Here I describe a machine learning model that can predict the outcome of sporting events. The name of this project is called graphRNN, as it is a graph-shaped recurrent neural network for predicting the sport of MMA. Normally RNN cells are connected linearly (one input and one output), but in graphRNN, each cell (which represents one event) has two cells as its input and two cells as its output.

- Graph of events: The strength of each fighter is determined by each one of their previous fights, and the strength of each previous opponent. This has the effect of requiring the model to understand the full graph-shaped network of event history.
- One-on-one matchups: The strength of each fighter is not a singular metric, but it also can represented as strengths or weakness against certain other fighter types. This contrasts with sports like horse racing, swimming, or track & field.
- Modest training data: The entire set of recorded professional mixed martial arts fights numbers 294,000, with most missing auxiliary information.
- High variance: For meaningful predictions, there needs to be a metric on the reliability, staleness, or variability of a metric, not just the metric itself. This requires the model to generalize well.
The performance of graphRNN can be compared to existing mathematical frameworks and benchmarks:
- Elo: This Chess-ranking system details a calculable rating (Elo) specifying player strength, and the win probability between two different Elo values.
- Glicko: An improvement on Elo, called Glicko, which adds a metric for variability (confidence) to each metric of strength.
- Vegas line: The aggregate prediction of top analysts. Each line consists of an open and a close, with the close being the more accurate.
- graphRNN (graph recurrent neural network): Our model has the potential of storing more meaningful information about player strength, while traversing the graph of fight history.

Each fighter’s strength is described as a vector. The vector is initialized as zeroes, and during training, the model decides what values to place at which locations in the vector, based on predictive ability. The strength vectors are then updated after each fight, with the winning and losing fighter each receiving certain updates.
Information about the fight that we know before the fight begins - this includes:
- Numerical traits: fighter weight, height, age, time since last fight.
- Categorical traits: fighter home country, fight league, fight country.
- Fighter strength vector: each fighter’s strength vector are included in the input data.
Information about the result of a fight. This data is used to augment the fighter strength vectors after each fight, but not used to predict the outcome of the fight.
- Traits: outcome(win, loss), end round, method of victory, closing odds, significant strikes, fight statistics.
The model does have a built-in concept of symmetry, where the layer nodes are mirrored between fighters A and B, and each fight is trained along with its mirror image. Other than symmetry, the model does not have knowledge of the space - all layer nodes are initialized randomly.
Training was performed using tensorflow 1.11.0 on an iMac Pro. The optimizer’s loss function was mean-squared error between the prediction and actual result. The model trained on the data set repeatedly, with the learning rate decreasing over time.
The resulting error (loss) of graphRNN, as measured by mean-squared error, is 0.2114, which is comparable to the Vegas line. This shows that a well-structured machine learning model can perform at comparable levels to top analysts, and greatly outperforms existing mathematical frameworks. A loss of 0.2114 means that graphRNN predicts even-odds fights with an accuracy of 54%, which is better than the 53.4% accuracy of the opening Vegas line.
