RepoManipulator
- About RepoManipulator
- Get RepoManipulator
-
Layers and Schemas
- Connectors: DIRECT Connectors to connect AC repositories using views
- Import Layer: CFG1 and CFG2
- IL1, IL2 - Integration Layer to integrate objects from Repo1 OR Repo2
- IL12 - Integration Layer to combine objects from Repo1 AND Repo2
- ILT12 - Integration Layer preparing Transformations: to prepare IL12
- Missing1, Missing2 - Rows, existing in one repository but missing in the second repository
- Filter1, Filter2 - predefined transformations to filter data by specific criteria and display only the columns necessary for the purpose
- Usage examples
- ToDo
AC (AnalyticsCreator) uses repositories which are databases.
Aims of RepoManipulator:
- denormalize AC object to simplify read and write access
- compare and merge the contents of different repositories
- to be extended...
RepoManipulator is maintained using AnalyticsCreator. It is a database and can connect to 2 AC repositories and simplify the manipulation of repositories.
- One way is to use AC and open the repository from the repo Skript RepoManipulator.sql, to create the dwh_RepoManipulator as master and to 'schema compare' from there to one or more target RepoManipulator databases. If you are using AC you should know, how to do.
You can easy change Connector properties in AC to connect to your own repositories. - use RepoManipulator database project and Visual Studio Schema compare.
Vou should care about the right connections to the right repositories by your own.
It would be possible to extend the Project to use variables. - use RepoManipulator.dacpac, which is included in the database project.
You should care about the right connections to the right repositories by your own.
Update Skripts could be used to change the code of the Views in schemas CFG1 and CFG2. Maybe these skripts will be included into the RepoManipulator Project if required.
Two "direct connectors" can connect with 2 different AC repositories.
Direct connectors are implemented as views. Repositories and the RepoManipulator needs to be on the same SQL Server instance. Linked servers are not supported.
Edit the connector to define source database, these should be AC repo databases. You can also connect both connectors to the same repo if you don't have several repos.
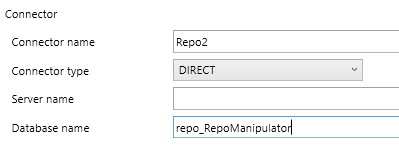
If you change the connection definition to another database, you need to refresh the sources to recreate the code for the views! Only to use "Synchronize" will NOT change the source code of the views.
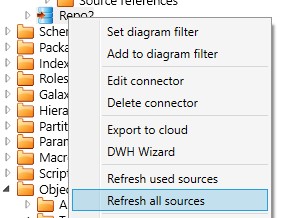
These 2 connectors Repo1 and Repo2 includes some but not all repository tables

Tables of the Repo1 are available as views in schema CFG1, tables of the Repo2 are available in schema CFG2. The logic in CFG2, IL2 etc. is always implemented analogous to CFG1, IL1 etc..
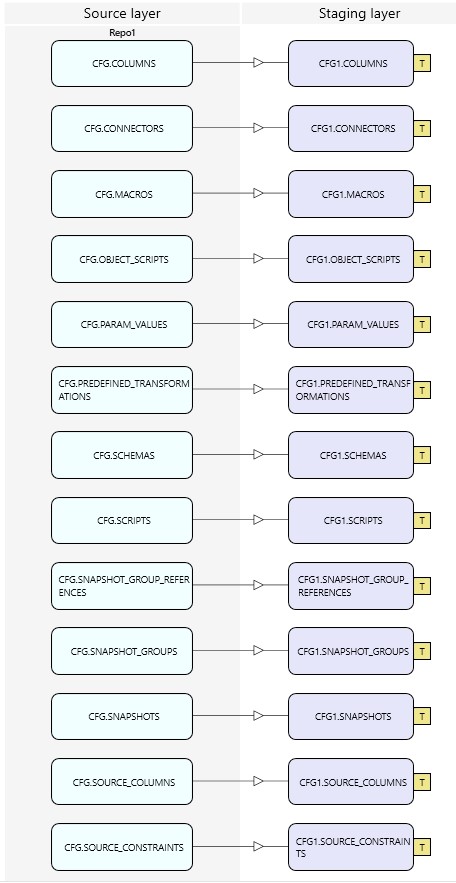
IL1 - Integration Layer to integrate Objects from Staging Layer Schema CFG1. IL2 does the same for CFG2.
