
earthmover transforms collections of tabular source data (flat files, FTP files, database tables/queries) into text-based (JSONL, XML) data via YAML configuration.
- Requirements
- Installation
- Setup
- Usage
- Features
- Tests
- Design
- Performance
- Limitations
- Best Practices
- Changelog
- Contributing
- License
- Bundles
pip install earthmover
To see Earthmover in action, run earthmover init to spin up a ready-to-run starter project.
In general, the tool requires
- source data, such as CSV or TSV files or a relational database table
- Jinja templates defining the desired output format (JSON, XML, etc.)
- a YAML configuration file specifying the source data, doing any necessary transformations (joins, value mappings, etc.), and destinations (output files) to write to
Item 1 is usually your own data. Items 2 & 3 together may be shared as a reusable "bundle" (zip file); see available bundles for more information and a list of published bundles.
If you already have a bundle, continue to the usage section below.
If you develop a bundle for a particular source data system or format, please consider contributing it to the community by publishing it online and emailing the link to [email protected] to get it listed here.
This tool is designed to operate on tabular data in the form of multiple CSV or TSV files, such as those created by an export from some software system, or from a set of database tables.
There are few limitations on the source data besides its format (CSV or TSV). Generally it is better to avoid using spaces in column names, however this can be managed by renaming columns as described in the sources YAML configuration section below.
After transforming the source data, this tool converts it to a text-based file like JSON(L) or XML based on a template using the Jinja templating language.
Briefly, Jinja interpolates variables in double curly braces {{...}} to actual values, as well as providing other convenience functionality, such as string manipulation functions, logic blocks like if-tests, looping functionality, and much more. See the examples in example_projects/, or check out the official Jinja documentation.
Note that templates may include other templates, specified relative to the location of the earthmover YAML configuration file - see example_projects/06_subtemplates/earthmover.yaml and example_projects/06_subtemplates/mood.jsont for an example.
When updating to 0.2.x
A breaking change was introduced in version 0.2 of Earthmover.
Before this update, each operation under a transformation required a source be defined.
This allowed inconsistent behavior where the results of an upstream operation could be discarded if misdefined.
The source key has been moved into transformations as a required field.
In unary operations, the source is the output of the previous operation (or the transformation source if the first defined).
In operations with more than one source (i.e., join and union), the output of the previous operation is treated as the first source;
any additional sources are defined using the sources field.
For example:
# Before # After
transA: transA:
source: $sources.A
operations: operations:
- operation: add_columns - operation: add_columns
source: $sources.A
columns: columns:
A: "a" A: "a"
B: "b" B: "b"
- operation: union - operation: union
sources: sources:
- $transformations.transA
- $sources.B - $sources.B
- $sources.C - $sources.CTo ensure the user has updated their templates accordingly, the key and value version: 2 is mandatory at the beginning of Earthmover templates going forward.
All the instructions for this tool — where to find the source data, what transformations to apply to it, and how and where to save the output — are specified in a single YAML configuration file. Example YAML configuration files and projects can be found in example_projects/.
The YAML configuration may also contain Jinja and environment variable references.
The general structure of the YAML involves the following sections:
version, with required value2(Earthmover 0.2.x and later)config, which specifies options like the logging level and parameter defaultsdefinitionsis an optional way to specify reusable values and blockspackages, an optional way to import and build on existing projectssources, where each source file is listed with details like the number of header rowstransformations, where source data can be transformed in various waysdestinations, where transformed data can be mapped to JSON templates and Ed-Fi endpoints and sent to an Ed-Fi API
Section 1 has general options. Sections 2, 3, and 4 define a DAG which enables efficient data processing. Below, we document each section in detail:
The config section of the YAML configuration specifies various options for the operation of this tool.
A sample config section is shown here; the options are explained below.
config:
output_dir: ./
state_file: ~/.earthmover.csv
log_level: INFO
tmp_dir: /tmp
show_stacktrace: True
show_graph: True
macros: >
{% macro example_macro(value) -%}
prefixed-int-{{value|int}}
{%- endmacro %}
parameter_defaults:
SOURCE_DIR: ./sources/
show_progress: True
git_auth_timeout: 120
- (optional)
output_dirdetermines where generated JSONL is stored. The default is./. - (optional)
state_filedetermines the file which maintains tool state. The default is~/.earthmover.csvon *nix systems,C:/Users/USER/.earthmover.csvon Windows systems. - (optional) Specify a
log_levelfor output. Possible values areERROR: only output errors like missing required sources, invalid references, invalid YAML configuration, etc.WARNING: output errors and warnings like when the run log is getting longINFO: all errors and warnings plus basic information about whatearthmoveris doing: start and stop, how many rows were removed by adistinct_rowsorfilter_rowsoperation, etc. (This is the defaultlog_level.)DEBUG: all output above, plus verbose details about each transformation step, timing, memory usage, and more. (Thislog_levelis recommended for debugging transformations.)
- (optional) Specify the
tmp_dirpath to use when dask must spill data to disk. The default is/tmp. - (optional) Specify whether to show a stacktrace for runtime errors. The default is
False. - (optional) Specify whether or not
show_graph(default isFalse), which requires PyGraphViz to be installed and createsgraph.pngandgraph.svgwhich are visual depictions of the dependency graph. - (optional) Specify Jinja
macroswhich will be available within any Jinja template content throughout the project. (This can slow performance.) - (optional) Specify
parameter_defaultswhich will be used if the user fails to specify a particular parameter or environment variable. - (optional) Specify whether to
show_progresswhile processing, via a Dask progress bar. - (optional) Specify the
git_auth_timeout(in seconds) to wait for the user to enter Git credentials if needed during package installation; default is 60. See project composition for more details on package installation.
The definitions section of the YAML configuration is an optional section you can use to define configurations which are reused throughout the rest of the configuration. earthmover does nothing special with this section, it's just interpreted by the YAML parser. However, this can be a very useful way to keep your YAML configuration DRY – rather than redefine the same values, Jinja phrases, etc. throughout your config, define them once in this section and refer to them later using YAML anchors, aliases, and overrides.
An example definitions section is shown below:
definitions:
operations:
- &student_join_op
operation: join
join_type: left
left_key: student_id
right_key: student_id
...
date_to_year_jinja: &date_to_year "{%raw%}{{ val[-4:] }}{%endraw%}"
...
transformations:
roster:
operations:
- <<: *student_join_op
sources:
- $sources.roster
- $sources.students
enrollment:
operations:
- <<: *student_join_op
sources:
- $sources.enrollment
- $sources.students
...
academic_terms:
operations:
- operation: duplicate_columns
source: $sources.academic_terms
columns:
start_date: school_year
- operation: modify_columns
columns:
school_year: *date_to_yearThe packages section of the YAML configuration is an optional section you can use to specify packages – other earthmover projects from a local directory or GitHub – to import and build upon exisiting code. See Project Composition for more details and considerations.
