assigns one of the sub-states
as the primary partition. All other non-primary partitions must drop
their states and re-initialize from the primary partition.
Netty is an open-source non-blocking I/O client-server framework for low-level network applications. It was originally developed by JBoss and currently maintained through the Netty project community. Netty greatly streamlines network programming such as TCP and UDP socket servers. Netty has built-in support for HTTP, HTTP2, Google protocol buffers, WebSockets SSL/TLS etc. However, for this project, many of those features will not be needed since the only requirement is to transmit packets end to end. The main advantage of Netty over the standard Java networking API is the ability to use asynchronous non-blocking operations, in conjunction with the reactive programming paradigms to achieve high performance. Furthermore, Netty ensures the events have an ordered relationship making it ideal for networking application.
Since Netty uses an asynchronous client-server model as the core architecture, only a client can initiate a request. The server can accept and write to the accepted connection but cannot initiate any requests. This can be problematic for applications such as JGroups since it uses an architecture that is similar to peer-to-peer. However, later on in the paper will discuss a design that can overcome this issue.
Netty uses the concept of channels (similar to JGroups) to establish a
connection between a client and a server. The channel represents an open
connection to an entity where it is capable of doing I/O operations such
as reading or writing. The client can bind itself to a local address and
port and can then connect to another remote address through a connection
call. Due to the non-blocking nature, a connection call will return
immediately while the operating system is establishing a connection with
the remote address. For the programmer to use the channel, a connection
call will return a channel future object. The channel future object is
an extension to the built-in Future type in Java which represents the
result of an asynchronous computation. From there, the programmer can
define the next steps after the connection is established through the
channel future object.
After a channel is established, messages can flow inbound and outbound
through the channel. These messages are passed through a pipeline which
is built during the construction of the server and client configuration.
The pipeline consists of a series of handlers that are internally stored
as a doubly-linked list. A handler is responsible to notify the users of
events that have been triggered. The events can be categorised by their
relevance to an inbound or outbound data flow. This can include events
such as data reads, writing or flushing data to sockets, opening or
closing connections etc. The user is notified of these events through
callbacks which are invoked by the handlers. An invocation of the
callback will trigger the next handler in the pipeline which will
propagate each event to the end of the pipeline. The event flows through
a chain of ChannelHandlers which can be seen in figure
1.
![Inbound and outbound events flowing through a chain of Channel Handlers [5]](images/nettychannel.png)
To send data across the wire, the user must write to the channel which will then be flushed down to the OS which is then sent to a remote peer as a stream of bytes. The flush operation is expensive to perform as it requires system calls which often contain a significant performance overhead. Reducing the occurrence of the usage of the IO Flush system call can greatly improve performance in Netty. Netty’s method of transport is a stream-based protocol such as TCP/IP. This comes with a small caveat when reading the data; in this method of transport, the receive buffer will be a queue of bytes instead of a queue of packets. However, the nature of TCP guarantees the order of the bytes will be the same as what the client has sent [5]. Consequently, the client must defragment the data for deserialization. This can be done through channel handlers in the pipeline which will be later discussed in the design and implementation section.
Improving performance is one of the key objectives of this project. This section will talk about some general techniques that can be used to improve the throughput of the final solution.
The operation to flush data onto the network can be very expensive as it may trigger system calls. These calls can be blocking and cause low throughput if allowed to be executed concurrently with a short period [6]. To reduce the number of system calls during peak load, the messages can be batched and sent through with one system call. Netty by default enables Nagle’s algorithm[5], which is a means of improving the efficiency of TCP/IP networks by reducing the number of packets required for data transmission. Conveniently, Netty also provides a channel handler that can be included in the pipeline which consolidates multiple flushes. However, this sacrifices latency as more messages will not be flushed straight away as there is a time delay due to the nature of batching messages together. This handler can be used with Nagle’s algorithm to try to reduce the number of system calls required to send messages.
The nature of the Java Virtual Machine (JVM) restricts the programmer in memory management. The JVM has no guarantee that the memory allocated to the programmer will be continuous [7][8]. However, for OS-level I/O operations, continuous memory is needed. This is usually achieved by copying the data to a native memory before the OS needs to perform any I/O operations. This can be optimized if the programmer can use continuous memory from the start to avoid the unnecessary copy at the OS level. One potential solution is to use direct memory buffers provided by both Java and Netty. Direct buffers can be beneficial if the buffer is long-lived. However, the allocation of direct buffers is very slow and should be used sparingly. Another disadvantage of the direct buffer is the management of reference counting maintained by the programmer. Improper use of reference counting or not releasing the buffer can lead to memory leaks in the application.
On the other hand, pooled buffers provided by Netty could also improve
performance when compared to the native heap memory buffers Java
provides in the Java.nio package. Pooled buffers take advantage of
pooling buffers together to improve performance and minimize memory
defragmentation. This is done by using an efficient approach to memory
allocation known as jemalloc [9][10]. This reduces the overhead
from multiple memory allocation system calls, which means an improvement
in performance. Moreover, using Netty’s buffer allocator could improve
performance with new releases and updates over time.
Ultimately, the allocation of memory is an expensive operation and should be minimized as much as possible; equally, fragmentation of memory can further decrease the performance since more time will be spent looking for space to write data. Not only can this be achieved by allocating a large amount of memory first and then reusing it throughout the application life, but also through the use of Netty’s pooled buffer allocator. The use of a direct buffer is only beneficial if the buffer is long-lived otherwise, it can be slow and should use a pooled buffer instead. Even so, the operations of allocating, deallocating and copying memory should be minimized as much as possible to perform at close to maximum efficiency as possible.
