This repository is for NMR simulation and education about the NMR field. Any thing here is free to use under the MIT License.

NMR spectroscopy is a non-destructive method for material identification. The current state-of-the-art machines are expensive and in high demand. Therefor, NMR Data is difficult to come by. This repository creates and and used fake NMR data to exemplify how NMR machines are used.
The first NMR machines used a continuous wave to bring protons (H atoms) in and out of resonance. This technology is called Continuous Wave Nuclear Magnetic Resonanse (CW-NMR). There are three main components discussed below: Signal Generation, Data Processing, and Pattern Recognition.
CW-NMR can only "see" part of the the resonance spectrum at any given iteration. The device must be iterated through a sweep of resonance ranges to produce a spectrum. The following gif shows a full sweep through the full range of high frequency.

A single iteration is seen below:



Several samples are needed in a single iteration to reduce the signal noise. The valid ranges are where the rate of the low frequncy signal is:
- Essentially flat - where the signal is linear
- Increasing - resonance peaks occur at diferent points according to increasing or decreasing magnetic field
The data processing step is broken down into 2 substeps: merge iteration and iteration combination.
Merge iteration merges all of the data from a single iteration to reduce noise from the data colection. The data was slices and saved as a single stream. This stream is resliced, and then the values averaged to smooth out errors.

Iteration combination recieves the merged iterations and adds them to the spectrum. The spectrum is initialized empty and value are added in a weighted manner, to reduce signal noise. This process creates the full spectrum of NMR data and is visualized below:

With the ability to create a full spectrum, the next task will be to reduce the data further and identify the material being sampled. This is done through a deep learning model in the next step.
Pattern recognition means developing a mathematical model that estimates the 1200 datapoints into a single material. This mathematical model is developed using machine learning. THe process of selecting an algorithm or architecture means looking at the data. This is seq2seq (sequence to sequence) problem that is further classified as a many-to-one. This means that many data points (an NMR spectrum) are translated into one data point (material classification.
The common approach to any ML problem is to pick an ML baseline from scikit-learn and then try to beat that baseline with a deep learning architecture. Scikit-learn provides a great tool for selecting an ML algorithm seen below:
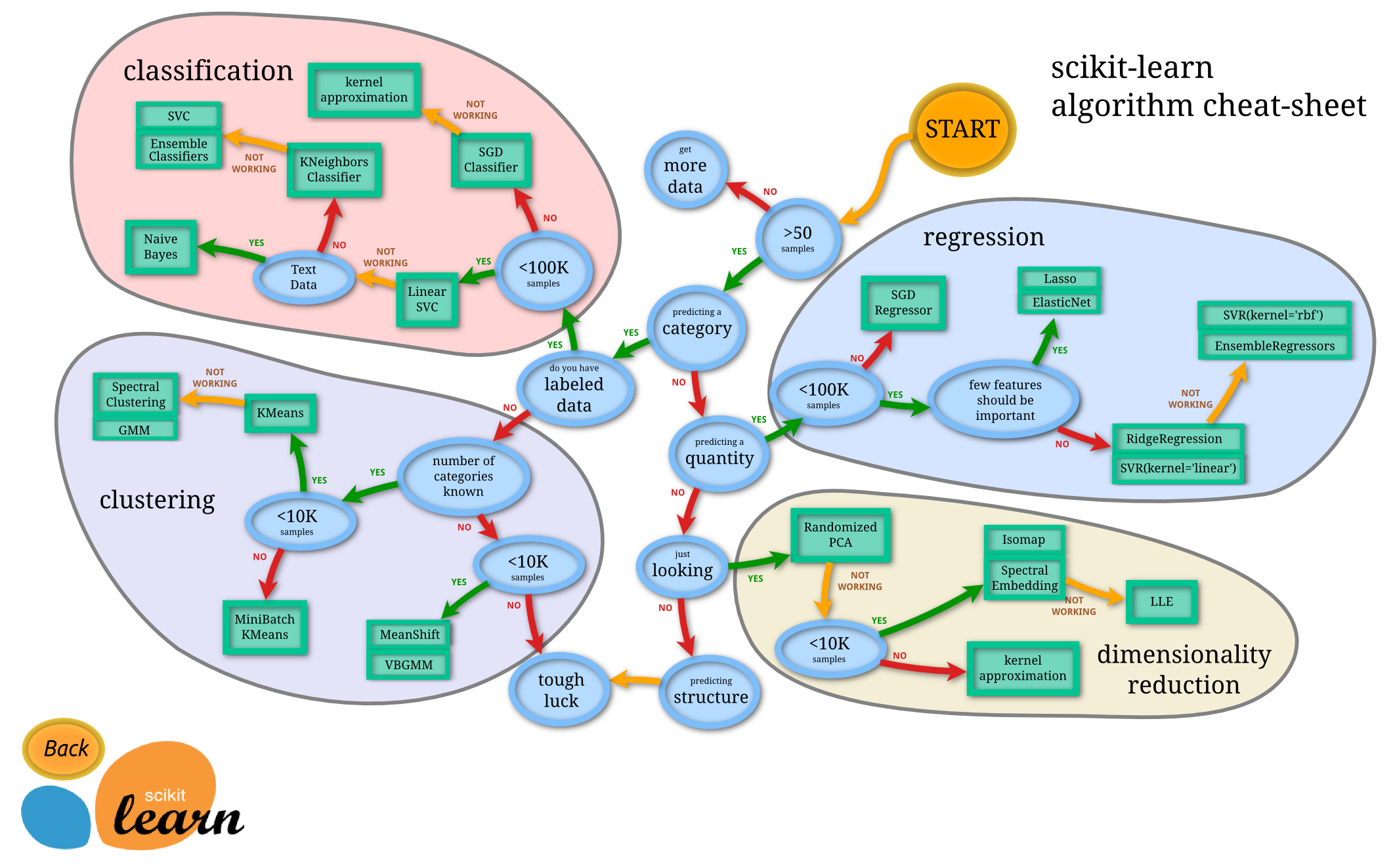
For this problem, a Linear Support Vector Classification (SVC) function was implemented. It had a 100% classification rate for the 2000 test samples. So it is pretty unneccesary to create a Neural Network for the data as it exists now (remember that this is idealized data, and there are other missing phenomenon).
A dense neural network is the obvious first choice for a deep leanring model. For sequential data classification Recurrent Neural Networks (RNNs), and Long-Short Term Memory (LSTMs) are appropriate choices, however they are very large and not needed in this application.
The neural network proived 100% classification as well. While it is ~10x slower than the Linear SVC, it provides regression data for all 5 materials. The Linear SVC returns a single number. The NN returns 5 numbers, confidences in each material positionally encoded to match the material. Below is an example of material classification:

The application, written with python/tkinter, combines all of the functions above to show how a CW-NMR device works.

Coming Soon...