A sample packages section is shown here; the options are explained below.
packages:
year_end_assessment:
git: "https://github.com/edanalytics/earthmover_edfi_bundles.git"
subdirectory: "assessments/assessment_name"
student_id_macros:
local: "path/to/student_id_macros"Each package must have a name (which will be used to name the folder where it is installed in /packages) such as year_end_assessment or student_id_macros in this example. Two sources of packages are currently supported:
- GitHub packages: Specify the URL of the repository containing the package. If the package YAML configuration is not in the top level of the repository, include the path to the folder with the the optional
subdirectory. - Local packages: Specify the path to the folder containing the package YAML configuration. Paths may be absolute or relative paths to the location of the
earthmoverYAML configuration file.
The sources section of the YAML configuration specifies source data the tool will work with.
A sample sources section is shown here; the options are explained below.
sources:
districts:
connection: "ftp://user:pass@host:port/path/to/districts.csv"
tx_schools:
connection: "postgresql://user:pass@host/database"
query: >
select school_id, school_name, school_website
from schema.schools
where school_address_state='TX'
courses:
file: ./data/Courses.csv
header_rows: 1
columns:
- school_id
- school_year
- course_code
- course_title
- subject_id
more_schools:
file: ./data/Schools.csv
header_rows: 1
columns:
- school_id
- school_name
- address
- phone_number
expect:
- low_grade != ''
- high_grade != ''
- low_grade|int <= high_grade|intEach source must have a name (which is how it is referenced by transformations and destinations) such as districts, courses, tx_schools, or more_schools in this example. Three types of sources are currently supported:
-
File sources must specify the path to the source
file. Paths may be absolute or relative paths to the location of theearthmoverYAML configuration file. Supported file types are- Row-based formats:
.csv: Specify the number ofheader_rows, and (ifheader_rows> 0, optionally) overwrite thecolumnnames. Optionally specify anencodingto use when reading the file (the default is UTF8)..tsv: Specify the number ofheader_rows, and (ifheader_rows> 0, optionally) overwrite thecolumnnames. Optionally specify anencodingto use when reading the file (the default is UTF8)..txt: a fixed-width text file. See here for usage information
- Column-based formats:
.parquet,.feather,.orc— these require thepyarrowlibrary, which can be installed withpip install pyarrowor similar - Structured formats:
.json: Optionally specify aobject_type(frameorseries) andorientation(see these docs) to interpret different JSON structures..jsonlor.ndjson: reads files with a flat JSON structure per line..xml: Optionally specify anxpathto select a set of nodes deeper in the XML..html: Optionally specify a regex tomatchfor selecting one of many tables in the HTML. This can be used to extract tables from a live web page.
- Excel formats:
.xls,.xlsx,.xlsm,.xlsb,.odf,.odsand.odt— optionally specify thesheetname (as a string) or index (as an integer) to load. - Other formats:
.pklor.pickle: a pickled Python object (typically a Pandas dataframe).sas7bdat: a SAS data file.sav: a SPSS data file.dta: a Stata data file
File type is inferred from the file extension, however you may manually specify
type:(csv,tsv,fixedwidth,parquet,feather,orc,json,jsonl,xml,html,excel,pickle,sas,spss, orstata) to forceearthmoverto treat a file with an arbitrary extension as a certain type. Remote file paths (https://somesite.com/path/to/file.csv) generally work. - Row-based formats:
-
Database sources are supported via SQLAlchemy. They must specify a database
connectionstring and SQLqueryto run. -
FTP file sources are supported via ftplib. They must specify an FTP
connectionstring.
For any source, optionally specify conditions you expect data to meet which, if not true for any row, will cause the run to fail with an error. (This can be useful for detecting and rejecting NULL or missing values before processing the data.) The format must be a Jinja expression that returns a boolean value. This is enables casting values (which are all treated as strings) to numeric formats like int and float for numeric comparisons.
The examples above show user:pass in the connection string, but if you are version-controlling your YAML you must avoid publishing such credentials. Typically this is done via environment variables or command line parameters, which are both supported by this tool. Such environment variable references may be used throughout your YAML (not just in the sources section), and are parsed at load time.
The transformations section of the YAML configuration specifies how source data is manipulated by the tool.
A sample transformations section is shown here; the options are explained below.
transformations:
courses:
source: $sources.courses
operations:
- operation: map_values
column: subject_id
mapping:
01: 1 (Mathematics)
02: 2 (Literature)
03: 3 (History)
04: 4 (Language)
05: 5 (Computer and Information Systems)
- operation: join
sources:
- $sources.schools
join_type: inner
left_key: school_id
right_key: school_id
- operation: drop_columns
columns:
- address
- phone_numberThe above example shows a transformation of the courses source, which consists of an ordered list of operations. A transformation defines a source to which a series of operations are applied. This source may be an original $source or another $transformation. Transformation operations each require further specification depending on their type; the operations are listed and documented below.
union
Concatenates the transformation source with one or more sources sources of the same shape.
- operation: union
sources:
- $sources.courses_list_1
- $sources.courses_list_2
- $sources.courses_list_3
fill_missing_columns: FalseBy default, unioning sources with different columns raises an error.
Set fill_missing_columns to True to union all columns into the output dataframe.
join
Joins the transformation source with one or more sources.
- operation: join
sources:
- $sources.schools
join_type: inner | left | right
left_key: school_id
right_key: school_id
# or:
left_keys:
- school_id
- school_year
right_keys:
- school_id
- school_year
# optionally specify columns to (only) keep from the left and/or right sources:
left_keep_columns:
- left_col_1
- left_col_2
right_keep_columns:
- right_col_1
- right_col_2
# or columns to discard from the left and/or right sources:
left_drop_columns:
- left_col_1
- left_col_2
right_drop_columns:
- right_col_1
- right_col_2
# (if neither ..._keep nor ..._drop are specified, all columns are retained)Joining can lead to a wide result; the ..._keep_columns and ..._drop_columns options enable narrowing it.
Besides the join column(s), if a column my_column with the same name exists in both tables and is not dropped, it will be renamed my_column_x and my_column_y, from the left and right respectively, in the result.
add_columns
Adds columns with specified values.
- operation: add_columns
columns:
new_column_1: value_1
new_column_2: "{%raw%}{% if True %}Jinja works here{% endif %}{%endraw%}"
new_column_3: "{%raw%}Reference values from {{AnotherColumn}} in this new column{%endraw%}"
new_column_4: "{%raw%}{% if col1>col2 %}{{col1|float + col2|float}}{% else %}{{col1|float - col2|float}}{% endif %}{%endraw%}"Use Jinja: {{value}} refers to this column's value; {{AnotherColumn}} refers to another column's value. Any Jinja filters and math operations should work. Reference the current row number with {{__row_number__}} or a dictionary containing the row data with {{__row_data__['column_name']}}. You must wrap Jinja expressions in {%raw%}...{%endraw%} to avoid them being parsed at YAML load time.
rename_columns
Renames columns.