For Unix machines, Netty provides packages that can take advantage of the native system calls exposed by the operating system. More specifically the scalable Linux epoll notification system API; used to monitor multiple file descriptors to see if I/O is possible [11]. Without native transport, Netty uses NIO Channels to manage I/O operations. This method can be deployed on any machine using any OS but comes with compromises to deliver the same capabilities on all systems. Conversely, the epoll implementation provided by Netty uses the Java Native Interface (JNI) that enables code running in the JVM to be invoked and invoke native libraries. This can improve performance under heavy load when compared to the standard NIO package. However, this is only available for Unix machines.
Java uses a Garbage Collector (GC) to automatically manage dynamic memory used by the application. All objects created by using the new keyword are allocated on the heap. The developer cannot explicitly manage the memory, instead, it is implicitly managed by the GC at run time. The invocation of the GC can consume resources that are needed to perform I/O operations, impacting performance. Reducing the number of objects used on the heap can visibly increase performance at higher loads. Trustin Lee, an engineer at Twitter compared the performance difference between the buffer allocators used in Netty 3 and Netty 4. Netty 4 uses a pooled buffer allocator and showed that it produces 5 times fewer garbage objects than Netty 3 [12].
The nature of asynchronous programming used by Netty means objects are
returned to represent a result of an operation. If there are 1k write
calls then Netty will create 1k ChannelFuture objects on the heap. If
the programmer is not using these objects, then this will be cleaned up
by the GC using up more resources to destroy the objects and deallocate
memory. To reduce the number of garbage objects produced, Netty provides
a voidPromise object that can be passed to any operation that returns
a ChannelFuture object. This creates an object that is shared among
all other operations. This, in turn, reduces the number of resources
consumed by the GC. However, this also means the programmer has no way
to know if the operation was successful. The only way to know if it was
unsuccessful is if the operation resulted in an exception.
A threading model specifies how code is going to be executed. It is vital to understand how this is applied to the code being written by the developer. Improper uses of threading can have negative side effects that could decrease performance or throughput. Creating and destroying threads can be very expensive. A better approach to multi-threaded applications is to use a thread pool and submit tasks to the pool. A basic thread pooling pattern can be described as: [9]
-
A thread is selected from the pools free list to execute a submitted task.
-
Once the task is completed the thread is returned to the pools free list, available for reuse.
Although this reduces the cost of creating and executing threads, it does not eliminate the cost of context switching. To solve most of the complex challenges faced with multithreaded applications, Netty uses Event Loops to simplify the process for the developer. An Event Loop runs exactly one thread that never changes where tasks are submitted to be executed. Figure [fig:codesnip] shows the idea behind an Event Loop. To manage multiple resources an Event Loop Group can be used to handle multiple Event Loops. This can distribute the workload using the thread pool.
while (!terminated) {
List<Runnable> readyEvents = blockUntilEventsReady();
for (Runnable ev: readyEvents) {
ev.run();
}
}In a multithreaded application, different tasks have different states of memory during execution. Depending on the OS, each task only gets a certain amount of time to execute on the CPU, after which another task is loaded to execute. When switching between one task to another it is called context switching [13]. In the context of threads, context switches happen when the execution needs to be switched to a different thread. To reduce context switching, Netty provides the ability to submit tasks to execute in the event loop directly without needing extra dispatching overhead.
During the implementation phase of the project, the standard industry tools used to develop JGroups will also be used for this project. This includes a Linux machine, git for version control and IntelliJ integrated development environment. Using the same tools helps the developer to adapt the workflow much faster than a new method. Furthermore, using a Linux system enables performance testing on the use of native transport layers supported by Netty. Benchmarking on a Windows environment is out of scope for this project as the time available for this project is very limited. Further detail will be explained later in this section.
The use of public cloud services such as Google Cloud can be used as a testing environment to evaluate the performance Netty provides. This public cloud provides a stable environment which provides consistent performance throughout the test. However, the resources available in the public cloud are limited within the price range this project can afford. This may not reflect the production environment that this will be deployed in. This could be solved through the use of existing infrastructure the University can provide as a form of private cloud. These resources can be matched as close as possible to the ones used in production in the industry. However, this can be much slower to set up than the public cloud services as well as an increase in costs. A combination of both services may be used to evaluate the performance in both public and private cloud services.
JGroups ships with two performance tests: MPerf and UPerf. Both will output a throughput figure which is the feature that will be used for evaluation.
MPerf measures the performance of multicast communication. This does not mean IP multicast, but point-to-multipoint performance[1]. This captures the load of a one-to-many message application. This works by each node taking, in turn, to broadcast an x amount of messages (set by the user) to every other member. Each member then waits for the predefined number of messages to be received before they take their turn to send messages. At the end of the test, a number of statistics will be displayed by the program including the throughput which is the key value the project will be used for evaluation. In this type of test, the throughput is expected to be very high in comparison to UPerf.
UPerf measures the performance of point-to-point communication in a cluster. In contrast to MPerf, every node can invoke synchronous remote procedure calls (RPCs) on the members. Each request will have a probability of either mimicking a GET request or a PUT request. By default, the probabilities are set to 80% GET and 20% PUT. The GET request is small and returns a 1k response. In contrast, a PUT request is bigger at 1k and returns a small response. The GETs and PUTs emulate a distributed cache where the GETs query the information from the cache and the PUT request updates the information[1]. According to Ban, this test closely represents the load they have in production.
