The cross-organization feature of service makes it possible for acting as a data sharing medium, when a user requires to access the data sources across organizations, we could compose data services or data providing services to answer the user query.
We proposed a model of continuous query service based on the data stream, and expanded two service composition algorithms(we call them SBucket and SMinicon) based on the ideas of Bucket algorithm and Minicon algorithm which are generally applied in traditional data integration. The aim of our project is to use one of the two algorithms to find executable query rewriting services from services and service instances exposed by system to answer user query.
The main process are the following steps:
- Atomic Services Setting:
Equivalent to the concept of mediation pattern in traditional data integration, and the establishment of user query, continuous query service, and continuous query service instance is based on atomic service.
- User Query Setting:
Conjunctive queries proposed by users based on the atomic services.
- Continuous Query Services or Service Instances Exposed by System Setting:
Equivalent to the concept of view in traditional data integration, they are established on the atomic services, and act as the exposing service source to generate rewriting services to answer user query.
- Service Algorithm Selection and Execution:
After setting the above, what is to do the next is choosing a method to generate rewriting services, SBucket algorithm can be used in SBucket.scala while SMinicon can be used in SMinicon.scala. Then you need to drive the program by appointing the user query, exposing service source in DataUtil.scala.
- Result Analysis:
After executing one of the method, the result will display on console, which includes information about rewriting services, time cost, etc. The following section we will demonstrate a use case to illustrate how it works.
- Download and setup Scala with version of 2.10.6 and JDK with version of 1.7.
- In
DataUtil.scala, create atomic services by providing such parameters :atomicservicename,outputattributes. For example:
val vesseltraj = new QueryService("vesseltraj", Set("mmsi","long","lat","speed"))- In
DataUtil.scala, propose queries based on atomic services by providing such parameters:queryname,queryattributes,dataconstraints(formed as a tuple of ("attribute",(leftvalue,rightvalue)), and POSI means positive infinity while NEGT means negative infinity),timewindow(formed as a tuple of (range, slide)). And then assign one of the queries to the variable query, for example:
val query1 = new QueryService("Q1", Set(vesselinfo, vesseltraj),Set("mmsi","callsign"),Set(("speed",40,POSI)),(5,4))
val query:QueryService = query1- In
DataUtil.scala, create services by providing such parameters:servicename,dataconstraints,timewindow. For example:
val S1 = new QueryService("S1",Set(vesseltraj),Set(("speed",NEGA,30)),(5,2))- Create service instances by providing such parameters:
serviceinstancename,outputattributes,dataconstraints,timewindow. For example:
val S2 = new QueryService("S2",Set(vesseltraj,vesselinfo), Set("mmsi", "draught", "speed"),Set(("imo",NEGA,2000)),(5,2))- Load these to a service collection
ucServicesas a use case service source:
val ucServices = List(S1,S2)- In
SBucket.scala, assign theDataUtil.queryto variablequeryas a user query:
val query = DataUtil.query- Appoint the exposing service source
ucServiceswe created manually in Step 3 :
val services = DataUtil.ucServices- After that you can run the program.