- operation: rename_columns
columns:
old_column_1: new_column_1
old_column_2: new_column_2
old_column_3: new_column_3duplicate_columns
Duplicates columns (and all their values).
- operation: duplicate_columns
columns:
existing_column1: new_copy_of_column1
existing_column2: new_copy_of_column2drop_columns
Removes the specified columns.
- operation: drop_columns
columns:
- column_to_drop_1
- column_to_drop_2keep_columns
Keeps only the specified columns, discards the rest.
- operation: keep_columns
columns:
- column_to_keep_1
- column_to_keep_2combine_columns
Combines the values of the specified columns, delimited by a separator, into a new column.
- operation: combine_columns
columns:
- column_1
- column_2
new_column: new_column_name
separator: "_"Default separator is none - values are smashed together.
modify_columns
Modify the values in the specified columns.
- operation: modify_columns
columns:
state_abbr: "{%raw%}XXX{{value|reverse}}XXX{%endraw%}"
school_year: "{%raw%}20{{value[-2:]}}{%endraw%}"
zipcode: "{%raw%}{{ value|int ** 2 }}{%endraw%}"
"*": "{%raw%}{{value|trim}}{%endraw%}" # Edit all values in dataframeUse Jinja: {{value}} refers to this column's value; {{AnotherColumn}} refers to another column's value. Any Jinja filters and math operations should work. Reference the current row number with {{__row_number__}} or a dictionary containing the row data with {{__row_data__['column_name']}}. You must wrap Jinja expressions in {%raw%}...{%endraw%} to avoid them being parsed at YAML load time.
map_values
Map the values of a column.
- operation: map_values
column: column_name
# or, to map multiple columns simultaneously
columns:
- col_1
- col_2
mapping:
old_value_1: new_value_1
old_value_2: new_value_2
# or a CSV/TSV with two columns (from, to) and header row
# paths may be absolute or relative paths to the location of the `earthmover` YAML configuration file
map_file: path/to/mapping.csvdate_format
Change the format of a date column.
- operation: date_format
column: date_of_birth
# or
columns:
- date_column_1
- date_column_2
- date_column_3
from_format: "%b %d %Y %H:%M%p"
to_format: "%Y-%m-%d"
ignore_errors: False # Default False
exact_match: False # Default FalseThe from_format and to_format must follow Python's strftime() and strptime() formats.
When ignore_errors is set to True, empty strings will be replaced with Pandas NaT (not-a-time) datatypes.
This ensures column-consistency and prevents a mix of empty strings and timestamps.
When exact_match is set to True, the operation will only run successfully if the from_format input exactly matches the format of the date column.
When False, the operation allows the format to partially-match the target string.
distinct_rows
Removes duplicate rows.
- operation: distinct_rows
columns:
- distinctness_column_1
- distinctness_column_2Optionally specify the columns to use for uniqueness, otherwise all columns are used. If duplicate rows are found, only the first is kept.
filter_rows
Filter (include or exclude) rows matching a query.
- operation: filter_rows
query: school_year < 2020
behavior: exclude | includeThe query format is anything supported by Pandas.DataFrame.query. Specifying behavior as exclude wraps the Pandas query() with not().
sort_rows
Sort rows by one or more columns.
- operation: sort_rows
columns:
- sort_column_1
descending: FalseBy default, rows are sorted ascendingly. Set descending: True to reverse this order.
limit_rows
Limit the number of rows in the dataframe.
- operation: limit_rows
count: 5 # required, no default
offset: 10 # optional, default 0(If fewer than count rows in the dataframe, they will all be returned.)
flatten
Split values in a column and create a copy of the row for each value.
- operation: flatten
flatten_column: my_column
left_wrapper: '["' # characters to trim from the left of values in `flatten_column`
right_wrapper: '"]' # characters to trim from the right of values in `flatten_column`
separator: "," # the string by which to split values in `flatten_column`
value_column: my_value # name of the new column to create with flattened values
trim_whitespace: " \t\r\n\"" # characters to trim from `value_column` _after_ flatteningThe defaults above are designed to allow flattening JSON arrays (in a string) with simply
- operation: flatten
flatten_column: my_column
value_column: my_valueNote that for empty string values or empty arrays, a row will still be preserved. These can be removed in a second step with a filter_rows operation. Example:
# Given a dataframe like this:
# foo bar to_flatten
# --- --- ----------
# foo1 bar1 "[\"test1\",\"test2\",\"test3\"]"
# foo2 bar2 ""
# foo3 bar3 "[]"
# foo4 bar4 "[\"test4\",\"test5\",\"test6\"]"
#
# a flatten operation like this:
- operation: flatten
flatten_column: to_flatten
value_column: my_value
# will produce a dataframe like this:
# foo bar my_value
# --- --- --------
# foo1 bar1 test1
# foo1 bar1 test2
# foo1 bar1 test3
# foo2 bar2 ""
# foo3 bar3 ""
# foo4 bar4 test4
# foo4 bar4 test5
# foo4 bar4 test6
#
# and you can remove the blank rows if needed with a further operation:
- operation: filter_rows
query: my_value == ''
behavior: excludegroup_by
Reduce the number of rows by grouping, and add columns with values calculated over each group.
- operation: group_by
group_by_columns:
- student_id
create_columns:
num_scores: count()
min_score: min(item_score)
max_score: max(item_score)
avg_score: mean(item_score)
item_scores: agg(item_score,;)Valid aggregation functions are
count()orsize()- the number of rows in each groupmin(column)- the minimum (numeric) value incolumnfor each groupstr_min(column)- the minimum (string) value incolumnfor each groupmax(column)- the maximum (numeric) value incolumnfor each groupstr_max(column)- the maximum (string) value incolumnfor each groupsum(column)- the sum of (numeric) values incolumnfor each groupmean(column)oravg(column)- the mean of (numeric) values incolumnfor each groupstd(column)- the standard deviation of (numeric) values incolumnfor each groupvar(column)- the variance of (numeric) values incolumnfor each groupagg(column,separator)- the values ofcolumnin each group are concatenated, delimited byseparator(defaultseparatoris none)json_array_agg(column,[str])- the values ofcolumnin each group are concatenated into a JSON array ([1,2,3]). If the optionalstrargument is provided, the values in the array are quoted (["1", "2", "3"])
Numeric aggregation functions will fail with errors if used on non-numeric column values.
