This Python-written project utilizes Time Series analysis, along with a Linear Regression model, to forecast the price of the Japanese Yen vs. the US Dollar. ARMA, ARIMA, and GARCH forecasting models included, as well as decomposition using the Hodrick-Prescott filter. In-Sample and Out-of-Sample performance metrics used to evaluate Linear Regression model.

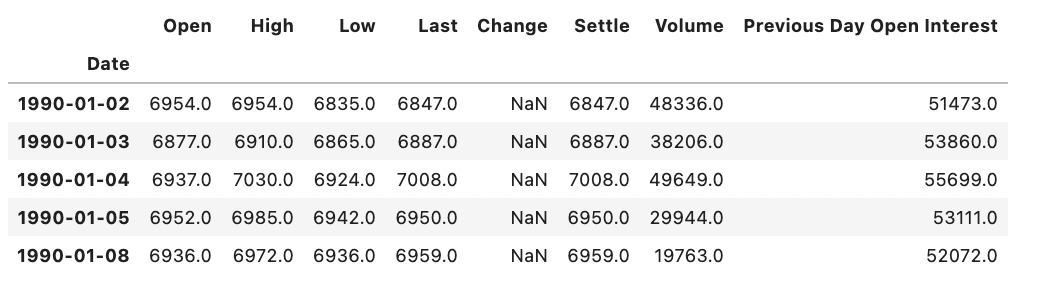
My dataset looked like the following (contains Yen price related data from 1990-2019):
First, apply the Hodrick-Prescott Filter by decomposing the "Settle" price into two separate series:
import statsmodels.api as sm
settle_noise, settle_trend = sm.tsa.filters.hpfilter(yen_futures['Settle'])
Then, create a dataframe of just the settle price, and add columns for "noise" and "trend" series from above:
df_settle_price = pd.DataFrame(yen_futures['Settle'])
df_settle_price['Noise'] = settle_noise
df_settle_price['Trend'] = settle_trend
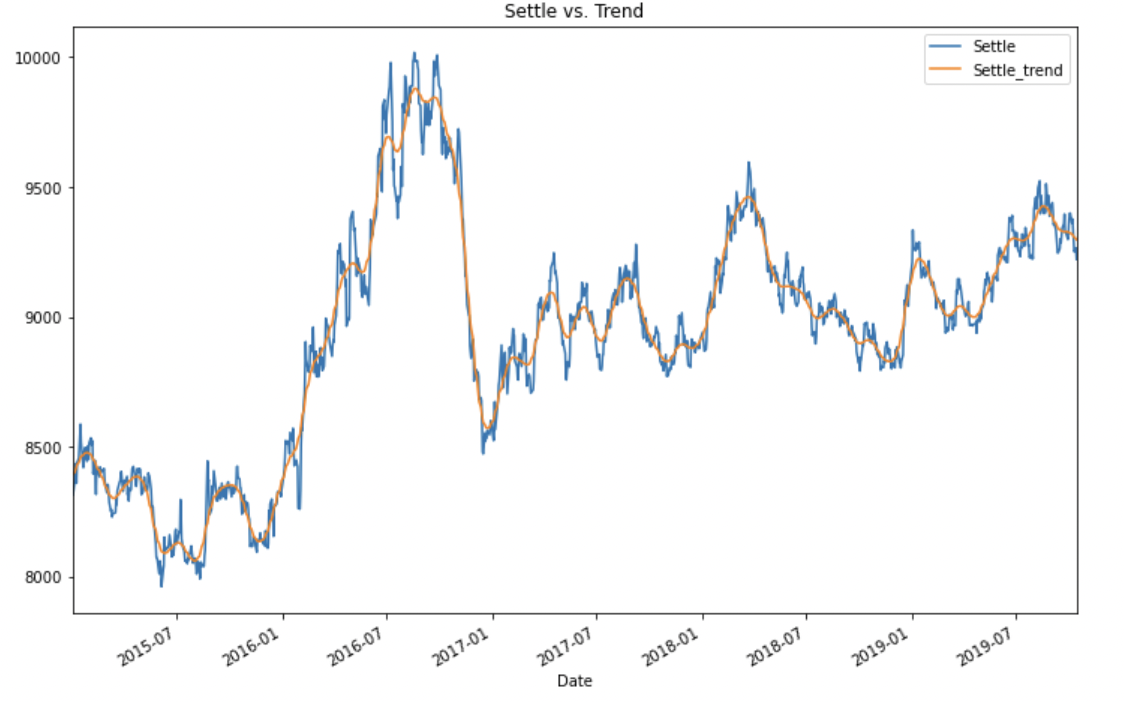
Now, plot the Settle Price vs. the Trend Price for 2015 to the present:
settle_price_2015_to_present = yen_futures.loc['2015-01-01':]
trend_2015_to_present = settle_trend.loc['2015-01-01':]
settle_vs_trend = pd.concat([settle_price_2015_to_present, trend_2015_to_present], axis="columns", join="inner")
settle_vs_trend_slice = settle_vs_trend[['Settle', 'Settle_trend']]
settle_vs_trend_slice.plot(figsize = (12,8), title = 'Settle vs. Trend')
# Set margins to 0 to eliminate whitespace on x-axis (required importing pyplot from matplotlib):
plt.margins(x=0)
The above code results in the following plot:
Create a series using "Settle" price percentage returns, drop any nan's, and then create model:
returns = (yen_futures[["Settle"]].pct_change() * 100)
returns = returns.replace(-np.inf, np.nan).dropna()
import statsmodels.api as sm
from statsmodels.tsa.arima_model import ARMA
# Estimate an ARMA model using statsmodels (order=(2, 1))
arma_model = ARMA(returns.Settle, order=(2,1))
# Fit the model and assign it to a variable called results
arma_results = arma_model.fit()