- The result will be displayed on the console, including information about bucket elements, executable service composition collection, and time costs of each phase :
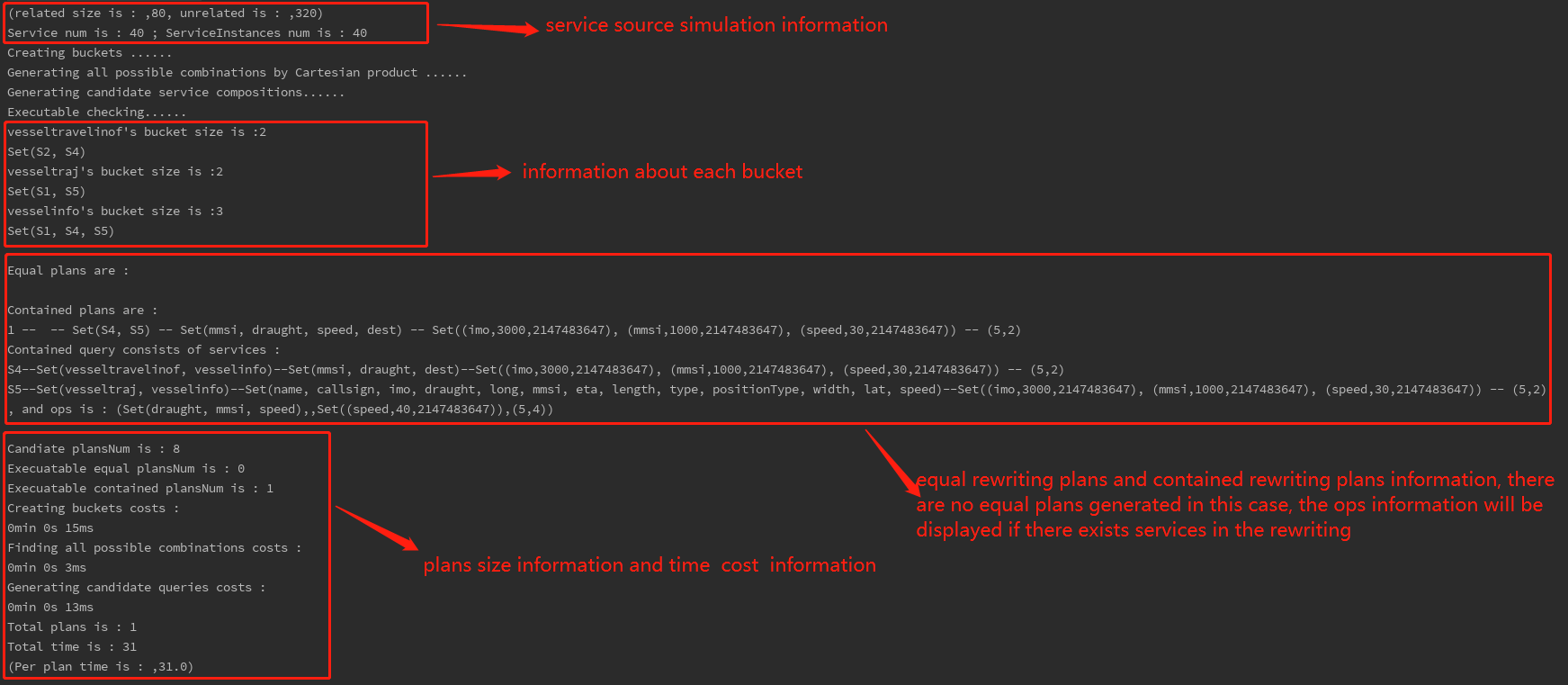
On the above use case we expose the services and service instances by hand, if we are going to measure the service composition performance, we should using the simulated services and service instances:
- In
DataUtil.scala, create a atomic service collectionsimulSourcewhich is used to simulate the service source:
val simulSource:Array[QueryService] = Array[QueryService](Movie,Revenues,Director,vesseltraj,vesseltravelinfo,vesselinfo)- Simulate the service source by giving such parameters:
relationcollection,query,servicesourcesize. For example:
val simulServices:List[QueryService] = SourceSImulation.geneViews(DataUtil.simulSource,query,1000)Besides the SBucket algorithm used in the above, you can choose SMinicon algorithm which is more efficient by replacing the SBucket.scala with SMinicon.scala in Step 4, the result display will be a little different from SBucket:
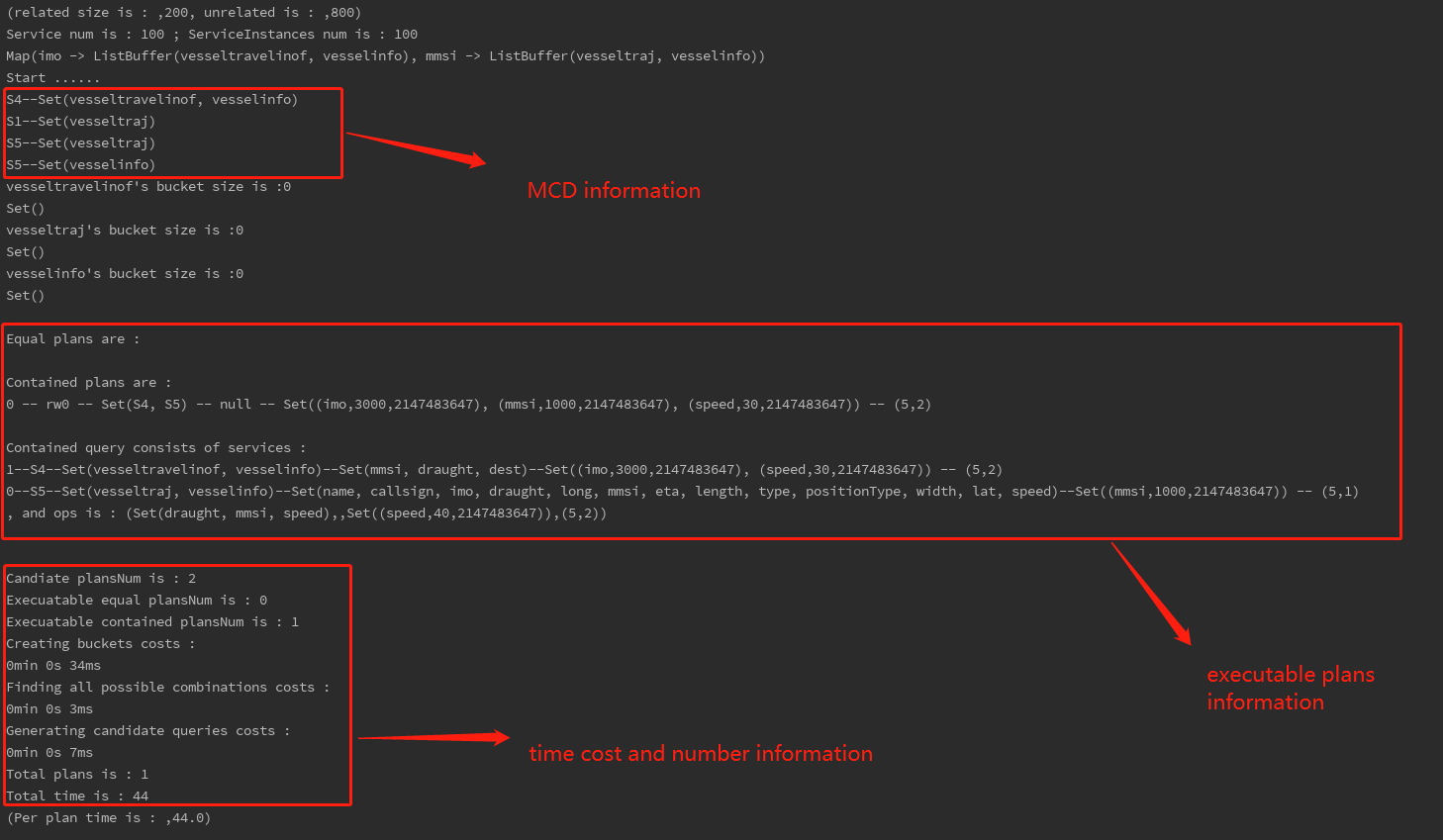 Note that the bucket elements are invalid, while adding the SMCD information on console.
Note that the bucket elements are invalid, while adding the SMCD information on console.
In addition, if we wanna to use the simulated sevice source, we need to assign the Datautil.simulServices to the variable services in Step 4:
val services = DataUtil.simulServices.toSet