Transformations:
-
Connector_Source
combination from CONNECTORS and SOURCES to get ConnectorName and Source_Name in one view
-
Connector_Source_Column
combination from CONNECTORS, SOURCES and SOURCE_COLUMNS to get ConnectorName, Source_Name and Columns_Name in one view
-
Schema_Table
it is implemented, but less usefull than Schema_Transformation -
Schema_Table_Column
it is implemented, but less usefull than Schema_Transformation_Column.
But is is required for tables which exists without transformations.
Also tables can contain optional calculated columns which are not available in their source transformation Schema_Transformation-
Schema_Transformation_Column

combination from several sources in one view- properties of source transformation columns
- properties of the transformation column itself
- properties of the target colum in the COLUMNS table for the related target table (each transformation has a related "table" which can be seen be clicking on the "T" in the small rectangle on the right of the transformation)
Some union transformations are required to combine object from Repo1 and Repo2
The best way is to use AC!
Best practice#ac-cloud-export-and-import
If we want to do this manuelly it is more complicated, and it is possible. But it is hard to insert missing objects in the right sequence.
- It is easy to detect and to insert simple object like connectors, sources, source colums, macros, packages, schemas, simple tables
- it is a little bit more complicated to insert missing tables, if these tables are "virtual tables" related to transformations
- it is harder to implement transformations with all their source tables (Transformation_Table), columns (Transformation_Columns) and JOIN References
Todo:
- implement a procedure with some object as parameter (a transformation?)
- the procedure should check all missing objects and import them from Repo1 into Repo2
most importand are marked bold:
- Column_References
- Columns
- Connectors
- Deployment_Packages
- Deployments
- DWH_Architecture_Objects
- Filter_Objects
- Filters
- Galaxies
- Groups
- Hierarchies
- Hierarchy_Columns
- Hist_Calc_Columns
- Hist_Column_References
- Hist_Table_References
- Imp_Column_References
- Imp_Table_References
- Index_Columns
- Indexes
- Makros
required in Columns, Transformation Columns, Transformations - Model_Dim_Columns
- Model_Dims
- Model_Fact_Dims
- Model_Fact_Measures
- Model_Facts
- Models
- Object_Groups
- Object_Skript_Params
- Object_Skripts
- Olap_Partitions
- Package_Dependencies
- Package_Skripts
- Package_Variables
- Packages
required in Transformations - Param_Values
- Predefined_Transformations
- Role_CubeDimensions
- Role_Cubes
- Role_Dimensions
- Roles
- Schemas
- Scripts
- Snapshot_Group_References
- Snapshot_Groups
- Snapshots
- Source_Colums
- Source_Constraints
- Source_Reference_Columns
- Source_References
- Sources
- Stars
- Table_Reference_Columns
- Table_References
- Tables
- Trans_Table_References
- Transformation_Columns
- Transformation_References
- Transformation_Rename_Columns
- Transformation_Snapshots
- Transformation_Standards
- Transformation_Stars
- Transformation_Tables
requird in Transformation Columns - Transformations
- Type_Custom
- Workflow_Package_References
The development will be stopped for now.
