- Features expectations
- Estimations (scale required, database sharding, caching, load balancing, etc)
- Design goals (latency required, CAP - consistency, availability and partitioning, ACID SQL properties - atomicity, consistency, isolation and durability, BASE NoSQL properties - basic availability, soft-state and eventual consistency)
- Skeleton of the Design
- Deep dive into above statements - API endpoints, client requirements, if sharding, how to consistent hash, security, randomness, etc
Published by Eric Brewer in 2000, the theorem is a set of basic requirements that describe any distributed system. If you imagine a distributed database system with multiple servers, here's how the CAP theorem applies:
- Consistency - All the servers in the system will have the same data so users will get the same copy regardless of which server answers their request.
- Availability - The system will always respond to a request (even if it's not the latest data or consistent across the system or just a message saying the system isn't working).
- Partition Tolerance - The system continues to operate as a whole even if individual servers fail or can't be reached.
It's theoretically impossible to have all 3 requirements met, so a combination of 2 must be chosen and this is usually the deciding factor in what technology is used.
When it comes to distributed databases, the two choices are only AP or CP because if it's not partition tolerant, it's not really a reliable distributed database. So the choice is simpler: if a network split happens, do you want the database to keep answering but with possibly old/bad data (AP)? Or should it just stop responding unless you can get the absolute latest copy (CP)?
This describes a set of properties that apply to data transactions, defined as follows:
- Atomicity - Everything in a transaction must happen successfully or none of the changes are committed. This avoids a transaction that changes multiple pieces of data from failing halfway and only making a few changes.
- Consistency - The data will only be committed if it passes all the rules in place in the database (ie: data types, triggers, constraints, etc).
- Isolation - Transactions won't affect other transactions by changing data that another operation is counting on; and other users won't see partial results of a transaction in progress (depending on isolation mode).
- Durability - Once data is committed, it is durably stored and safe against errors, crashes or any other (software) malfunctions within the database.
ACID is commonly provided by most classic relational databases like MySQL, Microsoft MS SQL Server (product), Oracle (company) and others. These are known for storing data in spreadsheet-like tables that have their columns and data types strictly defined. The tables can have relationships between each other and the data is queried with SQL (Structured Query Language), which is a standardized language for working with databases - and why these are also commonly called "SQL databases".
With the massive amounts of data being created by modern companies, alternative databases have been developed to deal with the scaling and performance issues of existing systems as well as be a better fit for the kind of data created. NoSQL databases are what these alternatives are grouped under because many do not support SQL as a way to query the data, although this is a poor term.
These alternatives have matured now and while some do provide SQL abilities, they have come to be known more for their emphasis on scalable storage of a much higher magnitude of data (ie: terabytes and petabytes) by dropping support for database joins, storing data differently and using several distributed servers together as one. They also tend to not have ACID support to make transactions faster and easier to scale.
CAP provides the basic requirements that a distributed system must follow and ACID is a set of rules that a database can choose to follow that guarantees how it handles transactions and keeps data safe.
There are lots of options other than relational databases for storing more or different kinds of data and they often use a distributed set of servers working together and are designed either for AP or CP under the CAP theorem. When it comes to how safe the committed data is, any ACID compliant system can be considered reliable.
