Calisphere harvester 2.0: Rikolti is the name for a collection of components designed to work together to aggregate metadata records from Calisphere's contributing institutions (Metadata Fetcher), normalize the metadata to a standard schema (Metadata Mapper), augment with supporting content files (Content Fetcher), and index for searching (Indexer).
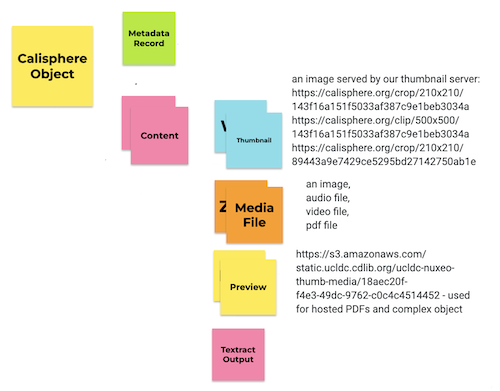
A Calisphere object is generally composed of metadata (sometimes called the metadata record) and content. Metadata is, explicitly, the metadata record fetched from the source institution and then mapped to the UCLDC schema. Content comes in several flavors depending on the type of object (text, audio, video, image, etc) and Calisphere's relationship to the contributing institution - we differentiate between harvesting from our own CDL-hosted Nuxeo digital asset management system (hosted objects) and harvesting from external systems (harvested objects). Content almost always includes a thumbnail - exceptions include audio objects harvested from external systems. Content can also include a media file if the object is hosted in the Nuxeo digital asset management system. Content can further include a preview if the object is hosted in Nuxeo and is a pdf, or if the object is hosted in Nuxeo and is part of a complex object. This structure is recursive: in the case of hosted complex objects, content may also include an ordered list of objects. This structure will likely also evolve to include additional pieces of data, for example, content may, in the future, include textract output of PDF media file analysis.
Each folder in this repository corresponds to a separate component of the Rikolti data pipeline. As of this writing on November 14th, 2022, metadata_fetcher and metadata_mapper are the most developed, while the others are left over from an earlier prototype.
Clone the repository. This documentation assumes you've cloned into ~/Projects/.
cd ~/Projects/
git clone [email protected]:ucldc/rikolti.gitSet up a python environment using python version 3.9. I'm working on a mac with a bash shell. I use pyenv to manage python versions and I use python3 venv to manage a python virtual environment located in ~/.venv/rikolti/. The following commands are meant to serve as a guide - please check the installation instructions for pyenv for your own environment.
# install pyenv
brew update
brew install pyenv
echo 'eval "$(pyenv init -)"' >> ~/.bash_profile
source ~/.bash_profile
# install python3.9 and set it as the local version
pyenv install 3.9
cd ~/Projects/rikolti/
pyenv local 3.9
python --version
# > Python 3.9.15
# create python virtual environment
python -m venv ~/.venv/rikolti/
source ~/.venv/rikolti/bin/activate
# install dependencies
cd metadata_fetcher/
pip install -r requirements.txt
cd ../metadata_mapper/
pip install -r requirements.txtCurrently, I only use one virtual environment, even though each folder located at the root of this repository represents an isolated component. If dependency conflicts are encountered, I'll wind up creating separate environments.
Note: We tried using sam local to develop the app locally and found that the overhead makes for a clunky and slow process that doesn't offer advantages over the local virtualenv development setup described above. We are using AWS SAM to build and deploy the lambda applications, however (see below).
After cloning the repo, run script/up to build and start the container. The
container will continue running until stopped. As most development tasks take place in
the Python console, there are two commands for starting the console in the
metadata_fetcher and metadata_mapper modules. They are:
bin/map - starts the console from within the mapper module
bin/fetch - starts the console from within the fetcher module
These commands install pip requirements and start an ipython console session.
The autoreload ipython extension is automatically loaded. Typing
autoreload or, just r in the console with reload all loaded modules.
To run other commands in the container, run docker compose exec from the
project root:
docker compose exec python ls -al
The Rikolti Wiki contains lots of helpful technical information. The GitHub Issues tool tracks Rikolti development tasks. We organize issues using the GitHub project board Rikolti MVP to separate work out into Milestones and Sprints.
All work should be represented by an issue or set of issues. Please create an issue if one does not exist. In order for our project management processes to function smoothly, when creating a new issue, please be sure to include any relevant Assignees, Projects ("Rikolti MVP"), Milestones, and Sprints.
We use development branches with descriptive names when working on a particular issue or set of issues. Including issue numbers or exact issue names is not necessary. Please use a distinct branch for a distinct piece of work. For example, there should be one development branch for a fetcher, and a different development branch for a mapper - even if the work for the mapper is dependent on the fetcher (you may create a mapper branch with the fetcher branch as the basis).
When starting work on a given issue, please indicate the date started. If more information is needed to start work on an issue, please @ CDL staff.
When finishing work on a given issue:
- Create a pull request to the main branch for a code owner to review. Be sure to link the pull request to the issue or set of issues it addresses, and add any relevant Projects ("Rikolti MVP"), Milestones, and Sprints.
- Indicate on the issue the date delivered, and move the issue to the "Ready for Review" state.
We use PR reviews to approve or reject, comment on, and request further iteration. It's the contributor's responsibility to keep their development branches up-to-date with main (or any other designated upstream branches).
- PEP 8 (enforced using flake8)
- DRY
- Readability & Transparency: Code as language
- Favor explicitness over defensiveness
We are using AWS SAM to build the rikolti lambda applications and deploy to AWS. Following are proposed steps for building and deploying using SAM:
Make sure you have SAM CLI installed.
From the rikolti directory, which contains template.yaml, build the serverless applications:
sam build --use-container
Using the --user-container option has SAM compile dependencies for each lambda function in a lambda-like docker container. This is necessary for compiling libraries such as lxml, which need to be natively compiled. The runtime and system architecture are defined for each lambda in the template.yaml file.
NOTE There is a troposphere script stub named
create_sam_template.pychecked into the repo. This script generatestemplate.yaml, but we decided not to use it for now since the template is simple and we don't need to introduce another layer of tooling at this point. We might use it in the future to generate templates for different environments and such.
Once built, deploy to AWS:
Make sure AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY and AWS_SESSION_TOKEN env vars are set. Then, the first time you deploy:
sam deploy --guided
Follow the prompts. Say yes to save arguments to a samconfig.toml configuration file. Then on subsequent deploys you can just type:
sam deploy