One of the main challenges with using Netty is the client-server model it imposes on the developer. As explained in the previous section, only a client can initiate requests to any other remote peer. This presents an interesting challenge when integrating Netty into JGroups. JGroups needs a peer-to-peer architecture to communicate with the other members. Therefore each member will need a client for outgoing messages and a server for incoming messages. The section below gives two approaches that try to overcome this challenge.
The simplest approach is to have an instance of a client and a server for each node. All outbound messages are passed through the client while the inbound messages are received by the server. This creates two simplex channels per connection to emulate a full-duplex communication. Figure 2 below shows the flow of communication between the members for a cluster size of 3.
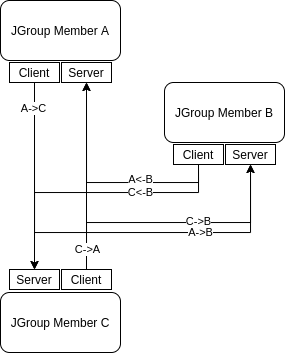
This method can completely separate both write and read operations. In theory, by having this separated it should produce a higher throughput since the capacity of each channel is much higher than if it were a full-duplex channel. Each channel only needs to handle one direction of traffic at max capacity. However, this requires (N(N-1)) connections for a full-duplex communication where (N) is the number of nodes in the cluster. This comes with the tradeoff of having a lot of overhead with an increasing number of members in the cluster. The number of channels that has to be managed is double the number of total nodes in a cluster. This can potentially impact performance and throughput since the bottleneck will be at the speed of write and read operations for each node and not the bandwidth of the channel.
The main area of concern that comes with the previous design is the overhead that follows with handling more channels than necessary. Every instance of a channel has an instance of the channel pipeline. More channel pipelines increase the garbage produced by the pipeline handlers. This could reduce the performance of the overall application. Once a connection is made it would be preferred to reuse that connection rather than create a new one.
Since the nodes are discovered using TCPPING protocol described in
JGroups, each node must accept the incoming request at a specified port
range. The solution is to simply reuse a channel that is already
connected. However, this comes with a challenge. Consider a simple
cluster with two members; Node A and Node B both of which are known
hosts. The list below shows the assumptions for this particular
scenario.
-
Initially, both members are offline and both nodes A and B are known initial hosts.
-
Node A comes online first.
-
Node B comes online after Node A.
-
Node B can discover Node A since it is one of the known initial hosts.
However, when Node A periodically looks for other known hosts, it will not recognize the connected channel since the remote address of B is not in the known list. This is because B will connect with its client which will be assigned to a random port. This can not be known before run time and therefore will not be on any known lists. Node A will only see B’s Client and will mistake it for another Node (B`). Hence, Node A will try to probe B’s server even though B is already connected. Figure 3 illustrates the connection between A and B before A connects to B again.
.png)
Node A in figure 3 knows it is connected to a server with the port 3451. Node B is connected to A on port 7800. When A periodically sends a request to the known hosts (in this example 7801), Node A will see that it’s not connected and send another request leading to two connections for two nodes; same as the previous solution.
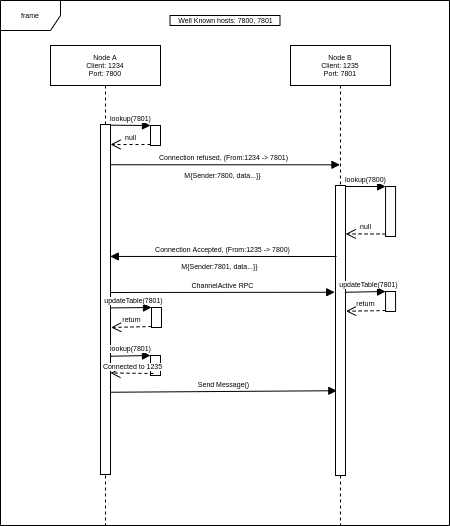
To solve this, each member can use a lookup table for outgoing connections. All outgoing messages will include their well-known address in the message. Once a Node has an incoming message it will be able to see which server (well-known address) the incoming message is associated with. The receiver can then add an entry into the lookup table that matches the sender’s well-known address to a channel. When Node A needs to send a message, it can use the lookup table to reuse a channel that is already connected. Figure 4 shows the flow of connections between two nodes. In these examples, the assumption is made that Node A is alive first and then Node B comes online after some unknown time. However, with this design special care must be taken for an edge case. Consider an example where both Node A and Node B send a connection request at the same time. Both Nodes must have a deterministic way to refuse one of the connections. An approach is to close the connection if the incoming well-known address and connected address are equal.
Simply put, the last connection to be established will get closed from the initiator. This statement will only be true for the second connection attempt and only for one Node. For this reason, only one channel will be closed.
There are two main components to implement for Netty to work with
JGroups. First, is to create the Netty connection process based on the
designs described in section 3.2. Next, is to
build on top of the connection class to create the new JGroups protocol.