Final note: There really is no such thing as "NoSQL" - it's just a meaningless term that caught on and it's far better to just reference the type of database itself:
- Relational (mysql, oracle, sql server, postgres)
- Document Store (mongodb, riak, couchbase, rethinkdb)
- Key/Value (redis, aerospike, leveldb)
- Wide-Column (different from relational db with columnar storage and really more like nested-key/value: hbase, cassandra)
- Graph (neo4j, titan)
- Search (optimized for storing and searching against text, elasticsearch, solr, lucene)
Scalling vertically means increasing CPU, DISK, RAM, etc. Note that you are constrained to physical and state of art technologies whereas scalling horizontally means increasing quantity of machines;
Note that when scalling horizontally, you should keep a distributed cache in order to share states and to make it safer in case cache goes down, keep a RAID (Redundant Array of Independent Disk) that stripes data by adding redundancy to garantee availability;
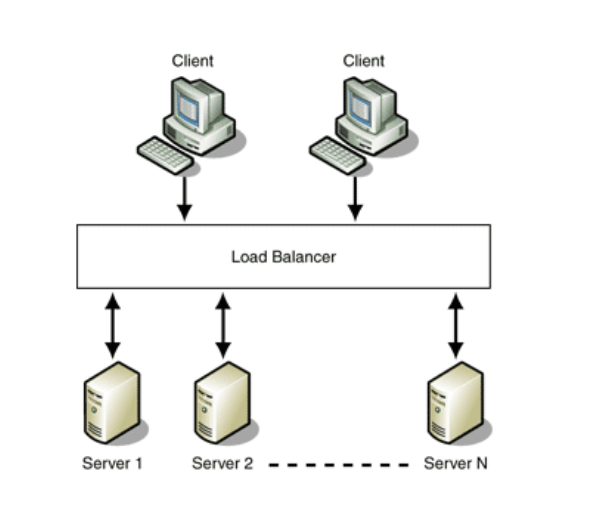
A load balancer is a device that acts as a reverse proxy and distributes network or application traffic across a number of servers. Load balancers are used to increase capacity (concurrent users) and reliability of applications. They improve the overall performance of applications by decreasing the burden on servers associated with managing and maintaining application and network sessions, as well as by performing application-specific tasks.
Load balancers are generally grouped into two categories: Layer 4 and Layer 7. Layer 4 load balancers act upon data found in network and transport layer protocols (IP, TCP, FTP, UDP). Layer 7 load balancers distribute requests based upon data found in application layer protocols such as HTTP.
Requests are received by both types of load balancers and they are distributed to a particular server based on a configured algorithm. Some industry standard algorithms are:
-
Round robin
-
Weighted round robin
-
Least connections
-
Least response time
-
Type of request
Layer 7 load balancers can further distribute requests based on application specific data such as HTTP headers, cookies, or data within the application message itself, such as the value of a specific parameter.
Load balancers ensure reliability and availability by monitoring the "health" of applications and only sending requests to servers and applications that can respond in a timely manner.
- HTTP is a uni-directional communicational protocol, whereas WebSocket is bi-directional.
- Whenever a request is made through HTTP, it creates a connection at the client(browser) and closes it once the response from the server is received. Whereas in WebSocket, it keeps the connection open until the state has died.
- Http should not be used, when you don’t want the connection to be opened for a long time, whereas WebSocket can be used in that case.
- Http works poorly with frequent kind of application, which overloads the server. Whereas WebSocket can be used with Chat, Trading, frequent updates kind of application, where a request is made very frequently.
- Http uses HTTP or https protocol for sending a request(like http://www.google.com), whereas WebSocket uses ws protocol( like ws://www.google.com).
Cross-origin resource sharing (CORS) is a mechanism that allows restricted resources on a web page to be requested from another domain outside the domain from which the first resource was served.[1] A web page may freely embed cross-origin images, stylesheets, scripts, iframes, and videos.[2] Certain "cross-domain" requests, notably Ajax requests, are forbidden by default by the same-origin security policy.
CORS defines a way in which a browser and server can interact to determine whether or not it is safe to allow the cross-origin request.[3] It allows for more freedom and functionality than purely same-origin requests, but is more secure than simply allowing all cross-origin requests.
Web-scale companies such as LinkedIn, Netflix, Google, Facebook, etc... have several requirements of their database systems around scalability, availability, and performance.
Let's discuss performance first. These companies have users the world over. Should users far from the data centers experience worse performance than those nearby? Imagine a data center is in Virginia, should US East Coast users get a much better experience than say users in China or Japan? If the answer is no, which it often is, then a company will deploy a few data centers in different parts of the world and partition their users using something like IP Anycast so that all of their users experience the fewest possible hops by being routed to the closest data center.