In the above ARMA model, the autoregressive term has a p-value (.42) that is greater than the significance level of 0.05. We can conclude that the coefficient for the autoregressive term is NOT statistically significant, and should NOT be kept in the model.
To Plot a Returns Forecast:
# Plot a 5 Day Returns Forecast
pd.DataFrame(arma_results.forecast(steps=4)[0]).plot(title="5 Day Returns Forecast")
The above code results in the following plot:

from statsmodels.tsa.arima_model import ARIMA
# Estimate an ARIMA Model:
arima_model = ARIMA(settle.Settle, order=(5,1,1))
# Fit the model
arima_results = arima_model.fit()

In the above ARIMA model, the autoregressive term has a p-value (.65) that is greater than the significance level of 0.05. We can conclude that the coefficient for the autoregressive term is NOT statistically significant, and should NOT be kept in the model.
import arch as arch
from arch import arch_model
# Estimate a GARCH model:
garch_model = arch_model(returns.Settle, mean="Zero", vol="GARCH", p=2, q=1)
# Fit the model
garch_results = garch_model.fit(disp="off")

Based on the above time series analysis, I would not in fact buy the yen now. First off, both the ARMA and the ARIMA model have p-values that are greater than .05 (.42 and .65, respectively), and therefore, the coefficient for the autoregressive term is not statistically significant and those terms should not be kept in the models. Additionally, as the upward-trending GARCH Model shows us, the exchange rate risk is expected to increase, and a more conservative investor may not be comfortable with this level of risk. Although I would not use either of these models, the AIC of the ARMA model (15,798) is significantly lower than that of the ARIMA model (83,905), and therefore it is performing significantly better.
When it comes to investing real money, I would not base my decisions solely on the results of these models. Before using them, I would want to improve them by training the models and making them statistically significant. If I did that, I would use them as one of the factors I consider, but would want to look at other factors as well before making any investment decisions.
However, a more opportunistic investor may take a look at this GARCH plot, expect increased short-term volatility in the markets, and invest in derivatives. Prices of derivative assets tend to increase as volatility increases, and a prudent investor may take advantage of this.
After loading in Yen Futures returns data, create a lagged return column using the .shift() function:
yen_futures['Lagged_Returns'] = yen_futures.Returns.shift()
yen_futures = yen_futures.replace(-np.inf, np.nan).dropna()
I was left with a dataframe that looked like the following:

After splitting into Training and Testing data, I ran the Linear Regression model:
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
predicted_y_values = model.predict(X_test)
And assembled actual y data (Y_test) with predicted y data (from just above) into two columns in a dataframe:
results_df = y_test.to_frame()
results_df["Predicted Return"] = predicted_y_values

from sklearn.metrics import mean_squared_error
mse = mean_squared_error(results_df["Returns"], results_df["Predicted Return"])
# Using that mean-squared-error, calculate the root-mean-squared error (RMSE):
rmse = np.sqrt(mse)
print(f"Out-of-Sample Root Mean Squared Error (RMSE): {rmse}")
# Output: Out-of-Sample Root Mean Squared Error (RMSE): 0.4154832784856737
# Construct a dataframe using just the "y" training data:
in_sample_results = y_train.to_frame()
# Add a column of "in-sample" predictions to that dataframe:
in_sample_results["In-sample Predictions"] = model.predict(X_train)
# Calculate in-sample mean_squared_error (for comparison to out-of-sample)
in_sample_mse = mean_squared_error(in_sample_results["Returns"], in_sample_results["In-sample Predictions"])
# Calculate in-sample root mean_squared_error (for comparison to out-of-sample)
in_sample_rmse = np.sqrt(in_sample_mse)
print(f"In-sample Root Mean Squared Error (RMSE): {in_sample_rmse}")
# Output: In-sample Root Mean Squared Error (RMSE): 0.5963660785073426
The out-of-sample RMSE (.42) is lower than the in-sample RMSE (.60). RMSE is typically lower for training data, but is higher in this case. This means the model made better predictions on data it has never seen before (the test set) than the actual training set. Therefore, I would not trust these predictions, and would instead develop a new model.