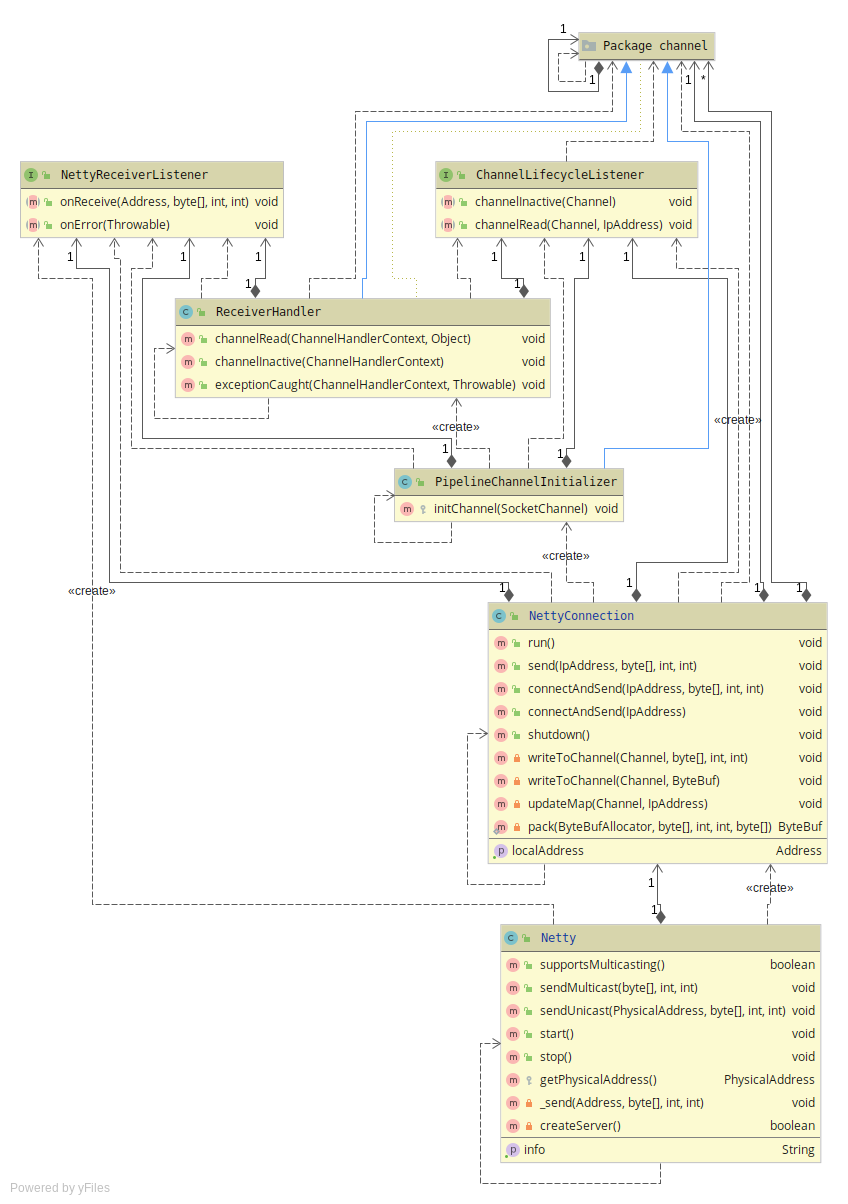
The connection process is encapsulated by the class NettyConnection.
This is then used to make the protocol class Netty that is used by
JGroups and ties all the other classes together. To integrate the Netty
protocol into JGroups, the class extends the abstract TP class. This
class is the transport layer that is used in JGroups for any class that
deals with the network. In this solution, the class Netty provides the
functionality required for JGroups to pass messages up and down. The
message is passed up through the JGroups stack once it is received as
a byte array and the messages are passed down through the stack until
it reaches the protocol level in the form of a byte array, an
illustration of the JGroups protocol stack can be seen in figure
5. When NettyConnection receives a message it will
use the provided callback to the Netty class which will then pass the
message up. When the Netty class receives a send request, it will
call NettyConnection.send() to send the message. The UML diagram in
figure 6 shows a high-level view of the implemented class
with dependencies.
![Message flow through the JGroup stack [1]](images/Diss%202%20drawing-Page-6.png)
In this implementation, the user can choose to use the native transport
if they wish to do so through the configuration file. This is done by
setting the following options use_native_transport="true". If not
enabled, the protocol will use the NioEventLoopGroup. For the server,
there are three thread pool groups in total: boss group, worker group
and an event executor group. For each thread, the number of threads can
be specified in the constructor. The protocol uses a single thread for
the boss group since its only job is to accept the incoming connections.
The use case for JGroups does not include many concurrent connections so
1 thread will be enough to handle all the incoming connections. The
worker group thread pool deals with decoding, writing and sending the
messages. This thread is also shared with the client object. For this
reason, the number of threads is kept to the default value of
(2 * The Number Of Cores Available). The Event executor is a separate
thread pool with 4 threads that are used for the receiver handler. This
is done because the receiver can block the thread while the messages are
passed up the protocol stack in JGroups. Therefore, the
ReceiverHandler will not block the NioEventLoop allowing them to
keep reading and writing data.
To keep the pipeline as short as possible, only 3 handlers are added to
the pipeline. Keeping the pipeline short reduces the amount of work
required for each message thus increasing efficiency. The three handlers
are FlushConsolidationHandler, LengthFieldBasedFrameDecoder and
ReceiverHandler. Figure 7 shows the flow of inbound
and outbound messages through the pipeline.
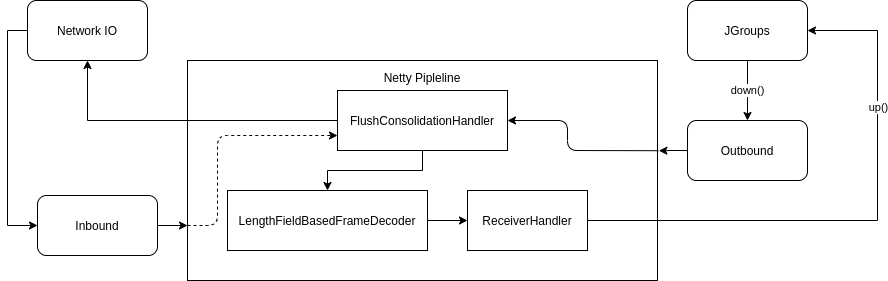
The purpose of the Flush Consolidate flush handler is to batch up multiple flush operations together to reduce the number of overall flush operations. This handler is an extension of a duplex handler, meaning that both inbound and outbound events are passed through it. As a result, this handler is added as the head of the pipeline. As a result, all outbound messages get consolidated before the expensive flush operation is invoked. However, all inbound messages must also pass through the Consolidation Handler which is unnecessary and could impact the performance slightly.