- target for
Connector_Source - Column
ConnectorIDis omitted in the view because it will be auto created when inserting intoCONECTORS
[ConnectorID] [int] IDENTITY(1,1) NOT NULL
example:
INSERT INTO CFG2.CONNECTORS
(
Code_Page
, Column_Delimiter
, Column_Names_First_Row
, ConnectionString
, ConnectorName
, ConnectorTypeID
, DatabaseName
, Format
, Header_Row_Delimiter
, Header_Rows_To_Skip
, Locale
, QuotedIdentifier
, Row_Delimiter
, ServerName
, Text_Qualifier
, Unicode
)
SELECT
Code_Page
, Column_Delimiter
, Column_Names_First_Row
, ConnectionString
, ConnectorName
, ConnectorTypeID
, DatabaseName
, Format
, Header_Row_Delimiter
, Header_Rows_To_Skip
, Locale
, QuotedIdentifier
, Row_Delimiter
, ServerName
, Text_Qualifier
, Unicode
FROM
Missing2.CONNECTORS AS CONNECTORS_1
WHERE ConnectorName = N'Partner';- target for
Connector_Source - required:
- existing Connector (
ConnectorName)
- existing Connector (
example:
INSERT INTO CFG2.SOURCES
(
ConnectorID
, Source_Name
, AnonStatement
, Description
, Directory
, FileSpec
, FriendlyName
, [Group]
, Hashkey
, IncludeSubDir
, Path
, ProcessDirectory
, Query
, SAP_DQ_AutoSync
, SAP_DQ_Extract
, SAP_DQ_LogSys
, SAP_DQ_Mode
, SAP_DQ_RFCDest
, SAP_DQ_RFCUrl
, SAP_DQ_Timestamp
, SAP_DQ_Transfer
, SAP_DQ_Type
, Source_Schema
, SourceTypeID
)
SELECT
ConnectorID
, Source_Name
, AnonStatement
, Description
, Directory
, FileSpec
, FriendlyName
, [Group]
, Hashkey
, IncludeSubDir
, Path
, ProcessDirectory
, Query
, SAP_DQ_AutoSync
, SAP_DQ_Extract
, SAP_DQ_LogSys
, SAP_DQ_Mode
, SAP_DQ_RFCDest
, SAP_DQ_RFCUrl
, SAP_DQ_Timestamp
, SAP_DQ_Transfer
, SAP_DQ_Type
, Source_Schema
, SourceTypeID
FROM
Missing2.SOURCES AS SOURCES_1
WHERE Source_Name LIKE 'view_part%'
-- z_ConnectorName is an additional colum which can be used to filter data
AND z_ConnectorName = 'Partner'- target for
Connector_Source_Colums - required:
- existing Source (
SourceID):
a source with the sameSource_NameandConnectorNamemust exist
=> first insert required Sources into CFGx.SOURCES
- existing Source (
example
INSERT INTO CFG2.SOURCE_COLUMNS
(
SourceID
, Column_Name
, Anonymize
, Character_Maximum_Length
, DelimitedColumnWidth
, Description
, FriendlyName
, Is_Nullable
, LongText
, MediumText
, Numeric_Precision
, Numeric_Scale
, OrderNr
, PK_Ordinal_Position
, SAP_DQ_Definition
, ShortText
, TextQualified
, TypeID
)
SELECT
SourceID
, Column_Name
, Anonymize
, Character_Maximum_Length
, DelimitedColumnWidth
, Description
, FriendlyName
, Is_Nullable
, LongText
, MediumText
, Numeric_Precision
, Numeric_Scale
, OrderNr
, PK_Ordinal_Position
, SAP_DQ_Definition
, ShortText
, TextQualified
, TypeID
FROM
Missing2.SOURCE_COLUMNS AS SOURCE_COLUMNS_1
--z_Source_Name is an additional colum which can be used to filter data
WHERE z_Source_Name LIKE 'view_part%';- target for
Schema
example:
INSERT INTO CFG2.SCHEMAS
(
Schema_Name
, DB
, Description
, Hashkey
, SchemaTypeID
, SeqNr
)
SELECT
Schema_Name
, DB
, Description
, Hashkey
, SchemaTypeID
, SeqNr
FROM
Missing2.SCHEMAS AS SCHEMAS_1
WHERE Schema_Name LIKE N'%partner%';Macros could be used in Tables, columns, Transformations, Transformation Columns
INSERT INTO CFG2.MACROS
(
MacroName
, Description
, Hashkey
, LanguageID
, Statement
, TableID
)
SELECT
MacroName
, Description
, Hashkey
, LanguageID
, Statement
, TableID
FROM
Missing2.MACROS AS MACROS_1
WHERE MacroName LIKE N'%blablabla%';- target for
Schema_Table - required:
- existing Schema (
SchemaID):
a schema with the sameSchema_Namemust exist
=> first insert required schemas into CFGx.SCHEMAS
- existing Schema (
- Tables contains a lot if ID Attributes as foreign keys, which needs to be generated correcty:
- SchemaID
- CFG.SCHEMAS.SchemaID
- HistOfTableID
- CFG.SOURCES.TableID
- HubOfTableID
- CFG.SOURCES.TableID
- LinkOfTableID
- CFG.TABLES.TableID
- PersistOfTableID
- CFG.TABLES.TableID
- SatOfTableID
- CFG.TABLES.TableID
- SchemaID
before you can use Missing2.TABLES for some specific tables, you need to check if all referenced tables exists which are required to create these tables.
example:
you want to create some missing tables in Schema STHPartner.