Note the difference between min()/max() and str_min()/str_max(): given a list like 10, 11, 98, 99, 100, 101, return values are
| function | return |
|---|---|
min() |
10 |
str_min() |
10 |
max() |
101 |
str_max() |
99 |
debug
Sort rows by one or more columns.
- operation: debug
function: head | tail | describe | columns # default=head
rows: 10 # (optional, default=5; ignored if function=describe|columns)
transpose: True # (default=False; ignored when function=columns)
skip_columns: [a, b, c] # to avoid logging PII
keep_columns: [x, y, z] # to look only at specific columnsfunction=head|tail displays the rows first or last rows of the dataframe, respectively. (Note that on large dataframes, these may not truly be the first/last rows, due to Dask's memory optimizations.) function=describe shows statistics about the values in the dataframe. function=columns shows the column names in the dataframe. transpose can be helpful with very wide dataframes. keep_columns defaults to all columns, skip_columns defaults to no columns.
The destinations section of the YAML configuration specifies how transformed data is materialized to files.
A sample destinations section is shown here; the options are explained below.
destinations:
schools:
source: $transformations.school_list
template: ./json_templates/school.jsont
extension: jsonl
linearize: True
courses:
source: $transformations.course_list
template: ./json_templates/course.jsont
extension: jsonl
linearize: True
course_report:
source: $transformations.course_list
template: ./json_templates/course.htmlt
extension: html
linearize: False
header: <html><body><h1>Course List:</h1>
footer: </body></html>For each file you want materialized, provide the source and the template file — a text file (JSON, XML, HTML, etc.) containing Jinja with references to the columns of source. The materialized file will contain template rendered for each row of source, with an optional header prefix and footer postfix (both of which may contain Jinja, and which may reference __row_data__ which is the first row of the data frame... a formulation such as {%raw%}{% for k in __row_data__.pop('__row_data__').keys() %}{{k}}{% if not loop.last %},{% endif %}{% endfor %}{%endraw%} may be useful). Files are materialized using your specified extension (which is required).
If linearize is True, all line breaks are removed from the template, resulting in one output line per row. (This is useful for creating JSONL and other linear output formats.) If omitted, linearize is True.
Any source, transformation, or destination node may also specify
debug: True, which outputs the dataframe shape and columns after the node completes processing (this can be helpful for building and debugging)require_rows: Trueorrequire_rows: 10to have earthmover exit with an error if 0 (forTrue) or less then 10 (for10) rows are present in the dataframe after the node completes processingshow_progress: Trueto display a progress bar while processing this noderepartition: Trueto repartition the node in memory before continuing to the next node; set either the number of bytes, or a text representation (e.g., "100MB") to shuffle data into new partitions of that size (Note: this configuration is advanced, and its use may drastically affect performance)
Once you have the required setup and your source data, run the transformations with
earthmover run -c path/to/config.yamlIf you omit the optional -c flag, earthmover will look for an earthmover.yaml in the current directory.
To remove all files created by Earthmover, run earthmover clean
See a help message with
earthmover -h
earthmover --helpSee the tool version with
earthmover -v
earthmover --versionOverride values in the config file with --set, for example
earthmover run --set config.tmp_dir path/to/another/dir/
earthmover run --set sources.schools.file './my schools with spaces.csv'
earthmover run --set destinations.my_dest.extension ndjson destinations.my_dest.linearize True(The flag must be followed by a set of key-value pairs.)
This tool includes several special features:
You may use Jinja in the YAML configuration, which will be parsed at load time. Only the config section may not contain Jinja, except for macros which are made available both at parse-time for Jinja in the YAML configuration and at run-time for Jinja in add_columns or modify_columns transformation operations.
The following example
- loads 9 source files
- adds a column indicating the source file each row came from
- unions the sources together
- if an environment variable or parameter
DO_FILTERING=Trueis passed, filters out certain rows
config:
show_graph: True
parameter_defaults:
DO_FILTERING: "False"
sources:
{% for i in range(1,10) %}
source{{i}}:
file: ./sources/source{{i}}.csv
header_rows: 1
{% endfor %}
transformations:
{% for i in range(1,10) %}
source{{i}}:
source: $sources.source{{i}}
operations:
- operation: add_columns
columns:
source_file: {{i}}
{% endfor %}
stacked:
source: $transformations.source1
operations:
- operation: union
sources:
{% for i in range(2,10) %}
- $transformations.source{{i}}
{% endfor %}
{% if "${DO_FILTERING}"=="True" %}
- operations: filter_rows
query: school_year < 2020
behavior: exclude
{% endif %}
destinations:
final:
source: $transformations.stacked
template: ./json_templates/final.jsont
extension: jsonl
linearize: TrueRun only portions of the DAG by using a selector:
earthmover run -c path/to/config.yaml -s people,people_*This processes all DAG paths (from sources to destinations) through any matched nodes.
If you specify the columns list and optional: True on a file source but leave the file blank, earthmover will create an empty dataframe with the specified columns and pass it through the rest of the DAG. This, combined with the use of environment variable references and/or command-line parameters to specify a source's file, provides flexibility to include data when it's available but still run when it is missing.
In your YAML configuration, you may reference environment variables with ${ENV_VAR}. This can be useful for making references to source file locations dynamic, such as
sources:
people:
file: ${BASE_DIR}/people.csv
...Note: because os.path.expandvars() does not expand variables within single quotes in Python under Windows, Windows users should avoid placing environment variable references (or CLI parameter references) inside single quote strings in their YAML.
Similarly, you can specify parameters via the command line with
earthmover run -c path/to/config.yaml -p '{"BASE_DIR":"path/to/my/base/dir"}'
earthmover run -c path/to/config.yaml --params '{"BASE_DIR":"path/to/my/base/dir"}'Command-line parameters override any environment variables of the same name.
This tool maintains state about past runs. Subsequent runs only re-process if something has changed – the YAML configuration itself, data files of sources, value_mapping CSVs of transformations, template files of destinations, or CLI parameters. (Changes are tracked by hashing files; hashes and run timestamps are stored in the file specified by config/state_file.) You may choose to override this behavior and force reprocessing of the whole DAG, regardless of whether files have changed or not, using the -f or --force command-line flag:
earthmover run -c path/to/config.yaml -f
earthmover run -c path/to/config.yaml --force-regenerateTo further avoid computing input hashes and not log a run to the state_file, use the -k or --skip-hashing flag:
earthmover run -c path/to/config.yaml -k
earthmover run -c path/to/config.yaml --skip-hashing(This makes a one-time run on large input files faster.) If earthmover skips running because nothing has changed, it returns bash exit code 99 (this was chosen because it signals a "skipped" task in Airflow).