The Length Based Frame Decoder is a built-in inbound channel handler
provided by Netty. It is used to decode any incoming messages based on a
length field parameter. The constructor takes 3 parameters which define
the behaviour of the handler. The parameters include Max-Frame Length,
Length Field Offset and Length of Field. The most important
parameter is the ‘Length of Field’ parameter as this defines the length
of bytes that the decoder should wait for until it can start to process.
This is set to 4 bytes which is the size of an integer in Java. However,
the decoder also accepts the sizes 1,2 and 8 as they represent byte,
short and a Long respectively. All of the sizes except 4 are represented
as a Long type internally by Netty.
After the decoder receives the 4 bytes, it will convert it to an integer
to get the value of the remaining bytes that are yet to arrive. The
arriving bytes are appended into a ByteBuf (Netty’s ByteBuffer
implementation) until the required amount is received, after which, the
buffer is passed along to the next channel handler in the pipeline; in
this case the last handler in the pipeline, the Receiver Handler.
The job of the receiver handler is to parse the ByteBuf that has been
received from LengthFieldBasedFrameDecoder handler into a byte array
that can be used by JGroups. The receiver handler uses the ByteBuf to
read two integers to get the total length and address byte array length.
This handler is annotated with the sharable property which enables Netty
to only use one instance of the handler for all the channels created. To
reduce allocation, the receiver handler creates a byte array with a size
of 65000 at initialization which acts as a buffer for any incoming data
The buffer is also shared amongst the other channels. The data from the
ByteBuf object is read into the shared buffer which is passed to
JGroups using a synchronized call. This will make sure no two threads
access the array at the same time.
As previously mentioned, the data is passed down to the Netty protocol
from JGroups is in the form of a byte array with a length and offset
parameter. This is then packed into a byte buffer object along with a
reply address. Furthermore as previously stated, the transport mode of
the network communication is a TCP/IP stream. The channel handler needs
to wait for all the bytes to arrive before it can begin to process the
data. To handle this a length based frame decoder can be used as one of
the inbound channel handlers. Netty provides the class
LengthFieldBasedFrameDecoder to handle cases where the length of the
messages are not fixed. First, the decoder waits for a fixed amount of
bytes to arrive. For this application, the length field is set to 4
bytes, the size of an integer in Java. Next, it decodes the 4 bytes to
get an integer which indicates to the decoder the number of bytes that
are yet to arrive before the frame is complete. The decoder will then
wait for those amount of bytes to arrive, before completing the frame
and reading the data into a byte array ready to be passed along to the
ReceiverHandler. The structure of the packet can be seen in figure
8.

The Length field is the combined total 4 bytes for the address length field, the bytes required for the address and the bytes required for the data from JGroups. [Length = 4 Bytes + Address Byte array + Data Byte Array] Decoding the frames are handled in the receiver handler. It is the same process as encoding but reading instead of writing. The handler will read in two integers, the total length and address length which is used to read in the rest of the data. The payload length is calculated as follows. Using these lengths the message can be properly deserialized and used by JGroups. [DataLength = TotalLength - 4 - AddressLength]
Integrating the Netty code base with JGroups was a fairly
straightforward task since JGroups provides a superclass TP that can
be extended to make any transport layer. The child class only needs 2
functions that need to be written, sendUnicast and sendMulticast. To
pass a message up to JGroup the receive function needs to be invoked.
On account of Netty’s asynchronous approach, a callback is needed to
invoke the receive method. An instance of a callback is made in the
Netty protocol class which is then passed into the NettyConnection
class. The NettyConnection class will then pass the data into the
callback where it will invoke the receive method. As mentioned before
the invocation of the callback must be synchronised to make it
concurrent, so the shared buffer is not accessed by different threads.
as possible, allocated arrays are reused so new allocation is not needed. The receiver handler takes advantage of this by reading in both the address and payload into a single byte array, which is then passed into JGroups with offsets via the receive function; after the method returns, the byte array is free to be used again without a new allocation or deallocation calls.
Additionally, Netty’s implementation of buffer allocator is also used to encode the messages before flushing. The allocator uses a pooled buffer which further reduces allocation and deallocation calls. Each channel in Netty has a reference to an allocator which is invoked when a message needs to be sent.
One other optimization technique used is adding the ability to share the
receiver handler. As mentioned before in the previous section, only one
instance of the handler is made when a channel is initialised. This is
done through the use of sharable annotation Netty provides. This could
potentially reduce the number of objects created thus reducing the
number of garbage collection.
One of the default behaviours in Netty is to sample memory regularly to
detect memory leaks, named the ResourceLeakDetector. This has some
overhead that can slow down performance. The default option is set to
“simple”, this comes with low overhead but can be eliminated by
disabling the leak detector. This will produce the optimal performance
for the application with the cost of not monitoring resources for leaks.
