scrapes text from YouTube live chat and finds the most relavent msgs from them
So, The other day I was watching a live stream and chat was zooming past my screen so much I could not see what anyone was saying, I wondered how hard it is for streamers to reply to any of that ginormous spam, So it came to me that if there was a way to take these loads of sentences and get the most important/relevant ones from them it would be great so I started researching how to do it,
Using python and selenium and a bit of tinkering around on the YouTube webpage I made a scraping app that can get the most recent texts from the chat, the second part is where I found trouble, I approached this using Facebook Bart to summarize it but what it tries to do is give the overall meaning of the chat sequences and was also very slow for these reasons it wasn’t very successful when I started wandering around I found the TextRank algorithm made by Rada Mihalcea and Paul Tarau
This is a graph-based ranking algorithm. Graph-based ranking algorithm is essentially a way of deciding the importance of a vertex within a graph vertex in this context being a sentence or a word, this works like a voting system as in one connection to a vertex a from another vertex b is counted as a vote from vertex b using this voting we need to find out vertices with most votes and they are our answer
let G = (V, E) represents a weighted directed graph with a set of vertices V and a set of Edges E and Weights W
let In(Vi) represent all incoming edges and Out(Vi) represent all outgoing edges
The score of a particular vertex is defined by :
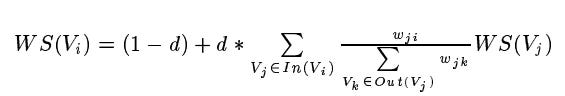
where, Wij refers to the weight of the edge from I to j, and we set these weights based on the inputs given and their connection strengths and d the damping factor, which can be set between 0 and 1, is usually set to 0.85
So now the task at hand is when given a list of sentences or words we need to find how closely they are related to other sentences and make a weighted graph using which we calculate the score of each vertex
for sentences, This relation is given by a similarity metric, where it’s measured as a function of their content overlap, The overlap of two sentences can be determined simply as the number of common tokens between the lexical representations of the two sentences
Here is the colab for the algorithm mentioned, or check out textrank.py implementation for the problem
https://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf
https://colab.research.google.com/drive/1Mk1WxKF0DaH0sGlfXJHDtNA7zYE8sKTx?usp=sharing