To produce a JSON file with metadata about the run, invoke earthmover with
earthmover run -c path/to/config.yaml --results-file ./results.jsonFor example, for example_projects/09_edfi/, a sample results file would be:
{
"started_at": "2023-06-08T10:21:42.445835",
"working_dir": "/home/someuser/code/repos/earthmover/example_projects/09_edfi",
"config_file": "./earthmover.yaml",
"output_dir": "./output/",
"row_counts": {
"$sources.schools": 6,
"$sources.students_anytown": 1199,
"$sources.students_someville": 1199,
"$destinations.schools": 6,
"$transformations.all_students": 2398,
"$destinations.students": 2398,
"$destinations.studentEducationOrganizationAssociations": 2398,
"$destinations.studentSchoolAssociations": 2398
},
"completed_at": "2023-06-08T10:21:43.118854",
"runtime_sec": 0.673019
}An earthmover project can import and build upon other earthmover projects by importing them as packages, similar to the concept of dbt packages. When a project uses a package, any elements of the package can be overwritten by the project. This allows you to use majority of the code from a package and specify only the necessary changes in the project.
To install the packages specified in your YAML Configuration, run earthmover deps. Packages will be installed in a nested format in a packages/ directory. Once packages are installed, earthmover can be run as usual. If you make any changes to the packages, run earthmover deps again to install the latest version of the packages.
Example of a composed project
# projA/earthmover.yml # projA/pkgB/earthmover.yml
config: config:
show_graph: True parameter_defaults:
output_dir: ./output DO_FILTERING: "False"
packages: sources:
pkgB: source1:
local: pkgB file: ./seeds/source1.csv
header_rows: 1
sources: source2:
source1: file: ./seeds/source2.csv
file: ./seeds/source1.csv header_rows: 1
header_rows: 1
transformations:
destinations: trans1:
dest1: ...
source: $transformations.trans1
template: ./templates/dest1.jsont destinations:
dest1:
source: $transformations.trans1
template: ./templates/dest1.jsont
dest2:
source: $sources.source2
template: ./templates/dest2.jsontComposed results:
config:
show_graph: True
output_dir: ./output
parameter_defaults:
DO_FILTERING: "False"
packages:
pkgB:
local: pkgB
sources:
source1:
file: ./seeds/source1.csv
header_rows: 1
source2:
file: ./packages/pkgB/seeds/source2.csv
header_rows: 1
transformations:
trans1:
...
destinations:
dest1:
source: $transformations.trans1
template: ./templates/dest1.jsont
dest2:
source: $sources.source2
template: ./packages/pkgB/templates/dest2.jsont-
The
configsection is not composed from the installed packages, with the exception ofmacrosandparameter_defaults. Specify all desired configuration in the top-level project. -
There is no limit to the number of packages that can be imported and no limit to how deeply they can be nested (i.e. packages can import other packages). However, there are a few things to keep in mind with using multiple packages.
- If multiple packages at the same level (e.g.
projA/packages/pkgBandprojA/packages/pkgC, notprojA/packages/pkgB/packages/pkgC) include same-named nodes, the package specified later in thepackageslist will overwrite. If the node is also specified in the top-level project, its version of the node will overwrite as usual. - A similar limitation exists for macros – a single definition of each macro will be applied everywhere in the project and packages using the same overwrite logic used for the nodes. When you are creating projects that are likely to be used as packages, consider including a namespace in the names of macros with more common operations, such as
assessment123_filter()instead of the more genericfilter().
- If multiple packages at the same level (e.g.
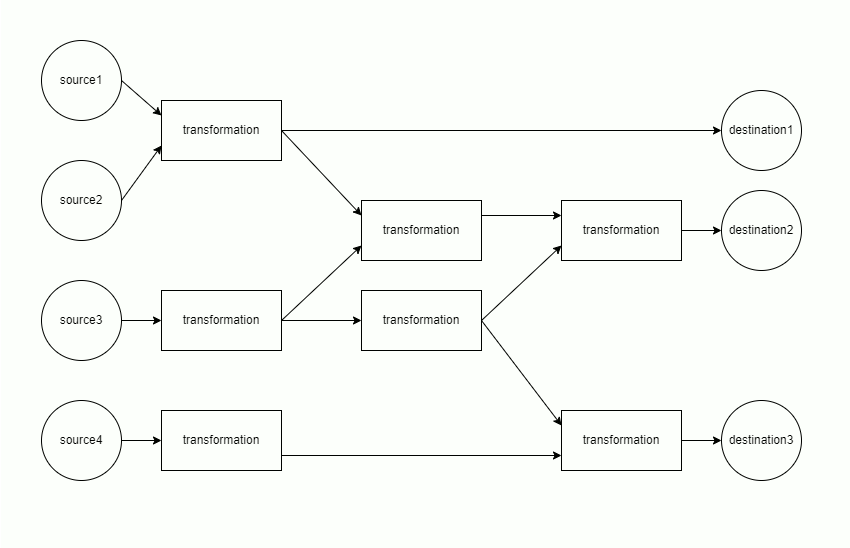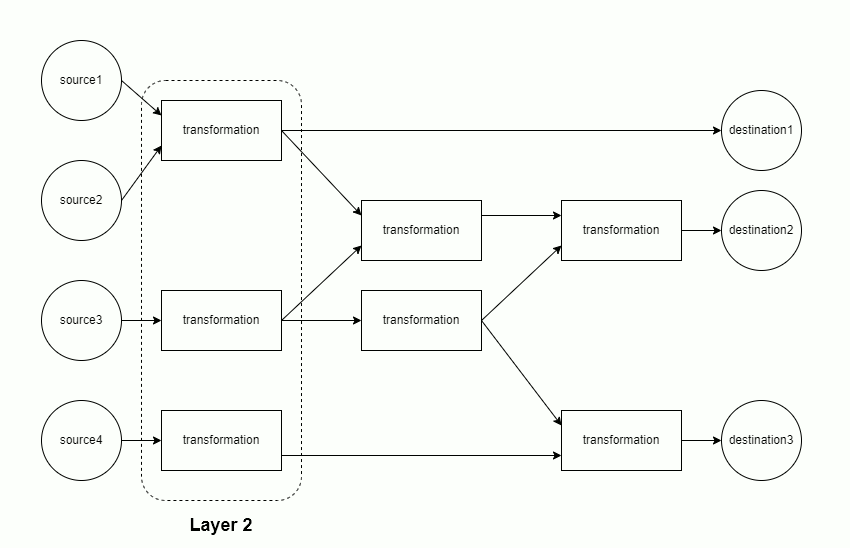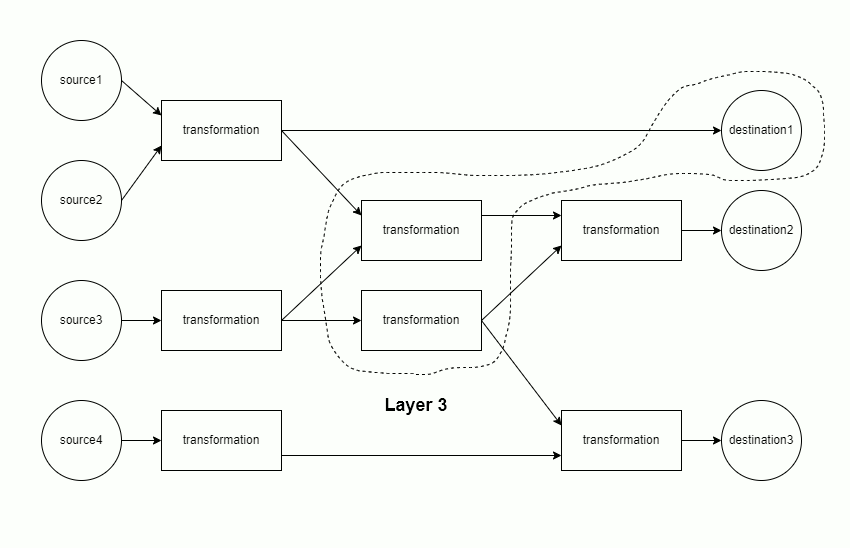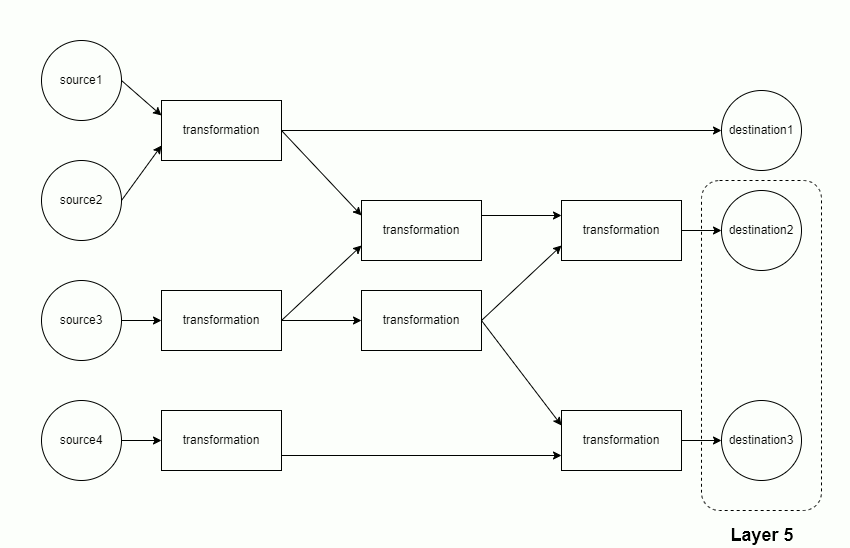
This tool ships with a test suite covering all transformation operations. It can be run with earthmover -t, which simply runs the tool on the config.yaml and toy data in the earthmover/tests/ folder. (The DAG is pictured below.) Rendered earthmover/tests/output/ are then compared against the earthmover/tests/expected/ output; the test passes only if all files match exactly.
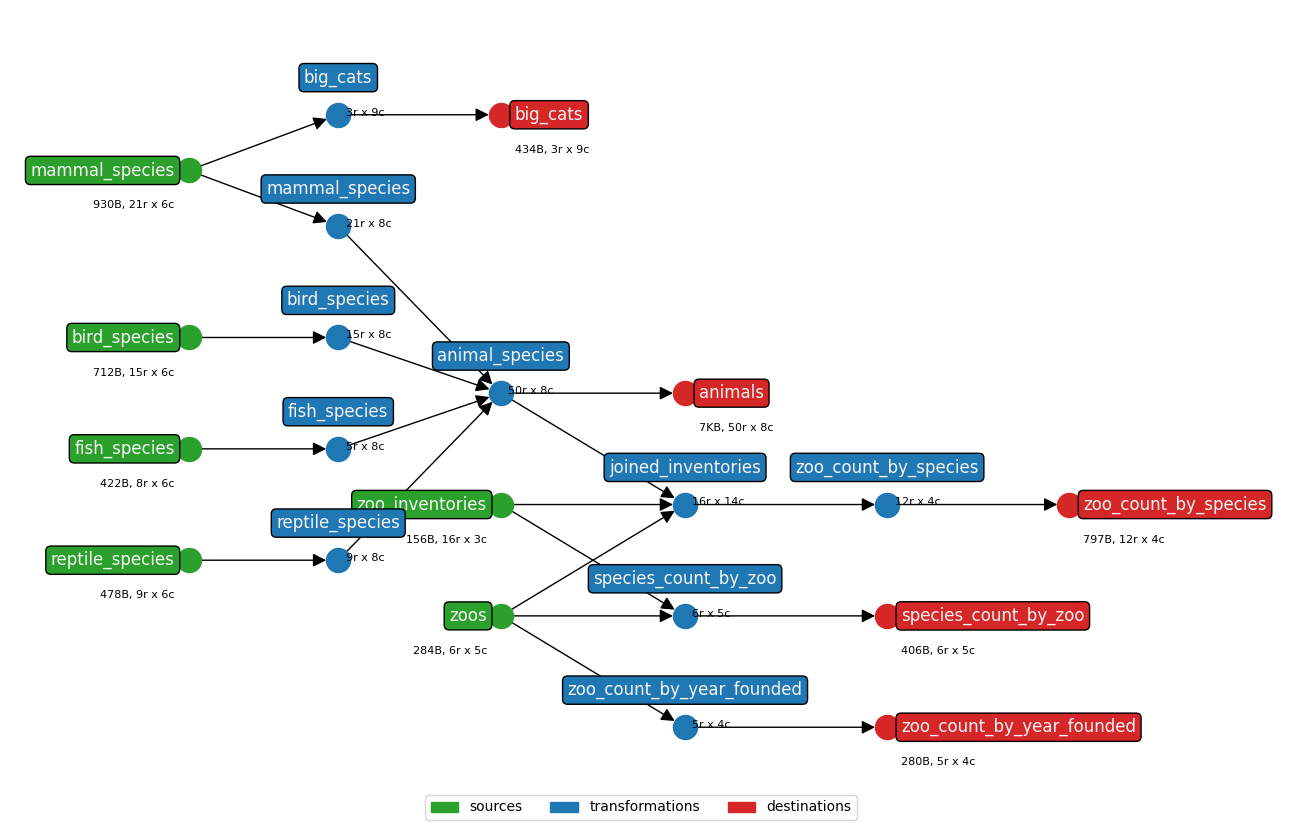
Run tests with
earthmover -tSome details of the design of this tool are discussed below.
earthmover allows Jinja templating expressions in its YAML configuration files. (This is similar to how Ansible Playbooks work.) earthmover parses the YAML in several steps:
- Extract only the
configsection (if any), in order to make available anymacroswhen parsing the rest of the Jinja + YAML. Theconfigsection only may not contain any Jinja (besidesmacros). - Load the entire Jinja + YAML as a string and hydrate all environment variable or parameter references.