Some small optimizations were used in the project to further improve
throughput. This includes using the native Linux epoll system when
possible; where the benefits of the epoll system are discussed in the
background section. Similarly, the use of the keyword ‘final’ was used
to allow the Just-in-Time (JIT) compiler to inline methods where
possible. Inlining methods is a means to reduce the method invocation
overhead. Instead of invoking a function, the body of the function is
expanded into wherever the method is called. This can be done manually
but will become difficult to maintain the codebase. Moreover, the use of
the consolidating flush handler is used to try and reduce the number of
system calls that are required at the cost of overall latency.
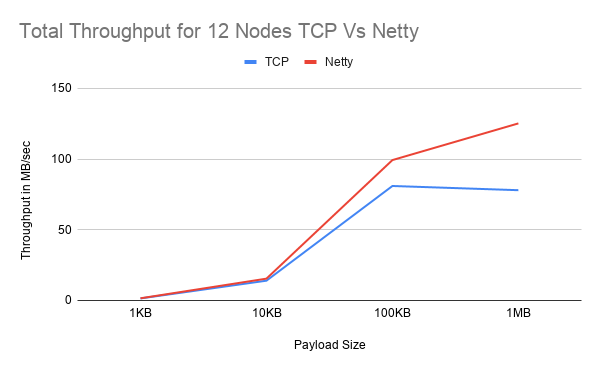
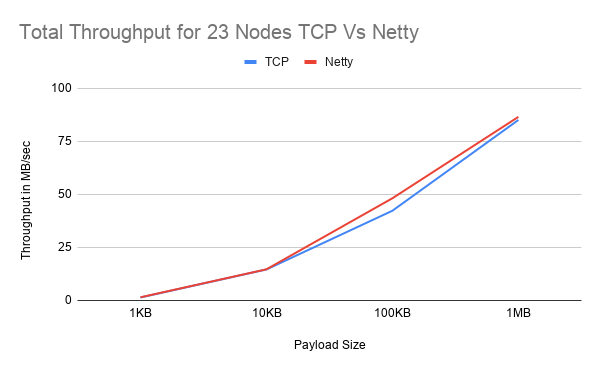
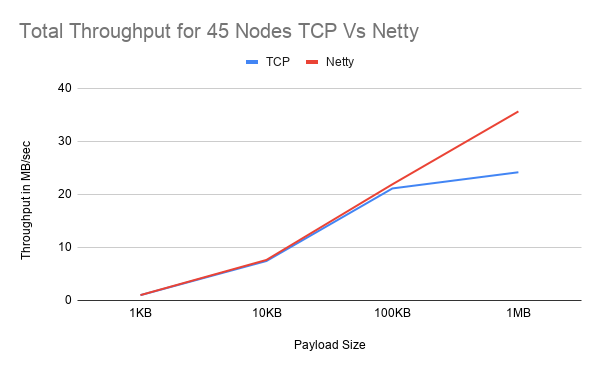
To assess the performance of the Netty implementation, two UPerf tests were run with both Netty and TCP. The throughput will be used as the key quantifiable metric that will be used to generate a comparison between the two systems. The tests were done on 12 Google Cloud VMs with the lowest hardware available. During both tests, 1 VM was reserved as the host and ran a single instance of UPerf. The other VMs had a concurrent number of UPerf tests running to simulate an increasing load. The UPerf test outputs the combined total throughput of all the nodes in the cluster. For each cluster the test was run with an exponentially increasing payload size; from 1KB to 1MB. For the first test, the maximum number of threads in the thread pool was 200 threads per node. In the second tests, the thread pool configuration was increased to a maximum of 500 threads per node. Moreover, the test was run 3 times in total for each payload and cluster size. The results were then averaged and used to create the graphs below. The two tests were done to compare how Netty and TCP will manage resources. The results can show how each implementation performs with increased overhead. Netty should perform well with lower threads counts since it is NIO and can manage resources better. The more threads that are added there is a high likelihood for Netty’s performance to be negatively impacted due to the bigger overhead of managing threads. Furthermore, since Netty is not tightly integrated with JGroups, Netty will create additional threads instead of using the ones from the thread pool like TCP does thus further increasing the already large overhead. On the other hand, TCP should do better with higher thread count with increasing cluster sizes since TCP uses one thread per connection model. Especially since the TCP solution is custom-built for JGroups, it can take advantage of the increased thread pool.
The following versions were used to measure the throughput of both TCP and Netty.
-
VM: Google Cloud N2 machine (General Purpose)
-
OS: Ubuntu 18.04 LTS
-
Netty Version: 4.1.50.Final
-
JGroups Version: 5.0.0.Beta1
-
Project build: v0.0.1-perf-test [14]
This test was run with a maximum of 200 and 500 thread per node and repeated 3 times. Unfortunately due to the huge amount of resources required at 45 nodes and 500 threads, the 1MB payload test did not work and so the results are omitted from the graphs and table.
