Architecture
This page outlines the general architecture and design principles of CHES and is mainly intended for a technical audience, and for people who want to have a better understanding of how the system works.
The Common Hosted Email Service is designed from the ground up to be a cloud-native containerized microservice. It is intended to be operated within a Kubernetes/OpenShift container ecosystem, where it can dynamically scale based on incoming load and demand. The following diagram provides a general overview of how the three main components relate to one another, and how network traffic generally flows between the components.
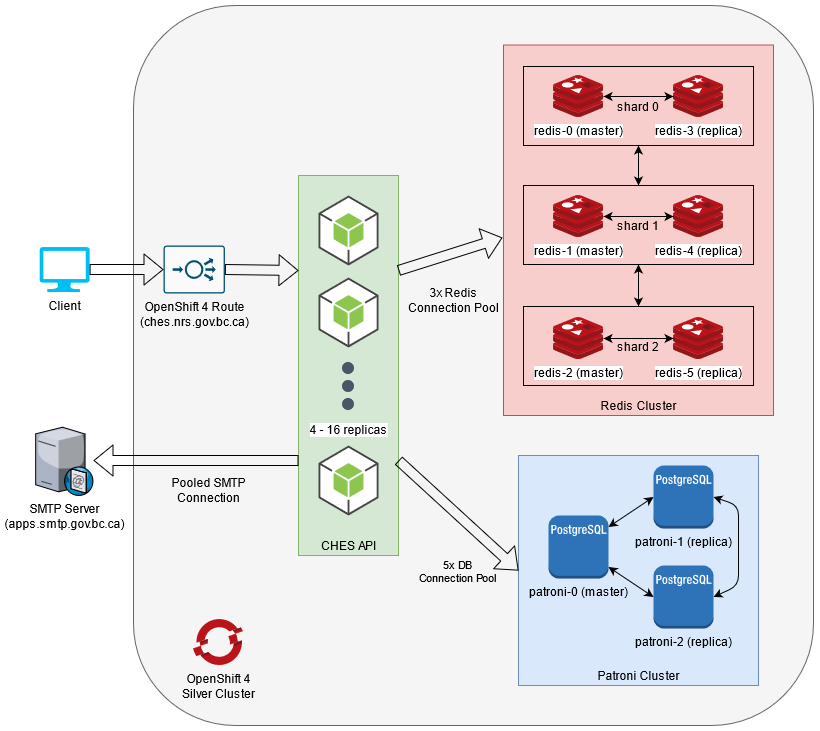
Figure 1 - The general infrastructure and network topology of CHES
The CHES API, Redis and Database are all designed to be highly available within the OpenShift environment. Redis achieves high availability by leveraging Redis Cluster, while the Database achieves high availability by leveraging Patroni. CHES is designed to be a scalable and atomic microservice. On the OCP4 platform, depending on the incoming email request volume and the queue, there can be between 4 to 16 running replicas of the CHES microservice. This allows the service to reliably handle a large variety of request volumes and scale resources accordingly.
In general, all network traffic follows the standard OpenShift Route to Service pattern. When a client connects to the CHES API, they will be going through OpenShifts router and load balancer, which will then forward that connection to one of the CHES API pod replicas. Depending on the request, that pod will connect to Redis, the external SMTP server and the Database to fulfill the request. Figure 1 represents the general network traffic direction through the use of the outlined fat arrows, and the direction of those arrows represents which component is initializing the TCP/IP connection.
Since this service may potentially have a huge volume of messages that need to be handled, these network connections are all designed to be pooled. This allows the service to avoid the overhead of the TCP/IP 3-way handshake that has to be done on every new connection and instead be able to leverage already existing connections to pipeline traffic and improve general efficiency. We pool connections from CHES to Redis, Patroni, and the SMTP server within our architecture. The OpenShift 4 Route and load balancer follows the general default scheduling behavior as defined by Kubernetes.
In order to reliably track the status of email messages as they flow through CHES, we store that information in the Postgres database. The following diagram illustrates the general database schema tha we use in the system.
