A Node Red node for speech-to-text using Mozilla DeepSpeech.
!!!!!!! THIS IS AN EXPERIMENTAL NODE !!!!!!
A few (simple!) steps are required to install DeepSpeech:
- Run the following npm command in your Node-RED user directory (typically ~/.node-red):
Remark: This command will also install automatically Tensorflow, the deep learning library from Google.
npm install bartbutenaers/node-red-contrib-deepspeech - Create a models subfolder in the node-red-contrib-deepspeech folder.
- Download the pre-trained English model, and uncompress it to that /models subfolder:
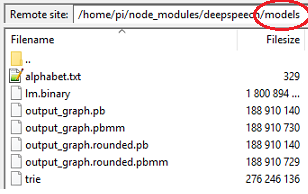
- The SOX library (to exchange audio formats) should be installed manually:
sudo apt-get install sox libsox-fmt-all
DeepSpeech is an open source Speech-To-Text (STT) engine by Mozilla. The model that is being used, is trained by machine learning techniques. To enlarge their training set in multiple languages, a website has been setup where everybody can help training the system. So please be my guest ...
A major advantage of Deepspeech is the ability to run it locally, in use cases where a cloud service (like Google, Amazon, ...) is not possible or desirable. A major disadvantage of running it local, is the need for lots of system resources. This will become clear in the test below.
Mozilla offers a CLI client.js file to test their library on NodeJS. This node is a similar test in Node-RED, which means their 2830-3980-0043.wav file is analysed:

[{"id":"e5ba519.146ecb","type":"deep-speech","z":"7f8aff01.07b4","name":"","x":710,"y":400,"wires":[["cc8720f6.68245"]]},{"id":"cc8720f6.68245","type":"debug","z":"7f8aff01.07b4","name":"Text from speech","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"payload","x":910,"y":400,"wires":[]},{"id":"2c5a9f46.43c74","type":"file in","z":"7f8aff01.07b4","name":"2830-3980-0043.wav","filename":"/home/pi/.node-red/node_modules/node-red-contrib-deepspeech/audio/2830-3980-0043.wav","format":"","chunk":false,"sendError":false,"x":500,"y":400,"wires":[["e5ba519.146ecb"]]},{"id":"3c223fc8.da189","type":"inject","z":"7f8aff01.07b4","name":"","topic":"","payload":"","payloadType":"date","repeat":"","crontab":"","once":false,"onceDelay":0.1,"x":290,"y":400,"wires":[["2c5a9f46.43c74"]]}]
And the text will correspond exactly to voice signal:
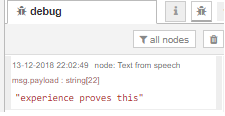
It would be better to have a larger audio sample to test, however I only wanted to have an indication of the speed via Node-RED. These are the results on a Raspberry Pi Model 3:
TensorFlow: v1.11.0-9-g97d851f
DeepSpeech: v0.3.0-0-gef6b5bd
Loaded model in 0.009705s.
Inference took 50.17s for 1.975s audio file.
Analysing 50.17 seconds on an audio sample of only 1.975 seconds is far from real-time. However all calculations are being done on CPU, while a neural network should be executed at least on a GPU. So more tests will be required on other platforms...
Some remarks:
- Currently every audio sample will start a new analysis, even when the previous analysis has not finished yet.
- Currently the SOX library will convert the audio sample to the required format. Perhaps this should be put in a separate node...
- The 2830-3980-0043.wav file has been downloaded from Mozilla's releases page.
- The installation procedure could be simplified, by adding the training data to this repository (so it would be installed automatically). However it is quite large, and for other languages extra files are needed.
From the Deepspeech releases page, it seems following hardware is currently supported:
- OS X 10.10, 10.11, 10.12, 10.13 and 10.14
- Linux x86 64 bit with a modern CPU (Needs at least AVX/FMA)
- Linux x86 64 bit with a modern CPU + NVIDIA GPU (Compute Capability at least 3.0, see NVIDIA docs)
- Raspbian Stretch on Raspberry Pi 3
- ARM64 built against Debian/ARMbian Stretch and tested on LePotato boards
However from the above test, we can conclude the Raspberry Pi 3 is not powerful to support real-time SST conversion. And the systems with NVIDIA GPU are a quite expensive for lots of hobbyist Node-RED users. There exist some other dedicated affordable hardware, however that hardware is not supported by Deepspeech at the moment. Some examples:
- Intel Movidius neural network USB stick: see issue.
- RockPro-64-AI board with artificial-intelligence processor: see issue.
As soon as Deepspeech can be executed real-time with less system resources, I will continue development on this Node-RED node...
Questions about this node can be asked on the Node-RED forum, in this discussion.