PyGrid ARM64 build for Hivecell, Jetson TX2.
Software: Python 3.7, PySyft 0.2.9, Pytorch 1.4.0
Container could run on L4T 32.4.2 with installed CUDA 10.2
Simply put, federated learning is machine learning where the data and the model are initially located in two different locations. The model must travel to the data in order for training to take place in a privacy-preserving manner. Depending on what you're looking to accomplish, there are two types of federated learning that you can perform with the help of PyGrid.
PyGrid is a peer-to-peer network of data owners and data scientists who can collectively train AI models using PySyft. PyGrid is also the central server for conducting both model-centric and data-centric federated learning.
PyGrid platform is composed by three different components.
- Network - A Flask-based application used to manage, monitor, control, and route instructions to various PyGrid Nodes.
- Node - A Flask-based application used to store private data and models for federated learning, as well as to issue instructions to various PyGrid Workers.
- Worker - An emphemeral instance, managed by a PyGrid Node, that is used to compute data.
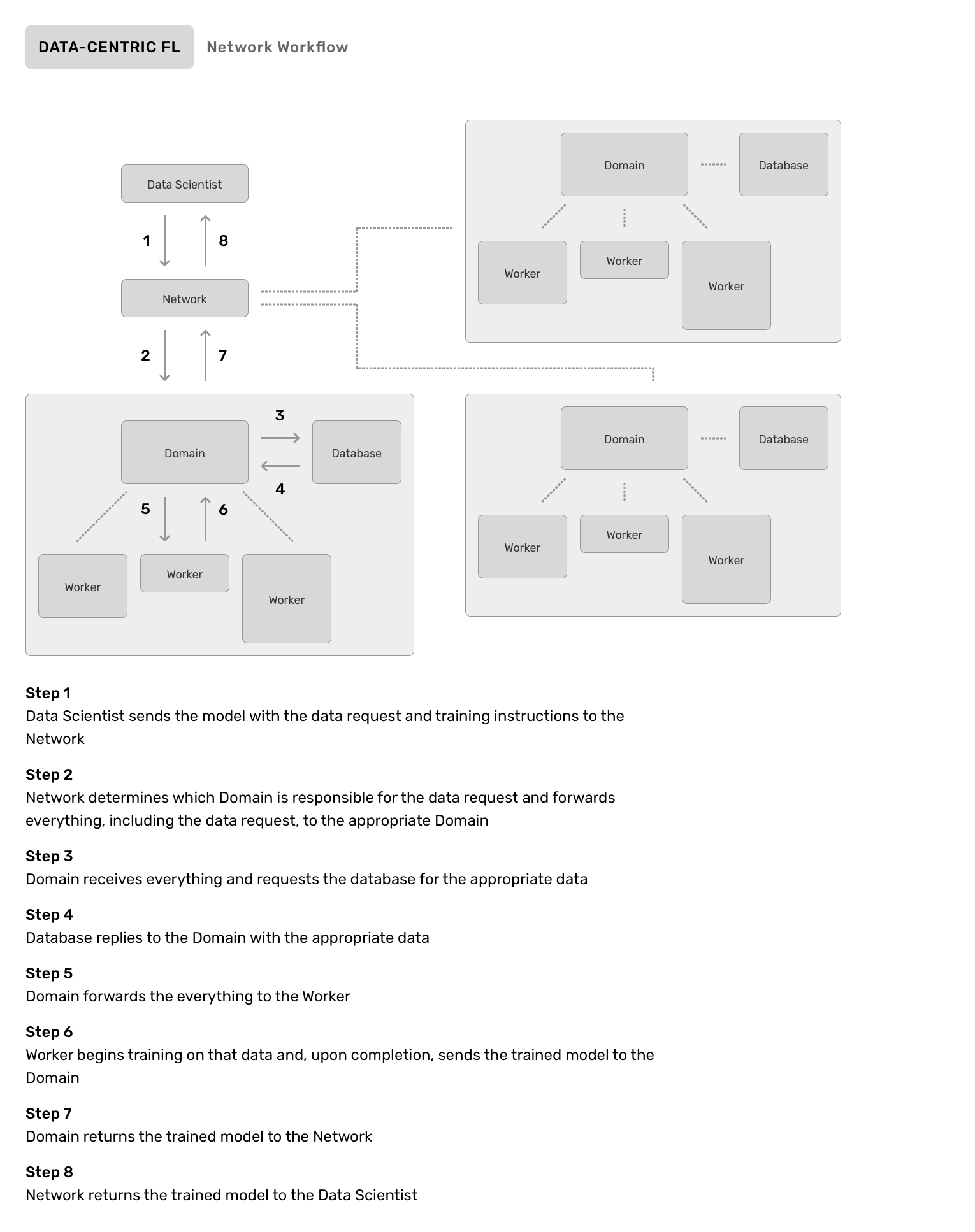
Data-centric FL is the same problem as model-centric FL, but from the opposite perspective. The most likely scenario for data-centric FL is where a person or organization has data they want to protect in PyGrid (instead of hosting the model, they host data). This would allow a data scientist who is not the data owner, to make requests for training or inference against that data. The following workflow will take place:
- A data scientist searches for data they would like to train on (they can search either an individual Node, or a Network of Nodes)
- Once the data has been found, they may write a training plan and optionally pre-train a model
- The training plan and model are sent to the PyGrid Node in the form of a job request
- The PyGrid Node will gather the appropriate data from its database and send the data, the model, and the training plan to a Worker for processing
- The Worker performs the plan on the model using the data
- The result is returned to the Node
- The result is returned to the data scientist
For the last step, we're working on adding the capability for privacy budget tracking to be applied that will allow a data owner to "sign off" on whether or not a trained model should be released.
Note: For posterity sake, we previously used to refer to this process as "dynamic federated learning".
Network-based data-centric FL
Many times you will wat to use a Network to allow multiple Nodes to be connected together. As a data owner, it's not strictly necessary to own and operate multiple Nodes.
To run Docker containers with CUDA support in Docker-compose, we should set nvidia runtime as default.
Just modify /etc/docker/daemon.json file to add default. File will looks like:
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"default-runtime": "nvidia"
}
The latest Hivecell PyGrid images are also available on the Docker Hub.
- Hivecell PySyft -
hivecell/pysyft:latest - Hivecell PySyft Notebook -
hivecell/pysyft:notebook - Hivecell PyGrid Network -
hivecell/pygrid-network - Hivecell PyGrid Node -
hivecell/pygrid-node
To download latest docker container just run:
$ docker-compose pull
To start the PyGrid platform you just need start the docker-compose process.
$ docker-compose up
This will download the latest Docker images and start a grid platform with a network and 4 nodes. You can modify this setup by changing the docker-compose.yml file.
If you want to build images, you may do so using the following command:
$ docker-compose build --no-cache