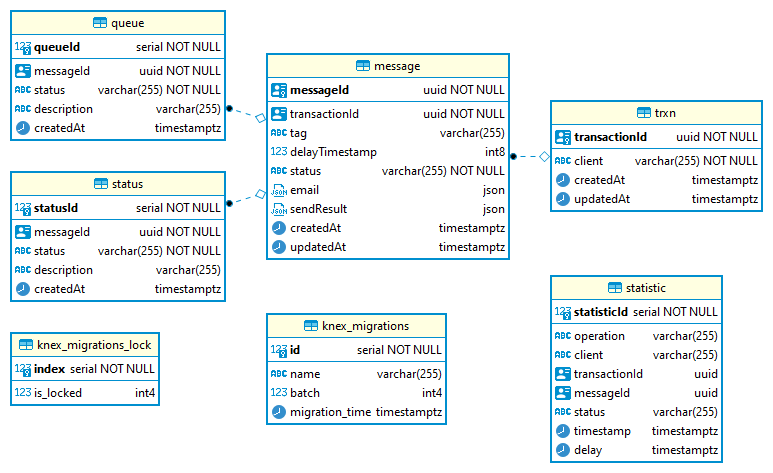
Figure 2 - The current Entity Relational Diagram of the CHES DB
The database schema is relatively straight forwards as most of it focuses on tracking and event logging. Each interaction with CHES will be assigned a unique transactionId or shorthand txId and written into the trxn table. Every transaction can have one or more uniquely associated messageId or shorthand msgId. Each message id represents a unique email message in the system, and the message table contains all the directly relevant information representing that message.
The queue table is an append-only table which focuses on only recording when a message has changed states within the system, and for what reason. The queue state flow will be discussed in further detail on the message queue state machine section. The status table is also an append-only table which focuses on only recording when a message has changed states within the system, and for what reason. However, unlike the queue table, the message table is much less technical and instead focuses on the more general statuses as explained in the Message Statuses page.
The statistic table was formerly used to log what kind of incoming API operation was taking place, and acted as a denormalized replica of the message, trxn and status tables. However, we have recently deprecated this table from operations due to the unnecessary amount of strain double-writing transactions to the database became for each message. Since all of the data found in the statistic table can be easily reconstructed from all the other tables, we have removed this redundancy from our codebase. A future pending migration will be formally deleting that table from our DB schema.
Both the txId and msgId are uniquely generated UUIDv4 identifiers created by the CHES API, whereas the statusId and queueId are serially generated numbers from the database. We use UUIDs for the transaction and message ids because we want to ensure that messages are evenly distributed within the UUIDv4 space and avoid leaking potential information that can come as a result of using a serially incrementing index number. Statuses and queue indices are never exposed in the API which is why we are able to use serial 32 bit incrementing integers instead.
One of the benefits of using a serial primary key instead of a UUID is that the database is able to create and maintain more efficient indecies, while taking up less disk space as well. However, this is only viable as long as there are only less than 2.1 billion records. Any more than that and the index would need to be converted to BIGINT. Since we require a degree of randomity and anonymity in the transaction and message ids, we are forced to use random UUIDs instead, which do take up more disk space and are less easy to index.
All email messages that flow through the CHES service will go through the following internal queue states. While these states are not directly visible through the /status endpoint, they will in most cases match and map to the statuses presented from that endpoint, albeit in less resolution and detail. The colored statuses should be somewhat analogous to what can be found from querying the status endpoint. The following diagram represents the entire state machine flow of what can happen to a message in CHES:
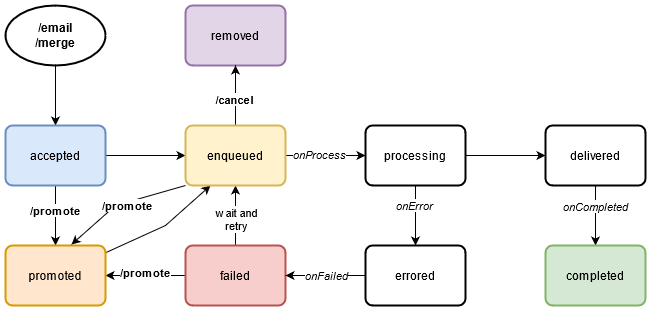
Figure 3 - The internal queue states and valid transitions a message can have
-
accepted- The message has been recognized by CHES and written to the database -
enqueued- The message has been added to the Redis Bull queue -
processing- The message queue has begun processing this message -
delivered- The message has received a valid response from the SMTP server -
completed- The message has been dispatched to the SMTP server successfully and cleaned up -
cancelled- The message has been cancelled by the client and cleaned up -
errored- The message encountered an issue while processing -
failed- The message failed to dispatch to the SMTP server for some reason -
promoted- The message has been promoted by the client and should begin processing momentarily
After you issue an /email or /merge request and get an HTTP 201 Accepted, the message will enter accepted state, and will eventually move through the other states automatically. The only exception is the promoted queue state, which only happens when a client calls the /promote endpoint in one of the other valid states that is promotable.
