Rationale
TL;DR A demo tool that scans satellite to flag unmapped locations.
TL;DR well-trained machines can do a remarkable job at scanning our world imagery to find missing features in the map.
In recent months, Machine Learning has caught the attention of the OSM and HOT communities as a potential tool for increasing map coverage.
Projects like Devseed, (e.g. trailbehind/DeepOSM and OSM-HOT-ConvNet) have been tackling the problem of feature detection, to find buildings, detect road geometries, and reconstruct the topology of the map; others like the impressive terrapattern project are attempting to tag the world.
The results are amazing.
Can we build a scanner?
I started playing with the idea of building a scanner that could search through our imagery and find those unmapped objects in OSM; particularly for regions where many roads are missing.
My idea wasn't building complex feature detection like the previous examples, but put together a practical user interface to automatically flag unmapped places. In other words, predicting whether a cat is in the image, instead of detecting the shape or the position of the cat.

Planning to scan roads in Ensenada, Mexico
P.S. you don’t need a PhD to understand how this works.
The technology behind these efforts is a particular kind of technique well known in the field of computer vision and image recognition competitions; a Convolutional Neural Network.
For those new to the idea. Neural Networks as any other Machine Learning technique, is an approach to solving problems where rule-based algorithms won't work, I'll leave the exercise of "trying to describe an image of a cat" to the reader.
As you feed this Neural Net with thousands of images, it will adjust the relevance of each "feature" from the examples and build a complex set of weighted rules to predict a result (i.e. is this a cat?).
The Convolutional part is useful when dealing with images, because it adds some previous steps (a.k.a layers), where we use filters to extract "and summarize" patterns like edges, or color density from the images, and finally pass a gazillion of numerical vallues to our neural network to learn a predicting model that will try to minimize error on each training step.

Convolutional layers apply transform functions on the image to extract patterns. Ref: cs231n.github.io
If you are interested in learning more about Convolutional Neural Networks check out this sources:
- Stanford's CS231n Convolutional Neural Networks for Visual Recognition
- Michael Nielsen's online book on Neural Networks and Deep Learning
NOTE: A special type of ConvNet called SegNet is used for feature detection; for standard image classification a traditional ConvNet.
To build a proof-of-concept over the winter break I needed a couple of things:
- A collection of labeled images for places containing roads and places where we are sure there are no roads.
- A machine learning library with a battle-tested implementation of a ConvNet for image classification.
Training set: collecting data
With OSM QA tiles and tile-reduce it is straightforward to extract locations where we have roads in OSM, i.e. if (feature.properties.highway). Once you find a road in a tile, you fetch that z/x/y tile from the mapbox-satellite API to get a labeled image for roads. After a couple of minutes running this script I collected a thousand z16 images for the first class.


For the second class (where we don't have roads), the process is a bit more tricky. One does not simply go and fetch images where there are no roads in OSM, because there's a chance you'll find false negatives and train your neural net on bad examples.

So I spent almost an hour tagging over 500 images manually, and using some known cheats to extend this dataset by flipping and distorting the images to generate more samples for "not a road in this picture".
In the end I collected over 2k labeled images at z16 to run a first trial.
The toolbox: tensorflow + inception
Despite its unstable documentation and breaking changes, tensorflow provides out-of-the-box tooling to get you started quickly.
In addition, Google made public the Inception v3 model a state-of-the-art ConvNet based on the ImageNet dataset (the olympics of image classification). With a technique called transfer learning, it is quite easy to repurpose layers trained over weeks of datacenter processing to work on a new set of images, i.e. from cat breeds to roads in OSM. Basically you just trained the last layer of the ConvNet on your images, taking advantage of all the convolutional steps that worked successfully for ImageNet.
Hacker trivia: if you try to classify a rural road with the original inception model, guess what object will it predict?
{kind=link}
Ok, here we go...
Training...