Now, what happens if one of these data centers experiences an outage? Should all users belonging to that data center experience the outage while there are in fact operational data centers. In this case, longer response times are better than no responses. In this case, web scale companies fail over traffic to the operational data centers.
Now, assume that database tables are partitioned by user and that all data centers have all of the data -- they need this in order to support failover between data centers. However, in most cases, writes for a particular user will happen in one data center (let's call this the home data center) and will need to be copied or replicated to the other data centers.
This is where CAP comes in. If the replication is synchronous, then you can achieve "consistency". You can achieve this by using 2PC-like protocols. The problem is that these protocols reduce the throughput of transactions. They take longer to run and hence less work gets done. As a result, transactions "back-up", connection pools are drained, and your scalability (number of concurrent transaction) drops. You are now prone to hitting a scalability bottleneck, which will cause intermittent outages of sorts (e.g. every other click on your site will timeout or fail fast). Hence, at the cost of consistency, you have compromised availability.
The other option is to replicate data asynchronously. In this model, every application writes to its local data base and immediately returns. All transactions remain fast and the transaction throughput remains high. Availability is not impacted. However, views are not consistent between data centers because data is delayed by definition, though this window of inconsistency can be made to be few minutes or better on average. This model is also called eventual consistency and was made popular by Amazon's Dynamo paper.
The "P" is not something you have a choice of trading off. Network partitions occur -- live with it. Hence, you can pick between AP and CP systems. Cassandra is an AP system. HBase is CP. Many traditional RDBMS systems, though they might have been CP at some point, have adopted eventual consistency to keep up with the times -- e.g. Oracle Golden Gate!
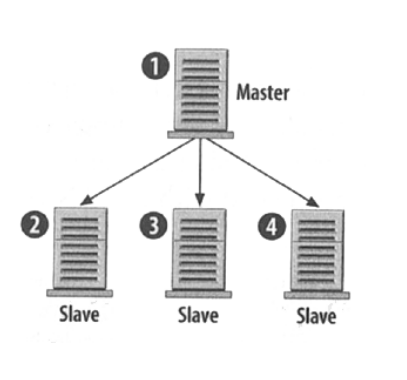
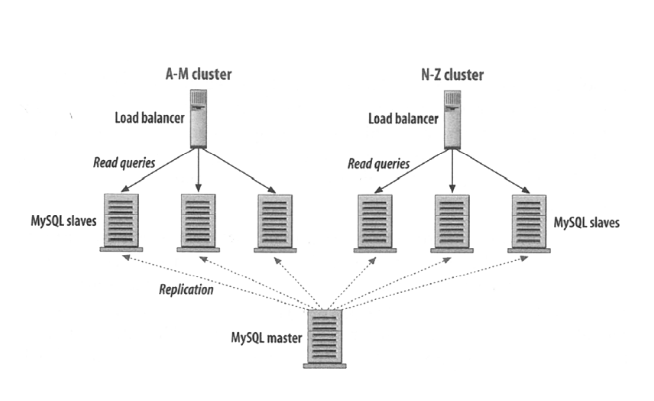
Master databases receive and store data from applications. Slave databases get copies of that data from the masters. Slaves are therefore read-only from the application's point of view while masters are read-write.
Writes to a database are more "expensive" than reads. Checking for data integrity and writing updates to physical disks, for example, consume system resources. Most web applications require a much higher ratio of reads to writes. For example a person may write an article once and then it’s read thousands of times. So setting up master-slave replication in the right scenario lets an application distribute its queries efficiently. While one database is busy storing information the others can be busy serving it without impacting each other. Most often each master and slave database are run on separate servers or virtual environments. Each is then tailored and optimized for their needs.