First you need to check if some referenced tables are missing.
And if they are missing you must create them before creating a dependent table
SELECT
SchemaID
, Table_Name
, Referenced_Schema_Name
, Referenced_Table_Name
, z_Schema_Name
FROM
Missing2.TABLES_required_ReferencedTable
WHERE z_Schema_Name = 'STHPartner'
AND Table_Name LIKE 'partnerVer%';My result set:
| SchemaID | Table_Name | Referenced_Schema_Name | Referenced_Table_Name | z_Schema_Name |
|---|---|---|---|---|
| 2 | PartnerVermittlervertragZugriff | STTPartner | PartnerVermittlervertragZugriff | STHPartner |
| 2 | PartnerVertragsrolleVertrag | STTPartner | PartnerVertragsrolleVertrag | STHPartner |
and I need to create these tables before I can create the target tables
example:
INSERT INTO CFG2.TABLES
(
SchemaID
, Table_Name
, AnonStatement
, CompressionTypeID
, Description
, DoNotExport
, FriendlyName
, Hashkey
, HistOfTableID
, HubOfTableID
, LinkOfTableID
, PersistOfTableID
, SatOfTableID
, TableTypeID
)
SELECT
SchemaID
, Table_Name
, AnonStatement
, CompressionTypeID
, Description
, DoNotExport
, FriendlyName
, Hashkey
, HistOfTableID
, HubOfTableID
, LinkOfTableID
, PersistOfTableID
, SatOfTableID
, TableTypeID
FROM
Missing2.TABLES AS TABLES_1
--z_Schema_Name is an additional colum which can be used to filter data
WHERE z_Schema_Name = 'STTPartner'
AND Table_Name LIKE 'partnerVer%';and in the next step I can create the target tables
...
FROM
Missing2.TABLES AS TABLES_1
--z_Schema_Name is an additional colum which can be used to filter data
WHERE z_Schema_Name = 'STHPartner'
AND Table_Name LIKE 'partnerVer%';![]()
the STT-tables are not shown.
If we sync the DWH, these STT-tables and even the STH history tables will be removed.
Maybe they have been removed because of missing colums? Lets add columns
...
the tables will be removed again.
our issue: these are not real tables, but these are target tables of transformations. And if the transformation doesn't exist, the tables will be removed.
Lets try to create real tables, for example import tables.
And the result is fine
![]()
We learned:
We can create real tables, but if we try to create virtual tables they could be deleted by AC.
We should create the associated transformations.
- target for
Schema_Table_Column - required:
- existing Table (
TableID):
a table with the sameSchema_NameandTable_Namemust exist
=> first insert required tables into CFGx.TABLES
- existing Table (
example:
INSERT INTO CFG2.COLUMNS
(
TableID
, Column_Name
, AggregateID
, Anonymize
, Character_Maximum_Length
, Collation
, [Default]
, Description
, FriendlyName
, IdentityIncrement
, IdentitySeed
, Is_Nullable
, IsCalculated
, IsIdentity
, IsPersisted
, Numeric_Precision
, Numeric_Scale
, PK_Ordinal_Position
, Statement
, ToOLAP
, TypeID
)
SELECT
TableID
, Column_Name
, AggregateID
, Anonymize
, Character_Maximum_Length
, Collation
, [Default]
, Description
, FriendlyName
, IdentityIncrement
, IdentitySeed
, Is_Nullable
, IsCalculated
, IsIdentity
, IsPersisted
, Numeric_Precision
, Numeric_Scale
, PK_Ordinal_Position
, Statement
, ToOLAP
, TypeID
FROM
Missing2.COLUMNS AS COLUMNS_1
--z_Schema_Name and z_Table_Name are additional colums which can be used to filter data
WHERE z_Schema_Name = N'STTPartner'
AND z_Table_Name LIKE 'partnerVer%';Packages are required to create new missing Transformations
example:
INSERT INTO CFG2.PACKAGES
(
PackageName
, Description
, DoNotRun
, Hashkey
, isHandmade
, PackageTypeID
)
SELECT
PackageName
, Description
, DoNotRun
, Hashkey
, isHandmade
, PackageTypeID
FROM