python tensorflow/examples/image_retraining/retrain.py --bottleneck_dir=/tf_files/bottlenecks --how_many_training_steps 500 --model_dir=/tf_files/inception --output_graph=/tf_files/retrained_graph.pb --output_labels=/tf_files/retrained_labels.txt --image_dir /tf_files/satellite
...
2017-01-01 03:02:56.710327: Step 499: Train accuracy = 91.0%
2017-01-01 03:02:56.710478: Step 499: Cross entropy = 0.211515
2017-01-01 03:02:57.068353: Step 499: Validation accuracy = 84.0%
Final test accuracy = 88.8%...let's try thiiis tile 16/11820/26685:
{kind=link}
root@5cca0bc5d586:/tensorflow# bazel-bin/tensorflow/examples/label_image/label_image --graph=/tf_files/retrained_graph.pb --labels=/tf_files/retrained_labels.txt --output_layer=final_result --image=/tf_files/satellite/11820-26685-16.jpg
I tensorflow/examples/label_image/main.cc:205] highway (0): 0.890988
I tensorflow/examples/label_image/main.cc:205] noway (1): 0.109013
89% chance there's a road in that image, this is not a handkerchief
Surprisingly it worked really well. Considering the fact that this neural net was originally trained to identify over 200 breeds of dogs and cats, it can be repurposed to classify satellite images.
You can see more results here.