- Parse the hydrated Jinja + YAML string with any
macrosto plain YAML. - Load the plain YAML string as a nested dictionary and begin building and processing the DAG.
Note that due to step (3) above, runtime Jinja expressions (such as column definitions for add_columns or modify_columns operations) should be wrapped with {%raw%}...{%endraw%} to avoid being parsed when the YAML is being loaded.
The parsed YAML is written to a file called earthmover_compiled.yaml in your working directory during a compile command. This file can be used to debug issues related to compile-time Jinja or project composition.
The mapping of sources through transformations to destinations is modeled as a directed acyclic graph (DAG). Each component of the DAG is run separately.
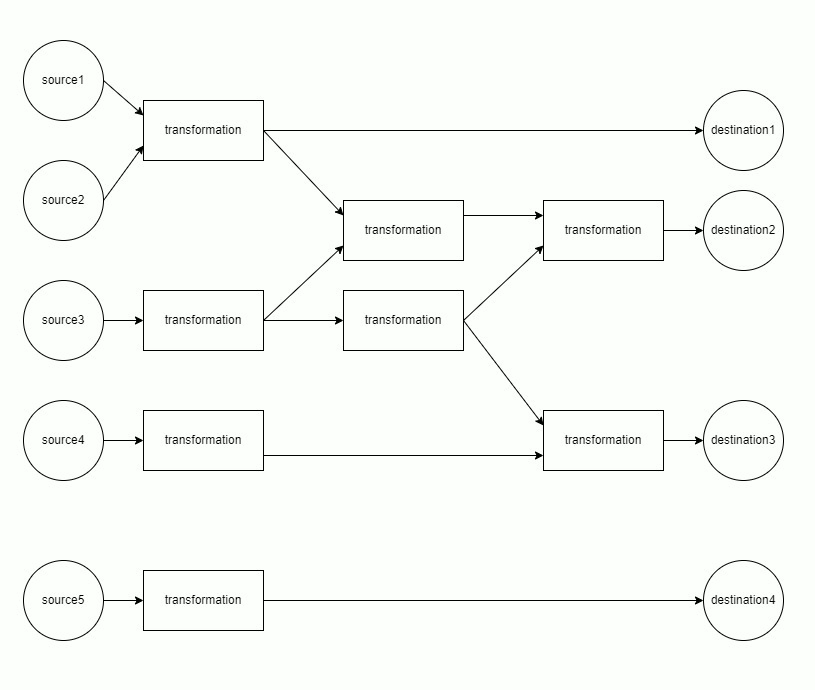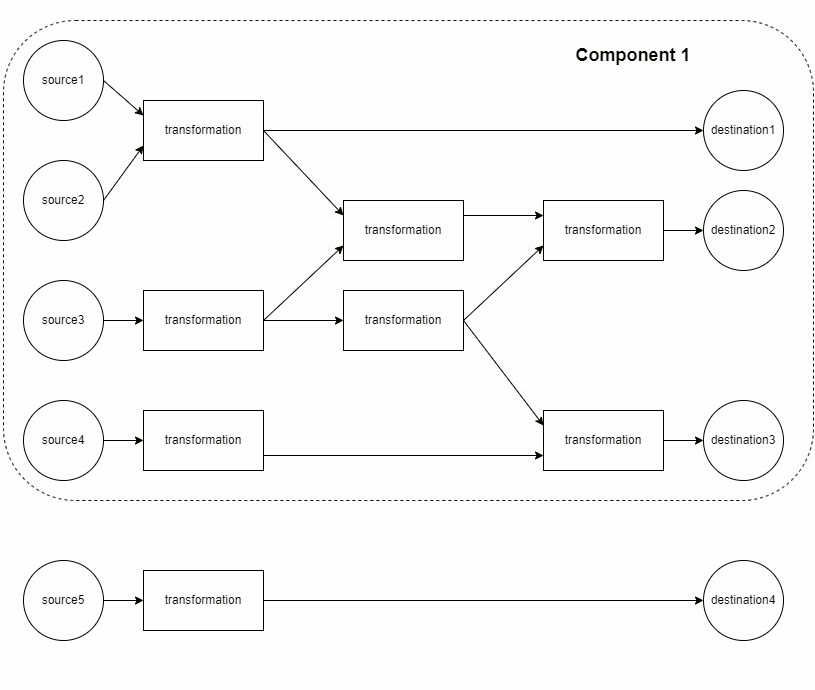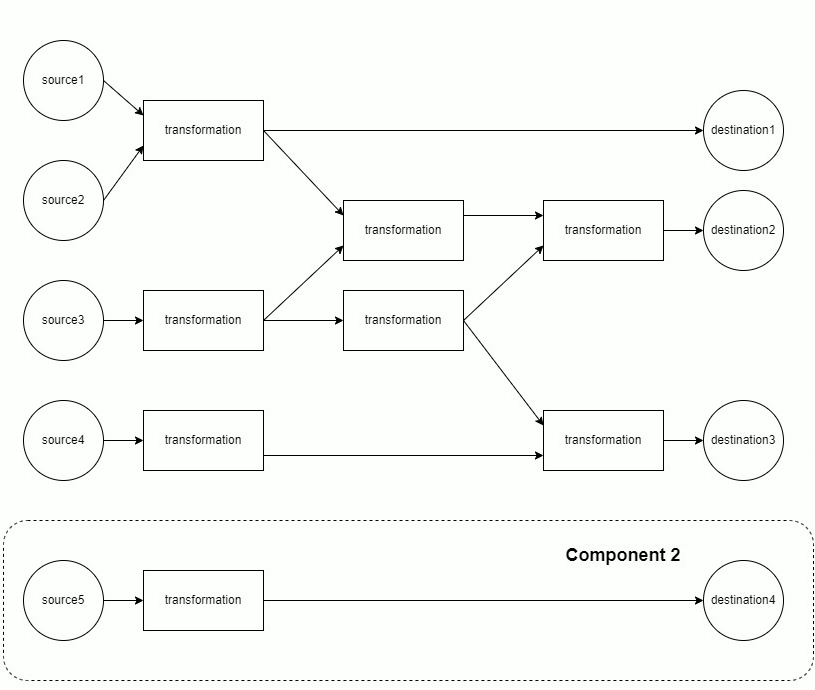
Each component is materialized in topological order. This minimizes memory usage, as only the data from the current and previous layer must be retained in memory.