Unlike the message status states, the message queue states represents every notable transition that can occur within the Redis Bull queue implementation. We track each transition event to the database as a transaction for operational reasons - mainly to trace and debug the general flow of messages and to understand what happened when.
While CHES itself is a relatively small and compact microservice with a very focused approach to handling and queueing messages, not all design choices are self-evident just from inspecting the codebase. The following section will cover some of the main reasons why the code was designed the way it is.
We introduced network pooling for both Redis, Patroni and SMTP connections because we noticed that as our volume of email messages started going up, creating and destroying network connections for each transaction was extremely time consuming and costly. While low volumes of messages are capable of operating without any apparently delay to the user, we started encountering issues scaling up and improving total message flow within CHES.
By reusing connections whenever possible, we were able to avoid the TCP/IP 3-way handshake that has to be done on every new connection and instead be able to leverage already existing connections to pipeline traffic and improve general efficiency. While this doesn't seem significant, in our testing, when we switched to pooling, we observed up to an almost 3x performance increase in total message volume flow.
Early versions of CHES were originally designed to be synchronous and not event-driven, which made things easier to trace and debug. However, we quickly needed to witch to an asynchronous event-driven model because there was no other way to reliably ensure we were efficiently using up all of the available cycles within the Node.js event-loop, and to maximize the number of emails we could handle at any given moment.
Another key note when we were looking at rapidly scaling CHES' capabilities to handle larger volumes of traffic was that the synchronous design was actually blocking and starving the Node.js event-loop. Given enough requests per second, our endpoint would start to fall behind and then time out connections because it was taking too long for Express to respond to the incoming connection. Any kind of blocking operation would grind the event loop to a halt, and causes the application to be unable to respond to incoming network requests. In large volume cases, we started getting network timeouts, which is highly undesirable behavior.
As CHES needs to be highly performant, many of the operations are now asynchronous by design and decoupled from the API calls. Messages will deterministically flow through the queue states as soon as they are able to within the Redis Bull queue. Most of the heavy lifting in CHES is designed to be event-driven. As such, logging the transitions between the queue states is essential because it allows us to track which asynchronous events happened at what time. By ensuring that each API endpoint will only do the minimum required before responding to the connection request, we can significantly increase network request volume without compromising the heavy lifting tasks when there are idle cycles available.
In order to make sure our application can horizontally scale (run many copies of itself), we had to ensure that all processes in the application are self-contained and atomic. Since we do not have any guarantees of which pod instance would be handling what task at any specific moment, the only thing we can do is to ensure that every unit of work is clearly defined and atomic so that we can prevent situations where there is deadlock, or double executions.
While implementing Horizontal Autoscaling is relatively simple by using a Horizontal Pod Autoscaler construct in OpenShift, we can only take advange of it if the application is able to handle the different type of lifecycles. Based on usage metrics such as CPU and memory load, the HPA can increase or decrease the number of replicas on the platform in order to meet the demand.
We found that in our testing, we were able to reliably scale up to around 17 pods before we began to crash out our Patroni database. While we haven't been able to reliably isolate the cause of this, we suspect that the underlying Postgres database can only handle up to 100 concurrent connections (and is thus ignoring Patroni's max connection limit of 500) or that the database containers are simply running out of memory before being able to handle more connections. As such, this is why we decided to cap our HPA to a maximum of 16 pods at this time.
Our current limiting factor for scaling higher is the ability for our database to support more connections for some reason or another. We have observed that Redis has not exhibited any constraints, so if in the event we need to scale way beyond 16 replicas in the future, we may need to consider options where we either improve the database, or drop the database alltogether and rely solely on Redis.