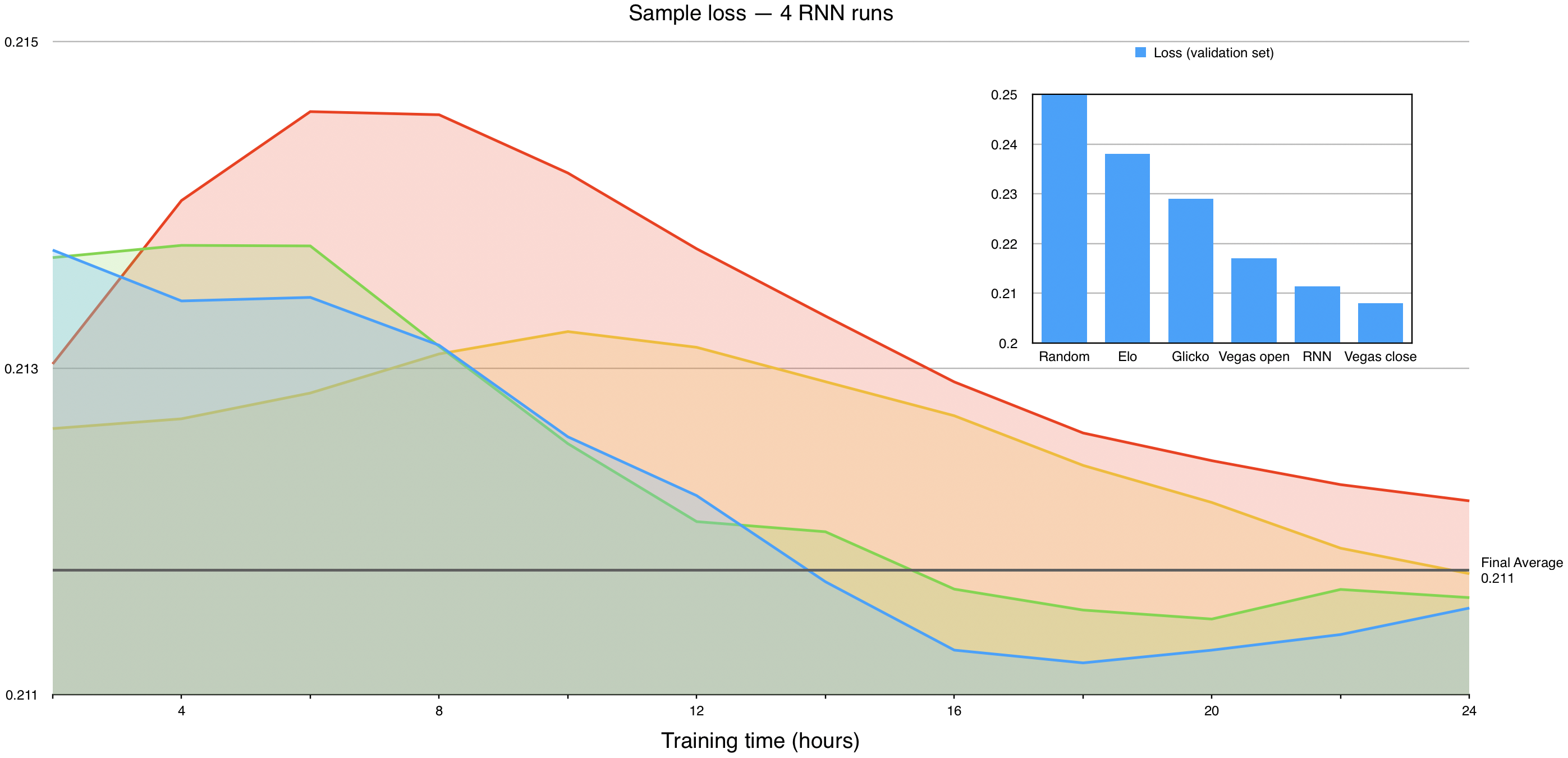 The training data comprised the first 80% of the fight history, and the above are results from the separate validation set.
The training data comprised the first 80% of the fight history, and the above are results from the separate validation set.
- Adam Optimizer
- Dense layer
- Sigmoid
- Relu
- Dropout
- Loss (mean squared error)
- Feature column
- RNN cell
- LSTM cell
- One primary challenge was speeding up the training time on the intertwined events. Since Tensorflow performs batches quickly, it was important to batch together the training of fights that were independent of each other. Therefore each batch corresponded to a level in the fight history tree. Doing this improved the training time by 20x.
# Calculate the level in the fight tree for this fight. 0 is bottom level (leafs of tree)
fightLevel = max(f0Level, f1Level)
level = levels[fightLevel]
level.append((fight, f0, f1))
- Since the graph/tree structure of RNN units was not standard to most machine learning problems, a special save & restore path was need to restore node weights from one run to the next.
for i, savedValue in enumerate(saved):
savedVar = tf.convert_to_tensor(savedValue)
assignments.append(tf.assign(trainables[i], savedVar))
sess.run(assignments)
- A custom web scraping engine was built to scrape historical MMA data from the websites of Sherdog, ESPN, Fightmetric, FightAnalytics, and BestFightOdds. (Selenium and HTTP requests)
header = {‘User-Agent’: ‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11’}
req = urllib.request.Request(url, headers=header)
usock = urllib.request.urlopen(req)
- Many experiments were run to tune hyperparameters and feature engineering.