All data processing is done using Pandas Dataframes and Dask, with values stored as strings (or Categoricals, for memory efficiency in columns with few unique values). This choice of datatypes prevents issues arising from Pandas' datatype inference (like inferring numbers as dates), but does require casting string-representations of numeric values using Jinja when doing comparisons or computations.
Tool performance depends on a variety of factors including source file size and/or database performance, the system's storage performance (HDD vs. SSD), memory, and transformation complexity. But some effort has been made to engineer this tool for high throughput and to work in memory- and compute-constrained environments.
Smaller source data (which all fits into memory) processes very quickly. Larger chunked sources are necessarily slower. We have tested with sources files of 3.3GB, 100M rows (synthetic attendance data): creating 100M lines of JSONL (30GB) takes around 50 minutes on a modern laptop.
The state feature adds some overhead, as hashes of input data and JSON payloads must be computed and stored, but this can be disabled if desired.
In this section we outline some suggestions for best practices to follow when using earthmover, based on our experience with the tool. Many of these are based on best practices for using dbt, to which earthmover is similar, although earthmover operates on dataframes rather than database tables.
A typical earthmover project might have a structure like this:
project/
├── README.md
├── sources/
│ └── source_file_1.csv
│ └── source_file_2.csv
│ └── source_file_3.csv
├── earthmover.yaml
├── output/
│ └── output_file_1.jsonl
│ └── output_file_2.xml
├── seeds/
│ └── crosswalk_1.csv
│ └── crosswalk_2.csv
├── templates/
│ └── json_template_1.jsont
│ └── json_template_2.jsont
│ └── xml_template_1.xmlt
│ └── xml_template_2.xmlt
Generally you should separate the mappings, transformations, and structure of your data – which are probably not sensitive – from the actual input and output – which may be large and/or sensitive, and therefore should not be committed to a version control system. This can be accomplished in two ways:
- include a
.gitignoreor similar file in your project which excludes thesources/andoutput/directories from being committed the repository - remove the
sources/andoutput/directories from your project and updateearthmover.yaml'ssourcesanddestinationsto reference another location outside theproject/directory
When dealing with sensitive source data, you may have to comply with security protocols, such as referencing sensitive data from a network storage location rather than copying it to your own computer. In this situation, option 2 above is a good choice.
To facilitate operationalization, we recommended using relative paths from the location of the earthmover.yaml file and environment variables or command-line parameters to pass filenames to earthmover, rather than hard-coding them into earthmover.yaml. For example, rather than
config:
output_dir: /path/to/outputs/
...
sources:
source_1:
file: /path/to/inputs/source_file_1.csv
header_rows: 1
source_2:
file: /path/to/inputs/source_file_2.csv
header_rows: 1
...
destinations:
output_1:
source: $transformations.transformed_1
...
output_2:
source: $transformations.transformed_2
...instead consider using
config:
output_dir: ${OUTPUT_DIR}
...
sources:
source_1:
file: ${INPUT_FILE_1}
header_rows: 1
source_2:
file: ${INPUT_FILE_2}
header_rows: 1
seed_1:
file: ./seeds/seed_1.csv
...
destinations:
output_1:
source: $transformations.transformed_1
...
output_2:
source: $transformations.transformed_2
...and then run with
earthmover earthmover.yaml -p '{ "OUTPUT_DIR": "path/to/outputs/", "INPUT_FILE_1": "/path/source_file_1.csv", "INPUT_FILE_2": "/path/source_file_2.csv" }'Note that with this pattern you can also use optional sources to only create one of the outputs if needed, for example
earthmover earthmover.yaml -p '{ "OUTPUT_DIR": "path/to/outputs/", "INPUT_FILE_1": "/path/source_file_1.csv" }'would only create output_1 if source_1 had required: False (since INPUT_FILE_2 is missing).
While YAML is a data format, it is best to treat the earthmover YAML configuration as code, meaning you should
- version it!
- avoid putting credentials and other sensitive information in the configuration; rather specify such values as environment variables or command-line parameters
- keep your YAML DRY by using Jinja macros and YAML anchors and aliases
Remember that code is poetry: it should be beautiful! To that end
- Carefully choose concise, good names for your
sources,transformations, anddestinations.- Good names for
sourcescould be based on their source file/table (e.g.studentsforstudents.csv) - Good names for
transformationsindicate what they do (e.g.students_with_mailing_addresses) - Good names for
destinationscould be based on the destination file (e.g.student_mail_merge.xml)
- Good names for
- Add good, descriptive comments throughout your YAML explaining any assumptions or non-intuitive operations (including complex Jinja).
- Likewise put Jinja comments in your templates, explaining any complex logic and structures.
- Keep YAML concise by composing
transformationoperations where possible. Many operations likeadd_columns,map_values, and others can operate on multiplecolumnsin a dataframe. - At the same time, avoid doing too much at once in a single
transformation; splitting multiplejoinoperations into separate transformations can make debugging easier.
When developing your transformations, it can be helpful to
- specify
config»log_level: DEBUGandtransformation»operation»debug: Trueto verify the columns and shape of your data after eachoperation - turn on
config»show_stacktrace: Trueto get more detailed error messages - avoid name-sharing for a
source, atransformation, and/or adestination- this is allowed but can make debugging confusing - install pygraphviz and turn on
config»show_graph: True, then visually inspect your transformations ingraph.pngfor structural errors - use a linter/validator to validate the formatting of your generated data
You can remove these settings once your earthmover project is ready for operationalization.
Typically earthmover is used when the same (or similar) data transformations must be done repeatedly. (A one-time data transformation task may be more easily done with SQLite or a similar tool.) When deploying/operationalizing earthmover, whether with a simple scheduler like cron or an orchestration tool like Airflow or Dagster, consider
-
specifying conditions you
expectyour sources to meet, soearthmoverwill fail on source data errors -
specifying
config»log_level: INFOand monitoring logs for phrases likedistinct_rowsoperation removed NN duplicate rowsfilter_rowsoperation removed NN rows
See CHANGELOG.
Bugfixes and new features (such as additional transformation operations) are gratefully accepted via pull requests here on GitHub.
- Cover image created with DALL • E mini
See License.
Bundles are pre-built data mappings for converting various data formats to Ed-Fi format using this tool. They consist of a folder with CSV seed data, JSON template files, and a config.yaml with sources, transformations, and destinations.
Here we maintain a list of bundles for various domain-specific uses:
- Bundles for transforming assessment data from various vendors to the Ed-Fi data standard
If you develop bundles, please consider contributing them to the community by publishing them online and emailing the link to [email protected] to get them listed above.