Missing2.PACKAGES AS PACKAGES_1
WHERE PackageName LIKE N'%partner%';- target for
Schema_Transformation - Transformations contains a lot if ID Attributes as foreign keys, which needs to be generated correcty:
- SchemaID
- CFG.SCHEMAS.SchemaID
- HubOfTableID
- CFG.SOURCES.TableID
- LinkOfTableID
- CFG.TABLES.TableID
- ModDimID
- CFG.MODEL_DIMS.ModDimID
- ModFactID
- CFG.MODEL_FACTS.ModFactID
- PersistPackageID
- CFG.PACKAGES.PackageID
- PersistTableID
- CFG.TABLES.TableID
not required
will be created later
- CFG.TABLES.TableID
- SatOfTableID
- CFG.TABLES.TableID
- SourceID
- CFG.SOURCES.SourceID
- TableID
- CFG.TABLES.TableID
not required
will be created later when the transformation will be compiled or created
- CFG.TABLES.TableID
- TransHistTypeID
- INTERN.TRANS_HIST_TYPES.TransHistTypeID
- TransTypeID
- INTERN.TRANSFORMATION_TYPES.TransTypeID
- should be equal in all repositories
- SchemaID
- required
- existing Schema
- existing Table
- existing Source
- exisitng Package
- existing Macros
- should be synchronized separately
- existing Model dim
- I don't use them in my projects, will be implemented only on request,
NULLwill be used
- I don't use them in my projects, will be implemented only on request,
- existing Model fact
- I don't use them in my projects, will be implemented only on request,
NULLwill be used
- I don't use them in my projects, will be implemented only on request,
Check TRANSFORMATIONS_required_ReferencedTable. Add required but missig tables.
SELECT
SchemaID
, Transformation_Name
, Referenced_Schema_Name
, Referenced_Table_Name
, z_Schema_Name
FROM
Missing2.TRANSFORMATIONS_required_ReferencedTable
WHERE z_Schema_Name = 'STTPartner'
AND Transformation_Name LIKE 'partnerVer%';Check TRANSFORMATIONS_required_Connector_Source. Add required but missing Sources.
SELECT
SchemaID
, Transformation_Name
, z_Source_ConnectorName
, z_Source_Source_Name
, z_Schema_Name
FROM
Missing2.TRANSFORMATIONS_required_Connector_Source
WHERE z_Schema_Name = 'STTPartner'
AND Transformation_Name LIKE 'partnerVer%';Check TRANSFORMATIONS_required_Package. Add required but missing Packages.
SELECT
SchemaID
, Transformation_Name
, PackageName
, z_Schema_Name
FROM
Missing2.TRANSFORMATIONS_required_Package
WHERE z_Schema_Name = 'STTPartner'
AND Transformation_Name LIKE 'partnerVer%';Also used Macros could be missing. Check them before or when you get a synchronization error later.
Insert missing transformations. Example:
INSERT INTO CFG2.TRANSFORMATIONS
(
SchemaID
, Transformation_Name
, CreateDummyEntry
, CreateResultTable
, Description
, Filter
, FriendlyName
, Hashkey
, [Having]
, HubOfTableID
, isCreated
, IsDistinct
, isFact
, LinkOfTableID
, ModDimID
, ModFactID
, PersistPackage_Name
, PersistPackageID
, PersistTable_Name
, PersistTableID
, SatOfTableID
, SourceID
, SpecialType
, TableID
, TransHistTypeID
, TransTypeID
, ViewDefinition
)
SELECT
SchemaID
, Transformation_Name
, CreateDummyEntry
, CreateResultTable
, Description
, Filter
, FriendlyName
, Hashkey
, [Having]
, HubOfTableID
, isCreated
, IsDistinct
, isFact
, LinkOfTableID
, ModDimID
, ModFactID
, PersistPackage_Name
, PersistPackageID
, PersistTable_Name
, PersistTableID
, SatOfTableID
, SourceID
, SpecialType
, TableID
, TransHistTypeID
, TransTypeID
, ViewDefinition
FROM
Missing2.TRANSFORMATIONS AS TRANSFORMATIONS_1
WHERE z_Schema_Name = 'STTPartner'
AND Transformation_Name LIKE 'partnerVer%';Synchronization of the inserted transformations should be fail, because columns are still missing. Only manual transformations could be fine.