Master database servers may be optimized for writing to permanent storage. Slave database servers may have more RAM for query caching. Tuning the environments and database settings makes each more optimized for reading or writing, improving the overall efficiency of the application.
- Replication Master-Slave
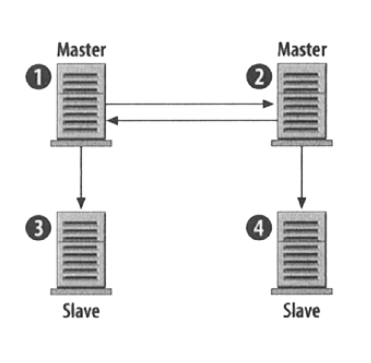
- Replication Master-Master
- Load Balancer
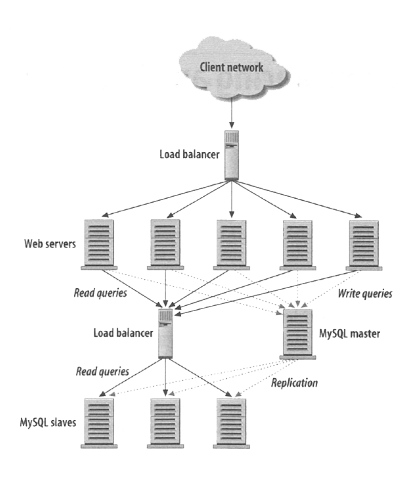
- Load Balancer + Replication
- Load Balancer + Replication + Partitioning
Features
- Client: UI with ansyncronous forms to allow user to short Url; also need another endpoint to redirect shortened Url;
- API endpoints: shorteningUrl(original Url) and retrieveUrl(short Url);
- System high scalable and system that saves usage statistics;
- Same Url shortened multiple times might give different shortened Urls;
Estimations
QPS (queries per second)
- Read query right after write query => keep a distributed cache;
- Many more read than write queries;
- System high scalable;
- Considering we'll have A-Z, a-z, 0-9 characters, we have 62 different posssible characters. Then we have 62^c possible shortened Url, regarding we have c characers. So if we short 1000 urls/second and store results for 5 years, we'd need c=ceil(log62(1000 * 60 * 60 * 23 * 365 * 5))=7; characters to support all shortened Urls;
Design goals
- Low latency regarding shortened Url is useless if it takes a long while to load, just like DNS;
- Partition: necessary regarding we need a distributed system across world;
- Consistency vs Availability: it is better to have a consistent system than a 100% available that gives unreliable Urls;
Skeleton
- Systems works like a scalable hash map, so we need only two endpoints: shorteningUrl(original Url) and retrieveUrl(short Url);
- Load balancer with distributed cache like Redis or Memcache;
- Typical queries: shorteningUrl(original Url) => "client -> server -> db"; retrieveUrl(short Url) => "client <-> server <-> db";
Deep dive
How to hash?