.png)
.png)
.png)
The following tables show the performance difference between TCP and Netty. To calculate the differences the formula shown below was used. The average throughput for each payload and all clusters are shown below. [Difference = \frac{TCP Throughput - Netty Throughput}{TCP Throughput} * 100]
| Payload/Cluster Size | 12 Nodes | 23 Nodes | 45 Nodes | Averages |
|---|---|---|---|---|
| 1 KB | 6.80% | 7.04% | 0.99% | 4.95% |
| 10 KB | 10.27% | 0.41% | 2.68% | 4.46% |
| 100 KB | 22.63% | 13.89% | 3.69% | 13.40% |
| 1 MB | 60.56% | 1.70% | 47.44% | 36.57% |
| Averages | 25.06% | 5.76% | 13.70% | 14.84% |
| Payload/Cluster Size | 12 Nodes | 23 Nodes | 45 Nodes | Averages |
|---|---|---|---|---|
| 1 KB | 8.70% | -11.02% | -15.49% | -5.94% |
| 10 KB | 9.74% | -11.01% | -11.58% | -4.28% |
| 100 KB | 13.05% | 3.36% | -7.25% | 3.05% |
| 1 MB | 62.77% | 5.42% | - | 34.10% |
| Averages | 23.56% | -3.31% | -11.44% | 6.73% |
The number of nodes increased to a maximum of 45 nodes before errors were thrown by JGroups resulting in inconsistent data for both testing groups, furthermore, errors were also encountered in the second test at a 1MB payload size with a cluster size of 45. Therefore in the last test, the 1MB test was not included in the results. These errors may have arisen from potential confounding variables such as low hardware specifications or the network capacity. The volume of packets could be saturating the network causing packet loss and causing inconsistent results. Analysis of the Google Cloud network performance platform reported up to 1500ms ping at peak loads (seen in figure 15) which could also cause inconsistent results for more nodes.

However, with the results that were collected, there is a clear trend to Netty performing equally or better in all cases in the first test. Furthermore, when the payload is at 1MB, with a cluster size of 12, Netty performs 60.5% greater than TCP in the first test and 62.7% improvement in the second test. Besides, with a cluster size of 23 and 45 and a 1MB payload size, Netty still performs 1.7% and 47.4% better respectively in the first test. In contrast, in the second test at 45 nodes, Netty performs worse than TCP at an average of -11.4% and even at 23 nodes Netty still performs worse than TCP at -3.31%. This is most likely due to the overhead of 500 threads for each node. With a cluster size of 45, 11 VMs are running 4 Nodes each with 500 threads equaling 2000 threads per VM not including the threads Netty creates for the event loop. This could be the reason for the poor performance, unfortunately, due to short time constraints and resources available it was not possible to collect the usage statistics of each VM. TCP would be best suited for smaller cluster sizes with small payloads where it can potentially outperform Netty.
Overall, Netty seems to increase performance by 14% with a lower thread count and an exponentially increasing payload size but with a higher thread count and increasing cluster size, Netty seems to perform worse. Interestingly in both tests, at 23 nodes, the expected trend does not follow as there is only a small margin of performance increase in the first test and an 11% decrease in performance in the second test. Nevertheless, it can be hypothesised that Netty will perform better when there is a 1-to-1 relation between the VM and Nodes but further testing is required to prove this theory.
The project aimed to develop a transport layer for JGroups with Netty so that the existing perf test can be run against the implementation. As a result of this section, achieving the project aim can be considered a success. In addition, using the results collected from this section, it can be used to evaluate the success of the original objectives.
As shown in section 2, numerous optimization techniques were researched, mainly targeted at Netty but also some general optimization for the JVM. These techniques have been applied during the development phase. The techniques that have been utilised during development have been investigated within section 3. Based off of the output presented, this objective can be considered successful.
Implement a TCP based transport layer using Netty and integrate it into JGroups so that the existing performance tests successfully work
The Netty solution was successfully integrated with JGroups since the perf test was able to be run without issue. Furthermore, the existing JGroups protocols work seamlessly with Netty indicating the correctness of the solution. If the implementation was not correct and properly integrated, then the system will not work end to end with the existing protocol therefore it can be concluded the system does meet this objective.
Evaluate the performance of the Netty implementation against the industry standard JGroups TCP protocol
The perf tool is integrated into JGroups and was used to benchmark both the TCP and Netty for evaluation. This objective was successfully met as shown in this section. Both implementations were evaluated on their performance of throughput, the increasing number of cluster and payload size.
The key aim of this project was to make a transport layer protocol for JGroups with Netty and optimize the throughput to match the current implementation of the transport layer, TCP. In the process of creating the solution, a number of optimization techniques have been discussed that have been applied to the solution.
After implementing the solution, the performance was compared with TCP to identify any advantages Netty provides. This was done by running two throughput tests with an exponentially increasing payload size from 1KB to 1MB and increasing cluster sizes. The test was done in 12 Google Cloud virtual machines (VMs) where 11 VMs hosted from 1 to 4 instances of the test at a time. The tests measure the total throughput of the cluster. In doing so, the results showed that Netty outperforms TCP when there is an overall lower JGroups thread pool count together with increasing payload size. Performance increased up to 60% and 62% for 12 nodes on dedicated VMs in both tests with a payload size of 1MB. However, performance seems to decrease when the thread pool is increased and more than 1 instance per VM is used. This is most likely down to the fact that the increased thread pool causes a great deal of overhead in Netty than in TCP thus severely impacting performance.
Ultimately, with an exponentially increasing payload size, Netty can maintain performance while TCP struggles with higher payloads. This implies Netty would be best suited for horizontal scaling while TCP would benefit from vertical scaling due to the one thread per connection model used. This also suggests Netty is best suited to a use case when there is a 1-to-1 relation between the node and VMs. The results show with a lower JGroups thread pool count, it can handle more connections with lower resources due to the non-blocking nature. The TCP implementation performance decays with increasing payload size and connections unless the thread count is increased with the load. In the use case where more connections and with bigger payloads and more concurrent connections Netty should be used while TCP would be best suited for smaller cluster size and payload.
This paper has demonstrated some of the potential benefits that may occur when using a non-blocking framework such as Netty as the transport layer in JGroups. The results indicated that Netty can handle an exponentially increasing payload and cluster size with ease with limited resources, while the TCP implementation required more resources to match Netty’s performance.