A transformation has one ore more source tables, they are located in CFG.TRANSFORMATION_TABLES. Before adding transformation columns the transformation source tables are required
foreign keys
- TableID
- CFG.TABLES.TableID
- TransformationID
- CFG.TRNSFORMATIONS.TransformationID
Check TRANSFORMATION_TABLES_required_SourceTable
SELECT
SourceTable__Schema_Name
, SourceTable__Table_Name
, z_Transformation_Schema_Name
, z_Transformation_Transformation_Name
FROM
Missing2.TRANSFORMATION_TABLES_required_SourceTable
WHERE z_Transformation_Schema_Name = 'STTPartner'
AND z_Transformation_Transformation_Name LIKE 'partnerVer%';Or check TRANSFORMATION_TABLES_missing_SourceTable
SELECT
SourceTable_Schema_Name
, SourceTable_Table_Name
, z_Transformation_Schema_Name
, z_Transformation_Transformation_Name
FROM
Missing2.TRANSFORMATION_TABLES_missing_SourceTable
WHERE z_Transformation_Schema_Name = 'STTPartner'
AND z_Transformation_Transformation_Name LIKE 'partnerVer%';insert required Transformation Tables
INSERT INTO CFG2.TRANSFORMATION_TABLES
(
TransformationID
, SequenceNumber
, [Distinct]
, Filter_Statement
, ForceJoin
, IsOutput
, JoinHistTypeID
, JoinTypeID
, Reference_Statement
, Subselect
, TableAlias
, TableID
, UnionAll
)
SELECT
TransformationID
, SequenceNumber
, [Distinct]
, Filter_Statement
, ForceJoin
, IsOutput
, JoinHistTypeID
, JoinTypeID
, Reference_Statement
, Subselect
, TableAlias
, TableID
, UnionAll
FROM
Missing2.TRANSFORMATION_TABLES AS TRANSFORMATION_TABLES_1
--WHERE z_Transformation_Schema_Name = N'config'
WHERE z_Transformation_Schema_Name = 'STTPartner'
AND z_Transformation_Transformation_Name LIKE 'partnerVer%';foreign keys
- ColumnID
- CFG.COLUMNS.ColumnID
- transformation source table column (
COLUMNS)
- TransformationID
- CFG.TRANSFORMATIONS.TransformationID
- transformation (
TRANSFORMATIONS)
- TransTableID
- CFG.TRANSFORMATION_TABLES.TransTableID
- transformation source table (
TRANSFORMATION_TABLES)
Check TRANSFORMATION_COLUMNS_required_TransTable
SELECT
z_Transformation_Schema_Name
, z_Transformation_Transformation_Name
, z_TransTable_Schema_Name
, z_TransTable_Table_Name
FROM
Missing2.TRANSFORMATION_COLUMNS_required_TransTable
--WHERE z_Transformation_Schema_Name = N'config'
WHERE z_Transformation_Schema_Name = 'STTPartner'
AND z_Transformation_Transformation_Name LIKE 'partnerVer%';Check TRANSFORMATION_COLUMNS_missing_TransTable
SELECT
z_Transformation_Schema_Name
, z_Transformation_Transformation_Name
, z_TransTable_Schema_Name
, z_TransTable_Table_Name
FROM
Missing2.TRANSFORMATION_COLUMNS_missing_TransTable
--WHERE z_Transformation_Schema_Name = N'config'
WHERE z_Transformation_Schema_Name = 'STTPartner'
AND z_Transformation_Transformation_Name LIKE 'partnerVer%';if you want to create Transformation Columns for several Transformations, you can check TRANSFORMATION_COLUMNS_missing_transformation
SELECT
z_Transformation_Schema_Name
, z_Transformation_Transformation_Name
FROM
Missing2.TRANSFORMATION_COLUMNS_missing_transformation
--WHERE z_Transformation_Schema_Name = N'config'
WHERE z_Transformation_Schema_Name = 'STTPartner'
AND z_Transformation_Transformation_Name LIKE 'partnerVer%';Check TRANSFORMATION_COLUMNS_required_SourceColumn
SELECT
z_Transformation_Schema_Name
, z_Transformation_Transformation_Name
, z_TransTable_Schema_Name
, z_TransTable_Table_Name
, z_SourceColumn_Column_Name
FROM
Missing2.TRANSFORMATION_COLUMNS_required_SourceColumn
--WHERE z_Transformation_Schema_Name = N'config'
WHERE z_Transformation_Schema_Name = 'STTPartner'
