Contents
Biases are bugs
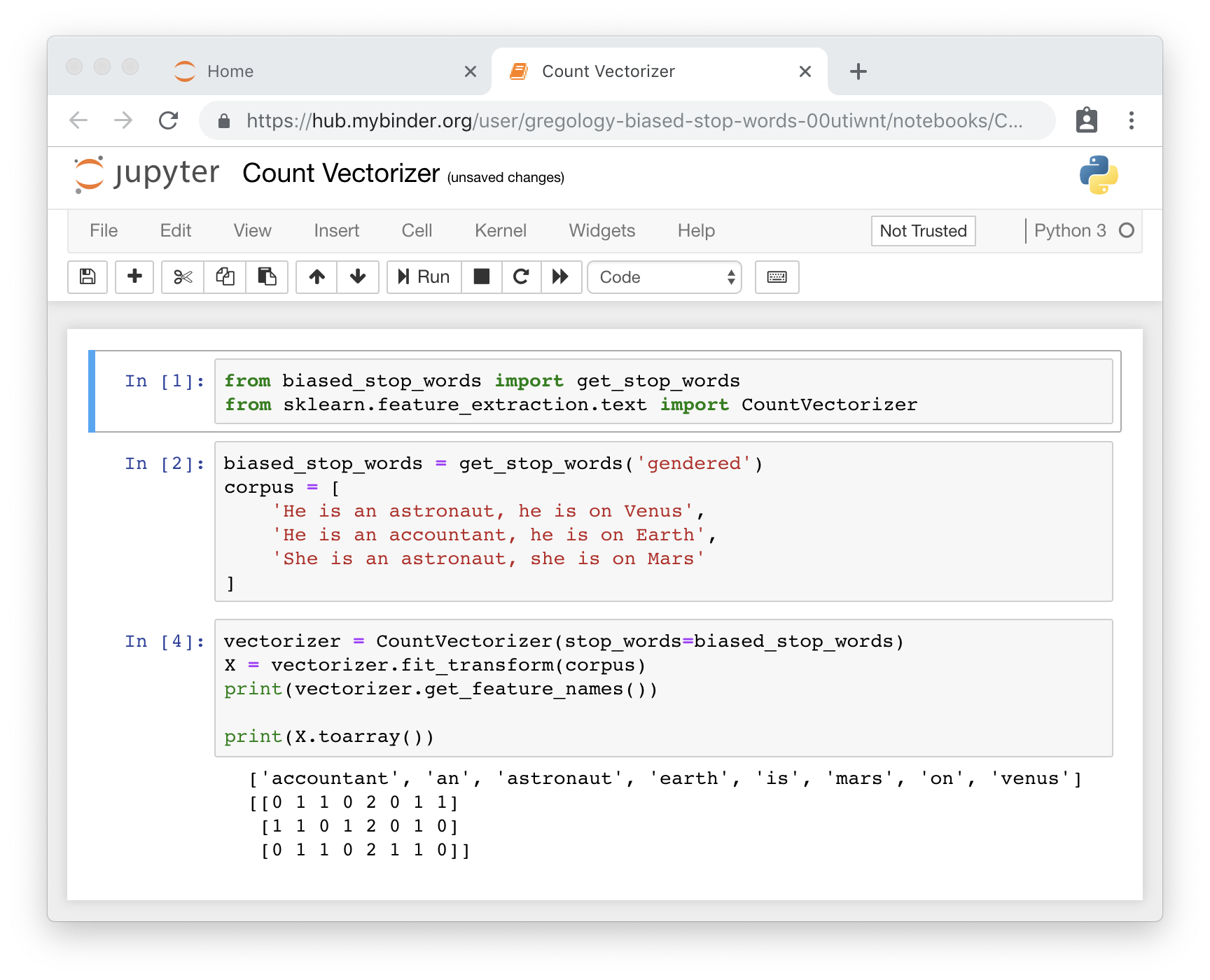
Stop words are words which are filtered out before processing of natural language data. Often in text analysis there are non-casual correlations, consider the following documents:
- He is an astronaut, he is on Venus
- He is an accountant, he is on Earth
- She is an astronaut, she is on Mars
Processing these documents into two topics will result in gendered clustering. If we remove the gendered terms:
- is an astronaut, is on Venus
- is an accountant, is on Earth
- is an astronaut, is on Mars
Processing will result in job clustering. Both clusterings are valid, however if you are interested in employing an astronaut, you don't want male accountants showing up. There are many other examples of non casual relationships occurring in natural language; religion, ethnicity, and age to name but a few.
- Gendered Terms
- US Names
- Religious Terms (Partial)
More will be available soon. Contribute at https://github.com/gregology/biased-words
Explore this package in an Interactive Notebook
Hosted by binder
biased-stop-words is available on PyPI
http://pypi.python.org/pypi/biased-stop-words
Install via pip
$ pip install biased-stop-words
Or via easy_install
$ easy_install biased-stop-words
Or directly from biased-stop-words's git repo <https://github.com/gregology/biased-words>
$ git clone --recursive git://github.com/gregology/biased-stop-words.git $ cd biased-stop-words $ python setup.py install
>>> from biased_stop_words import genres, get_stop_words
>>> genres()
'religious, gendered, us-common-names, us-names, us-male-names, us-female-names, gendered-nouns'
>>> get_stop_words('gendered', 'us-common-names')
[u'trenton', u'augustine', u'khalil', u'aiden', u'elisabeth', u'andre', u'khanum', u'elva', u'fran...
$ python biased_stop_words/tests.py
Developed for Python 2 & 3.