- Shortening same Url multiple times will lead to different shortened ones to possible be used for caching purposes;
- Take simple incremental index, convert it to base 62 and then add randomness through few bits at the end;
SQL vs NoSQL
- Joins required? No, simple schema with shortened url, original url, index and some statistics;
- All fits inside one machine what allow indexing? Considering each row takes few bytes, we would have log2(1000 * 60 * 60 * 23 * 365 * 5)=2^37=2^7 GB => ~1TB => fits on single machine;
- Regarding we don't need sharding at all, SQL storage is enough, otherwise NoSQL would be easier because it auto scales easily but does not have ACID support. Note that once we've choosen consistency rather than availability, SQL is better regarding ACID support;
- SQL-specific design: distributed cache like Redis or Memcache which works through a LRU cache regarding RAID (Redundant Array of Independent Disks) support; Replication Master-Slave databases, with Master allowing higher latency read-write queries while Slaves replicates Master and allows low latency read-only queries;
- If we needed to shard, we might use consistent hashing;
Features
- What is the scale we're looking for? Really scalable system, should check if all data really fits only single machine;
- Only 1:1 conversations? Yes, let's design only 1:1 and as follow up we try to intruduce group conversations;
- Attachments messages support? Yes;
- Length limited messages? Yes, not many more than a hundread charaters;
- Notification system for real time chat? Yes;
- High security levels required? No;
Estimations
- Given there are billion of people using Facebook, let's consider there are around a billion messages a day; Then assuming a message have around 100 characters, there are ~10^9 * 10^12 ~ 10^11 characters sent every day, it means we have to store 2^(ceil(log2(10^11))) ~ 2^37 ~ 1TB/day so we know only one single machine is not enough;
Design goals
- High latency required;
- High consistency required;
- Good to have high availability;
- Consistency vs Availability: consistency is preferred regarding CAP theorem and we want a distributed system across world;
Skeleton
- Project works through websocket other than http requests in order to manage bi-directional requests (server->client, client->server);
- What operations do we need to support? send message to other person, receive message if online, fetch most recent conversations, fetch most recent messages for given conversation;
- API endpoints: sendMessage(sender,receiver,content), fetchConversations(user,qty_threshold), fetchMessages(conversation,qty_threshold)
- Typical write query: client makes a get/post async request to backend, server persist data to database, notifyee user if online and update conversation flags like last updated time;
- Typical read query: client makes a get/post async request to backend, server takes a lookup query at database and give user json response;
- Load balancer with distributed cache to store what servers are managing what users and when last iteration has been done in order to check what time users have been online last time and if they're online, what server is managing him. Cache will be in-memory, partially consistent and with Master-Slave Replication just like Redis or Memcache;
Deep dive
Users login/logout workflow
- Subscribe user status and what servers is managing him at distributed cache; if server that's managing him dies, a new one can be got and just updating distributed cache is enough to garantee workflow keep working; if user dies, last time it has been online can be seen at distributed cache;
Messages workflow
- Let's suppose you have userA online and server N1 managing him as well as userB and server N2; If userA wants to send a message to userB, then it sends a message to Load Balancer which redirects traffic to N1; then N1 persists message to database; then N1 checks at distributed cache if userB is online and what server is managing him; if userB is online, N1 sends a message to server that manages userB then this server sends a message to userB through a websocket request; if userB if offline, just flag this user has unread messages and when userB gets online, server notifyees this user with all unread messages and updates distributed cache as well; note that when userB gets online, if userA is still online, it is notifyee that userB has read his messages;
File storage
- When some user wants to send an attachement, store this file at a blob storage like Amazon S3 then send only link as message content; if any user wants to see file, when you click on this, you load this blob from file storage;
SQL vs NoSQL
- Are joins required? Yes, we would need to join users -> conversations, conversation->message, then SQL would be better;
- Do all data fit on a single machine? No, it does not as have estimated previously. If we use SQL we would have a sharding overhead, regarding NoSQL technologies consider data does not fit into a sigle machine and auto scales automatically, a NoSQL technology would be better;
- What is the read-write pattern? We need a considerably amount of write. Regarding write on SQL databases are not only appending a row to a table but also updating indexes and linking tables, there are NoSQL technologies that supports better high write flow so a NoSQL technology would be better;
- Due to size of DB and technology maturity, we choose NoSQL;
Schemas design
NoSQL approach
- Distributed cache: user|server|heartbeat_time
- Regarding we have a NoSQL storage, all user would have their own copy of the message box; that means that we will store 2 copies of the message, one for each participant for every message sent;
- Data will be sharded based on users; then for a user we'd need to lookup conversations then messages; --not sure how to query this data, seems to be a bit messy;
On the other hand, if we had choosen SQL approach, we'd have
- messages/conversation table: conversation_id|time|text|from_user|blob_url
- unread table: from_user|to_user|time
- read table: from_user|to_user|time
- simple queries to filter read and unread messages;
db sharding and handle shutting down machine at db storage scability design examples!