Design Doc: Using Scanline as Intermediate Data for Image Rewriting
Huibao Lin, 2013-05-20
Currently we are using compressed image formats, namely GIF, PNG, JPEG, and WebP for the input and output data. Because the I/O image is compressed, in each of the processing stages we have to decompress the image first, process it, and then compress again. We have to repeat this procedure again and again when there is cascade of processings. The use of compressed data as I/O is causing many problems which will be elaborated in the next section. This design aims at using the uncompressed data, i.e., scanlines, for the I/O.
Please note that neither the idea of scanline nor its implementation is new in this design. We already have ScanlineReaderInterface, ScanlineWriterInterface, JpegScanlineWriter, and WebpScanlineWriter in Pagespeed Insights. The goal of this design is to finish the implementation of scanline interface and actually use it in PSOL.
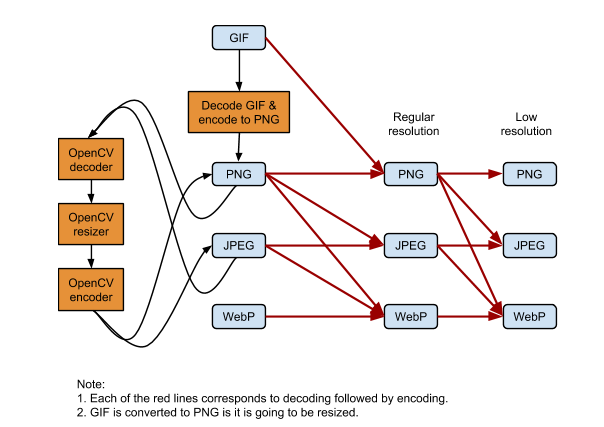
The above diagram shows the current design. Please note that each of the red lines corresponds to an image decompression followed by an image compression. In many cases, we are decompressing and compressing an image multiple times. In the worst case, to resize and compress a GIF image to low resolution, we have to repeat decompression and compression 4 times!
Problems of the current design include
- Waste of computation and loss of image quality because we decompress and compress an image multiple times.
- Duplication of code because multiple conversion processes involve the same image reader / writer. We are sharing code in some cases, but not always.
- Difficult to add new features. To support a new image format, we will have to add conversion from it to all other formats. Similarly, to add a new image processing technique, we will have to add it for all formats.
- Incomplete support for WebP. We cannot resize WebP images and cannot convert it to other formats, even if the browser doesn’t support WebP. This is fine now, but as WebP grows, we will need such features.
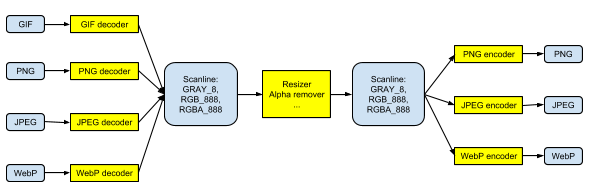
We decode the image at the beginning of the workflow, then apply image processing on the uncompressed data until all processings are done, finally we compress the image at the end of workflow.
We chose scanline, which is a row of pixels, for the uncompressed image. Scanline is the smallest possible unit in image compression and has the least memory footprint. For a scanline, we are currently supporting GRAY_8, RGB_888, and RGBA_8888. We will need to add GRAYA_88 to support grayscale with alpha channel.
We will need 4 image decoders and 3 image encoders for the images we’re currently supporting. If we want to support a new image format in the future, we just need to add another decoder and another encoder.
The new design will have lots of advantage compared to the old one:
- Save of computation. Each image will only be decompressed and compressed once.
- Save of memory. In the old design, we decompress the whole image before any processing or compression, so we needed the buffer for the entire image. In the new design, we just need to decompress a scanline or several scanlines unless the image is progressive. Memory is reducSince it supports a small subset of functionality, I wonder if it's aed from O(M*N) to O(M) where M and N are the number of columns and rows, respectively.
- Support transcoding between all image formats, and image resizing for all formats.
- Ease to add new image processing technique. Whatever new technique we add, it will automatically apply to all image formats.
- Ease to add new image format. To support a new format, we just need to add a decoder and a encoder. This is in contrast to the K conversion routines in the past, where K is the number of image formats.
- Ease for code maintenance. Each module has its unique functionalities and all decoders / encoders have the same API.