After running a couple of validation tests, I decided to start hacking on a proxy server to hook a web interface to the docker containers running the tensorflow classifier. Finally some weekends ago I finished a point-and-click tool to massively scan z16 tiles one z12 at a time. Cool!
Tiles in blue have 80% chance of containing a road:
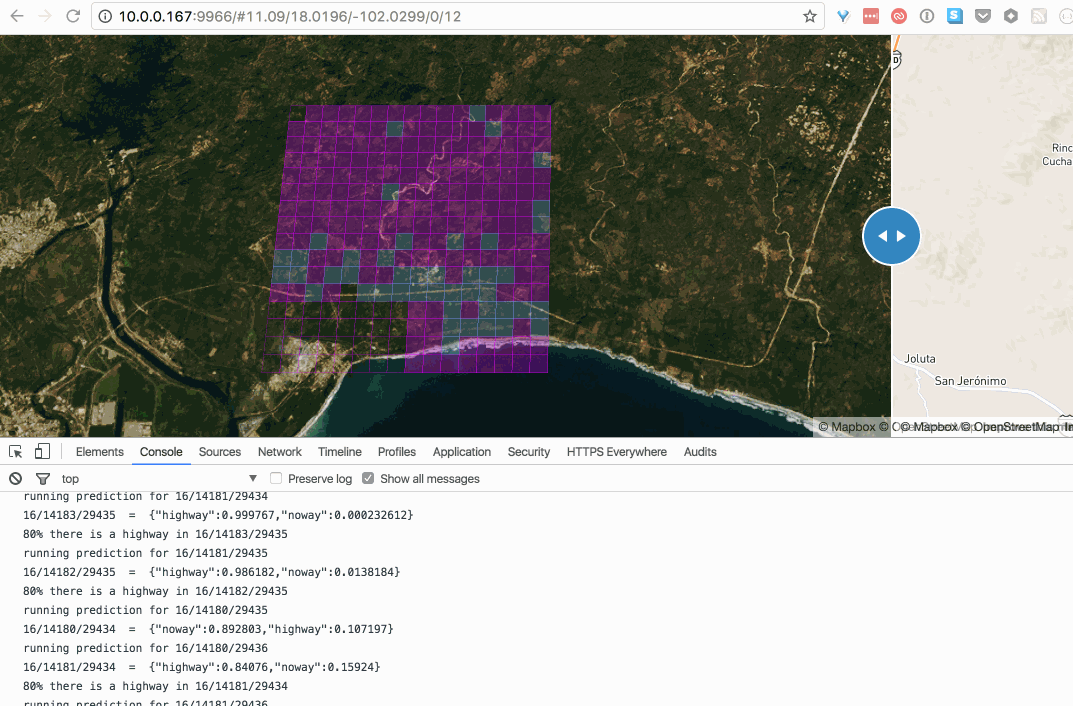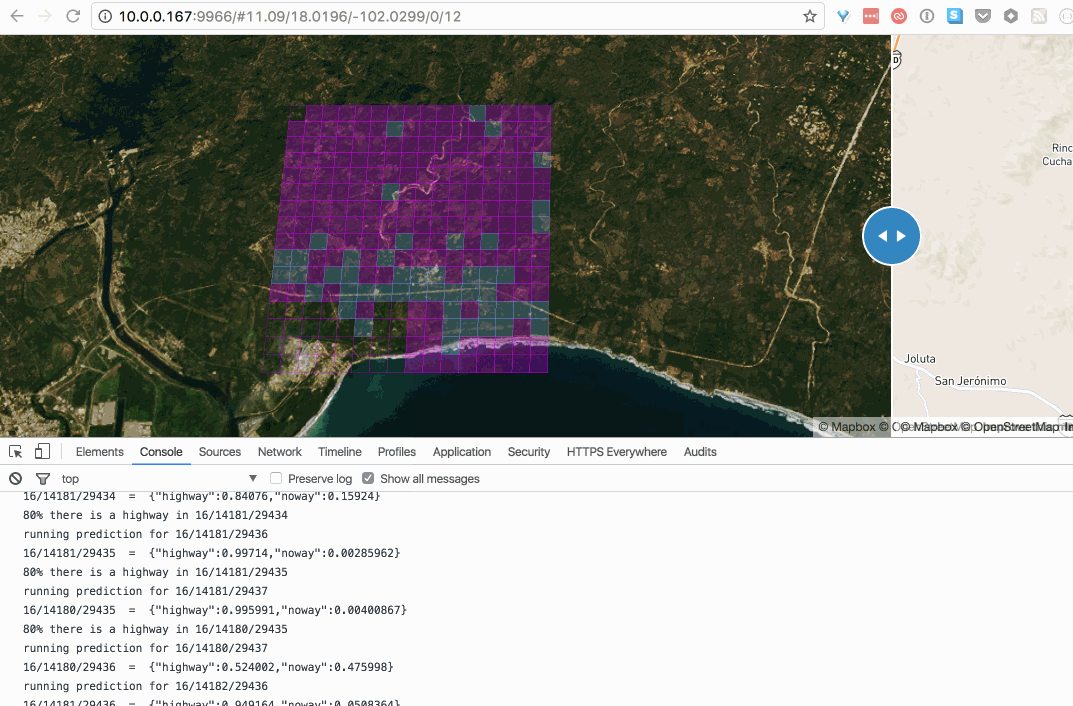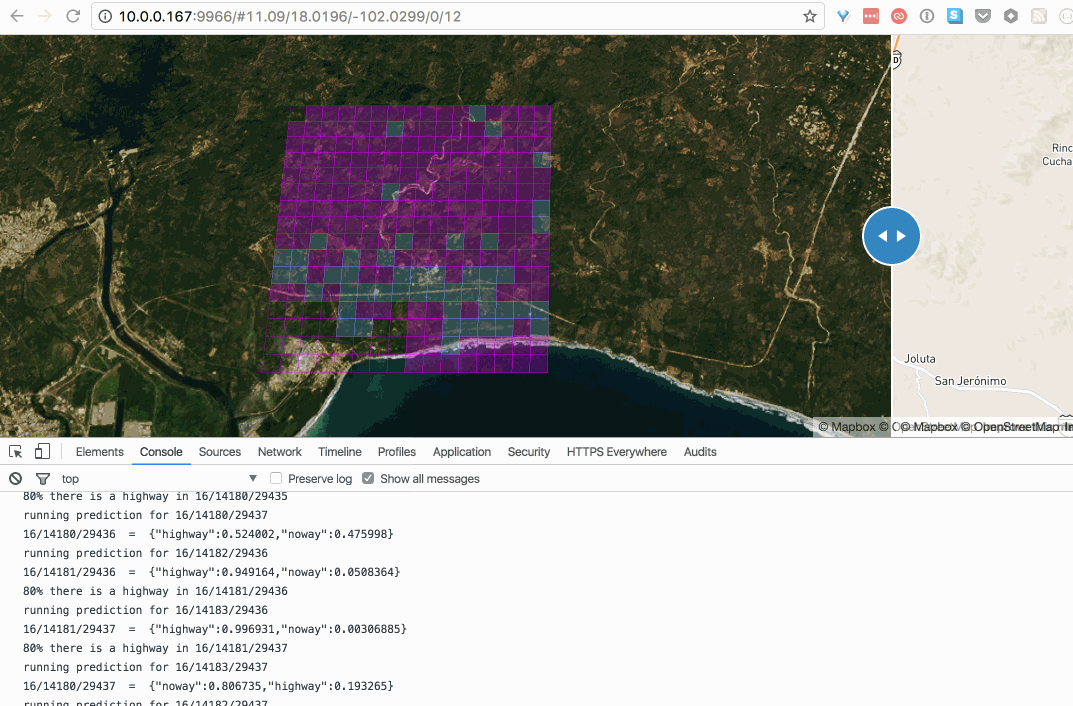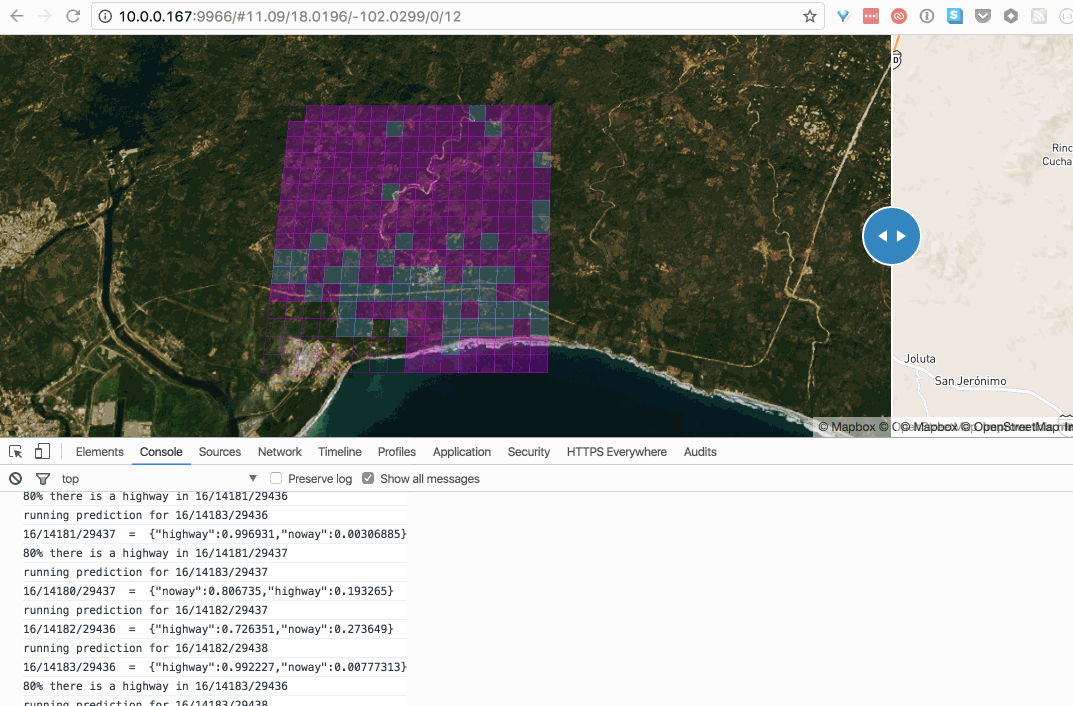
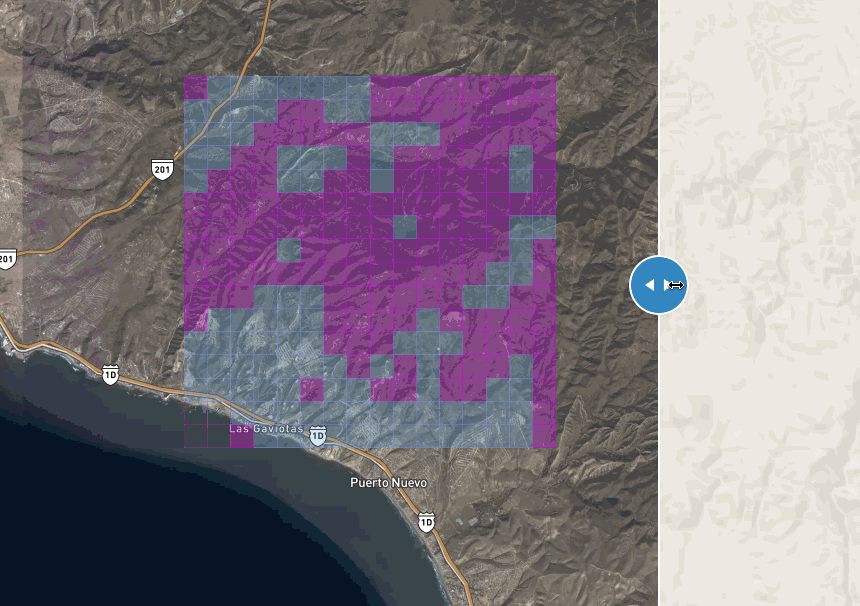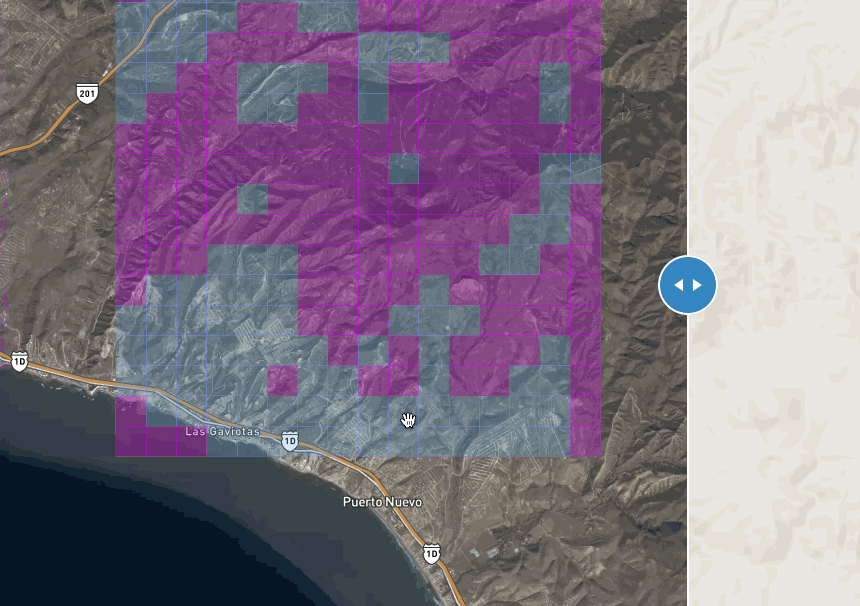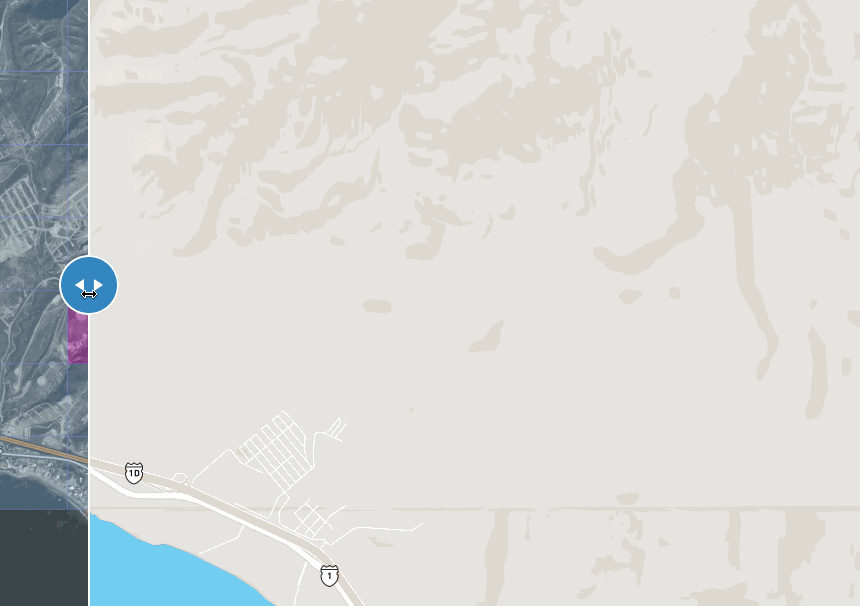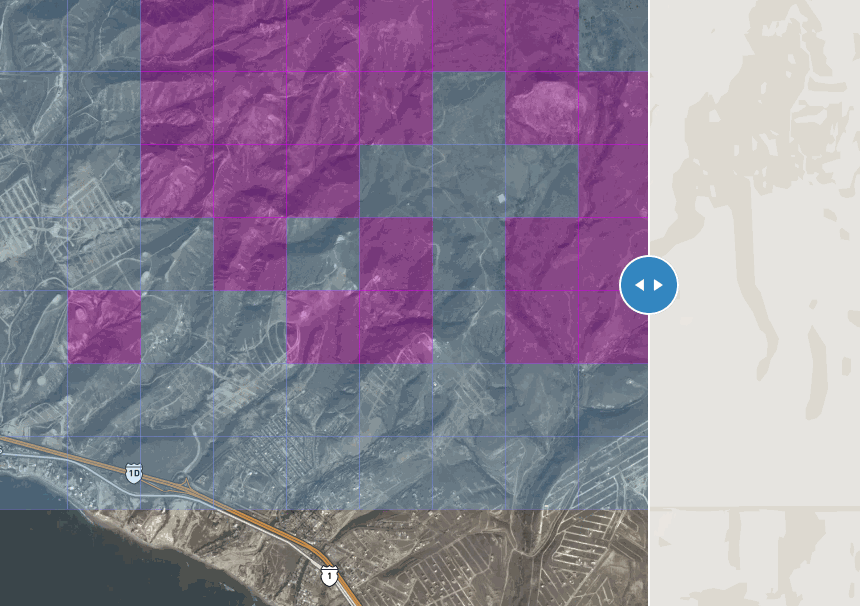
this gif is fat, click to see this in action
You can find more about the experiment in the following repos:
This is clearly an experiment. Without optimization, scanning a whole country with my computer is not scalable at all. It would take millions of z16 tiles to process, e.g. Mexico is covered by 6 tiles at zoom 5, that's roughly 25M z16 tiles (6 * 4 ^ (16 - 5)); at 1s per prediction it would take over 300 days to scan the whole country. If we could lower that number close to 100K tiles (by skipping mapped tiles and water bodies) we could scan a country like Mexico in less than a day (without parallelization and assuming no API throttling). Furthermore, choosing smaller regions like states is definitely feasible on a regular computer with 2GB of RAM and 4GB of free disk space.
I have a bunch of ideas on what's next for this scrappy demo. Hit me up if you want to try this on your computer, find new stuff on the map, or thinking about pointing the scanner elsewhere.
Machine learning is still controversial within the OSM community, and I totally understand, this is becoming scarily scalable. However, putting machines to work on tasks like finding unmapped places is beneficial even for the OSM purists, the hobbyist mapper, and the luddites. By building tools like this, we still keep the most valuable work for our mappers making sure we don't leave places off the map.