State-of-the-art coreference resolution library using neural nets and spaCy. Try it online !
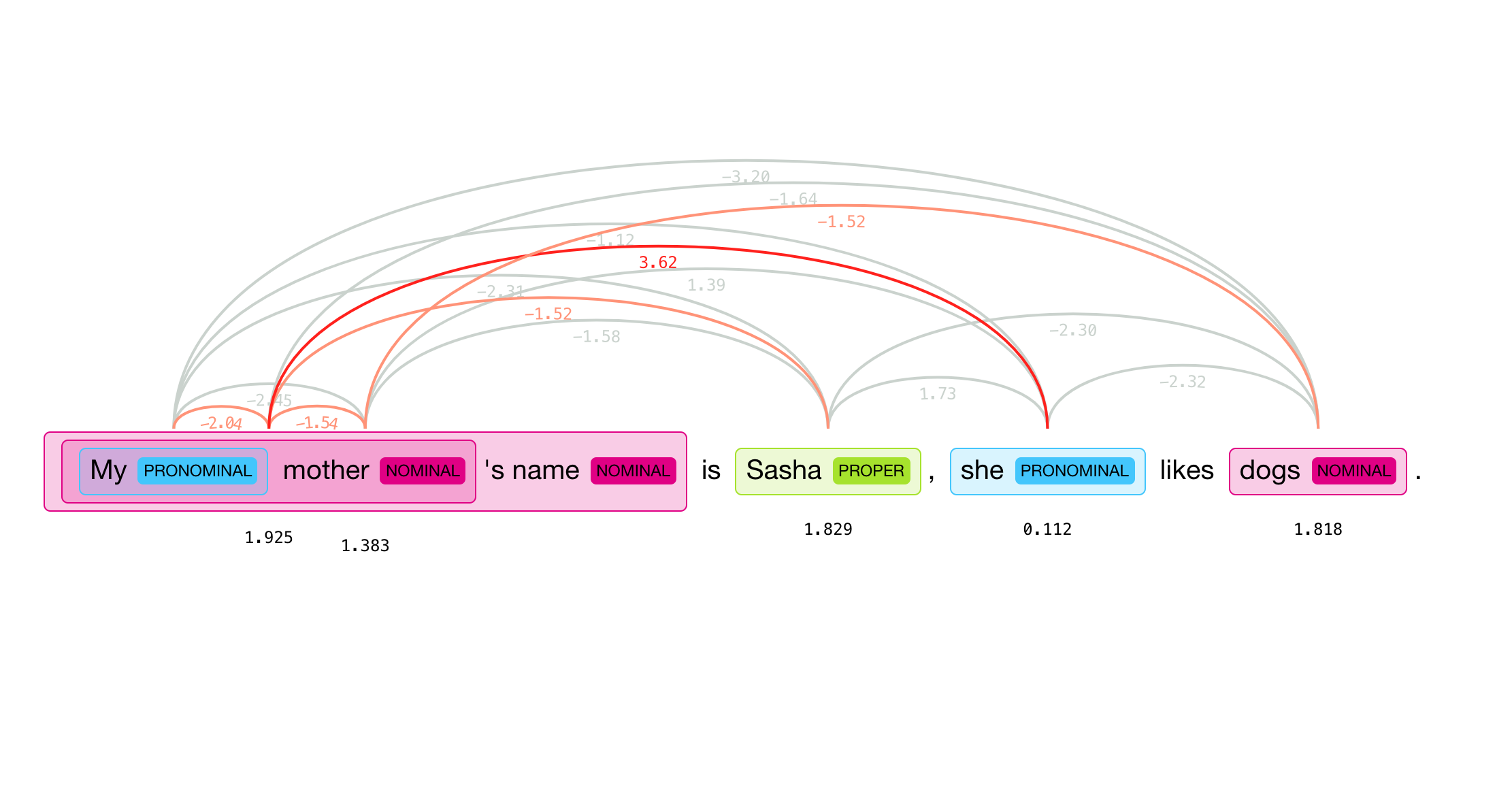
This coreference resolution module is based on the super fast spaCy parser and uses the neural net scoring model described in Deep Reinforcement Learning for Mention-Ranking Coreference Models by Kevin Clark and Christopher D. Manning, EMNLP 2016.
Be sure to check out our medium post in which we talk more about neuralcoref and coreference resolution.
Clone the repo (the trained model weights are too large for PyPI)
cd neuralcoref
pip install -r requirements.txt
You will also need an English model for spaCy if you don't already have spaCy installed.
python -m spacy download 'en'
The mention extraction module is strongly influenced by the quality of the parsing so we recommend selecting a model with a higher accuray than usual. Since the coreference algorithm don't make use of spaCy's word vectors, a medium sized spaCy model like 'en_depent_web_md' can strike a good balance between memory footprint and parsing accuracy.
