Meta-repository containing both the python scripts (used for 'target reaching', 'mouse control' and 'unity mechanism control') and the nodejs server used for interfacing the scripts with Unity3D.
NOTE: for an in-depth look at the the different possible installation and running procedures refer to the project 📖 Wiki
In alphabetic order:
| Name | profile | |
|---|---|---|
| Federico Danzi | [email protected] | Etruria89 |
| Marco Gabriele Fedozzi | [email protected] | hypothe |
| Amanzhol Raisov | [email protected] | robotmiro1 |
| Laura Triglia | [email protected] | lauratriglia |
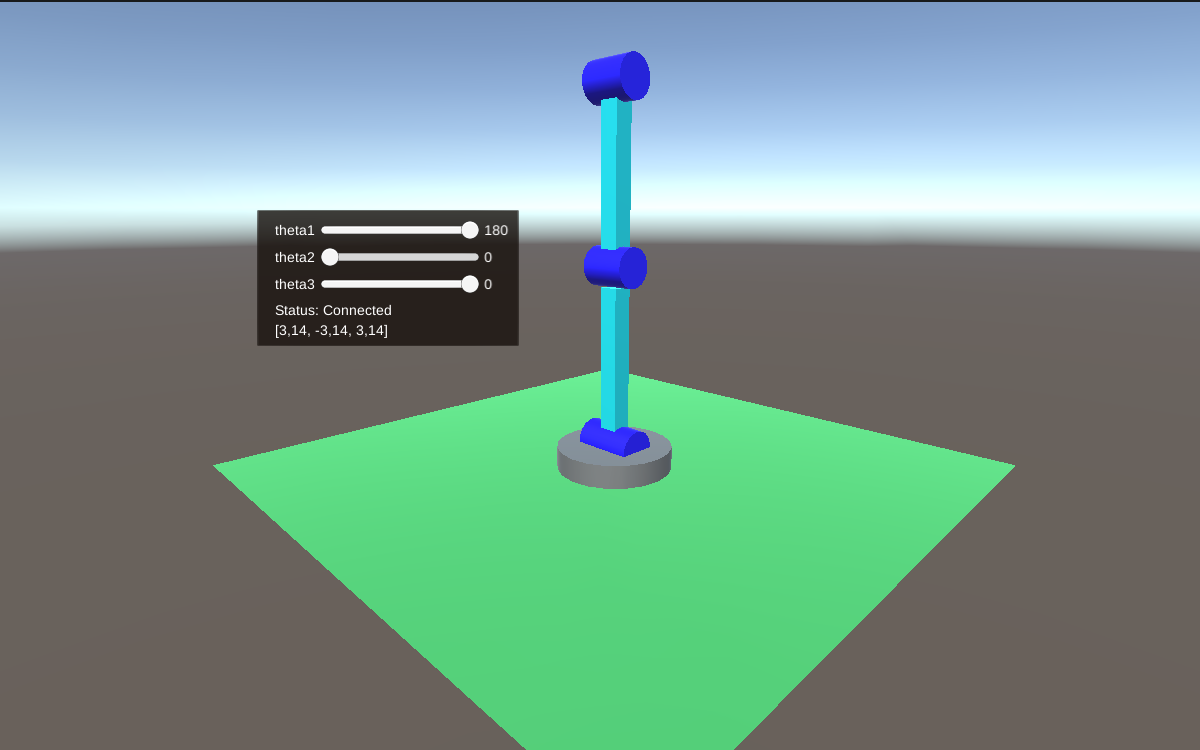
The scripts presented in the two submodules are combined here (see the docker-compose section) to control a 3dof robotic arm in a Unity3D simulation by mapping relevant joint positions of the user - in the 2D image frame detected using the pc webcam - to the angular position of each of the robot joint (direct kinematic position control).
First of all clone this repo together with its submodules
$ git clone https://github.com/hypothe/bomi-cam-unity3dof-control.git --recurse-submodulesYou will need to install docker-compose if it's not present on your system already (see install docker-compose)
Once you have docker-compose installed you will just have to run the compose file present in this repo with
.../bomi-cam-unity3dof-control$ docker-compose upThis will launch two containers, one for each of the two submodules in this repo.
Once both containers are up (it might take a while to build them the first time), open your web browser of choice and go to
http://localhost:8080.