Due to the limited resources and time available, a more comprehensive and thorough benchmarking evaluation was not performed. In future tests, cluster size from 4 nodes to 64 nodes should be run with each VM only hosting up to a maximum of 4 nodes. Furthermore, the test should be performed numerous times to get the average to reduce the level noise that may have been included in results. In addition, it would be beneficial if the tests run in this paper were re-created to see if the results are similar.
The Netty implementation is not fine-tuned for optimal performance, there may exist further optimisations that can be done to increase overall performance. One of the bottlenecks in the implementation currently faces is back pressure in the channels. Netty clients are able to write much faster than they can read and can cause pressure to build during peak loads. Currently, the Netty receive operation is closely coupled with JGroups which could be causing a delay in the read. Decoupling the read method from JGroups could improve backpressure.
In the context of back pressure, another area of improvement is the fine-tuning the values of the send and receive buffer in Netty for the application of JGroups. In addition, fine-tuning the values for the high and low buffer marks could also be looked into further.
It could be possible some of the configurations are having an adverse effect on the performance, therefore, the system could benefit from benchmarking with different configurations. Furthermore, JGroups already has TCP-NIO protocol that is largely under experimentation [1] that can be tested against. If the results are similar to that shown in this paper, then the TCP-NIO can be replaced by Netty.
Moreover, the current solution lacks any kind of unit testing which can lead to more bugs in the future. The system should be thoroughly unit tested so that it can be maintained by future developers. In addition, the new releases of Netty can be tested with the unit tests before benign used in production.
In Netty, there are a lot of parameters that can be fine-tuned. Currently, this is not exposed to the end-user. Every use case is likely to be different and the optimized parameters will not work for every application. For this reason, the end-user should be able to configure the possible options through the XML file that is already used to configure JGroups protocol stack. This will make the code base much cleaner and easier to maintain.
In the interest of increasing throughput in the cloud for TCP based protocols, a new protocol was proposed by Bela Ban [15] based on the research of Rachid Guerraoui et al [16]. In the cloud multicast broadcasting with TCP can be inefficient as the node is required to send N-1 messages, where N is the number of nodes in a cluster. Ban defines around as the time to take to send or receive a message [15]. Adding to this, it would take (x*(N-1)) rounds to send x messages to a cluster of N nodes. Ban proposed the idea of Daisy Chaining which states that instead of sending the message to (N-1) members, it can simply be transmitted to the neighbour node which forwards to its neighbours. This idea can be used to parallelize message sending and increase total throughput at the cost of latency. Using this method, each node only needs to be concerned about sending the message to their neighbours. The message will eventually be forwarded to all members. Using Daisy Chaining it only takes (x+(N-2)) rounds to broadcast the message. This drastically lowers the number of rounds required for a multicast TCP. This approach can be integrated with the current solution to evaluate the performance of combining Daisy Chaining and Netty.
[1] B. Ban, “Reliable group communication with JGroups.” [Online]. Available: http://www.jgroups.org/manual5/index.html. [Accessed: 18-May-2020].
[2] “Maven repository: Org.jgroups, jgroups (usages).” [Online]. Available: https://mvnrepository.com/artifact/org.jgroups/jgroups/usages. [Accessed: 24-May-2020].
[3] “JGroups - success stories - projects using JGroups.” [Online]. Available: http://www.jgroups.org/success.html. [Accessed: 24-May-2020].
[4] “Netty adopters.” [Online]. Available: https://netty.io/wiki/adopters.html. [Accessed: 24-May-2020].
[5] The Netty Project Team, “Netty.docs.” [Online]. Available: https://netty.io/wiki/index.html.
[6] Norman Maurer, “Netty best practices a.k.a faster == better.” [Online]. Available: http://normanmaurer.me/presentations/2014-facebook-eng-netty/slides.html. [Accessed: 15-May-2020].
[7] Oracle, “Chapter 2. The structure of the java virtual machine.” [Online]. Available: https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-2.html#jvms-2.5.2. [Accessed: 18-May-2020].
[8] G. Mirek, “Understanding java buffer pool memory space. FusionReactor,” 26-Mar-2018. [Online]. Available: https://www.fusion-reactor.com/evangelism/understanding-java-buffer-pool-memory-space/. [Accessed: 16-May-2020].
[9] Norman Maurer, Marvin Allen, Netty in action..
[10] J. Evans, “A scalable concurrent malloc(3) implementation for FreeBSD,” p. 14.
[11] T. L. man-pages project, “Epoll(7) - linux manual page.” [Online]. Available: http://man7.org/linux/man-pages/man7/epoll.7.html. [Accessed: 18-May-2020].
[12] T. Lee, “Netty 4 at twitter: Reduced GC overhead.” [Online]. Available: https://blog.twitter.com/engineering/en_us/a/2013/netty-4-at-twitter-reduced-gc-overhead.html. [Accessed: 15-May-2020].
[13] A. S. Tanenbaum, Modern operating systems, 3rd ed. USA: Prentice Hall Press, 2007.
[14] “Jgroups-netty release v0.0.1-perf-test.” [Online]. Available: https://github.com/jgroups-extras/jgroups-netty/releases/tag/v0.0.1-perf-test. [Accessed: 24-May-2020].
[15] “Belas blog: Daisychaining in the clouds.” [Online]. Available: http://belaban.blogspot.com/2010/08/daisychaining-in-clouds.html. [Accessed: 24-May-2020].
[16] “Throughput optimal total order broadcast for cluster environments ACM transactions on computer systems.” [Online]. Available: https://dl.acm.org/doi/10.1145/1813654.1813656. [Accessed: 23-May-2020].