To download and install the 'en_depent_web_md' model:
python -m spacy download 'en_depent_web_md'
python -m spacy link en_depent_web_md en
If you are an early user of spacy 2 alpha, you can use neuralcoref with spacy 2 without any specific modification.
python -m neuralcoref.server starts a wsgiref simple server.
You can retreive coreferences on a text or dialogue utterances by sending a GET request on port 8000.
Example of server query:
curl -G "http://localhost:8000/" --data-urlencode "text=My sister has a dog. She loves him so much"
The main class to import is neuralcoref.Coref.
neuralcoref.Coref exposes two main functions for resolving coreference:
-
Coref.one_shot_coref()for a single coreference resolution. Clear history, load a list of utterances/sentences and an optional context and run the coreference model on them. Arguments:utterances: optional iterator or list of string corresponding to successive utterances (in a dialogue) or sentences. Can be a single string for non-dialogue text.utterances_speakers_id=None: optional iterator or list of speaker id for each utterance (in the case of a dialogue).- if not provided, assume two speakers speaking alternatively.
- if utterances and utterances_speaker are not of the same length padded with None
context=None: optional iterator or list of string corresponding to successive utterances or sentences sent prior toutterances. Coreferences are not computed for the mentions identified incontext. The mentions incontextare only used as possible antecedents to mentions inuterrance. Reduce the computations when we are only interested in resolving coreference in the last sentences/utterances.context_speakers_id=None: optional, same asutterances_speakers_idforcontext.speakers_names=None: optional dictionnary of list of acceptable speaker names (strings) for speaker_id inutterances_speakers_idandcontext_speakers_id. Help identify the speakers when they are mentioned in the utterances/sentences.
Return: dictionnary of clusters of entities with coreference resolved
-
Coref.continuous_coref()for continous coreference resolution (during an on-going dialogue for instance). What is the difference betweenCoref.one_shot_coref()andCoref.continuous_coref():Coref.one_shot_coref()start from a blank page with a supplied context and supplied last utterances/sentences.Coref.continuous_coref()add the supplied utterance/sentence to the memory and compute coreferences on it. Arguments:utterances: optional iterator or list of string corresponding to successive utterances (in a dialogue) or sentences. Can be a single string for non-dialogue text.utterances_speakers_id=None: optional iterator or list of speaker id for each utterance (in the case of a dialogue).- if not provided, assume two speakers speaking alternatively.
- if utterances and utterances_speaker are not of the same length padded with None
speakers_names=None: optional dictionnary of list of acceptable speaker names (strings) for speaker_id inutterances_speakers_idandcontext_speakers_id. Help identify the speakers when they are mentioned in the utterances/sentences.
Return: dictionnary of clusters of entities with coreference resolved
neuralcoref.Coref has several functions for retreiving the results of the coreference resolution:
Coref.get_utterances(): retrieve the list utterances parsed by spaCy (list of spaCy Docs). Argument:last_utterances_added=True: only send back the last utterances/sentences added.
Coref.get_mentions(): retrieve the list of mentions identified during the coreference resolution.Coref.get_scores(): retrieve dictionnary of scores for single mentions and pair of mentions.Coref.get_clusters(): return the clusters computed during the coreference: dictionnary of list of mentions indexes. The mentions indexes are index in the list of mentions obtained byCoref.get_mentions(). Arguments:remove_singletons=True: only send back cluster with more than one mention.use_no_coref_list=True: don't send back mentions in a list of words for which coreference is not necessary/tricky (currently "I" and "you").
Coref.get_most_representative(): return a dictionnary of coreference with a representative coreference for each mention which has an antecedent. A representative coreference is typically a proper noun if there is one or a noun chunk if possible. Arguments:last_utterances_added=True: only send back representative mentions for the coreferences resolved in the last utterances added.use_no_coref_list=True: don't send back representative mentions for a list of words for which coreference is not necessary/tricky (currently "I" and "you").
The source code contains details of the various arguments you can use.
The code of server.py also provides a simple example.
Here is a simple example of use of the coreference resolution system.
from neuralcoref import Coref
coref = Coref()
clusters = coref.one_shot_coref(utterances=u"She loves him.", context=u"My sister has a dog.")
print(clusters)
mentions = coref.get_mentions()
print(mentions)
utterances = coref.get_utterances()
print(utterances)
resolved_utterance_text = coref.get_resolved_utterances()
print(resolved_utterance_text)