You should see the Unity3D logo and a progress bar loading, after which the simulation should appear.
both Mozilla Firefox and Google Chrome have been tested and working
The Node.JS server that receives information from the python client and hosts the WebGL Unity3D scene (see the original repo) for a more in-depth explanation).
The python client that is used for motion tracking via a webcam (or a prerecorded video, the only option os Windows systems at the moment). Has a simple GUI and uses mediapipe for the tracking. Note that two different applications are implemented:
- the first in which the user motion is used to control either a circle in a dedicated pygame GUI or the mouse cursor on the screen (file:
main_reaching.py) - the other one which instead uses the motion information to control the 3dof mechanism spawn in a Unity3D scene (by the other docker).
Please note that the docker-compose automatically spawns the latter, as the former is intended to be run as a standalone script (see the original repo) for a more in-depth explanation).
IMPORTANT: if you are running the command in Unix you have to add the docker to the list of services allowed to access the xserver before the docker-compose, or else you will be prompted with an error right after the containers spawn. In order to do that you can simply type in the shell:
$ xauth +local:dockerIf, instead, you are using WSL:
- if you have one of the latest Windows build, with WSLG included, you have nothing else to do, it will autonomously manage the GUI
- otherwise you might have to use a third-party XServer (e.g., XMing)
The various parts of the project - Node.JS server, WebGL application, Python script - communicate using a websocket, and all routing is taken care of by the docker-compose, and that's the recommanded way of testing the project. If you prefer to instead run this locally, beware you might require a few different libraries, that you can find by looking at the Dockerfiles inside each repository. Take also
The current project was designed and tested mostly on Unix systems, including Windows' WSL. The functions used in the libraries (mostly regarding python) should be platform independant, but full compatibility is not guaranteed to work. However, plese take into account that, at the time of writing this, WSL does not support accessing to USB devices (rather, they're midway through it). What this means is that, even if this project can run on WSL, you need to use a pre-recorded video instead of the live feed from the webcam in all steps unless you run it locally instead of using the suggested docker-compose.
The video format should be .mp4, .avi, .mkv or any other of the most common video file formats. It's enough to place it inside your local copy of the repository, inside the markerlessBoMI_FaMa folder, before spinning up the docker-compose.
You can find, at the bottom of the Python-Client GUI window that pops up, a text box with a Ext. Video Source button: clicking on it you will be prompted to select the video file that you wish to use as the source. You can then use it for the calibration, customization and practice, or you can use different videos across those sections (selecting them as you did for the first one).
Note: using the external video as a source can be used also on a Unix host since, despite not mandatory in that casae, can speed up and standardize the steps across different trials.
Yes, it is. The solution proposed to track the user's motion is, definitely not the best one possible. Some (quite a few) updates have been made to the one proposed in the source repository. However, the whole design needs to be remade from the ground up, as a more intuitive control might tracking the user's joints configuration rather than their screen-space position; aka, "my fingers are open/close" rather than "my fingers are up there, no matter if the hand is open or closed". But, unfortunately, that would require probably quite some time to be implemented in a robust enough way, and might not provide significantly better results for some of the human joints (the shoulders and the nose).
As already mentioned, it's probably more interesting to track the joint configuration of the user, instead of the position of their body features in the image-space. Mediapipe does not do that natively and, while it's possible to retrieve those values from the image-space ones, it's definitely not a trivial task (although, since Mediapipe itself is using a skeletal model to yiel a more coherent representation, it might be possible to do so by digging into lower-level API).
Or, rather, a better dataset for the PCA/AE/VAE to work with. Right now all the joint values detected by Mediapipe are saved and used, but it's easy to notice with a visual inspection of the video-feed during calibration, that not all postures detected are correct when compared with the user's movements. Although Mediapipe already tries to keep a coherent representation of the human skeleton the amount in which that is applied here is insufficient. Again, might be solved with lower level API and a bit of thinkering (i.e., there is the smooth_landmarks=True option for the Holistic model, but that messed up the face features detection in our trials). In addition, some further filtering might be applied: particular notice can be put in the case of the adoption of the VAE mapping, as its gaussian nature (returning both mu and sigma for each detection) could allow to use a Kalman Filter.
Right now the control implemented in the Unity3D simulation is a simple Direct Kinematic - Position Controlled, meaning that each joint's position is directly controlled by one of the output variables produced by the python script. This is, of course, a simple and limited approach. A more realistic implementation might instead adopt an Impedance Control, driving the arm's end effector forces given the user's motion.