AND z_Transformation_Transformation_Name LIKE 'partnerVer%';Check TRANSFORMATION_COLUMNS_missing_SourceColumn
SELECT
z_Transformation_Schema_Name
, z_Transformation_Transformation_Name
, z_TransTable_Schema_Name
, z_TransTable_Table_Name
, z_SourceColumn_Column_Name
FROM
Missing2.TRANSFORMATION_COLUMNS_missing_SourceColumn
--WHERE z_Transformation_Schema_Name = N'config'
WHERE z_Transformation_Schema_Name = 'STTPartner'
AND z_Transformation_Transformation_Name LIKE 'partnerVer%';If finaly all required objects are available, insert missing Transformation Columns
INSERT INTO CFG2.TRANSFORMATION_COLUMNS
(
TransformationID
, ColumnName
, TransTableID
, ColumnID
, DefaultValue
, Description
, FriendlyName
, IsAggregate
, PK_Ordinal_Position
, SequenceNumber
, Statement
)
SELECT
TransformationID
, ColumnName
, TransTableID
, ColumnID
, DefaultValue
, Description
, FriendlyName
, IsAggregate
, PK_Ordinal_Position
, SequenceNumber
, Statement
FROM
Missing2.TRANSFORMATION_COLUMNS AS TRANSFORMATION_COLUMNS_1
--WHERE z_Transformation_Schema_Name = N'config'
WHERE z_Transformation_Schema_Name = 'STTPartner'
AND z_Transformation_Transformation_Name LIKE 'partnerVer%';Filter1, Filter2 - predefined transformations to filter data by specific criteria and display only the columns necessary for the purpose
-
Schema_Transformation_Column__Diff_Anonymize
Compare Anonymize -
Schema_Transformation_Column__Diff_ColumnName_FriendlyName
Compare ColumnName with FriendlyName -
Schema_Transformation_Column__Diff_Description
Compare Description -
Schema_Transformation_Column__Diff_FriendlyName
Compare FriendlyName -
Schema_Transformation_Column__Diff_PK_Ordinal_Position
Compare PK_Ordinal_Position
You are working in a team. Some members are responsible for the technical conception, others for the implementation.
Use Repo1 for technical conception and Repo2 for the implementation.
For example data from a source system should be imported, but some information should be added (PK definition, alternative Names, Descriptions, ...)
a possible workflow:
- get the source definitions into AC
- merge source definitions between Repo1 and Repo2
todo: define some user defined procedures, to not only compare existing Columns but to insert colums, missing in one repository into the second repository - manipulate the
Connector_Source_Columnsin Repo1 (or use AC to do this) - merge changes between Repo1 and Repo2
- Use the definitions you made in Repo1 for the implementation in Repo2
- change something in Repo1 or in Repo2
- Compare from time to time if Repo1 and Repo2 match or if there are differences.
What could be defined in the technical conception in Connector Source Columns?
- Connector Source Columns should be renamed in the DWH
- use
Connector_Source_Column.FriendlyNameto define the target column name. (or define the FriendlyName using AC) - FriendlyName can be inherited and they can be compared with ColumnName
-
ColumnName can be updated to use FriendlyName
- in Repo2 use this view to update data:
Filter2.Schema_Transformation_Column__Diff_ColumnName_FriendlyName
open the view in SSMS for editing for manually control what to change
or (not recommended!) try to use
UPDATE ... SET ColumnName = FriendlyName WHERE ...
- in Repo2 use this view to update data:
- use
- logical PK should be defined:
usePK_Ordinal_Position - columns should be described:
useDescription - Data protection and "DSGVO" must be observed, for some attributes it must be determined whether and how these are to be anonymised.
useAnonymize
- Imports
- Historizations
- Snapshots
- ...